基于卷积神经网络的密集人群估计/人群计数算法【内含教程和踩坑】
文章目录
- 前言
- 一、什么是密集人群估计
- 二、实验前准备
-
- 1.Github开源项目——Awesome Crowd Counting
- 2.数据集下载
- 3.环境配置
- 三、ShanghaiTech数据集实验
-
- 1.论文代码复现
- 2.CAN复现
- 3.CSRNet复现
- 4.可视化调参
- 5.复现代码性能评估
- 四、UCF_CC_50数据集实验
-
- 1.数据集目录结构重构
- 2.实验结果
- 五、DIY数据集实验
-
- 1.数据集采集
- 2.降低图片分辨率
- 3.数据集人头标注
- 4.数据集整合
- 5.DIY数据集训练
- 6.仅供参考的训练结果
- 六、人群计数后续工作
-
- 1.生成输入网络训练的密度图
- 2.生成网络预测结果的密度图
- 文末资源
- 总结
前言
毕业季要到了,在此之前最重要的事情就是毕业设计,而我的课题是关于密集人群估计的算法研究。我和各位在坐大部分人一样都是从零开始的,在看论文、修改代码、训练模型、调参数中一点点了解人群估计的全貌。此文力求带领各位初学者进一步了解人群密度估计算法,尽量涵盖前期了解算法的途径到后期自己复现论文代码、训练模型的全过程。本文出现的一些代码和数据集都会在文末给出网盘资源供读者下载。
一、什么是密集人群估计
简而言之,就是给你一张图片,然后你能算出图片中出现的人的数量。基于卷积神经网络的此类算法都离不开生成Ground Truth,高斯核函数生成密度图,然后对密度图进行积分,积分结果即为估计出的人群数量,很明显算法并不是一个个去数人头,而是通过积分的方法来估计。有人问为啥要这么做呢,因为人群估计的重点在于密集,一张图片可能存在成百上千人,就算让算法一个个数这也是不现实的,因此如今最好的办法就是去拟合估计,也算是回归算法的一种做法。
想要大致了解可以阅读以下文章:
基于CNN的人群密度图估计方法简述
人群计数:从MCNN开始谈起~
二、实验前准备
1.Github开源项目——Awesome Crowd Counting
名字带有Awesome的项目永远都不会让你失望,这个项目整理了关于人群估计的论文和论文中模型的代码,当然并不是所有论文都能找得到代码。有个原则就是先找有代码的论文来读,因为论文始终是架空的,只有真正自己运行起了代码才是开始的第一步。
项目地址如下,此处给的是https://hub.fastgit.org这一github镜像网站,这能很好解决连接github时断时续的问题,强烈推荐给读者。
Awesome Crowd Counting
2.数据集下载
人群密度估计的数据集相对较为有限,基本就那么几个常见数据集。
1.ShanghaiTech dataset【最常用】
总共1198张标记图片,数据集分为两部分part_A和part_B,part_B部分的图片相较于part_A部分的图片人群分布更为稀疏。
MCNN中首次建立该数据集,part_A部分300张用于训练,182张用于测试;part_B部分400张用于训练,316张用于测试。
2.WorldExpo’s dataset
总共3980张标记图片,其中3380张用于训练,剩下的图片用于测试。
测试集包括5中不同的场景,每种场景有120张图片。每种场景中都提供了ROI,因此人群计数只在ROI部分进行。
3.UCF_CC_50 dataset
总共50张图片。这一数据集的特点是图片数量少,但是人数变化大。
4.其他
还有监考拍摄的行人数据集UCSDpeds和商场的mall_dataset数据集。
3.环境配置
这一步环境配置没什么好说的,读者自行配置环境,配置环境是做实验的第一步,也算是对个人能力的一种锻炼。毫无疑问是要使用Python语言来开发,版本最好为3.7以上,建议安装anaconda,学习通过虚拟环境管理不同项目,pip或者conda install安装过慢解决方法参照使用国内清华、阿里镜像来提速。深度学习框架我是选择了Pytorch,我在过去的AlexNet那篇文章也有解释理由,因为Pytorch更加Pythonic。最后深度学习训练最好有块显卡,别在自己的笔记本电脑上跑。
三、ShanghaiTech数据集实验
1.论文代码复现
其实这一步以前读者最好先把原论文读一遍,不过问题也不大,看代码其实更好理解。我跑通的论文代码有两个,[CAN] Context-Aware Crowd Counting和[CSR] CSRNet: Dilated Convolutional Neural Networks for Understanding the Highly Congested Scenes,这两份代码结构上基本一致,CSRNet早于CAN发表,尽管CAN论文中给出自己超过前面论文模型的实验证明,但我在自己做过实验后更看好CSRNet,尽管CSRNet训练的时间远比CAN长。
2.CAN复现
从github上直接下载的代码运行绝对是会报错的,不过只要修改几个地方就可以正常运行了。
具体请参考文章:[CAN] Context-Aware Crowd Counting 复现过程记录
【踩坑】文章主要针对ShanghaiTech数据集中的partB进行训练,如果是训练partA可能也会报错,问题就在于batch_size,partB部分的训练图片都是统一大小的,而partA则是大小不一,对于图片大小不一致只能将batch_size设置为1。不仅如此,训练partA时你甚至可能遇到训练出现Loss是nan的异常情况,网上说是学习率太高导致,造成了梯度爆炸,只要将学习率减少原来十分之一左右就可以了。
3.CSRNet复现
如CAN复现的那样如法炮制来修改原代码,训练基本不会出啥问题。
【切记】每次训练完后一定要额外备份训练好的参数即pth文件,否则可能你再次训练就会被覆盖,亲身经历血的教训!
4.可视化调参
一般来说partA的效果往往和论文效果相差甚远,我训练的时候CSRNet倒是和论文给的结果很贴近,而CAN就呵呵了。我们接下来可以就CAN对partA的训练过程进行可视化,然后通过图像我们手动调节学习率等参数(我目前是只修改CAN学习率)。
强烈推荐PP飞桨VisualDL只要直接安装就可以很方便使用,再在代码里加几句代码就可以在浏览器轻松看到可视化的训练参数曲线。官方指南VisualDL 使用指南也写的很全面,跟着来就行,我目前只是使用了标量图表这个简单的功能,读者可自行尝试超参数这一功能,据说效果不错。
我训练时图像如下:
1.学习率为1e-5时CAN训练图像:
2.学习率为1e-6时CAN训练图像:
3.学习率为1e-7时CAN训练图像:
Loss值(即MAE)越小效果越好,即1e-5时下限更低,所以训练时我选用e-5这个学习率。
5.复现代码性能评估
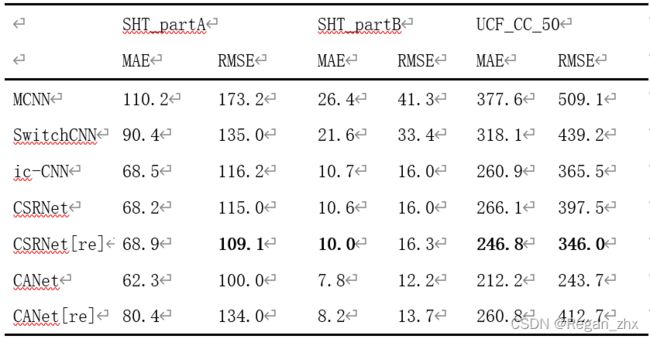
其中【re】代表复现的代码,可以看出CAN与原论文中的结果差别很大,目前造成这个的原因我还在寻找,要不就是我代码配置出了问题,可能需要多实验几次看看甚至换台机器运行,否则真就是原论文的问题,保不齐论文数据就是造的,在学术界这种事情也不是没有发生,希望是前者吧,CAN这篇论文热度确实不及CSRNet,并且其代码框架和CSRNet神似。
反观复现的CSRNet代码,在学校实验室3060GPU上训练的结果竟然比原论文要好,简直难以置信。
综上,CSRNet是一个性能优异的人群计数算法,准确率和稳定性在众多算法中脱颖而出,作为2018年发表的算法模型,放到4年后的现在依旧有很多值得借鉴参考的地方。
四、UCF_CC_50数据集实验
1.数据集目录结构重构
网上所下载的UCF_CC_50的数据集往往是图片和mat文件都在同个文件夹,而ShanghaiTech里面则是分了train训练集和test测试集。为了更好让我们已复现的代码可以适应UCF数据集,我们要对UCF目录进行重构。按照论文要把50张图分为5组每组10张做交叉验证,4组训练集,1组测试集;如此做不同的5次最后取平均值。我的五组安排如下:
| 组别 | test测试集所含图片 |
|---|---|
| part1 | 1-10.jpg做测试集 |
| part 2 | 11-20做测试集 |
| part 3 | 21-30做测试集 |
| part 4 | 31-40做测试集 |
| part 5 | 41-50做测试集 |
以part1为例如图,其实就是和ShanghaiTech的文件目录保持一致。
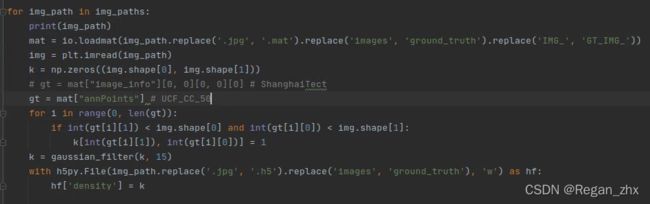
【踩坑】UCF_CC_50里面的mat文件和SHanghaiTech里面的mat文件坐标所在字典的key是不同的,改成下图所示即可。
2.实验结果
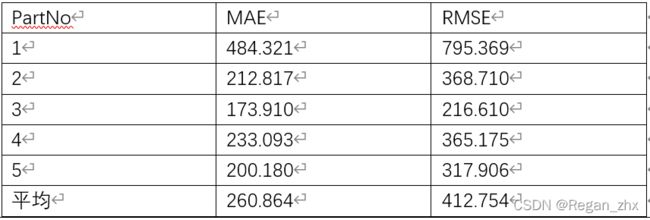
这个训练的时间可不比ShanghaiTech的短,本人训练结果如下图供读者参考:
1.CAN训练结果
2.CSRNet训练结果
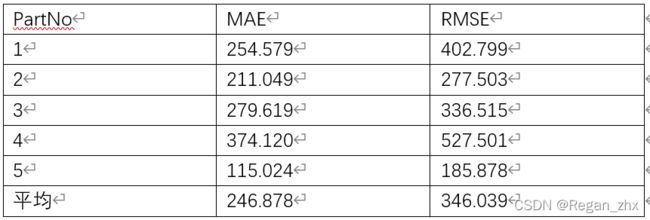
观察上面图表就可知为什么我说CSRNet更好,网上有的人都质疑CAN中的某个网络模块是无用的,不过本人也没法求证就听一听罢了,要用实验数据说话。学术界确实存在用某刻碰巧的数据来代表整个模型算法的优越,而忽略了鲁棒性这一关键因素,因此流传着AI界论文不可复现这个梗。
五、DIY数据集实验
跑通了实验只能证明读者已具备配置环境和自行运行程序的能力,要进一步理解人群估计算法还得自行制作数据集来训练。
1.数据集采集
这一步读者可根据自身情况而定,手机相机等设备拍摄人群图像亦或是网上采集到的现成图片均可。我采用的是前者,使用手机拍摄校园中的人群。如图:

【踩坑】在人头标注之前,要关注的一个图片重要参数就是分辨率,因为训练的时候要生成Ground Truth,h5文件的大小直接和分辨率挂钩。好比我手机拍摄出来的图片分辨率是3000x4000=1200万像素,生成h5文件接近100M,训练时GeForce RTX 3060的显卡直接报空间不足,因为ShanghaiTech里面的任一张图片的h5文件也才6K左右。因此如果读者拍摄的图片分辨率太高,就要降低图片分辨率。
2.降低图片分辨率
#resolution_changer.py
import glob
from PIL import Image
import os
img_path = glob.glob("dataset/train/images/*jpg")
path_save = "dataset/train/images/"
for file in img_path:
name = os.path.join(path_save, file)
print(name)
im = Image.open(file)
im.thumbnail((1080,720)) # 尽量按比例改成1080,720格式,尽管最后图片不会都是找个大小,但是一定比这个规格小
print(im.format, im.size, im.mode)
im.save(name,'JPEG')
这是网上直接搜到的代码,读者自行更改img_path和path_save即可,不难发现这两个路径是相同的,只是img_path多了个*.jpg。
3.数据集人头标注
[T-PAMI] NWPU-Crowd: A Large-Scale Benchmark for Crowd Counting and Localization是个不错的网站,值得一看,其实在Awesome-Crowd-Counting里面就能找到。接下来我们要使用其中的Annotation Tools工具CCLabeler-master,读者直接进入链接安装即可,其中有完备的说明,很容易使用。尽管如此我还是多说几句吧。
1.首先把已降低分辨率的图片都放到cclabeler-master\data\images下,并且把图片编好序号。
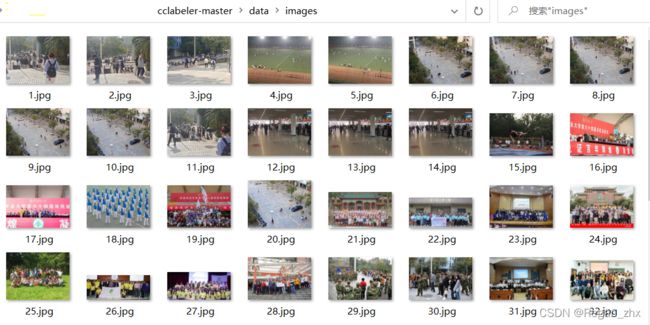
2.进入cclabeler-master\users\,会看到test.json文件,打开json文件,password在登录浏览器界面时要用到,data存放你待标注的图片名称(可以自己写个python脚本生成字符串),不用后缀,done和half保持空的状态。
3.打开cmd,cd到cclabeler-master目录,执行python manage.py runserver 0.0.0.0:8000,出现如果提示后在浏览器输入localhost:8000再登录就OK了。

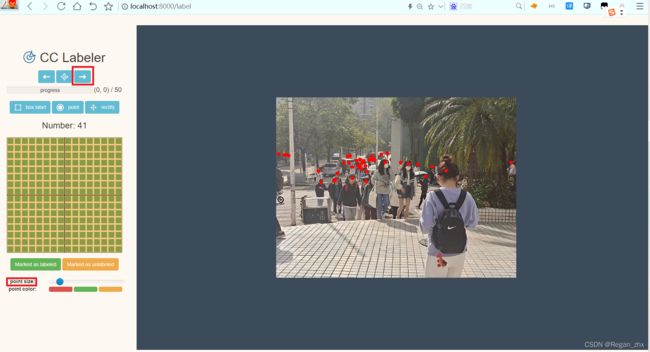
4.界面如下,具体操作看项目的HOWTO.pdf
4.数据集整合
标注打完后,人头的位置坐标就存在cclabeler-master\data\jsons\目录下,里面的json文件相当于市面上数据集里的mat文件。参照ShanghaiTech数据集分成train、test,然后分成ground_truth和images子目录的结构就可以了。
5.DIY数据集训练
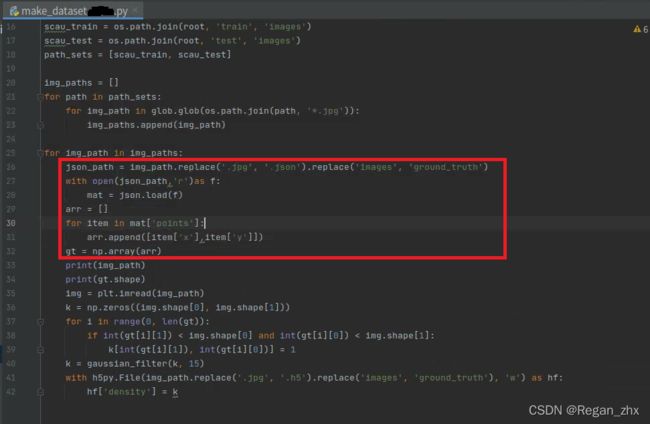
毕竟和传统数据集中mat文件不同,DIY的是json文件,所以代码相应位置也要做细微调整。只需将make_dataset.py此处更改即可,其他地方貌似没有什么要改动的,生成了GT的h5文件后,后续操作都一视同仁。
6.仅供参考的训练结果
| CAN | 学习率=e-5 | MAE=4.231 | RMSE=7.334 |
|---|---|---|---|
| CSRNet | 无需更改 | MAE=5.774 | RMSE=7.546 |
我的数据集图片数仅有50张,40张用于训练,10张用于测试,epoch数均为500,看来这次是CAN打败了CSRNet呢。
六、人群计数后续工作
在完成网络训练后续仍然有许多工作要做,因为从前面一直训练好网络权重为止我们并没有对整个项目的细节有更多了解,只是能跑通模型而已。接下来将介绍几个方面可以方便读者进行类似毕业论文的撰写,比如生成训练用的密度图,生成网络预测的密度图。
1.生成输入网络训练的密度图
如今的人群计数算法也是主流人群计数算法都是通过卷积神经网络寻找图像低级特征与密度图的映射关系,而不再是以前的图像与人数的映射关系。因此神经网络的输入就应该是密度图,输出的也应该是密度图,密度图的一大优势是可以直接积分求和,体现在python代码中就是调用sum()方法。
如下为输入网络的密度图生成代码,使用Jupyter notebook食用更佳。
# ipynb文件
import h5py
import scipy.io as io
import PIL.Image as Image
import numpy as np
import os
import glob
from matplotlib import pyplot as plt
from scipy.ndimage.filters import gaussian_filter
import scipy
from scipy import spatial
import json
import cv2
from matplotlib import cm as CM
from image import *
from model import CSRNet # 以CSRNet为例,此文件最好放到与项目同级目录
import torch
import random
import matplotlib.pyplot as plt
%matplotlib inline # 使用py文件请删除此行
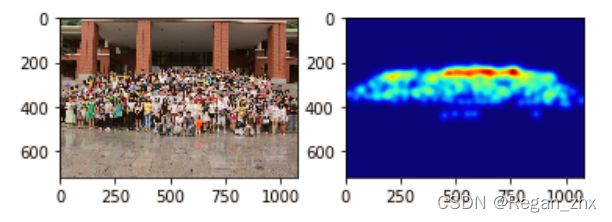
img_path = r'SCAU_50\train\images\35.jpg' # 读者自行更改想要显示图片路径
json_path = img_path.replace('.jpg', '.json').replace('images', 'ground_truth') # 这里是自制数据集,所以读的是json文件,如果读者用已有数据集可以更改成mat文件,道理都是一样的就是读取人头位置坐标。
with open(json_path,'r')as f:
mat = json.load(f)
arr = []
for item in mat['points']: # 由于是自制数据集是points,如果是ShanghaiTech的话可以参考项目源码对应部分
arr.append([item['x'],item['y']])
gt = np.array(arr)
img = plt.imread(img_path)
k = np.zeros((img.shape[0], img.shape[1]))# 按图片分辨率生成零矩阵
# img.shape是先图片height然后是width,所以如下代码gt[i][1]与height比较,gt[i][0]与width比较
for i in range(0, len(gt)):
if int(gt[i][1]) < img.shape[0] and int(gt[i][0]) < img.shape[1]:
k[int(gt[i][1]), int(gt[i][0])] = 1 # 往零矩阵填人头坐标填1
k = gaussian_filter(k, 15)# 高斯滤波,请自行了解,这里的15是sigma值,值越大图像越模糊
plt.subplot(1,2,1) # 将plt画布分成1行2列,当前图片置于位置1
plt.imshow(img)
plt.subplot(1,2,2) # 当前图片置于位置2
plt.imshow(k,cmap=CM.jet)
plt.show()
所得图像如下:
2.生成网络预测结果的密度图
在调用test.py进行预测时,神经网络读入任一张人群图片,输出一张匹配的密度图,我们接下来就显示这张密度图。
#ipynb文件
import sys
# 导入项目路径,这样在jupyter notebook就可以直接导入
sys.path.append(r"E:\大四上\毕设\Context-Aware-Crowd-Counting-master")
# 这里以CANNet为例,如果不是用jupyter notebook请忽略这步
import glob
from image import *
from model import CANNet
import os
import torch
from torch.autograd import Variable
from sklearn.metrics import mean_squared_error, mean_absolute_error
from torchvision import transforms
from pprint import pprint
import matplotlib.pyplot as plt
from matplotlib import cm
import matplotlib
matplotlib.rcParams['font.sans-serif'] = ['Fangsong']
matplotlib.rcParams['axes.unicode_minus'] = False
# 以上两步为设置matplotlib显示中文,这里可以忽略
%matplotlib inline
transform = transforms.Compose([
transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
]) # RGB转换使用的转换器,其中的mean和std参数可以不用理会,这些数据是大家公认使用的,因为这些数值是从概率统计中得到的,直接照写即可不必深究
model = CANNet()# 导入网络模型
model = model.cuda()
checkpoint = torch.load(r'E:\大四上\毕设\Context-Aware-Crowd-Counting-master\scau_model_best.pth.tar') # 载入训练好的权重
model.load_state_dict(checkpoint['state_dict'])
model.eval() # 准备预测评估
# 指定任意一张图片即可,都是从CANNet项目源码里复制的,这里仅为作者本地所运行代码供参考
img = transform(Image.open('E:\\大四上\\dataset\\SCAU_50\\train\\images\\35.jpg').convert('RGB')).cuda()
img = img.unsqueeze(0)
h, w = img.shape[2:4]
h_d = h // 2
w_d = w // 2
# 可以看出输入图片被切割成四份
img_1 = Variable(img[:, :, :h_d, :w_d].cuda())
img_2 = Variable(img[:, :, :h_d, w_d:].cuda())
img_3 = Variable(img[:, :, h_d:, :w_d].cuda())
img_4 = Variable(img[:, :, h_d:, w_d:].cuda())
density_1 = model(img_1).data.cpu().numpy()
density_2 = model(img_2).data.cpu().numpy()
density_3 = model(img_3).data.cpu().numpy()
density_4 = model(img_4).data.cpu().numpy()
# 将上部两张图片进行拼接,...为表示省略表示后面参数都全选
up_map=np.concatenate((density_1[0,0,...],density_2[0,0,...]),axis=1)
down_map=np.concatenate((density_3[0,0,...],density_4[0,0,...]),axis=1)
# 将上下部合成一张完成图片
final_map=np.concatenate((up_map,down_map),axis=0)
plt.imshow(final_map,cmap=cm.jet) # 展示图片
print(final_map.sum())# 直接输出图像预测的人数
效果展示供参考:
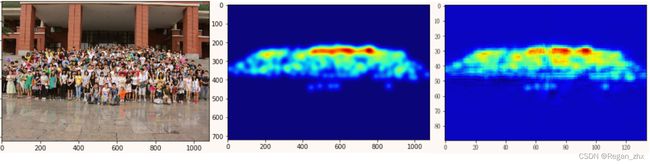
依次为原图,输入网络训练的密度图,网络预测的输出密度图。
文末资源
https://wwn.lanzoul.com/b030neddc
密码:6j57
由于训练结果的网络参数太多且单个文件太大,就没放网盘上,外链内容暂时只包含CSRNet、CAN的可执行代码,UCF_CC_50原数据集。
总结
长路漫漫你并不孤单,你不是一个人面对这困难,曾经有许多人和你面临相同的问题,未来也会有无数人遇到,我们能做的且唯一能做到的就是问心无愧,尽力而为。毕设还未结束,我后期仍将更新此文,请读者关注,欢迎和各路大佬交流学习。
最后感谢本文中引用的链接的作者及组织。