Paddle深度学习①---深度学习里的Hello word
Paddle深度学习---深度学习里的Hello word
- 一、深度学习里的Hello word---波士顿房价预测问题分析
-
- 1、线性回归模型
- 2、线性回归模型的神经网络结构
- 二、波士顿房价问题的实现步骤
-
- 1、构建波士顿房价预测任务的神经网络模型
- 2、数据处理
- 3、模型设计
- 4、训练配置
- 5、开始训练
-
- 1. 我们可以通过程序查看每个变量的数据和维度。
- 2. 当只有一个样本时,可以计算某个 w j w_j wj,比如 w 0 w_0 w0的梯度。
- 3. 使用Numpy进行梯度计算
- 4. 确定损失函数更小的点
- 6.训练扩展到全部参数
很早就听说过飞浆这个深度学习框架,只是一直没有时间去学习。最近在家实在是没什么意思,还有好久才开学。于是想趁着这21天来学习一下PaddlePaddle。
本人纯小白,有问题麻烦在下面告诉一下。
注:本文所有内容以及数据均来自AI Studio。
一、深度学习里的Hello word—波士顿房价预测问题分析
波士顿房价预测是一个经典的机器学习任务,类似于程序员世界的“Hello World”。和大家对房价的普遍认知相同,波士顿地区的房价是由诸多因素影响的。该数据集统计了13种可能影响房价的因素和该类型房屋的均价,期望构建一个基于13个因素进行房价预测的模型,如 图1 所示。
图1:波士顿房价影响因素示意图
对于预测问题,可以根据预测输出的类型是连续的实数值,还是离散的标签,区分为回归任务和分类任务。因为房价是一个连续值,所以房价预测显然是一个回归任务。下面我们尝试用最简单的线性回归模型解决这个问题,并用神经网络来实现这个模型。
1、线性回归模型
假设房价和各影响因素之间能够用线性关系来描述:
y = ∑ j = 1 M x j w j + b y = {\sum_{j=1}^Mx_j w_j} + b y=j=1∑Mxjwj+b
模型的求解即是通过数据拟合出每个 w j w_j wj和 b b b。其中, w j w_j wj和 b b b分别表示该线性模型的权重和偏置。一维情况下, w j w_j wj 和 b b b 是直线的斜率和截距。
线性回归模型使用均方误差作为损失函数(Loss),用以衡量预测房价和真实房价的差异,公式如下:
M S E = 1 n ∑ i = 1 n ( Y i ^ − Y i ) 2 MSE = \frac{1}{n} \sum_{i=1}^n(\hat{Y_i} - {Y_i})^{2} MSE=n1i=1∑n(Yi^−Yi)2
2、线性回归模型的神经网络结构
神经网络的标准结构中每个神经元由加权和与非线性变换构成,然后将多个神经元分层的摆放并连接形成神经网络。线性回归模型可以认为是神经网络模型的一种极简特例,是一个只有加权和、没有非线性变换的神经元(无需形成网络),如 图2 所示。
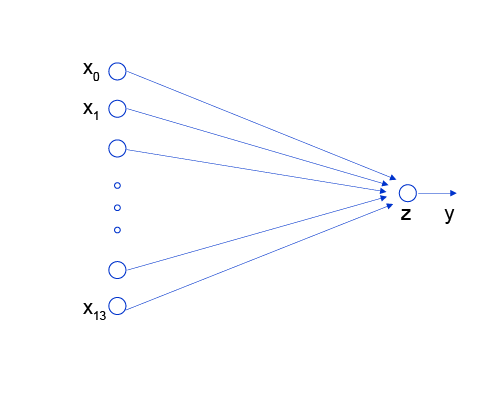
图2:线性回归模型的神经网络结构
二、波士顿房价问题的实现步骤
1、构建波士顿房价预测任务的神经网络模型
深度学习不仅实现了模型的端到端学习,还推动了人工智能进入工业大生产阶段,产生了标准化、自动化和模块化的通用框架。不同场景的深度学习模型具备一定的通用性,五个步骤即可完成模型的构建和训练,如 图3 所示。
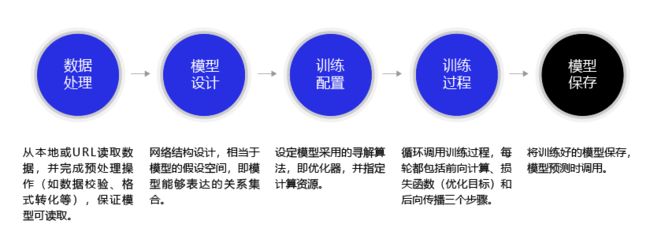
图3:构建神经网络/深度学习模型的基本步骤
正是由于深度学习的建模和训练的过程存在通用性,在构建不同的模型时,只有模型三要素不同,其它步骤基本一致,深度学习框架才有用武之地。
2、数据处理
- 读入数据
通过如下代码读入数据,了解下波士顿房价的数据集结构
# 导入需要用到的package
import numpy as np
import json
# 读入训练数据
datafile = './work/housing.data'
data = np.fromfile(datafile, sep=' ')
data
array([6.320e-03, 1.800e+01, 2.310e+00, …, 3.969e+02, 7.880e+00,
1.190e+01])
- 数据形状变换
由于读入的原始数据是1维的,所有数据都连在一起。因此需要我们将数据的形状进行变换,形成一个2维的矩阵,每行为一个数据样本(14个值),每个数据样本包含13个X(影响房价的特征)和一个Y(该类型房屋的均价)。
# 读入之后的数据被转化成1维array,其中array的第0-13项是第一条数据,第14-27项是第二条数据,以此类推....
# 这里对原始数据做reshape,变成N x 14的形式
feature_names = [ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE','DIS',
'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV' ]
feature_num = len(feature_names)
data = data.reshape([data.shape[0] // feature_num, feature_num])
# 查看数据
x = data[0]
print(x.shape)
print(x)
(14,)
[6.320e-03 1.800e+01 2.310e+00 0.000e+00 5.380e-01 6.575e+00 6.520e+01
4.090e+00 1.000e+00 2.960e+02 1.530e+01 3.969e+02 4.980e+00 2.400e+01]
- 数据集划分
由于我们拿到手的数据是有限的,而如果将所有的数据用于训练,那么就没有可用的数据来测试,所以选择拿出80%的数据用于训练,而20%的数据用于测试
ratio = 0.8
offset = int(data.shape[0] * ratio)
training_data = data[:offset]
training_data.shape
(404, 14)
- 数据归一化处理
对每个特征进行归一化处理,使得每个特征的取值缩放到0~1之间。这样做有两个好处:一是模型训练更高效;二是特征前的权重大小可以代表该变量对预测结果的贡献度(因为每个特征值本身的范围相同)。
# 计算train数据集的最大值,最小值,平均值
maximums, minimums, avgs = \
training_data.max(axis=0), \
training_data.min(axis=0), \
training_data.sum(axis=0) / training_data.shape[0]
# 对数据进行归一化处理
for i in range(feature_num):
#print(maximums[i], minimums[i], avgs[i])
data[:, i] = (data[:, i] - avgs[i]) / (maximums[i] - minimums[i])
- 封装函数
def load_data():
# 从文件导入数据
datafile = './work/housing.data'
data = np.fromfile(datafile, sep=' ')
# 每条数据包括14项,其中前面13项是影响因素,第14项是相应的房屋价格中位数
feature_names = [ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', \
'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV' ]
feature_num = len(feature_names)
# 将原始数据进行Reshape,变成[N, 14]这样的形状
data = data.reshape([data.shape[0] // feature_num, feature_num])
# 将原数据集拆分成训练集和测试集
# 这里使用80%的数据做训练,20%的数据做测试
# 测试集和训练集必须是没有交集的
ratio = 0.8
offset = int(data.shape[0] * ratio)
training_data = data[:offset]
# 计算训练集的最大值,最小值,平均值
maximums, minimums, avgs = training_data.max(axis=0), training_data.min(axis=0), \
training_data.sum(axis=0) / training_data.shape[0]
# 对数据进行归一化处理
for i in range(feature_num):
#print(maximums[i], minimums[i], avgs[i])
data[:, i] = (data[:, i] - avgs[i]) / (maximums[i] - minimums[i])
# 训练集和测试集的划分比例
training_data = data[:offset]
test_data = data[offset:]
return training_data, test_data
# 获取数据
training_data, test_data = load_data()
x = training_data[:, :-1]
y = training_data[:, -1:]
# 查看数据
print(x[0])
print(y[0])
[-0.02146321 0.03767327 -0.28552309 -0.08663366 0.01289726 0.04634817
0.00795597 -0.00765794 -0.25172191 -0.11881188 -0.29002528 0.0519112
-0.17590923]
[-0.00390539]
3、模型设计
模型设计是深度学习模型关键要素之一,也称为网络结构设计,相当于模型的假设空间,即实现模型“前向计算”(从输入到输出)的过程。
如果将输入特征和输出预测值均以向量表示,输入特征 x x x有13个分量, y y y有1个分量,那么参数权重的形状(shape)是 13 × 1 13\times1 13×1。假设我们以如下任意数字赋值参数做初始化:
w = [ 0.1 , 0.2 , 0.3 , 0.4 , 0.5 , 0.6 , 0.7 , 0.8 , − 0.1 , − 0.2 , − 0.3 , − 0.4 , 0.0 ] w=[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, -0.1, -0.2, -0.3, -0.4, 0.0] w=[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,−0.1,−0.2,−0.3,−0.4,0.0]
w = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, -0.1, -0.2, -0.3, -0.4, 0.0]
w = np.array(w).reshape([13, 1])
- 取出第1条样本数据,观察样本的特征向量与参数向量相乘的结果。
x1=x[0]
t = np.dot(x1, w)
print(t)
[0.03395597]
- 完整的线性回归公式,还需要初始化偏移量bbb,同样随意赋初值-0.2。那么,线性回归模型的完整输出是z=t+bz=t+bz=t+b,这个从特征和参数计算输出值的过程称为“前向计算”。
b = -0.2
z = t + b
print(z)
[-0.16604403]
- 将上述计算预测输出的过程以“类和对象”的方式来描述,类成员变量有参数www和bbb。通过写一个forward函数完成上述从特征和参数到输出预测值的计算过程,代码如下所示。
class Network(object):
def __init__(self, num_of_weights):
# 随机产生w的初始值
# 为了保持程序每次运行结果的一致性,
# 此处设置固定的随机数种子
np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1)
self.b = 0.
def forward(self, x):
z = np.dot(x, self.w) + self.b
return z
- 基于Network类的定义,模型的计算过程如下所示。
net = Network(13)
x1 = x[0]
y1 = y[0]
z = net.forward(x1)
print(z)
print(y1)
[-0.63182506]
[-0.00390539]
4、训练配置
模型设计完成后,需要通过训练配置寻找模型的最优值,即通过损失函数来衡量模型的好坏。
通过模型计算 x 1 x_1 x1表示的影响因素所对应的房价应该是 z z z, 但实际数据告诉我们房价是 y y y。这时我们需要有某种指标来衡量预测值 z z z跟真实值 y y y之间的差距。对于回归问题,最常采用的衡量方法是使用均方误差作为评价模型好坏的指标,具体定义如下:
L o s s = ( y − z ) 2 Loss = (y - z)^2 Loss=(y−z)2
因为计算损失函数时需要把每个样本的损失函数值都考虑到,所以我们需要对单个样本的损失函数进行求和,并除以样本总数 N N N。
L o s s = 1 N ∑ i = 1 N ( y i − z i ) 2 Loss= \frac{1}{N}\sum_{i=1}^N{(y_i - z_i)^2} Loss=N1i=1∑N(yi−zi)2
在Network类下面添加损失函数的计算过程如下:
class Network(object):
def __init__(self, num_of_weights):
# 随机产生w的初始值
# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子
np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1)
self.b = 0.
def forward(self, x):
z = np.dot(x, self.w) + self.b
return z
def loss(self, z, y):
error = z - y
cost = error * error
cost = np.mean(cost)
return cost
net = Network(13)
# 此处可以一次性计算多个样本的预测值和损失函数
x1 = x[0:3]
y1 = y[0:3]
z = net.forward(x1)
print('predict: ', z)
loss = net.loss(z, y1)
print('loss:', loss)
predict: [[-0.63182506]
[-0.55793096]
[-1.00062009]]
loss: 0.7229825055441156
5、开始训练
上述计算过程描述了如何构建神经网络,通过神经网络完成预测值和损失函数的计算。接下来介绍如何求解参数w和b的数值,这个过程也称为模型训练过程。训练的目标则是选择出一组(w, b)是的损失函数 L L L最小。
这里我们选取梯度下降法来进行训练
1. 我们可以通过程序查看每个变量的数据和维度。
x1 = x[0]
y1 = y[0]
z1 = net.forward(x1)
print('x1 {}, shape {}'.format(x1, x1.shape))
print('y1 {}, shape {}'.format(y1, y1.shape))
print('z1 {}, shape {}'.format(z1, z1.shape))
x1 [-0.02146321 0.03767327 -0.28552309 -0.08663366 0.01289726 0.04634817
0.00795597 -0.00765794 -0.25172191 -0.11881188 -0.29002528 0.0519112
-0.17590923], shape (13,)
y1 [-0.00390539], shape (1,)
z1 [-12.05947643], shape (1,)
2. 当只有一个样本时,可以计算某个 w j w_j wj,比如 w 0 w_0 w0的梯度。
gradient_w0 = (z1 - y1) * x1[0]
print('gradient_w0 {}'.format(gradient_w0))
gradient_w0 [0.25875126]
3. 使用Numpy进行梯度计算
gradient_w = (z1 - y1) * x1
print('gradient_w_by_sample1 {}, gradient.shape {}'.format(gradient_w, gradient_w.shape))
gradient_w_by_sample1 [ 0.25875126 -0.45417275 3.44214394 1.04441828 -0.15548386 -0.55875363
-0.09591377 0.09232085 3.03465138 1.43234507 3.49642036 -0.62581917
2.12068622], gradient.shape (13,)
输入数据中有多个样本,每个样本都对梯度有贡献。如上代码计算了只有样本1时的梯度值,同样的计算方法也可以计算样本2和样本3对梯度的贡献。
x2 = x[1]
y2 = y[1]
z2 = net.forward(x2)
gradient_w = (z2 - y2) * x2
print('gradient_w_by_sample2 {}, gradient.shape {}'.format(gradient_w, gradient_w.shape))
gradient_w_by_sample2 [ 0.7329239 4.91417754 3.33394253 2.9912385 4.45673435 -0.58146277
-5.14623287 -2.4894594 7.19011988 7.99471607 0.83100061 -1.79236081
2.11028056], gradient.shape (13,)
聪明的你肯定会想到可以使用for循环把每个样本对梯度的贡献都计算出来,然后再作平均。但是我们不需要这么做,仍然可以使用Numpy的矩阵操作来简化运算,如3个样本的情况。
# 注意这里是一次取出3个样本的数据,不是取出第3个样本
x3samples = x[0:3]
y3samples = y[0:3]
z3samples = net.forward(x3samples)
print('x {}, shape {}'.format(x3samples, x3samples.shape))
print('y {}, shape {}'.format(y3samples, y3samples.shape))
print('z {}, shape {}'.format(z3samples, z3samples.shape))
x [[-0.02146321 0.03767327 -0.28552309 -0.08663366 0.01289726 0.04634817
0.00795597 -0.00765794 -0.25172191 -0.11881188 -0.29002528 0.0519112
-0.17590923]
[-0.02122729 -0.14232673 -0.09655922 -0.08663366 -0.12907805 0.0168406
0.14904763 0.0721009 -0.20824365 -0.23154675 -0.02406783 0.0519112
-0.06111894]
[-0.02122751 -0.14232673 -0.09655922 -0.08663366 -0.12907805 0.1632288
-0.03426854 0.0721009 -0.20824365 -0.23154675 -0.02406783 0.03943037
-0.20212336]], shape (3, 13)
y [[-0.00390539]
[-0.05723872]
[ 0.23387239]], shape (3, 1)
z [[-12.05947643]
[-34.58467747]
[-11.60858134]], shape (3, 1)
上面的x3samples, y3samples, z3samples的第一维大小均为3,表示有3个样本。下面计算这3个样本对梯度的贡献。
gradient_w = (z3samples - y3samples) * x3samples
print('gradient_w {}, gradient.shape {}'.format(gradient_w, gradient_w.shape))
gradient_w [[ 0.25875126 -0.45417275 3.44214394 1.04441828 -0.15548386 -0.55875363
-0.09591377 0.09232085 3.03465138 1.43234507 3.49642036 -0.62581917
2.12068622]
[ 0.7329239 4.91417754 3.33394253 2.9912385 4.45673435 -0.58146277
-5.14623287 -2.4894594 7.19011988 7.99471607 0.83100061 -1.79236081
2.11028056]
[ 0.25138584 1.68549775 1.14349809 1.02595515 1.5286008 -1.93302947
0.4058236 -0.85385157 2.46611579 2.74208162 0.28502219 -0.46695229
2.39363651]], gradient.shape (3, 13)
上面gradient_w的每一行代表了一个样本对梯度的贡献。根据梯度的计算公式,总梯度是对每个样本对梯度贡献的平均值。
∂ L ∂ w j = 1 N ∑ i = 1 N ( z i − y i ) ∂ z i ∂ w j = 1 N ∑ i = 1 N ( z i − y i ) x i j \frac{\partial{L}}{\partial{w_j}} = \frac{1}{N}\sum_{i=1}^N{(z_i - y_i)\frac{\partial{z_i}}{\partial{w_j}}} = \frac{1}{N}\sum_{i=1}^N{(z_i - y_i)x_i^{j}} ∂wj∂L=N1i=1∑N(zi−yi)∂wj∂zi=N1i=1∑N(zi−yi)xij
我们也可以使用Numpy的均值函数来完成此过程:
# axis = 0 表示把每一行做相加然后再除以总的行数
gradient_w = np.mean(gradient_w, axis=0)
print('gradient_w ', gradient_w.shape)
print('w ', net.w.shape)
print(gradient_w)
print(net.w)
gradient_w (13,)
w (13, 1)
[ 1.59697064 -0.92928123 4.72726926 1.65712204 4.96176389 1.18068454
4.55846519 -3.37770889 9.57465893 10.29870662 1.3900257 -0.30152215
1.09276043]
[[ 1.76405235e+00]
[ 4.00157208e-01]
[ 9.78737984e-01]
[ 2.24089320e+00]
[ 1.86755799e+00]
[ 1.59000000e+02]
[ 9.50088418e-01]
[-1.51357208e-01]
[-1.03218852e-01]
[ 1.59000000e+02]
[ 1.44043571e-01]
[ 1.45427351e+00]
[ 7.61037725e-01]]
我们使用Numpy的矩阵操作方便地完成了gradient的计算,但引入了一个问题,gradient_w的形状是(13,),而w的维度是(13, 1)。导致该问题的原因是使用np.mean函数时消除了第0维。为了加减乘除等计算方便,gradient_w和w必须保持一致的形状。因此我们将gradient_w的维度也设置为(13, 1),代码如下:
gradient_w = gradient_w[:, np.newaxis]
print('gradient_w shape', gradient_w.shape)
gradient_w shape (13, 1)
综上,梯度的计算如下:
z = net.forward(x)
gradient_w = (z - y) * x
gradient_w = np.mean(gradient_w, axis=0)
gradient_w = gradient_w[:, np.newaxis]
gradient_w
array([[ 1.59697064],
[-0.92928123],
[ 4.72726926],
[ 1.65712204],
[ 4.96176389],
[ 1.18068454],
[ 4.55846519],
[-3.37770889],
[ 9.57465893],
[10.29870662],
[ 1.3900257 ],
[-0.30152215],
[ 1.09276043]])
将上面计算www和bbb的梯度的过程,写成Network类的gradient函数,实现方法如下所示。
class Network(object):
def __init__(self, num_of_weights):
# 随机产生w的初始值
# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子
np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1)
self.b = 0.
def forward(self, x):
z = np.dot(x, self.w) + self.b
return z
def loss(self, z, y):
error = z - y
num_samples = error.shape[0]
cost = error * error
cost = np.sum(cost) / num_samples
return cost
def gradient(self, x, y):
z = self.forward(x)
gradient_w = (z-y)*x
gradient_w = np.mean(gradient_w, axis=0)
gradient_w = gradient_w[:, np.newaxis]
gradient_b = (z - y)
gradient_b = np.mean(gradient_b)
return gradient_w, gradient_b
# 调用上面定义的gradient函数,计算梯度
# 初始化网络
net = Network(13)
# 设置[w5, w9] = [-100., -100.]
net.w[5] = -100.0
net.w[9] = -100.0
z = net.forward(x)
loss = net.loss(z, y)
gradient_w, gradient_b = net.gradient(x, y)
gradient_w5 = gradient_w[5][0]
gradient_w9 = gradient_w[9][0]
print('point {}, loss {}'.format([net.w[5][0], net.w[9][0]], loss))
print('gradient {}'.format([gradient_w5, gradient_w9]))
point [-100.0, -100.0], loss 686.3005008179159
gradient [-0.850073323995813, -6.138412364807849]
4. 确定损失函数更小的点
下面我们开始研究更新梯度的方法。首先沿着梯度的反方向移动一小步,找到下一个点P1,观察损失函数的变化。
# 在[w5, w9]平面上,沿着梯度的反方向移动到下一个点P1
# 定义移动步长 eta
eta = 0.1
# 更新参数w5和w9
net.w[5] = net.w[5] - eta * gradient_w5
net.w[9] = net.w[9] - eta * gradient_w9
# 重新计算z和loss
z = net.forward(x)
loss = net.loss(z, y)
gradient_w, gradient_b = net.gradient(x, y)
gradient_w5 = gradient_w[5][0]
gradient_w9 = gradient_w[9][0]
print('point {}, loss {}'.format([net.w[5][0], net.w[9][0]], loss))
print('gradient {}'.format([gradient_w5, gradient_w9]))
point [-99.91499266760042, -99.38615876351922], loss 678.6472185028845
gradient [-0.8556356178645292, -6.0932268634065805]
运行上面的代码,可以发现沿着梯度反方向走一小步,下一个点的损失函数的确减少了。感兴趣的话,大家可以尝试不停的点击上面的代码块,观察损失函数是否一直在变小。
在上述代码中,每次更新参数使用的语句:
net.w[5] = net.w[5] - eta * gradient_w5
- 相减:参数需要向梯度的反方向移动。
- eta:控制每次参数值沿着梯度反方向变动的大小,即每次移动的步长,又称为学习率。
大家可以思考下,为什么之前我们要做输入特征的归一化,保持尺度一致?这是为了让统一的步长更加合适。
如 图4 所示,特征输入归一化后,不同参数输出的Loss是一个比较规整的曲线,学习率可以设置成统一的值 ;特征输入未归一化时,不同特征对应的参数所需的步长不一致,尺度较大的参数需要大步长,尺寸较小的参数需要小步长,导致无法设置统一的学习率。
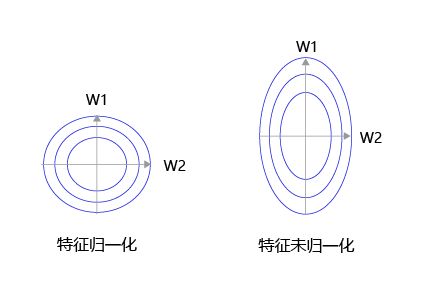
图4:未归一化的特征,会导致不同特征维度的理想步长不同
### 5.代码封装Train函数 将上面的循环计算过程封装在train和update函数中,实现方法如下所示。
class Network(object):
def __init__(self, num_of_weights):
# 随机产生w的初始值
# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子
np.random.seed(0)
self.w = np.random.randn(num_of_weights,1)
self.w[5] = -100.
self.w[9] = -100.
self.b = 0.
def forward(self, x):
z = np.dot(x, self.w) + self.b
return z
def loss(self, z, y):
error = z - y
num_samples = error.shape[0]
cost = error * error
cost = np.sum(cost) / num_samples
return cost
def gradient(self, x, y):
z = self.forward(x)
gradient_w = (z-y)*x
gradient_w = np.mean(gradient_w, axis=0)
gradient_w = gradient_w[:, np.newaxis]
gradient_b = (z - y)
gradient_b = np.mean(gradient_b)
return gradient_w, gradient_b
def update(self, graident_w5, gradient_w9, eta=0.01):
net.w[5] = net.w[5] - eta * gradient_w5
net.w[9] = net.w[9] - eta * gradient_w9
def train(self, x, y, iterations=100, eta=0.01):
points = []
losses = []
for i in range(iterations):
points.append([net.w[5][0], net.w[9][0]])
z = self.forward(x)
L = self.loss(z, y)
gradient_w, gradient_b = self.gradient(x, y)
gradient_w5 = gradient_w[5][0]
gradient_w9 = gradient_w[9][0]
self.update(gradient_w5, gradient_w9, eta)
losses.append(L)
if i % 50 == 0:
print('iter {}, point {}, loss {}'.format(i, [net.w[5][0], net.w[9][0]], L))
return points, losses
# 获取数据
train_data, test_data = load_data()
x = train_data[:, :-1]
y = train_data[:, -1:]
# 创建网络
net = Network(13)
num_iterations=2000
# 启动训练
points, losses = net.train(x, y, iterations=num_iterations, eta=0.01)
# 画出损失函数的变化趋势
plot_x = np.arange(num_iterations)
plot_y = np.array(losses)
plt.plot(plot_x, plot_y)
plt.show()
iter 0, point [-99.99144364382136, -99.93861587635192], loss 686.3005008179159
iter 50, point [-99.56362583488914, -96.92631128470325], loss 649.221346830939
iter 100, point [-99.13580802595692, -94.02279509580971], loss 614.6970095624063
iter 150, point [-98.7079902170247, -91.22404911807594], loss 582.543755023494
iter 200, point [-98.28017240809248, -88.52620357520894], loss 552.5911329872217
iter 250, point [-97.85235459916026, -85.9255316243737], loss 524.6810152322887
iter 300, point [-97.42453679022805, -83.41844407682491], loss 498.6667034691001
iter 350, point [-96.99671898129583, -81.00148431353688], loss 474.4121018974464
iter 400, point [-96.56890117236361, -78.67132338862874], loss 451.7909497114133
iter 450, point [-96.14108336343139, -76.42475531364933], loss 430.68610920670284
iter 500, point [-95.71326555449917, -74.25869251604028], loss 410.988905460488
iter 550, point [-95.28544774556696, -72.17016146534513], loss 392.5985138460824
iter 600, point [-94.85762993663474, -70.15629846096763], loss 375.4213919156372
iter 650, point [-94.42981212770252, -68.21434557551346], loss 359.3707524354014
iter 700, point [-94.0019943187703, -66.34164674796719], loss 344.36607459115214
iter 750, point [-93.57417650983808, -64.53564402117185], loss 330.33265059761464
iter 800, point [-93.14635870090586, -62.793873918279786], loss 317.2011651461846
iter 850, point [-92.71854089197365, -61.11396395304264], loss 304.907305311265
iter 900, point [-92.29072308304143, -59.49362926899678], loss 293.3913987080144
iter 950, point [-91.86290527410921, -57.930669402782904], loss 282.5980778542974
iter 1000, point [-91.43508746517699, -56.4229651670156], loss 272.47596883802515
iter 1050, point [-91.00726965624477, -54.968475648286564], loss 262.9774025287022
iter 1100, point [-90.57945184731255, -53.56523531604897], loss 254.05814669965383
iter 1150, point [-90.15163403838034, -52.21135123828792], loss 245.67715754581488
iter 1200, point [-89.72381622944812, -50.90500040003218], loss 237.796349191773
iter 1250, point [-89.2959984205159, -49.6444271209092], loss 230.3803798866218
iter 1300, point [-88.86818061158368, -48.42794056808474], loss 223.3964536766492
iter 1350, point [-88.44036280265146, -47.2539123610643], loss 216.81413643451378
iter 1400, point [-88.01254499371925, -46.12077426496303], loss 210.60518520483126
iter 1450, point [-87.58472718478703, -45.027015968976976], loss 204.74338990147896
iter 1500, point [-87.15690937585481, -43.9711829469081], loss 199.20442646183588
iter 1550, point [-86.72909156692259, -42.95187439671279], loss 193.96572062803054
iter 1600, point [-86.30127375799037, -41.96774125615467], loss 189.00632158541163
iter 1650, point [-85.87345594905815, -41.017484291751295], loss 184.3067847442463
iter 1700, point [-85.44563814012594, -40.0998522583068], loss 179.84906300239203
iter 1750, point [-85.01782033119372, -39.21364012642417], loss 175.61640587468244
iter 1800, point [-84.5900025222615, -38.35768737548557], loss 171.59326591927967
iter 1850, point [-84.16218471332928, -37.530876349682856], loss 167.76521193253296
iter 1900, point [-83.73436690439706, -36.73213067476985], loss 164.11884842217898
iter 1950, point [-83.30654909546485, -35.96041373329276], loss 160.64174090423475
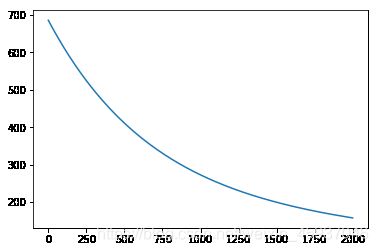
6.训练扩展到全部参数
上面演示的梯度下降的过程仅包含 w 5 w_5 w5和 w 9 w_9 w9两个参数,但房价预测的完整模型,必须要对所有参数 w w w和 b b b进行求解。这需要将Network中的update和train函数进行修改。由于不再限定参与计算的参数(所有参数均参与计算),修改之后的代码反而更加简洁。实现逻辑:“前向计算输出、根据输出和真实值计算Loss、基于Loss和输入计算梯度、根据梯度更新参数值”四个部分反复执行,直到到达参数最优点。具体代码如下所示。
class Network(object):
def __init__(self, num_of_weights):
# 随机产生w的初始值
# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子
np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1)
self.b = 0.
def forward(self, x):
z = np.dot(x, self.w) + self.b
return z
def loss(self, z, y):
error = z - y
num_samples = error.shape[0]
cost = error * error
cost = np.sum(cost) / num_samples
return cost
def gradient(self, x, y):
z = self.forward(x)
gradient_w = (z-y)*x
gradient_w = np.mean(gradient_w, axis=0)
gradient_w = gradient_w[:, np.newaxis]
gradient_b = (z - y)
gradient_b = np.mean(gradient_b)
return gradient_w, gradient_b
def update(self, gradient_w, gradient_b, eta = 0.01):
self.w = self.w - eta * gradient_w
self.b = self.b - eta * gradient_b
def train(self, x, y, iterations=100, eta=0.01):
losses = []
for i in range(iterations):
z = self.forward(x)
L = self.loss(z, y)
gradient_w, gradient_b = self.gradient(x, y)
self.update(gradient_w, gradient_b, eta)
losses.append(L)
if (i+1) % 10 == 0:
print('iter {}, loss {}'.format(i, L))
return losses
# 获取数据
train_data, test_data = load_data()
x = train_data[:, :-1]
y = train_data[:, -1:]
# 创建网络
net = Network(13)
num_iterations=1000
# 启动训练
losses = net.train(x,y, iterations=num_iterations, eta=0.01)
# 画出损失函数的变化趋势
plot_x = np.arange(num_iterations)
plot_y = np.array(losses)
plt.plot(plot_x, plot_y)
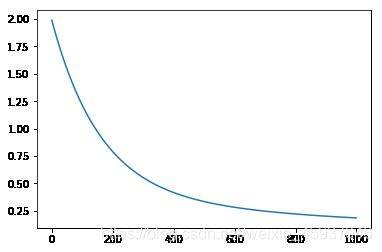
plt.show()
iter 9, loss 1.8984947314576224
iter 19, loss 1.8031783384598725
iter 29, loss 1.7135517565541092
iter 39, loss 1.6292649416831264
iter 49, loss 1.5499895293373231
iter 59, loss 1.4754174896452612
iter 69, loss 1.4052598659324693
iter 79, loss 1.3392455915676864
iter 89, loss 1.2771203802372915
iter 99, loss 1.218645685090292
iter 109, loss 1.1635977224791534
iter 119, loss 1.111766556287068
iter 129, loss 1.0629552390811503
iter 139, loss 1.0169790065644477
iter 149, loss 0.9736645220185994
iter 159, loss 0.9328491676343147
iter 169, loss 0.8943803798194307
iter 179, loss 0.8581150257549611
iter 189, loss 0.8239188186389669
iter 199, loss 0.7916657692169988
iter 209, loss 0.761237671346902
iter 219, loss 0.7325236194855752
iter 229, loss 0.7054195561163928
iter 239, loss 0.6798278472589763
iter 249, loss 0.6556568843183528
iter 259, loss 0.6328207106387195
iter 269, loss 0.6112386712285092
iter 279, loss 0.59083508421862
iter 289, loss 0.5715389327049418
iter 299, loss 0.5532835757100347
iter 309, loss 0.5360064770773406
iter 319, loss 0.5196489511849665
iter 329, loss 0.5041559244351539
iter 339, loss 0.48947571154034963
iter 349, loss 0.47555980568755696
iter 359, loss 0.46236268171965056
iter 369, loss 0.44984161152579916
iter 379, loss 0.43795649088328303
iter 389, loss 0.4266696770400226
iter 399, loss 0.41594583637124666
iter 409, loss 0.4057518014851036
iter 419, loss 0.3960564371908221
iter 429, loss 0.38683051477942226
iter 439, loss 0.3780465941011246
iter 449, loss 0.3696789129556087
iter 459, loss 0.3617032833413179
iter 469, loss 0.3540969941381648
iter 479, loss 0.3468387198244131
iter 489, loss 0.3399084348532937
iter 499, loss 0.33328733333814486
iter 509, loss 0.3269577537166779
iter 519, loss 0.32090310808539985
iter 529, loss 0.3151078159144129
iter 539, loss 0.30955724187078903
iter 549, loss 0.3042376374955925
iter 559, loss 0.2991360864954391
iter 569, loss 0.2942404534243286
iter 579, loss 0.2895393355454012
iter 589, loss 0.28502201767532415
iter 599, loss 0.28067842982626157
iter 609, loss 0.27649910747186535
iter 619, loss 0.2724751542744919
iter 629, loss 0.2685982071209627
iter 639, loss 0.26486040332365085
iter 649, loss 0.2612543498525749
iter 659, loss 0.2577730944725093
iter 669, loss 0.2544100986669443
iter 679, loss 0.2511592122380609
iter 689, loss 0.2480146494787638
iter 699, loss 0.24497096681926708
iter 709, loss 0.2420230418567802
iter 719, loss 0.23916605368251415
iter 729, loss 0.23639546442555454
iter 739, loss 0.23370700193813704
iter 749, loss 0.2310966435515475
iter 759, loss 0.2285606008362593
iter 769, loss 0.22609530530403904
iter 779, loss 0.22369739499361888
iter 789, loss 0.2213637018851542
iter 799, loss 0.21909124009208833
iter 809, loss 0.21687719478222933
iter 819, loss 0.21471891178284025
iter 829, loss 0.21261388782734392
iter 839, loss 0.2105597614038757
iter 849, loss 0.20855430416838638
iter 859, loss 0.20659541288730932
iter 869, loss 0.20468110187697833
iter 879, loss 0.2028094959090178
iter 889, loss 0.20097882355283644
iter 899, loss 0.19918741092814596
iter 909, loss 0.19743367584210875
iter 919, loss 0.1957161222872899
iter 929, loss 0.19403333527807176
iter 939, loss 0.19238397600456975
iter 949, loss 0.19076677728439412
iter 959, loss 0.1891805392938162
iter 969, loss 0.18762412556104593
iter 979, loss 0.18609645920539716
iter 989, loss 0.18459651940712488
iter 999, loss 0.18312333809366155