【计量统计】计量经济学导论常见公式原理及习题解答
关键词:[Stata] [计量经济学] [习题解答]

一、简单二元回归模型
y = b 0 + b 1 x + u y = b_0 + b_1x + u y=b0+b1x+u
- b 0 b_0 b0 , b 1 b_1 b1被称为回归系数。 b 0 b_0 b0也被称为常数项或截矩项,或截矩参数。
- b 1 b_1 b1代表了回归元 x 的边际效果,也被称为斜率参数;
- u u u为误差项或扰动项,它代表了除了 x 之外可以影响y的因素
w a g e = b 0 + b 1 e d u c + u wage= b_0 + b_1educ + u wage=b0+b1educ+u
误差项 u 的平均值为零? y = ( b 0 + 5 ) + b 1 x + ( u − 5 ) y = (b_0 +5)+ b_1x + (u-5) y=(b0+5)+b1x+(u−5), E ( u ′ ) = E ( u − 5 ) = 0 E(u')=E(u-5)=0 E(u′)=E(u−5)=0,上述推导说明我们总可以通过调整常数项来实现误差项的均值为零
条件期望零值假定
E ( u ∣ x ) = E ( u ) E(u|x) = E(u) E(u∣x)=E(u),我们需要对 u 和 x 之间的关系做一个关键假定。理想状况是对 x 的了解并不增加对 u 的任何信息。换句话说,我们需要 u 和 x 完全不相关;
普通最小二乘法的推导
C o v ( X , Y ) = E ( X Y ) – E ( X ) E ( Y ) Cov(X,Y) = E(XY) – E(X)E(Y) Cov(X,Y)=E(XY)–E(X)E(Y)
E [ ( A + B ) C ] = E [ A C ] + E [ B C ] E[(A+B)C]=E[AC]+E[BC] E[(A+B)C]=E[AC]+E[BC]
由 E ( u ∣ x ) = E ( u ) = 0 E(u|x) = E(u) = 0 E(u∣x)=E(u)=0 可得 C o v ( x , u ) = E ( x u ) = 0 Cov(x,u) = E(xu) = 0 Cov(x,u)=E(xu)=0
OLS 法是要找到一条直线,使残差平方和最小。残差是对误差项的估计,因此,它是拟合直线(样本回归函数)和样本点之间的距离;

正式解一个最小化问题,即通过选取参数而使下列残差值的和最小:
∑ i = 1 n ( u ^ i ) 2 = ∑ i = 1 n ( y i − β ^ 0 − β ^ 1 x i ) 2 \sum_{i=1}^{n}{(\hat{u}_{i})^2}=\sum_{i=1}^{n}(y_i-\hat{\beta}_{0}-\hat{\beta}_{1}x_{i})^2 ∑i=1n(u^i)2=∑i=1n(yi−β^0−β^1xi)2
E [ y – b 0 – b 1 x ] = 0 E[y – b_0 – b_1x] = 0 E[y–b0–b1x]=0 => E [ x ( y – b 0 – b 1 x ) ] = 0 E[x(y – b_0 – b_1x)] = 0 E[x(y–b0–b1x)]=0
从而 ∑ i = 1 n x i ( y i − β ^ 0 − β ^ 1 x i ) = 0 \sum_{i=1}^{n}{x_{i}(y_i-\hat{\beta}_{0}-\hat{\beta}_{1}x_i)}=0 ∑i=1nxi(yi−β^0−β^1xi)=0
从而 ∑ i = 1 n x i u ^ i = 0 \sum_{i=1}^{n}{x_{i}\hat{u}_i}=0 ∑i=1nxiu^i=0
OLS 的代数性质
OLS 残差和为零,因此 OLS 的样本残差平均值也为零;
OLS回归线总是通过样本的均值: y ‾ = β ^ 0 + β ^ 1 x ‾ \overline{y}=\hat{\beta}_{0}+\hat{\beta}_{1}\overline{x} y=β^0+β^1x
- 把每一次观测看作由被解释部分和未解释部分构成: y i = y ^ i + u ^ i y_i=\hat{y}_i+\hat{u}_i yi=y^i+u^i
- 预测值和残差在样本中是不相关的: c o v ( y ^ i , u ^ i ) = 0 cov(\hat{y}_i,\hat{u}_i)=0 cov(y^i,u^i)=0
推导 c o v ( y ^ i , u ^ i ) = 0 cov(\hat{y}_i,\hat{u}_i)=0 cov(y^i,u^i)=0
- 由于 C o v ( X , Y ) = E ( X Y ) – E ( X ) E ( Y ) Cov(X,Y) = E(XY) – E(X)E(Y) Cov(X,Y)=E(XY)–E(X)E(Y), c o v ( y ^ i , u ^ i ) = E ( y ^ i u ^ i ) − y ‾ E ( u ^ i ) cov(\hat{y}_i,\hat{u}_i) = E(\hat{y}_{i} \hat{u}_{i})-\overline{y}E(\hat{u}_{i}) cov(y^i,u^i)=E(y^iu^i)−yE(u^i)
- 因为 E ( u ^ i ) = 0 E(\hat{u}_{i})=0 E(u^i)=0,所以 c o v ( y ^ i , u ^ i ) = E [ ( β ^ 0 + β ^ 1 x i ) u ^ i ] = β ^ 0 E ( u ^ i ) + β ^ 1 E ( x i u ^ i ) cov(\hat{y}_i,\hat{u}_i) = E[(\hat{\beta}_0+\hat{\beta}_1x_i)\hat{u}_i] = \hat{\beta}_0E(\hat{u}_{i})+\hat{\beta}_1E(x_i\hat{u}_{i}) cov(y^i,u^i)=E[(β^0+β^1xi)u^i]=β^0E(u^i)+β^1E(xiu^i)
- 因为 E ( u ^ i ) = 0 E(\hat{u}_{i})=0 E(u^i)=0, E ( x i u ^ i ) = 0 E(x_i\hat{u}_{i})=0 E(xiu^i)=0,所以 c o v ( y ^ i , u ^ i ) = 0 cov(\hat{y}_i,\hat{u}_i)=0 cov(y^i,u^i)=0
残差平方和
S S T = S S E + S S R SST=SSE+SSR SST=SSE+SSR
- 总平方和 S S T = ∑ i = 1 n ( y i − y ‾ ) 2 SST=\sum_{i=1}^{n}{(y_i-\overline{y})^2} SST=∑i=1n(yi−y)2,对 y 在样本中所有变动的度量;
- 解释平方和 S S E = ∑ i = 1 n ( y i − y ^ ) 2 SSE=\sum_{i=1}^{n}{(y_i-\hat{y})^2} SSE=∑i=1n(yi−y^)2,度量了 y 的预测值在样本中的变动;
- 残差平方和 S S R = ∑ u ^ i 2 SSR=\sum{\hat{u}_i^2} SSR=∑u^i2,残差平方和度量了残差的样本变异;
拟合优度 R方
如何衡量样本回归线是否很好地拟合了样本数据,拟合优度计算公式: R 2 = S S E / S S T = 1 – S S R / S S T R^2 = SSE/SST = 1 – SSR/SST R2=SSE/SST=1–SSR/SST,可被看作是 y 的样本变动中被可以被 x 解释的部分;
- 当回归中加入另外的解释变量时, R 2 R_2 R2 通常会上升
- 例外:如果这个新解释变量与原有的解释变量完全共线,那么OLS不能使用
- 如果OLS恰好使第二个解释变量系数取零,那么不管回归是否加入此解释变量,SSR 相同
- 如果OLS使此解释变量取任何非零系数,那么加入此变量之后,SSR 降低了;实际操作中,被估计系数精确取零是极其罕见的,所以,当加入一个新解释变量后,一般来说,SSR 会降低;
调整过的 R方
R 2 R_2 R2增加并不意味着加入新的变量一定会提高模型拟合度;
调整过的 R2 是 R2 一个修正版本,当加入新的解释变量,调整过的 R2 不一定增加
R ‾ 2 = 1 − n − 1 n − k − 1 S S R S S T \overline{R}^2=1-\frac{n-1}{n-k-1}\frac{SSR}{SST} R2=1−n−k−1n−1SSTSSR
- 调整过的 R2 是 1 减去 OLS 残差的样本方差(修正过自由度之后)与 y 的样本方差之比
- 因为 ( n − 1 ) / ( n − k − 1 ) > 1 (n-1)/(n-k-1)>1 (n−1)/(n−k−1)>1,所以调整过的 R2 总比 R2 小
- 加入一个解释变量有两个相反的效果:1)SSR 降低导致调整过的 R2 增加;2) ( n − 1 ) / ( n − k − 1 ) (n-1)/(n-k-1) (n−1)/(n−k−1)增加导致调整过的 R2 降低
- 调整过的 R2 可能是负的,发生在以下情况:所有解释变量使残差平方和下降的太少,不足以抵消因子 ( n − 1 ) / ( n − k − 1 ) (n-1)/(n-k-1) (n−1)/(n−k−1)
- R2 只有在过原点回归中才可能为负
OLS 的无偏性
β ^ 0 = y ‾ − β ^ 1 x ‾ = β 0 + β 1 x ‾ + u ‾ − β ^ 1 u ‾ = β 0 + ( β 1 − β ^ 1 ) x ‾ + u ‾ \hat{\beta}_0=\overline{y}-\hat{\beta}_1\overline{x}=\beta_0+\beta_1\overline{x}+\overline{u}-\hat{\beta}_1\overline{u}=\beta_0+(\beta{1}-\hat{\beta}_1)\overline{x}+\overline{u} β^0=y−β^1x=β0+β1x+u−β^1u=β0+(β1−β^1)x+u
所以, E ( β 0 ^ ) = β 0 + E [ ( β 1 − β ^ 1 ) x ‾ ] + E ( u ‾ ) = β 0 E(\hat{\beta_0})=\beta_0+E[(\beta{1}-\hat{\beta}_1)\overline{x}]+E(\overline{u})=\beta_0 E(β0^)=β0+E[(β1−β^1)x]+E(u)=β0
OLS 估计量的抽样方差
在一个附加假定下计算这个方差会容易的多,因此有 V a r ( u ∣ x ) = σ 2 ( H o m o s k e d a s t i c i t y ) Var(u|x)=\sigma^2(Homoskedasticity) Var(u∣x)=σ2(Homoskedasticity)
E ( y ∣ x ) = b 0 + b 1 x E(y|x)=b_0 + b_1x E(y∣x)=b0+b1x, V a r ( y ∣ x ) = σ 2 Var(y|x) = \sigma^2 Var(y∣x)=σ2,方差; σ \sigma σ 标准方差
误差方差 σ 2 \sigma^2 σ2 越大,斜率估计量的方差也越大
误差方差估计量
回归的误差: σ ^ 2 = 1 n − 2 ∑ u ^ i 2 = S S R / ( n − 2 ) \hat{\sigma}^2=\frac{1}{n-2}\sum{\hat{u}_i^2}=SSR/(n-2) σ^2=n−21∑u^i2=SSR/(n−2)
回归的标准误: σ ^ \hat{\sigma} σ^
二、多元回归分析:估计
假设 1-5
假设 MLR.1 对参数而言为线性
在总体模型(或称真实模型)中,因变量 y 与自变量 x 和误差项 u 关系如下
y = b 0 + b 1 x 1 + b 2 x 2 + … + b k x k + u y= b_0+ b_1x_1+ b_2x_2+ …+b_kx_k+u y=b0+b1x1+b2x2+…+bkxk+u
其中, b 1 , b 2 … , b k b_1, b_2 …, b_k b1,b2…,bk为所关心的未知参数,u 为不可观测的随机误差项或随机干扰项
假定 MLR.2 随机抽样性:从总体中随机抽取若干个样本
假定 MLR.3 零条件均值
E ( u ∣ x i 1 , x i 2 , … , x i k ) = 0 E(u| x_{i1} , x_{i2},…, x_{ik})=0 E(u∣xi1,xi2,…,xik)=0
当该假定成立时,我们称所有解释变量均为外生的;否则,我们则称解释变量为内生的
假定 MLR.4 不存在完全共线性
在样本中,没有一个自变量是常数,自变量之间也不存在严格的线性关系;当一个自变量是其它解释变量的严格线性组合时,我们说此模型有多重共线性;
当 n < ( k + 1 ) n<(k+1) n<(k+1) 也发生完全共线性的情况,即样本数量小于自由度 +1 时;
OLS 的无偏性:无偏性是估计量的特性,而不是估计值的特性。估计量是一种方法(过程),该方法使得给定一个样本,我们可以得到一组估计值。我们评价的是方法的优劣
- 如果在设定中包含了不属于真实模型的变量,这是过度设定,对我们的参数估计没有影响,OLS仍然是无偏的;但它对OLS估计量的方差有不利影响;
- 如果在设定中排除了一个本属于真实模型的变量,即遗漏变量,这是设定不足;此时 OLS 通常有偏
假定 MLR.5 同方差性
Assume Homoskedasticity: 同方差性假定: V a r ( u ∣ x 1 , x 2 , … , x k ) = σ 2 Var(u|x_1 , x_2 ,…, x_k ) = \sigma^2 Var(u∣x1,x2,…,xk)=σ2
意思是,不管解释变量出现怎样的组合,误差项 u 的条件方差都是一样的,如果这个假定不成立,我们说模型存在异方差性
误设模型的方差
在考虑一个回归模型中是否该包括一个特定变量的决策中,偏误和方差之间的消长关系是重要的;
真实模型是 y = b 0 + b 1 x 1 + b 2 x 2 + u y = b0 + b1x1 + b2x2 +u y=b0+b1x1+b2x2+u,有 V a r ( β ^ 1 ) = σ 2 S S T 1 ( 1 − R 1 2 ) Var(\hat{\beta}_1)=\frac{\sigma^2}{SST_1(1-R_1^2)} Var(β^1)=SST1(1−R12)σ2
考虑误设模型是 y ~ = β ~ 0 + β ~ 1 x 1 \tilde{y}=\tilde{\beta}_0 +\tilde{\beta}_1x_1 y~=β~0+β~1x1,有 V a r ( β ~ 1 ) = σ 2 S S T 1 Var(\tilde{\beta}_1)=\frac{\sigma^2}{SST_1} Var(β~1)=SST1σ2
当 x1 和 x2 不相关时, V a r ( β ~ 1 ) = V a r ( β ^ 1 ) Var(\tilde{\beta}_1)=Var(\hat{\beta}_1) Var(β~1)=Var(β^1),否则 V a r ( β ~ 1 ) < V a r ( β ^ 1 ) Var(\tilde{\beta}_1)
用残差项构造一个误差项方差的估计: σ ^ 2 = S S R / ( n − k − 1 ) \hat{\sigma}^2=SSR/(n-k-1) σ^2=SSR/(n−k−1),df 是自由度,观察点个数 - 被估参数个数
OLS 的有效性:高斯-马尔科夫定理
在假定 MLR.1.5下,OLS 是最优线性无偏估计量(BLUE)
- 最优:方差最小
- 线性:因变量数据的线性函数
- 无偏:参数估计量的期望等于参数的真值
- 估计量:产生一个估计量的规则

三、多元回归分析:推断
OLS 估计量的样本分布
Sampling Distributions of the OLS Estimators
假设 MLR.6 正态
当Gauss-Markov假设成立时,OLS是最优线性无偏估计,为了进行经典的假设检验,我们要在Gauss-Markov假设之外增加另一假设;
假设 MLR.6 (正态):假设 u 与 x 1 , x 2 , … , x k x1 , x2 ,…, xk x1,x2,…,xk独立,且 u 服从均值为 0,方差为 σ 2 \sigma^2 σ2的正态分布
- 假设 MLR.1-MLR.6 被称为经典线性模型假设,满足这六个假设的模型称为经典线性模型
- 在经典线性模型假设下,OLS 不仅是 BLUE,而且是最小方差无偏估计量,即在所有线性和非线性的估计量中,OLS估计量具有最小的方差
如果正态假设不成立怎么办?此时是异方差情况,那么,通过变换,特别是通过取自然对数,往往可以得到接近于正态的分布,降低异方差性;
注意:大样本允许我们放弃正态假设(近似方式)
单个总体参数的假设检验:t 检验
Testing Hypothesis About a Single Population Parameter: The t test
y = β 0 + β 1 x 1 + . . . + β k x k + u y=\beta_0+\beta_1x_1+...+\beta_kx_k+u y=β0+β1x1+...+βkxk+u
研究如何对一个特定的 β j \beta_j βj进行假设检验
注意这是一个 t 分布,因此要用 σ ^ 2 \hat{\sigma}^2 σ^2 来估计 σ 2 \sigma^2 σ2,自由度: n − k − 1 n-k-1 n−k−1
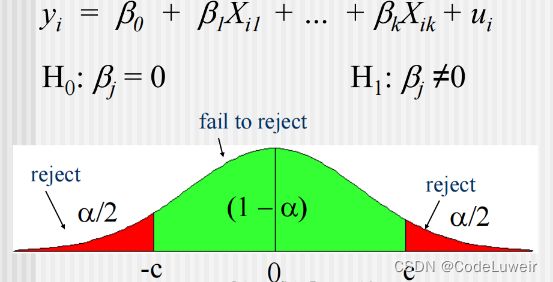
原假设: H 0 : β j = 0 H0 : \beta_j=0 H0:βj=0
如果接受零假设,则认为控制 x x x 其它分量后, x j x_j xj 对 y 没有边际影响
T 值计算公式: t β ^ j = β ^ j / s e ( β ^ j ) t_{\hat{\beta}_j}=\hat{\beta}_j/se(\hat{\beta}_j) tβ^j=β^j/se(β^j)
- β ^ j \hat{\beta}_j β^j 是 x j x_j xj的系数值
- s e ( β ^ j ) se(\hat{\beta}_j) se(β^j) 是 β j \beta_j βj的标准差
除了零假设外,我们需要替代假设 H1,并设定显著性水平,H1 可以是单边(单尾)或双边(尾)的,双边就是单边显著性水平*2;
如果我们愿意在5%的概率上错误地拒绝实际上为真的零假设,则说我们的显著水平为5%;
取定显著性水平 a 后,找到自由度为 n – k – 1 n – k – 1 n–k–1 的 t 分布的 ( 1 – α ) (1 – \alpha) (1–α) 分位数 c,即临界值;
单尾:单边替代假设

注意:当 t 分布的自由度增大时,t 分布趋近于标准正态分布;
双尾:双边替代假设
P-value
计算 t 检验的 p 值
提前确定显著水平可能会隐藏关于假设检验的一些有用信息;另一种想法:如果将算得的t 统计量作为临界值,那么使得零假设被拒绝的最小显著水平是多少;这个水平称为 p 值。
对于双边检验 p − v a l u e = P ( ∣ T ∣ > ∣ t ∣ ) p-value=P(|T|>|t|) p−value=P(∣T∣>∣t∣)
- 小 p 值提供了拒绝零假设的证据,大 p 值不能提供证据拒绝零假设;
- 理解 p 值的其它角度:如果零假设为真,那么有多大的概率可以观察到算得的 t 值
经济重要性与统计显著性
- 统计显著性完全由t 统计量的大小决定
- 经济上的重要性强调估计系数的大小
- 权衡两者来判断解释变量对被解释变量的边际影响
置信区间
Confidence Intervals
由于随机取样误差的存在,我们不可能通过样本知道 β \beta β 的准确值,但是利用来自随机样本的数据构造一个取值的集合,使得真值在给定概率下属于这个集合是可能的;这样的集合称为置信集,预先设定的真值属于此集合的概率称为置信水平(置信度);
置信集是下限和上限之间所有可能的取值,故置信集为一个区间,称为置信区间;
如果 t β ^ j = ( β ^ j − α j ) / s e ( β ^ j ) t_{\hat{\beta}_j}=(\hat{\beta}_j-\alpha_j)/se(\hat{\beta}_j) tβ^j=(β^j−αj)/se(β^j)服从 n − k − 1 n-k-1 n−k−1自由度的 t 分布,简单的运算可以得到关于未知的 β j \beta_{j} βj的置信区间: [ β ^ j − c ⋅ s e β ^ j , β ^ j + c ⋅ s e β ^ j ] [\hat{\beta}_j-c·se\hat{\beta}_j,\hat{\beta}_j+c·se\hat{\beta}_j] [β^j−c⋅seβ^j,β^j+c⋅seβ^j];
举例:

参数线性组合的假设检验
Testing Hypotheses About a Single Linear Combination of the Parameters
假设我们要检验是否一个参数等于另一个参数 H 0 : β 1 = β 2 H0: \beta_1 = \beta_2 H0:β1=β2,而不是检验 β 1 \beta_1 β1 是否等于一个常数
- t = β ^ 1 − β ^ 2 s e ( β ^ 1 − β ^ 2 ) t=\frac{\hat{\beta}_1-\hat{\beta}_2}{se(\hat{\beta}_1-\hat{\beta}_2)} t=se(β^1−β^2)β^1−β^2
- s e ( β ^ 1 − β ^ 2 ) = V a r ( β ^ 1 − β ^ 2 ) se(\hat{\beta}_1-\hat{\beta}_2)=\sqrt{Var(\hat{\beta}_1-\hat{\beta}_2)} se(β^1−β^2)=Var(β^1−β^2)
- V a r ( β ^ 1 − β ^ 2 ) = V a r ( β ^ 1 ) + V a r ( β ^ 2 ) − 2 C o v ( β ^ 1 , β ^ 2 ) Var(\hat{\beta}_1-\hat{\beta}_2)=Var(\hat{\beta}_1)+Var(\hat{\beta}_2)-2Cov(\hat{\beta}_1,\hat{\beta}_2) Var(β^1−β^2)=Var(β^1)+Var(β^2)−2Cov(β^1,β^2)
- 所以, s e ( β ^ 1 − β ^ 2 ) = ( [ s e ( β ^ 1 ) ] 2 + [ s e ( β ^ 2 ) ] 2 − 2 s 12 ) se(\hat{\beta}_1-\hat{\beta}_2)=\sqrt{([se(\hat{\beta}_1)]^2+[se(\hat{\beta}_2)]^2-2s_{12})} se(β^1−β^2)=([se(β^1)]2+[se(β^2)]2−2s12),其中 s 12 = C o v ( β ^ 1 , β ^ 2 ) s_{12}=Cov(\hat{\beta}_1,\hat{\beta}_2) s12=Cov(β^1,β^2)
Stata中,在 reg y x1 x2 … xk 后,可以输入 test x1 =x2 得到检验的p值
举例:竞选支出对选举结果的影响
v o t e A = β 0 + β 1 l o g ( e x p e n d A ) + β 2 l o g ( e x p e n d B ) + β 3 p r t y s t r A + u voteA = \beta_0 + \beta_1log(expendA) + \beta_2log(expendB) + \beta_3prtystrA + u voteA=β0+β1log(expendA)+β2log(expendB)+β3prtystrA+u
- H 0 : β 1 = − β 2 H0:\beta_1=-\beta_2 H0:β1=−β2 ,然后: θ 1 = β 1 + β 2 = 0 \theta_1=\beta_1+\beta_2=0 θ1=β1+β2=0
- 令 β 1 = θ 1 − β 2 \beta_1=\theta_1-\beta_2 β1=θ1−β2
- 带入方程得 v o t e A = β 0 + θ 1 l o g ( e x p e n d A ) + β 2 [ l o g ( e x p e n d B ) – l o g ( e x p e n d A ) ] + β 3 p r t y s t r A + u voteA = \beta_0 +\theta_1log(expendA) + \beta_2[log(expendB) –log(expendA)] + \beta_3prtystrA + u voteA=β0+θ1log(expendA)+β2[log(expendB)–log(expendA)]+β3prtystrA+u
- 这个模型与原模型相同,但是此时可以直接从回归中得到 β 1 – β 2 = θ 1 \beta_1 – \beta_2 = \theta_1 β1–β2=θ1的标准差
- 参数的任何线性组合都可以用类似的手段进行检验
多个线性约束的假设检验:F检验
Testing Multiple Linear Restrictions: The F Test
是检验“排除约束”,即想知道是不是一组参数都等于0;
此时,零假设形如 H 0 : β k − q + 1 = 0 , . . . , β k = 0 H0: \beta_{k-q+1} = 0, ... , \beta_k = 0 H0:βk−q+1=0,...,βk=0,其中 q q q 就是你要检验的参数个数;
替代假设 H 1 : H 0 为 假 H1: H0 为假 H1:H0为假
不能分别进行 t 检验,因为存在这样的可能性:在给定显著水平下,所有的参数都不显著,但是联合检验显著;出现这种情况的原因:解释变量很可能高度相关,即使变量实际上显著,结果中的较大的标准差也可能表明参数不显著;
或者换一个说法:我们想知道加入 x k − q + 1 , … , x k x_{k-q+1}, …, x_k xk−q+1,…,xk 来降低 SSR 是否值得?
通过公式 F = ( S S R r − S S R u r ) / 1 S S R u r / ( n − k − 1 ) F=\frac{(SSR_r-SSR_ur)/1}{SSR_ur/(n-k-1)} F=SSRur/(n−k−1)(SSRr−SSRur)/1,其中 r r r 表示约束, u r ur ur 表示无约束, q q q 是约束个数
由于 SSR 可能很大而不易处理,我们有另一个有用的公式,结合 S S R = S S T ( 1 – R 2 ) SSR = SST(1 – R^2) SSR=SST(1–R2)
F = ( R u r 2 − R r 2 ) / q ( 1 − R u r 2 ) / ( n − k − 1 ) F=\frac{(R_{ur}^2-R^2_r)/q}{(1-R_{ur}^2)/(n-k-1)} F=(1−Rur2)/(n−k−1)(Rur2−Rr2)/q,其中 r r r 代表约束, u r ur ur 代表无约束;
举个例子
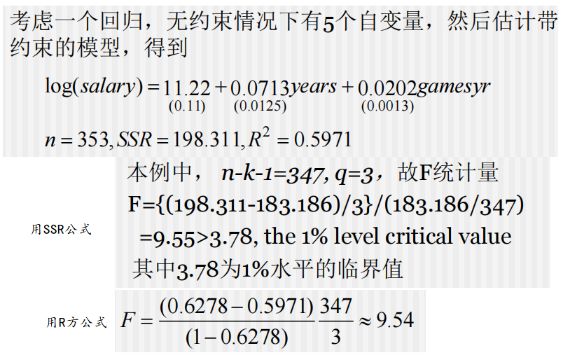
排除约束的一个特殊情况是检验 H 0 : b 1 = b 2 = … = b k = 0 H0: b1 = b2 =…= bk = 0 H0:b1=b2=…=bk=0
由于只带常数项的回归得到的 R 2 R^2 R2 为0,此时的 F 统计量应为 F = R 2 / k ( 1 − R 2 ) / ( n − k − 1 ) F=\frac{R^2/k}{(1-R^2)/(n-k-1)} F=(1−R2)/(n−k−1)R2/k
特殊情况:注意:如果由于自变量系数受到约束而使因变量发生改变的话,比如 y = b 0 + b 1 x 1 + b 2 x 2 + . . . + b k x k + u y = b_0 + b_1x_1 + b_2x_2 + . . . +b_kx_k + u y=b0+b1x1+b2x2+...+bkxk+u
b 1 b_1 b1被限制为1,从而新的因变量为 y − x y-x y−x,则 R方 构造的 F 统计量不再适用,只有 SSR 形式的公式适用
对于模型 v o t e A = b 0 + b 1 l o g ( e x p e n d A ) + b 2 l o g ( e x p e n d B ) + b 3 p r t y s t r A + u voteA = b_0 + b_1log(expendA) + b_2log(expendB) + b_3prtystrA + u voteA=b0+b1log(expendA)+b2log(expendB)+b3prtystrA+u
零假设为: H 0 : b 1 = 1 , b 3 = 0 H0: b_1 = 1, b_3 = 0 H0:b1=1,b3=0,代入进入将 v o t e A − l o g ( e x p e n d A ) = b 0 + b 2 l o g ( e x p e n d B ) + u voteA - log(expendA) = b_0 + b_2log(expendB) + u voteA−log(expendA)=b0+b2log(expendB)+u作为约束模型
四、多元回归分析:进一步的问题
数据的测度单位换算对OLS统计量的影响
改变解释变量测度单位的影响,注意是测量单位,不是对变量转换数学形式
- t 统计量相同
- R平方相同
- SSR相同
- SE相同
改变变量y的测度单位会导致系数和标准差相应的改变,所以解释变量系数显著性和对其解释没有改变;
改变一个变量x的测度单位会导致该变量系数和标准差的相应改变,所以所有解释变量显著性和对其解释没有改变;
重新定义变量
- 对数模型,如果被解释变量以对数形式出现,改变被解释变量度量单位对任何斜率系数没有影响(这应该不是指系数值,有待实际做分析确认);
- 双对数模型,改变y测度单位将改变截距,不改变斜率系数;
对于变量的估计系数大小问题
- 被估计系数的大小是不可比较的
- 一个相关的问题是,当变量大小差别过大时,在回归中因运算近似而导致的误差会比较大
对数模型
OLS也可以用在 x 和 y 不是严格线性的情况,通过使用非线性方程,使得关于参数仍为线性
- 可以取x,y(一个或全部)的自然对数
- 可以用x的平方形式
- 可以用x的交叉项
对数模型 l n ( y ) = b 0 + b 1 x + u ln(y) = b_0 + b_1x + u ln(y)=b0+b1x+u, b 1 b_1 b1近似是,给定一单位 x 的改变,y 的百分比变化,常被称为半弹性;
对数都是以 e 为底的自然对数形式!
比如:
l o g ( y ) = β 0 + β 1 x 1 log(y)=\beta_0+\beta_1x_1 log(y)=β0+β1x1, x x x 上升 1 个单位, y y y 将变化 ( 100 β 1 ) % (100\beta_1)\% (100β1)%,如果 y y y 当前值为 y 0 y_0 y0,那么预计 y y y 的值为 y 0 ( 1 + β 1 ) y_0(1+\beta_1) y0(1+β1)
近似证明:
- l n ( y ) = a + b x ln(y)=a+bx ln(y)=a+bx, l n ( y 0 ) = a + b x 0 ln(y_0)=a+bx_0 ln(y0)=a+bx0
- 那么 y = e a + b x y=e^{a+bx} y=ea+bx, y 0 = e a + b x 0 y_0=e^{a+bx_0} y0=ea+bx0, ( y − y 0 ) / y 0 = e a + b x − e a + b x 0 e a + b x 0 = e b ( x − x 0 ) − 1 (y-y_0)/y_0=\frac{e^{a+bx}-e^{a+bx_0}}{e^{a+bx_0}}=e^{b(x-x_0)}-1 (y−y0)/y0=ea+bx0ea+bx−ea+bx0=eb(x−x0)−1
- 所以, x x x 每上升一个单位, y y y新增了 e b − 1 e^b-1 eb−1,再乘100的话就接近 b % b\% b%;
- 举例: l n ( y ) = 3 + 0.018 x ln(y)=3+0.018x ln(y)=3+0.018x, x = 1 x=1 x=1时, y = 20.45 y=20.45 y=20.45, x = 2 x=2 x=2时, y = 20.82 y=20.82 y=20.82
- 从而 100 ∗ ( 20.82 − 20.25 ) / 20.45 = 1.8 % 100*(20.82-20.25)/20.45=1.8\% 100∗(20.82−20.25)/20.45=1.8%,跟系数乘以100近似;
为什么用对数模型?
- 取对数后变量的斜率系数,不随变量测度单位改变
- 如果回归元和回归子都取对数形式,斜率系数给出对弹性的一个直接估计
- 对于 y > 0 y>0 y>0 的模型,条件分布经常偏斜或存在异方差,而 l n ( y ) ln(y) ln(y) 就小多了,所以 l n ( y ) ln(y) ln(y) 的分布窄多了,限制了异常(或极端)观测值(outliers)的影响;
一些经验法则 关于 什么类型的变量经常用对数形式
- 肯定为正的钱数:工资,薪水,企业销售额和企业市值
- 非常大的变量:如人口,雇员总数和学校注册人数等
一些经验法则 关于 什么类型的变量经常用水平值形式
- 用年测量的变量:如教育年限,工作经历,任期年限和年龄
可以以水平值或对数形式出现的变量:比例或百分比变量:失业率,养老保险金参与率;
对数模型的限制:
- 一个变量取零或负值,则不能使用对数
- 如果 y 非负但可以取零,则有时使用 l o g ( 1 + y ) log(1+y) log(1+y)
- 当数据并非多数为零时,使用 l o g ( 1 + y ) log(1+y) log(1+y) 估计,并且假定变量为 l o g ( y ) log(y) log(y),解释所得的估计值,是可以接受的
- 当 y 取对数形式时,更难以预测原变量的值,因为原模型允许我们预测 log(y) 而不是 y;
含二次式模型
其实就是复杂版的一元二次方程:
- 假如 x x x 的系数为正, x 2 x^2 x2的系数为负,那么开口向下,y 先随 x 增加而增加,再随 x 增加而减少;
- 假如 x x x 的系数为负, x 2 x^2 x2的系数为正,那么开口向上,y 先随 x 增加而减少,再随 x 增加而增加;
- 上述两种情况, y = b x + a x 2 y=bx+ax^2 y=bx+ax2,转折点就是 x 0 = ∣ b 2 a ∣ x_0=|\frac{b}{2a}| x0=∣2ab∣
含交叉项
对于形式为 y = b 0 + b 1 x 1 + b 2 x 2 + b 3 x 1 x 2 + u y = b_0 + b_1x_1 + b_2x_2 + b_3x_1x_2 + u y=b0+b1x1+b2x2+b3x1x2+u的模型,我们不能单独将 b 1 b_1 b1解释为关于 x 1 x_1 x1,y变化的度量,我们需要将 b 3 b_3 b3也考虑进来,因为 Δ y Δ x 1 = β 1 + β 3 x 2 \frac{\Delta y}{\Delta x_1}=\beta_1+\beta_3x_2 Δx1Δy=β1+β3x2,所以,要总述 x1 对 y 的影响,比较典型地做法是在 x2 处估计上式;
待补充
习题






T分布表
