2021(self-supervised) - 浅谈MAE《Masked Autoencoders Are Scalable Vision Learners》
文章目录
-
- 原文地址
- 论文阅读方法
- 前因
- 初识
- 相知
-
- 分析问题
- 具体技术
- 部分实验
- 回顾
原文地址
https://arxiv.org/pdf/2111.06377.pdf
论文阅读方法
三遍论文法
前因
最近没太关注自监督学习领域的进展,但最近几天公众号都在疯狂推送这篇kaiming大佬的自监督学习新作《MAE》,抱着好奇的态度看了一下,有一些自己的感悟和思考。
此外,这篇文章在知乎上也引起了大佬们的广泛讨论,以及也有很多不错的博客进行了分析。
[1] 知乎讨论链接
[2] https://mp.weixin.qq.com/s/hGLQTB68Fdotydg6O0WrgQ
初识
为了学习有用的表征,文章主要构造了一个pretext task,如下图所示:
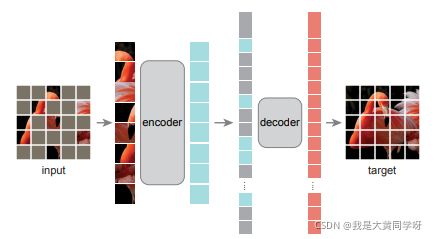
核心思想就是mask掉输入图像的一些patch,然后送到网络中进行重构。这个idea并不新鲜,但与之前的方法有几点最主要的不同之处:① 非对称的encoder-decoder结构;② mask的覆盖率非常高(75%)。
注意:用的backbone为Transformer
因为这两个独特的设计,使得MAE的计算量非常小,使得它能够很高效地推广到大模型的训练上。
MAE在下游任务的迁移取得了优于监督训练的性能,同时也通过实验证明了MAE的可扩展能力。
相知
主要介绍一些主要思想和方法,更细节的内容可以参考链接[2]以及阅读原文
分析问题
文中首先这种"移除一部分数据进行恢复(remove a portion of the data and learn to predict the removed content)的方法被BERT用于NLP领域的自监督学习。同样也被应用用于CV的自编码器(denoising autoencoders),最近也有方法参考它进行自监督学习,但效果却很差。
因此,文章提出一个问题:是什么导致masked autoencoding在CV和NLP领域的差距呢?
1)架构:CV所用的CNN不太好处理这类masked的问题,不像Transformer那样自然地构造"masked token"和"positional embeddings",但视觉Transformer的引入打破了领域限制。
2)信息密度:图像不同于语言,图像是自然信号有大量的冗余信息,而语言本身是高度语义且具有信息稠密性。这也就意味着图像块的重构可以根据邻域块来进行重构,而不需要高级的语义理解;但语言token的重构却要对整句话有较好的理解才可以。这意味着仅进行图像块的重构可能学不到太多高级语义特征,而MAE采用大面积的mask patch提升任务的难度,强迫网络学习到一些高级语义特征,如下图所示。

3)decoder扮演的角色不同:CV是对像素pixel的重构,这种输出富含的语义信息较少,而Bert这类模型要预测单词words,富含语义信息。因此Bert的编码器只是采用MLP,而作者认为在CV中编码器扮演的角色要重要得多。
具体技术
如上图所示,MAE采用非对称的结构,并且覆盖了大量图像块,下面详细介绍其技术:
Masking:参考ViT将图像块拆分成non-overlapping的块,并较高的覆盖率(75%)进行随机覆盖(uniform distrbution)。
Encoder:采用ViTal作为编码器,并且输入仅为那些可见的、没有masked的图像块,这样的好处是大大减少了时间复杂度,从而推广到大模型上。
并且作者后续做了实验,证明加mask patch作为encoder的输入并没有带来提升。
Decoder:解码器地输入包括编码器的输出 + mask token,每个mask token都是共享的,可学习的。并且只在预训练过程中使用decoder,下游任务上会丢弃,因此作者采用了一个轻量级的编码器。
每个块上都包含了PE,确保不丢失图像块的位置信息。
重构目标:为每个masked patch预测像素值,损失函数采用MSE。此外作者还引入一种normalized pixel values的目标,对每个块进行归一化后再进行预测,后续实验证明其能提升模型表征质量。
跟Bert一样,loss只关注mased patch的重构。作者也做了实验,如果在所有块上应用,性能会下降0.5%左右。
简单实现:作者还提供一种简单的实现方式,先处理所有图像块(线性映射+PE),然后随机shuffle顺序,根据masking率丢弃后面的块,将保留下的图像块送入encoder中。
随后,在编码块中插入掩码token并unshuffle得到正常序列的token与target进行对齐,送入解码器。
整个过程没有任何稀疏化的操作,并且shuffle等操作非常快
p.s. 以上就是主要的技术,作者文中和附录中均为给出网络结构,且无任何公式(大佬还是大佬…)
部分实验
下图展示了使用MAE进行自监督学习和直接进行监督学习的性能对比,可以看到使用MAE后性能提升了不少。除此之外,作者对ViT进行了重新复现,性能比Google原论文的结果高了不少(并且在大模型上没有出现退化,是不是也侧面说明了ViT其实不那么依赖大数据量?)

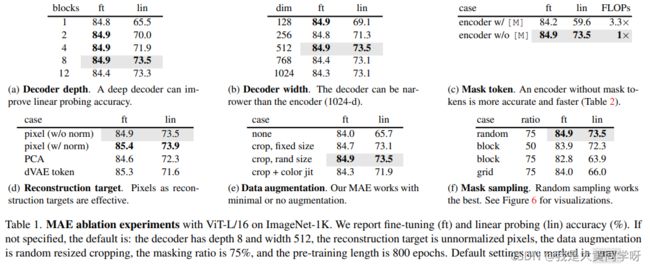
下图展示了一些消融实验:包括Decoder的深度、宽度实验(a)(b),在fine-tuning条件下,性能相差不大;(c)展示了encoder的mask实验,可以发现不加mask patch得到的性能更好,并且速度更快;(d)展示了重构目标给性能带来的影响;(e)(f)展示了数据增强和mask采样策略的影响。
更多细节详见论文
值得注意的是,之前的自监督学习一个很重要的评估指标是linear probe performance,即固定backbone (提取特征),只调整新加的MLP head (分类),评估得到的分类性能。
而MAE的实验表面,fine-tuning与linear probe之间的性能相差较大,并且更鲁棒。这一点也比较有争议,就是评估一个模型的表征能力,linear probe是不是针对这么重要呢?
回顾
说实话,这篇刚看完abstract,我没有get到太多创新点。因为Masked Autoencoder这种inpainting的设计思想早就应用在CV的各个领域了,包括自监督学习领域(比Bert的masked autoencoding更早)。而且,用Transformer做mask的自监督学习的工作也存在了(BEiT等)。
令我开始惊讶的是看到它重构的可视化效果,只根据少量的patch块也能重构出非常不错的结果,并且具有可解释性,比如下面的这幅图,这也从侧面体现了模型确实学到了一些有用的信息。

但也有令我疑惑的一点,这样是否真的有意义?比如当覆盖率非常高的时候,如果不事先见过这张图像,可能人都无法想象出来。这是不是一种过拟合呢?以及前面提到的linear probe的性能也能从侧面说明,如果不进行fine-tuning的话,直接从模型提取到的表征是不具备可分性的。
但也有观点提到,不能只依据linear probe的性能来评价,毕竟在下游任务中都要经过微调。而且,之前的对比学习在这个指标上表现好,其实很大程度上是沾了对比范式的光,其本身就起到一种特征聚合性质,所以模型在这个目标下学习得到的特征对于分类任务是非常友好的,因此只需要微调分类头即可。
其次,这些大佬团队的工程能力也是非常强的,从它们文中复现ViT的准确率就能可见一斑。文中对框架的具体细节的介绍也比较少,目前代码貌似还没有开源,很多问题可能还需要看了代码后才能明白。
总之,自监督学习的发展本身是由各种各样的Generative Learning变成了Contrastive Learning,由于ViT的出现,貌似又回到了Generative Learning来占据潮流。只希望在视觉领域早点出现像NLP中BERT这类的工作,真的起到代替ImageNet-pretrained的作用,反哺工业界。