SETR 阅读笔记
目录
- 前言
- 1. 模型的特点
- 2. 模型结构
-
- 2.1 Encoder
- 2.2 Decoder
- 3. 思考与分析
- 4. 下一步计划
- 参考
前言
SETR是一篇CVPR2021的语义分割论文,论文将于语义分割视为Seq2Seq的预测任务,提出了一种解决语义分割问题的新思路。
1. 模型的特点
现有的语义分割模型大多都是基于FCN的Encoder-Decoder结构:Encoder用于学习图像特征,Decoder则基于Encoder学到的特征对图片中的每一个像素进行分类。其中,Encoder通常以卷积分类网络作为Backbone,将输入图片不断下采样以增加感受野,学习更加抽象的图像特征。但是,通过不断堆叠卷积层来增加感受野无法有效地学习图像信息中的远距离依赖关系。而这一点对于提升语义分割的效果十分重要。
为了解决这个问题,SETR完全舍弃卷积操作,Encoder将输入图像看作图像patch序列,通过全局注意力建模学习图像特征;Decoder利用从Transformer Encoder中学到的特征,将图像恢复到原始大小,完成分割任务。整个过程没有使用卷积操作,没有对图片进行下采样,而是在Encoder Transformer的每一层进行全局上下文建模,从而为语义分割问题的解决提供了新思路。
SETR的主要贡献如下:
- 区别于Encoder-Decoder结构,将语义分割问题重新定义为Seq2Seq问题
- Encoder完全使用Transformer框架,通过序列化的图像实现全局注意力特征提取
- 设计了三种不同复杂度的解码器。
2. 模型结构
SETR整体模型结构如下:

2.1 Encoder
Encoder的功能是将输入图像 x ∈ R C × H × W x \in \mathbb R^{C \times H \times W} x∈RC×H×W转化为序列 Z ∈ R L × C Z \in \mathbb R^{L \times C} Z∈RL×C。(img2seq)
输入图像等分为16个Patch,每一个Patch大小都是 H 16 × W 16 \frac{H}{16} \times \frac{W}{16} 16H×16W,可以拉伸为长度 L = H × W 256 L = \frac{H \times W}{256} L=256H×W的序列。将这16份Patch平展成一个序列,通过线性变换 f : p → e ∈ R C f: p \rightarrow e \in \mathbb R^{C} f:p→e∈RC,将每一个Patch映射到 C C C维向量空间中,转化为序列 x f ∈ R L × C x_f \in \mathbb R^{L \times C} xf∈RL×C。然后为每一个 e i e_i ei向量添加对应的位置编码 p i p_i pi,得到最终的输入序列 E = { e 1 + p 1 , e 2 + p 2 , … , e L + p L } E = \lbrace e_1 + p_1, e_2 +p_2, \ldots, e_L + p_L \rbrace E={e1+p1,e2+p2,…,eL+pL}。
将embeding序列 E E E输入到Transformer Encoder当中,Transformer Encoder由 L e L_e Le个Transformer层组成。其中第 l l l层的输入是 Z l − 1 ∈ R L × C Z^{l -1} \in \mathbb R^{L \times C} Zl−1∈RL×C的向量,自注意力的输入是由 Z l − 1 Z^{l -1} Zl−1计算得到的三维元组 ( q u e r y , k e y , v a l u e ) (query, key, value) (query,key,value):
q u e r y = Z l − 1 W Q , k e y = Z l − 1 W K , v a l u e = Z l − 1 W V query = Z^{l - 1}W_Q, key = Z^{l - 1}W_K, value = Z^{l - 1}W_V query=Zl−1WQ,key=Zl−1WK,value=Zl−1WV
其中, W Q W_Q WQ、 W K W_K WK、 W V W_V WV是可学习权重矩阵,且 W Q / W K / W V ∈ R C × d W_Q/W_K/W_V \in \mathbb R^{C \times d} WQ/WK/WV∈RC×d, d d d为 ( q u e r y , k e y , v a l u e ) (query, key, value) (query,key,value)的维度。
则自注意力可以表示为:
S A = Z l − 1 + s o f t m a x ( Q K T d ) V SA = Z^{l -1} + softmax(\frac{QK^T}{\sqrt {d}})V SA=Zl−1+softmax(dQKT)V
多层自注意力即是由m个SA拼接起来得到, M S A ( Z l − 1 ) = [ S A 1 ( Z l − 1 ) ; S A 2 ( Z l − 1 ) ; ⋯ ; S A m ( Z l − 1 ) ] W O MSA(Z^{l - 1}) = [SA_1(Z^{l - 1}); SA_2(Z^{l - 1}); \cdots; SA_m(Z^{l - 1})]W_O MSA(Zl−1)=[SA1(Zl−1);SA2(Zl−1);⋯;SAm(Zl−1)]WO,其中 W O ∈ R m d × C W_O \in \mathbb R^{md \times C} WO∈Rmd×C,最后 M S A MSA MSA的输出通过一个带有残差连接的全连接层得到Encoder的输出:
Z l = M S A ( Z l − 1 ) + M L P ( M S A ( Z l − 1 ) ) ∈ R L × C Z^l = MSA(Z^{l-1}) + MLP(MSA(Z^{l-1})) \in \mathbb R^{L \times C} Zl=MSA(Zl−1)+MLP(MSA(Zl−1))∈RL×C
进而有Transformer Encoder各层的输出 { Z 1 , Z 2 , … , Z L e } \lbrace Z^{1},Z^{2},\ldots,Z^{L_e} \rbrace {Z1,Z2,…,ZLe}
2.2 Decoder
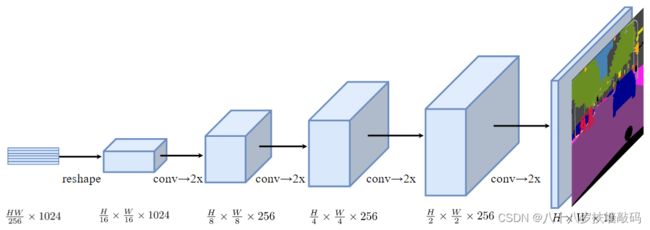
Decoder的目标是在原始的二维图像 ( H × W ) (H \times W) (H×W)上生成分割结果,需要将Encoder的输出 Z Z Z从二维 H W 256 × C \frac{HW}{256} \times C 256HW×Creshape为三维特征图 H 16 × W 16 × C \frac{H}{16} \times \frac{W}{16} \times C 16H×16W×C。
设计了三种解码器:
(1)朴素上采样
使用一个简单的2层网络: 1 × 1 1 \times 1 1×1conv + batch norm + 1 × 1 1 \times 1 1×1conv,将将Transformer输出的 Z L e Z^{L_e} ZLe投影到类别个数的维度上(如Cityscapes中有19个类别),然后直接用双线性插值进行上采样得到原分辨率大小的输出。最后接一个逐像素计算交叉熵损失的分类层,得到每个像素的预测类别。
(2)渐进上采样(PUP)
直接一步上采样会引入很大的噪声,可以使用交替执行卷积和上采样的方法,将上采样倍数设置成2倍,减轻噪声。从 H 16 × W 16 \frac{H}{16} \times \frac{W}{16} 16H×16W的 Z L e Z^{L_e} ZLe得到原始图片大小,共需执行4次上采样操作。
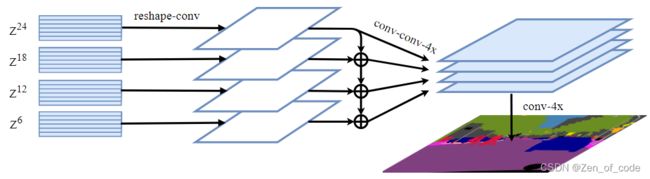
(3)多层特征融合(MLA)
与特征金字塔相似的多级特征融合,但不同的是特征 Z L Z^L ZL来自各层Transformer并具有相同的分辨率。每隔 L e M \frac{L_e}{M} MLe层提取一层特征 { Z m } ( m ∈ { L e M , 2 L e M , … , M L e M ) \lbrace Z^m \rbrace (m \in \lbrace \frac{L_e}{M},2\frac{L_e}{M},\ldots,M\frac{L_e}{M}) {Zm}(m∈{MLe,2MLe,…,MMLe),总共提取了 M M M条路径的特征。其中,每一层都是先将 Z L e Z^{L_e} ZLe从 H W 256 × C \frac{HW}{256} \times C 256HW×Creshape到 H 16 × W 16 × C \frac{H}{16} \times \frac{W}{16} \times C 16H×16W×C,然后使用一个三层神经网络进行处理(卷积核大小 1 × 1 1 \times 1 1×1, 3 × 3 3 \times 3 3×3, 3 × 3 3 \times 3 3×3),在第一层和第三层分别将通道数减半,然后在第三层之后进行4倍双线性插值上采样。并且从第2条路径开始,依次融合前面路径的特征,增强每条路径间的信息交互,再次经过一个 3 × 3 3 \times 3 3×3的卷积层后,将每条路径得到的特征图进行通道维度的拼接,并采用4倍双线性插值进行上采样,恢复出原图尺寸。
3. 思考与分析
SETR完全采用ViT-large作为encoder有以下几个缺点:
(1) ViT-large 参数和计算量非常大,有300M+参数,这对于移动端模型是无法承受的;
(2) ViT的结构不太适合做语义分割,因为ViT是柱状结构,全程只能输出固定分辨率的feature map, 比如1/16, 这么低的分辨率对于语义分割不太友好,尤其是对轮廓等细节要求比较精细的场景。
(3) ViT的柱状结构意味着一旦增大输入图片或者缩小patch大小,计算量都会成平方级提高,对显存的负担非常大。
(4) 位置编码,ViT 用的是固定分辨率的positional embedding, 但是语义分割在测试的时候往往图片的分辨率不是固定的,这时要么对positional embedding做双线性插值,这会损害性能;要么做固定分辨率的滑动窗口测试,这样效率很低而且很不灵活。
4. 下一步计划
- 阅读源码进一步理解SETR模型结构
- 学习并整理U-Net
- 阅读论文熟悉Segformer模型结构
参考
Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers