开发spark程序笔记
开发spark程序笔记
开发spark程序流程:spark使用本地模式(local),进行程序调试,完成后,生成jar包,submit到hadoop yarn集群上运行。
spark的RDD中的操作分为两大类:转换、执行(行动)。
spark的RDD中的转换操作采用惰性操作。(非惰性可能占用大量内存)
1.生成RDD
1)从本地文件生成RDD
命令:textFile(URI)
例如:

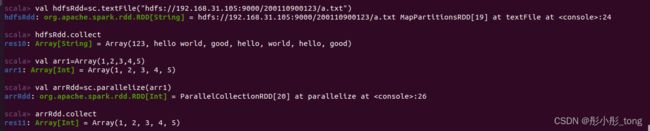
2)从hdfs文本文件生成RDD
命令:textFile(URL)
启动集群:

3)从集合创建数据
方法:parallelize(集合)
练习:从文件生成RDD,用collect转化为Array,然后用parallelize再生成RDD,再用collect显示,用一行程序完成。
2.idea下spark编程环境搭建
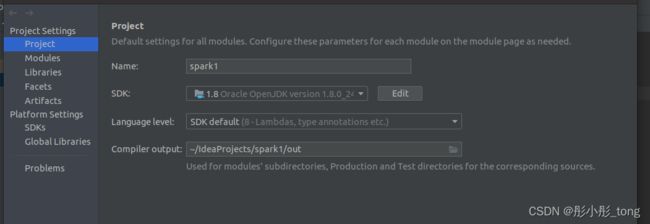
1)创建一个scala项目
2)加入spark的库
菜单File->project Structure
左边选Libraries或者Global Libraries,中间点击“+”号,选java,选中spark目录下的jar下面所有的jar文件。
函数式编程初步(高阶函数):
1.参数是函数
定义一个参数是函数的函数:
object helloWorld {
def main(args: Array[String]):Unit = {
def addxy(x:Int,y:Int):Int=x+y
def mulxy(x:Int,y:Int):Int=x*y
def func1(f:(Int,Int)=>Int,a:Int,b:Int):Int={f(a,b)}
val res=dunc1(addxy,1,2)
val res1=func1(x:Int,y:Int):Int=>x+y,1,2)
println(res1)
val res2=func1(mulxy,1,2)
println(res2)
}
}
将函数的参数简化为匿名函数:
object helloWorld {
def main(args: Array[String]):Unit = {
def func1(f:(Int,Int)=>Int,a:Int,b:Int):Int={f(a,b)}
val res1=func1((x:Int,y:Int)=>x+y,1,2)
println(res1)
val res2=func1((x:Int,y:Int)=>x*y,1,2)
println(res2)
}
}
将函数的参数简化为匿名函数进行简化:
object helloWorld {
def main(args: Array[String]):Unit = {
def func1(f:(Int,Int)=>Int,a:Int,b:Int):Int={f(a,b)}
val res1=func1((x,y)=>x+y,1,2)
println(res1)
val res2=func1((x,y)=>x*y,1,2)
println(res2)
}
}
将函数的参数用通配符进行简化:
object helloWorld {
def main(args: Array[String]):Unit = {
def func1(f:(Int,Int)=>Int,a:Int,b:Int):Int={f(a,b)}
val res1=func1(_+_,1,2)
println(res1)
val res2=func1(_*_,1,2)
println(res2)
}
}