联邦学习((Federated Learning,FL)
每日一诗:
题竹(十三岁应试作于楚王孙园亭)
——明*张居正
绿遍潇湘外,疏林玉露寒。
凤毛丛劲节,只上尽头竿。
近期在阅读联邦学习领域相关文献,简单介绍如下文。本文仅供学习,无其它用途。如有错误,敬请批评指正!
一、联邦学习(Federated Learning,FL):
举目四望皆”联邦“,“信息孤岛”尽凉凉
1. 通俗理解:
传统的机器学习算法需要用户将源数据上传 到高算力的云服务器上集中训练,这种方式导致 了数据流向的不可控和敏感数据泄露问题,联邦学习联邦学习能够在多方数据源聚合的场景下协同训练全局最优模型,将机器学习的数据存储和模型训练阶段转移至本地用户,仅与中心服务器交互模型更新的方式有效保障了用户的隐私安全
2. 机器学习技术的发展过程中面临两大挑战:
一是数据安全难以得到保障,隐私数据泄 露问题亟待解决;
二是网络安全隔离和行业隐私,不同行业、部门之间存在数据壁垒,数据形成“孤岛”无法安全共享
3. 联邦学习特点:
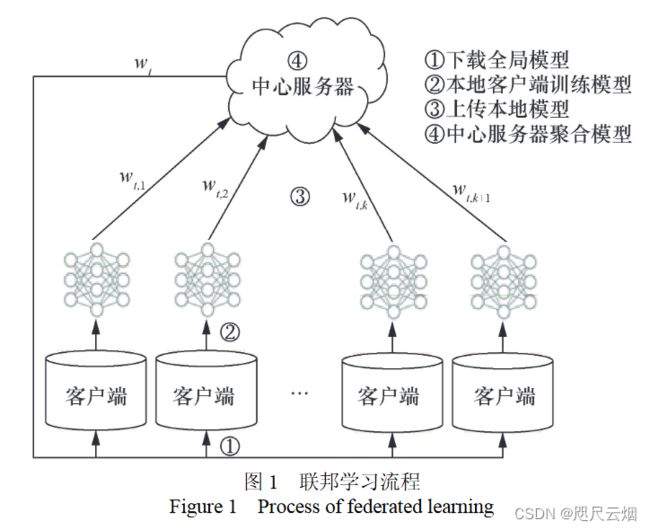
1) 参与联邦学习的原始数据都保留在本地客户端, 与中心服务器交互的只是模型更新信息
2) 联邦 学习的参与方联合训练出的模型 w 将被各方共 享
3) 联邦学习最终的模型精度与集中式机器学 习相似
4)联邦学习参与方的训练数据质量越高,全局模型精度越高
4. 联邦学习流程:

机器学习得目标函数优化通常是让损失函数达到最小值:




5. 联邦学习的分类
一个 完整的训练数据集 D 应由(I,Y,X)构成,假设 Dm代表客户端 m 持有的数据,I 表示样本 ID,Y 表示数据集的标 签信息,X 表示数据集的特征信息.
| 横向联邦学习 | 纵向联邦学习 | 联邦迁移学习 | |
|---|---|---|---|
| 特点 | 数据集特征 X 和标签信息Y相同,但样本ID不同 | 各数据集特征 X 和标签信息Y不同,但样本ID信息相同 | 数据集特征 X、标 签信息 Y 和样本 ID 信息都不同 |
| 举例说明 | 在用户输入法数据上训练的下一词预测模型。不同的手机用户具 有相同的数据特征,数百万个安卓手机在云服务 器的协调下训练共享的全局模型,其本质是将多 方对不同目标的相同特征描述进行训练提取。 | 同一地区的银行和电商平台: 银行拥有当地用户的收支记录 x1,电商平台拥有 用户的消费记录和浏览记录 x2,双方想通过数据 联合对客户信用 Y 进行评级,从而提供更个性化 的服务,其本质是将多方对相同目标的不同特征 描述进行训练提取。 | 中国的电商平台与其他国家银行之间的数据迁移,由于跨部门跨国的数据交流。 |
| X、Y看作数据集,ID看作产生数据集的对象 | 数据集基本相同(词组习惯),但是产生数据集的对象(不同安卓设备)不同 | 数据集不同(银行、电商平台业务不同 所建立的数据库不同),但是产生数据集合的对象(顾客)基本相同(同一地区 可认为两大平台服务的对象群体基本相同) | 数据集不同(两平台数据库差异),服务对象不同(不同国家) |
二、challenges and countermeasure:
1. 通信效率短板
1)challenges:
传统的分布式框架算法在处理非独立同分布数据(IID)时会产生训练过程难以收敛、通信轮数多的问题
动辄万计的客户端很容易对通信网络造成巨大的带宽负担相邻的模型更新中可
能包含许多重复更新或者与全局模型不相关的更新
2)对策:
算法优化:开发适合处理 Non-IID 和非 平衡分布数据的模型训练算法,减少用于传输的模型数据大小,加快模型训练的收敛速度。
压缩数据包:压缩能够有效降低通信数据大 小,但对数据的压缩会导致部分信息的丢失, 此类方法需要在模型精度和通信效率之间寻找最佳的平衡。
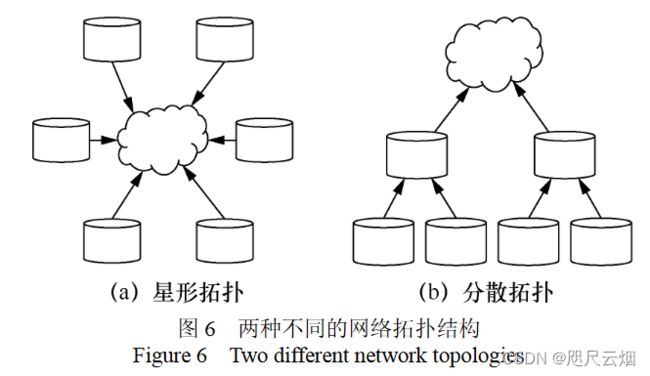
分散训练:将联邦学习框架分层分级 星形拓扑改成分散拓扑, 降低中心服务器的通信负担
2. 隐私安全隐患
1)challenges
理想情况下联邦学习源数据不出本地仅仅交换模型梯度信息,以此保护本地敏感数据
真实情况下模型反演攻击、 成员推理攻击、模型推理攻击层出不穷,参与训练的客户端动机难以判断,中心服务器的可信程度不确定攻击者可以通过客户端上传的梯度信息间接推出标签信息和数据集的成员信息

3种主要威胁:
恶意客户端修改模型更新,破坏全局模型聚合;
恶意分析者通过对模型更新信息的分析推测源数 据隐私信息;
恶意服务器企图获得客户端的源数据
2) 对策:
差分隐私(DP,differential privacy) 差分隐私算法的噪声机制分为指数噪声、Laplace 噪声和高斯噪声,其中,指数噪声主要用于 处理 离散数据集,Laplace 噪声和高斯噪声主要用于处 理连续数据集。
安全多方计算(MPC,secure multi-party computation)
同态加密(HE,homomorphic encryption)可以解决上述问题
3. 激励机制设置/客户端信誉等级划分
区块链是比特币的底层技术, 它作为一种安全可靠、不可篡改和支持查询验证的分布式分类账,被应用于解决各类数据安全存储和信任问题
联邦学习与区块链的结合使系统成为一个完善的闭环学习机制。一方面,联邦学习技术能够为具有隐私数据的参与方提供跨域安全共享方案;另一方面,区块链技术作为核心数据库为参与方提供了安全存储、信任管理、细粒度区分和激励回报等应用需求,促使拥有数据的用户积极参与到数据联邦中。
三、研究热点:
-
系统异构:
参与训练的客户端之间硬件配置、网络带宽、电池容量不同
终端设备的计算能力、通信速度 和存储能力各不相同
客户端并不一定可靠, 随时可能因为网络故障、算力限制等问题退出现有训练
适用于系统异构的联邦 学习算法必须满足 3 点要求:
客户端的低参与率;
兼容不同的硬件结构;
能够容忍训练设备的中途退出。
-
统计异构:
不同的终端设备通常使用各式各样的方式生成、存储和传输数据,各设备之间数据的特征和体量可能有很大的不同,呈现Non-IID分布和非平衡分布。
-
无线通信:
无线信道的带宽容量有限,因此在发送信息之前,需要对模型更新进行量化压缩,在这种模式下, 一个重要的考虑因素是存在量化误差时模型更新的鲁棒性。无线通信中复杂的噪声和干扰也加剧信道瓶颈。
四、前景展望:
-
边缘计算+联邦学习:
联邦学习作为 边缘计算的操作系统,提供了一种各方协作与共 享的协议规范,它能够让边缘设备在不向云端设 备发送源数据的情况下,合作训练出一个最优的 全局机器学习模型

-
联邦学习+智慧医疗:
由于医疗机构的数据对于隐私和 安全的敏感性,医疗数据中心很难收集到足够数量的、特征丰富的、可以全面描述患者症状的数 据,而性能良好的机器学习模型往往需要来自多 个数据源,包括医疗报告、病例特征、生理指标、基因序列等。
联邦迁移学习是解决这类问题的有 效方法,无须交换各医疗机构的私有数据,协同 所有的训练参与方训练一个共享模型,同时迁移 学习技术可以扩展训练数据的样本空间和特征空 间,有效降低各医疗机构之间样本分布的差异性。打破“信息孤岛”
-
联邦学习+金融:
对客户“肖像”特征的描 述通常包括资质信息、购买能力、购买偏好及商 品特征等,而这些信息分别分布在银行、电子商 务平台和用户的私人社交网络中。出于隐私安全 的考虑,将三方数据聚合并不现实,而联邦学习 为构建跨企业、跨数据平台以及跨领域的大数据 和 AI 系统提供了良好的技术支持。
-
联邦学习+智慧城市:
在城市的不同信息部门中,如后勤、应急、 维稳、安保等,会产生大量的异构数据,形成多 个数据孤岛,无法整合利用。联邦学习的异构数 据处理能力能够帮助人们创造迅速响应市民需求 的智慧城市,解决数据“孤岛”问题,同时基于 智慧城市构建的机器学习模型为企业提供个性化 服务
Reference:
周传鑫, 孙奕, 汪德刚,等. 联邦学习研究综述[J]. 网络与信息安全学报.
Zhao, Yue, et al. “Federated learning with non-iid data.” arXiv preprint arXiv:1806.00582 (2018).
Sattler, Felix, et al. “Robust and communication-efficient federated learning from non-iid data.” IEEE transactions on neural networks and learning systems 31.9 (2019): 3400-3413.