GraphSAGE【文献阅读笔记】
GraphSAGE模型
paper:《Inductive Representation Learning on Large Graphs》。
Hamilton W, Ying Z, Leskovec J. Inductive representation learning on large graphs[C]//Advances in neural information processing systems. 2017: 1024-1034.
因为要进行实验,所以重点关注的模型和实验部分。
文章目录
- GraphSAGE模型
-
- Abstract
- 1 Introduction
- 2 Related work
- 3 Proposed method: GraphSAGE
-
- 3.1 Embedding generation (i.e., forward propagation) algorithm
- 3.2 Learning the parameters of GraphSAGE
- 3.3 Aggregator Architectures
- 4 Experiments
-
- 4.1 Inductive learning on evolving graphs: Citation and Reddit data
- 4.2 Generalizing across graphs: Protein-protein interactions
- 4.3 Runtime and parameter sensitivity
- 4.4 Summary comparison between the different aggregator architectures
- 5 Theoretical analysis
- 6 Conclusion
- Appendices
Abstract
两个比较重要的概念:
- transductive:直推式学习,训练时所有节点(数据)均可见
- inductive:归纳学习,用于测试的节点(数据)在训练时不可见(unseen)。
之前的一些模型基本都是transductive的,而本文提出的GraphSAGE模型是inductive的——通过采样+聚合邻居来学习节点嵌入表示,最终的测试是对于3个数据集的节点分类任务。
知乎:如何理解 inductive learning 与 transductive learning?
1 Introduction
废话就不多说了。
本文的工作:将Kipf等人的GCN模型扩展到inductive unsupervised learning,并且提出使用可学习聚合器的通用模型框架GraphSAGE。
Present work
核心思想:采样+聚合+更新
(测试时,用训练好的model为unseen节点生成嵌入表示)
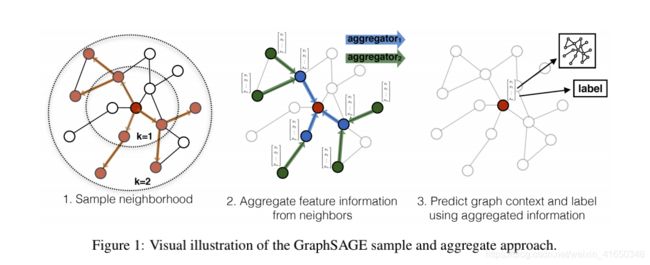
2 Related work
之前的相关工作和GraphSAGE模型息息相关:
Factorization-based embedding approaches
基于因子分解的方法,主要是随机游走和矩阵分解。
和它们不同,GraphSAGE利用特征信息来为unseen节点训练模型。
Supervised learning over graphs
和图级任务不同,本次工作主要是面向单个节点的嵌入表示(node-level)。
Graph convolutional networks
GraphSAGE模型和Kipf等人的GCN模型密切相关。
3 Proposed method: GraphSAGE
重点来了!!!
3.1 Embedding generation (i.e., forward propagation) algorithm
前向传播算法,假设模型的参数已知(随机初始化,之后再使用SGD更新)。
其中模型的参数主要是:每一层的聚合函数 A g g r e g a t e k Aggregate_k Aggregatek中的参数和每一层的权重 W k W^k Wk。
算法1是full-batch的算法,算法2(附录A)是mini-batch的算法,实验中肯定要使用minibatch,因此算法2是事实上的前向传播算法。

注意:算法1中用到的是全节点集 V \mathcal V V,并且 N ( v ) N(v) N(v)一开始是全邻居集,后面重载定义为每层采样固定数量的邻居。算法1符合消息传递框架,也是比较好理解的。

算法2理解起来就有一些绕了,特别是采样阶段“倒推”求解的骚操作,让人直呼好家伙。
相比之下,算法2增加了采样阶段,也是因为采样,后面的聚合阶段也有小小的改动(不过基本和算法1一致)。
下面主要来讲一讲如何进行采样。这里的采样和邻居采样有关,但其实又不太一样。初始给出一个小批量节点集 β \beta β(可以理解为shuffle后dataloader提取的一个batch),记住,这个集合很重要,在这个batch当中,我们最终只去学习 β \beta β内节点的嵌入表示,而非全部节点。因此,最后一层(第K层)需要采样的节点集 β K \beta^K βK就是 β \beta β。
但是,随之而来的一个问题是,我虽然只学习 β \beta β内的节点,但是我在聚合阶段需要它们的邻居啊,因此第k-1层采样的节点集一定要包含第k层计算所用到的所有节点(邻居)。基于这种思想,采样阶段才会搞出“倒推”计算的骚操作——从最后一层K开始推,依次将本层计算所需要的(邻居)节点加入到集合中,生成前一层的节点集,直到 β 0 \beta^0 β0为止。因此,有如下的关系: ∣ β 0 ∣ ⊇ . . . ⊇ ∣ β K ∣ |\beta^0|\supseteq...\supseteq|\beta^K| ∣β0∣⊇...⊇∣βK∣。
还有一点需要注意,就是邻居采样函数 N k ( u ) N_k(u) Nk(u)。它是一个决策函数,用来确定节点邻居的随机样本。每一层的 N k ( u ) N_k(u) Nk(u)相互独立,它为每个节点u采样固定大小(数量)的邻居,第k层每个节点采样的邻居数量用 S k S_k Sk表示。最后一层的 S K = ∣ β ∣ S_K=|\beta| SK=∣β∣,每层每个节点都采样 S k S_k Sk个邻居节点,依次往前推,算法的数量级大约在 O ( ∏ k = 1 K S k ) O(\prod_{k=1}^K S_k) O(∏k=1KSk),这要比full-batch好太多了。
之后,在聚合阶段中,因为每层的节点集都被提前计算出来了,在每一层中我们就直接使用 β k \beta^k βk来进行各种操作而非全集 V \mathcal V V。
不得不说,虽然有点绕,但是算法设计的还真是挺巧妙的。
Relation to the Weisfeiler-Lehman Isomorphism Test
GraphSAGE模型是WL算法的连续近似。
Neighborhood definition
在某一层中,为每个节点采样固定数量的邻居。模型的层数K和每层采样的邻居数量 S k S_k Sk都是由用户定义的常数,本实验中发现 K = 2 , S 1 ⋅ S 2 ≤ 500 K=2,S_1\cdot S_2\le500 K=2,S1⋅S2≤500效果会比较好。
除了在算法中进行固定大小的采样,为了提升计算效率,一般还需要在算法开始之前对数据集中图的边进行下采样(downsample),以保证每个节点的度数不超过128。下采样之后,我们就可以用邻接表来存储图,这样不论是时间还是空间复杂度都变得更低。
3.2 Learning the parameters of GraphSAGE
要分为2种情况:
- 完全无监督:
使用的是负采样下的交叉熵损失。节点对(u,v)代表从节点u出发的固定长度的随机游走序列中出现了节点v。附录C:在实验中,运行50次长度为5的随机游走来得到节点对。 P n P_n Pn代表负样本 v n v_n vn的分布。附录C:在实验中,使用 P n P_n Pn=上下文分布(context distribution)为每个节点采样Q=20个负样本,并且根据节点的度进行平滑处理?,平滑参数为0.75。
直觉:附近的节点应该有相似的表示,借鉴了GAE中的重构思想并且和node2vec的损失函数很相似,后面一项可以看作是噪声。
J G ( z u ) = − log ( σ ( z u T z v ) ) − Q ⋅ E v n ∼ P n ( V ) [ log ( σ ( − z u T z v n ) ) ] (1) J_G(z_u)=-\log(\sigma(z_u^Tz_v))-Q \cdot \mathbb E_{v_n\sim P_n(V)}[\log(\sigma(-z_u^Tz_{v_n}))] \tag{1} JG(zu)=−log(σ(zuTzv))−Q⋅Evn∼Pn(V)[log(σ(−zuTzvn))](1) - 监督:
可以将以上的损失函数,替换或者增加为监督学习中特定任务的目标,比如说针对节点label的分类交叉熵损失等等。
3.3 Aggregator Architectures
提供了三种具有排列不变性且可训练的聚合函数 A g g r e g a t e k Aggregate_k Aggregatek,但实际上算上归纳版本的GCN,应该可以算是4个模型。
- Mean aggregator.(不具有可学习的参数)
聚合器为逐元素平均,并且保留了skip-connection的模型被称为GraphSAGE-mean。
A g g r e g a t e k = m e a n ( h u k − 1 , ∀ u ∈ N ( v ) ) (2) Aggregate_k=mean(h_u^{k-1},\forall u \in N(v)) \tag{2} Aggregatek=mean(huk−1,∀u∈N(v))(2)
(类似GCN模型)进一步使用self-loop进行简化(取消了skip-connection)的模型被称为GraphSAGE-GCN模型。
h v k = σ ( W ⋅ m e a n ( h u k − 1 , ∀ u ∈ { N ( v ) ∪ v } ) ) (3) h_v^k=\sigma(W\cdot mean(h_u^{k-1},\forall u \in \{N(v)\cup v\} )) \tag{3} hvk=σ(W⋅mean(huk−1,∀u∈{N(v)∪v}))(3) - LSTM aggregator.(不满足排列不变性)
使用了LSTM并通过随机排列来(强行)满足排列不变性,这种模型被称为GraphSAGE-LSTM。 - Pooling aggregator.(既有可学习的参数,又满足排列不变性)
先将所有需要聚合的邻居节点嵌入通过一个FC层(单层MLP),再将结果逐元素取max或mean,这种模型被称为GraphSAGE-pool。
A g g r e g a t e k = m a x ( { σ ( W p o o l h u k − 1 + b ) , ∀ u ∈ N ( v ) } ) (4) Aggregate_k=max\left(\{\sigma(W_{pool}h_u^{k-1}+b),\forall u \in N(v)\}\right) \tag{4} Aggregatek=max({σ(Wpoolhuk−1+b),∀u∈N(v)})(4)
4 Experiments
关于实验,分别对citation、Reddit和PPI数据集进行节点分类任务。
Experimental set-up.
对比实验,将4个baseline和4个GraphSAGE变体模型进行对比。
4个baseline:
- 随机分类器Random
- 基于节点特征的逻辑斯蒂回归Raw feature
- 基于因子分解的DeepWalk
- 使用了节点特征的拼接版本DeepWalk+feature
4个GraphSAGE变体:
- GraphSAGE-GCN
- GraphSAGE-mean
- GraphSAGE-LSTM
- GraphSAGE-pool
并且,每个数据集都执行无监督学习和监督学习2个版本
- 无监督学习的损失函数:公式(1)
- 监督学习的损失函数:分类交叉熵损失
DeepWalk只能在简单图(citation、Reddit)上执行(附录C有复现的细节),而不能再多关系图上执行(附录D)。
此外,一些其他的超参数取值:(附录C+第4部分)
| 超参数 | 取值(范围) |
|---|---|
| σ \sigma σ | RELU |
| K | 2 |
| S 1 S_1 S1 | 25 |
| S 2 S_2 S2 | 10 |
| h v k h_v^k hvk的维度 | 256 |
| 监督模型的学习率(除DeepWalk) | { 0.01 , 0.001 , 0.0001 } \{0.01,0.001,0.0001\} {0.01,0.001,0.0001} |
| 无监督模型的学习率(除DeepWalk) | { 2 × 1 0 − 6 , 2 × 1 0 − 7 , 2 × 1 0 − 8 } \{2\times 10^{-6},2\times 10^{-7},2\times 10^{-8}\} {2×10−6,2×10−7,2×10−8} |
| DeepWalk模型的学习率 | { 0.2 , 0.4 , 0.8 } \{0.2,0.4,0.8\} {0.2,0.4,0.8} |
| 优化器(除DeepWalk) | Adam |
| 优化器(DeepWalk) | vanilla |
| 训练批大小(除DeepWalk) | 512 |
| 训练批大小(DeepWalk) | 64 |
| 池化维度 | 「1024,512」 |
| LSTM隐藏层维度 | 「256,128」 |
| 负采样数量Q | 20 |
注意:为了保证公平性,minibatch操作、损失函数、邻居采样等操作都要一致,但是为了防止“hyperparameter hacking”的发生,对于不同的模型我们需要使用最适合各自的超参数,因此学习率等超参数才有了一个范围。这些超参数集都是根据早期的验证测试得出的,参与其中的这部分数据集也会被排除在正式的训练和测试之外。(附录B)
4.1 Inductive learning on evolving graphs: Citation and Reddit data
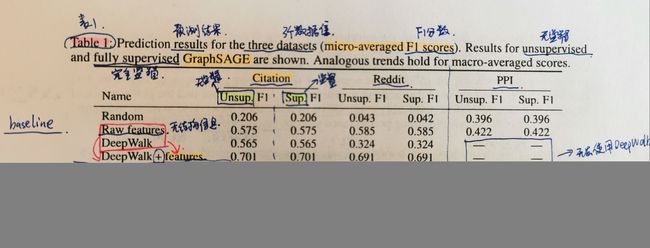
对于两个简单图数据集citation和Reddit,测试时是对同一张图中的unseen节点进行归纳。
- Citation data.
使用的是2000-2005年间的汤森路透社Web of Science核心集合的引文数据(WoS)。(附录B)
数据集划分。
train:2000-2004
test:2005(70%)
validation:2005(30%) - Reddit data.
2014.9Reddit论坛的帖子。(附录B)
数据集的划分。
train:20天
test:剩下的天数(70%)
validation:剩下的天数(30%)
结果分析:从表1中可以看出GraphSAGE模型明显好于之前的模型,并且无监督学习几乎和监督学习一样有竞争力。
4.2 Generalizing across graphs: Protein-protein interactions
对于多关系图PPI数据集,测试时是对unseen的图(不同的图)进行归纳。
- PPI.
蛋白质分子之间的作用图。
数据及的划分:20-2-2。
可以发现LSTM-和pool-的表现要优于GCN-和mean-。
4.3 Runtime and parameter sensitivity
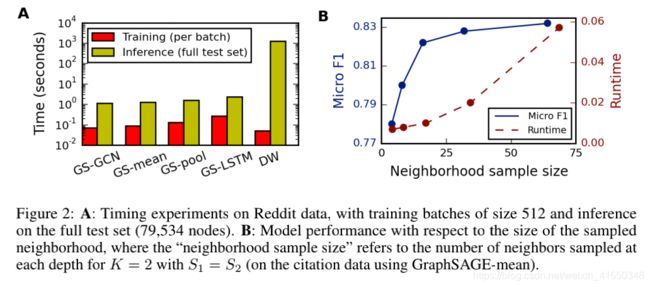
运行时间和参数灵敏度分析。
结论:虽然子采样导致了GraphSAGE模型较大的方差,但是它仍然在提升运行效率的同时保持了较高的准确率。
4.4 Summary comparison between the different aggregator architectures
不同GraphSAGE模型变体的评价。
结论:GraphSAGE-pool总体上略占优势。
5 Theoretical analysis
理论分析:GraphSAGE也能够学习到结构信息(附录E)。
6 Conclusion
本文提出了GraphSAGE模型。未来的方向可以从非均匀的邻居采样入手。
Appendices
本文的附录A、C相当有价值。