FPGA图像处理仿真实验——均值滤波
均值滤波是典型的线性滤波,它的原理也很简单,生成一个n*n的模板,在目标图像上进行滑动,用模板上所有像素的均值来代替模板中间那个像素点的值,一直滑动模板,知道处理完整张图片。网上也能搜到均值滤波的Verilog代码,但是我感觉写的不够完善,我对网上已有的代码的理解是,当处理到某个像素点时,将该像素点左上方n*n的窗口内的像素求均值,来替代掉该像素点的像素值,但我认为这个和均值滤波的原理有出入,所以我在他们的代码的基础上进行了完善,给图像加了边界,网上的代码文章的连接附在文末。
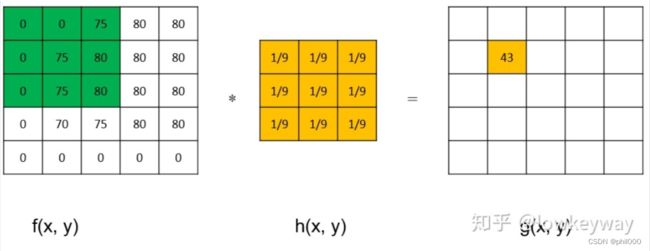
1、边界处理
在用滑动窗口对图像进行处理时,首先要考虑的就是边界问题,要给图像加边界,加边界的方法也有很多种,可以在图像外围补一圈0,也可以将图像最外层的像素值向外扩展一圈等。我选择了在图像外围补一圈0,这个补0的操作我是通过延时操作完成的。因为缓存的三行数据row_data1、row_data2、row_data3在图像数据没有送入时是0,这就完成了在图像上方的补0操作,通过延时一行的输出像素时钟,在最后一行图像数据送入之后在最下面送入一行0,完成了在图像下方补0操作。3*3的窗口在处理完一行数据后,窗口里的9个数据会置0,在下一行送入数据时,这也相当于在图像左侧和右侧进行了补0。左右侧补0通过延时一个输出像素时钟完成。在设置延时周期时要注意输出像素时钟是clk的2倍,延时一行的参数设置由图像大小决定,应该是在仿真文件中行计数的2倍,即H_TOTAL*2。
2、代码
module mean_filter(
input clk,
input rst_n,
input per_frame_vsync,
input per_frame_href,
input per_frame_clken,
input [7:0] per_img_Y,
output post1_vsync,
output post1_href,
output post1_clken,
output [7:0] post1_img_data
);
parameter [10:0] delay=11'd1310;
wire [7:0] post_img_data;
wire post_frame_vsync;
wire post_frame_href;
wire post_frame_clken;
//-----------------------------
//generate 3×3 picture matrix
//-----------------------------
wire matrix_frame_clken;
wire matrix_frame_href;
wire matrix_frame_vsync;
wire [7:0] matrix_p11;
wire [7:0] matrix_p12;
wire [7:0] matrix_p13;
wire [7:0] matrix_p21;
wire [7:0] matrix_p22;
wire [7:0] matrix_p23;
wire [7:0] matrix_p31;
wire [7:0] matrix_p32;
wire [7:0] matrix_p33;
generate_3_3 #(delay) u_generate_3_3(
.clk ( clk ),
.rst_n ( rst_n ),
.per_frame_vsync ( per_frame_vsync ),
.per_frame_href ( per_frame_href ),
.per_frame_clken ( per_frame_clken ),
.per_img_Y ( per_img_Y ),
.matrix_frame_vsync ( matrix_frame_vsync ),
.matrix_frame_href ( matrix_frame_href ),
.matrix_frame_clken ( matrix_frame_clken ),
.matrix_p11 ( matrix_p11 ),
.matrix_p12 ( matrix_p12 ),
.matrix_p13 ( matrix_p13 ),
.matrix_p21 ( matrix_p21 ),
.matrix_p22 ( matrix_p22 ),
.matrix_p23 ( matrix_p23 ),
.matrix_p31 ( matrix_p31 ),
.matrix_p32 ( matrix_p32 ),
.matrix_p33 ( matrix_p33 )
);
//-----------------------------
//mean filter function
//-----------------------------
reg [11:0] add_p1;
reg [11:0] add_p2;
reg [11:0] add_p3;
reg [11:0] add_all;
//step1:add every href
always @(posedge clk or negedge rst_n) begin
if(~rst_n)begin
add_p1<=12'd0;
add_p2<=12'd0;
add_p3<=12'd0;
end
else begin
add_p1<=matrix_p11+matrix_p12+matrix_p13;
add_p2<=matrix_p21+matrix_p22+matrix_p23;
add_p3<=matrix_p31+matrix_p32+matrix_p33;
end
end
//step2:add all the data
always @(posedge clk or negedge rst_n) begin
if(~rst_n)begin
add_all<=12'd0;
end
else begin
add_all<=add_p1+add_p2+add_p3;
end
end
//step3:shift to get mean filter data
assign post_img_data=add_all/9;
//-----------------------------
//clk signal synchronization
//-----------------------------
reg [2:0] post_clken_dy;
reg [2:0] post_href_dy;
reg [2:0] post_vsync_dy;
always @(posedge clk or negedge rst_n) begin
if(~rst_n)begin
post_clken_dy<=2'd0;
post_href_dy<=2'd0;
post_vsync_dy<=2'd0;
end
else begin
post_clken_dy<={post_clken_dy[1:0],matrix_frame_clken};
post_href_dy<={post_href_dy[1:0],matrix_frame_href};
post_vsync_dy<={post_vsync_dy[1:0],matrix_frame_vsync};
end
end
assign post_frame_clken=post_clken_dy[2];
assign post_frame_href=post_href_dy[2];
assign post_frame_vsync=post_vsync_dy[2];
//在这里做一个延时处理,先延时一行,是因为在输出图像第二行的数据时,3*3窗口中放的是前3行的数据,所以输出的数据要比送入3*3窗口的数据晚到一行的时间
//再延时一个输出像素时钟周期(两个clk时钟周期),这是因为输出的每一行的第n个数据时,这时3*3窗口中送入的是n-1、n、n+1这三列的数据,所以输出的第n个数据比送入3*3的n+1这一列数据晚到一个输出像素时钟周期
reg [delay+1:0] post_clken_dl;
reg [delay+1:0] post_href_dl;
reg [delay+1:0] post_vsync_dl;
always @(posedge clk or negedge rst_n) begin
if(~rst_n)begin
post_clken_dl<=0;
post_href_dl<=0;
post_vsync_dl<=0;
end
else begin
post_clken_dl<={post_clken_dl[delay:0],post_frame_clken};
post_href_dl<={post_href_dl[delay:0],post_frame_href};
post_vsync_dl<={post_vsync_dl[delay:0],post_frame_vsync};
end
end
assign post1_clken=post_clken_dl[delay+1];
assign post1_href=post_href_dl[delay+1];
assign post1_vsync=post_vsync_dl[delay+1];
assign post1_img_data=post1_href?post_img_data:0;
endmodulemodule generate_3_3(
input clk, //cmos video pixel clock
input rst_n, //global reset
//Image data prepred to be processd
input per_frame_vsync, //Prepared Image data vsync valid signal
input per_frame_href, //Prepared Image data href vaild signal
input per_frame_clken, //Prepared Image data output/capture enable clock
input [7:0] per_img_Y, //Prepared Image brightness input
//Image data has been processd
output matrix_frame_vsync, //Prepared Image data vsync valid signal
output matrix_frame_href, //Prepared Image data href vaild signal
output matrix_frame_clken, //Prepared Image data output/capture enable clock
output reg [7:0] matrix_p11, matrix_p12, matrix_p13,
output reg [7:0] matrix_p21, matrix_p22, matrix_p23,
output reg [7:0] matrix_p31, matrix_p32, matrix_p33
);
parameter [10:0] delay=11'd1310;
//--------------------------------------------------------------------------
//sync row3_data with per_frame_clken & row1_data & raw2_data
wire [7:0] row1_data; //frame data of the 1th row
wire [7:0] row2_data; //frame data of the 2th row
reg [7:0] row3_data; //frame data of the 3th row
reg [delay-1:0] per_clken_dl;
wire per1_frame_clken;
always @(posedge clk or negedge rst_n) begin
if(~rst_n)begin
per_clken_dl<=0;
end
else begin
per_clken_dl<={per_clken_dl[delay-2:0],per_frame_clken};
end
end
assign per1_frame_clken=per_clken_dl[delay-1];
//***********************************************************************此处移位寄存器落后一个时钟周期
always@(posedge clk or negedge rst_n)
begin
if(!rst_n)
row3_data <= 0;
else
begin
if(per_frame_clken||per1_frame_clken) //将输入的信号用像素使能时钟同步一拍,以保证数据与Shift_RAM输出的数据保持同步
row3_data <= per_img_Y;
else
row3_data <= row3_data;
end
end
//借助2个移位寄存器进行串联
c_shift_ram_0 u1(
.D(row3_data),
.CLK(clk),
.CE(per_frame_clken||per1_frame_clken),
.Q(row2_data)
);
c_shift_ram_0 u2(
.D(row2_data),
.CLK(clk),
.CE(per_frame_clken||per1_frame_clken),
.Q(row1_data)
);
//------------------------------------------
//lag 3 clocks signal sync
reg [1:0] per_frame_vsync_r;
reg [1:0] per_frame_href_r;
reg [1:0] per_frame_clken_r;
always@(posedge clk or negedge rst_n)
begin
if(!rst_n)
begin
per_frame_vsync_r <= 0;
per_frame_href_r <= 0;
per_frame_clken_r <= 0;
end
else
begin
per_frame_vsync_r <= {per_frame_vsync_r[0], per_frame_vsync};
per_frame_href_r <= {per_frame_href_r[0], per_frame_href};
per_frame_clken_r <= {per_frame_clken_r[0], per_frame_clken};
end
end
assign matrix_frame_vsync = per_frame_vsync_r[1];
assign matrix_frame_href = per_frame_href_r[1];
assign matrix_frame_clken = per_frame_clken_r[1];
wire read_frame_href = per_frame_href_r[0];
wire read_frame_clken = per_frame_clken_r[0];
//这个延时一行的操作是为了在图像的最后一行下面补上一个全0行
reg [delay-1:0] read_frame_href_dl;
reg [delay-1:0] read_frame_clken_dl;
wire read1_frame_href;
wire read1_frame_clken;
wire bu0_tag;
wire read_frame_clken_bu0;
wire read1_frame_clken_bu0;
always @(posedge clk or negedge rst_n) begin
if(~rst_n)begin
read_frame_href_dl<=0;
read_frame_clken_dl<=0;
end
else begin
read_frame_href_dl<={read_frame_href_dl[delay-2:0],read_frame_href};
read_frame_clken_dl<={read_frame_clken_dl[delay-2:0],read_frame_clken};
end
end
assign read1_frame_href=read_frame_href_dl[delay-1];
assign read1_frame_clken=read_frame_clken_dl[delay-1];
always@(posedge clk or negedge rst_n)
begin
if(!rst_n) begin
{matrix_p11, matrix_p12, matrix_p13} <= 24'd0;
{matrix_p21, matrix_p22, matrix_p23} <= 24'd0;
{matrix_p31, matrix_p32, matrix_p33} <= 24'd0;
end
else if(read_frame_href||read1_frame_href) begin
if(read_frame_clken||read1_frame_clken) begin//Shift_RAM data read clock enable
{matrix_p11, matrix_p12, matrix_p13} <= {matrix_p12, matrix_p13,row1_data}; //1th shift input
{matrix_p21, matrix_p22, matrix_p23} <= {matrix_p22, matrix_p23,row2_data}; //2th shift input
{matrix_p31, matrix_p32, matrix_p33} <= {matrix_p32, matrix_p33,row3_data}; //3th shift input
end
else begin
{matrix_p11, matrix_p12, matrix_p13} <= {matrix_p11, matrix_p12, matrix_p13};
{matrix_p21, matrix_p22, matrix_p23} <= {matrix_p21, matrix_p22, matrix_p23};
{matrix_p31, matrix_p32, matrix_p33} <= {matrix_p31, matrix_p32, matrix_p33};
end
end
else if(bu0_tag) begin
if(read_frame_clken_bu0||read1_frame_clken_bu0)begin
{matrix_p11, matrix_p12, matrix_p13} <= {matrix_p12, matrix_p13,8'd0}; //1th shift input
{matrix_p21, matrix_p22, matrix_p23} <= {matrix_p22, matrix_p23,8'd0}; //2th shift input
{matrix_p31, matrix_p32, matrix_p33} <= {matrix_p32, matrix_p33,8'd0}; //3th shift input
end
else begin
{matrix_p11, matrix_p12, matrix_p13} <= {matrix_p11, matrix_p12, matrix_p13};
{matrix_p21, matrix_p22, matrix_p23} <= {matrix_p21, matrix_p22, matrix_p23};
{matrix_p31, matrix_p32, matrix_p33} <= {matrix_p31, matrix_p32, matrix_p33};
end
end
else begin
{matrix_p11, matrix_p12, matrix_p13} <= 24'd0;
{matrix_p21, matrix_p22, matrix_p23} <= 24'd0;
{matrix_p31, matrix_p32, matrix_p33} <= 24'd0;
end
end
//这里的延时是为了在3*3滑动窗口处理的每一行的最后一列数据时,延时一个输出像素时钟周期,在每一列的最后进行补0操作
reg [2:0] read_frame_href_dy;
reg [2:0] read1_frame_href_dy;
reg [1:0] read_frame_clken_dy;
reg [1:0] read1_frame_clken_dy;
wire read_frame_href_bu0;
wire read1_frame_href_bu0;
always@(posedge clk or negedge rst_n)
begin
if(!rst_n)
begin
read_frame_href_dy <= 0;
read1_frame_href_dy <= 0;
read_frame_clken_dy <= 0;
read1_frame_clken_dy <= 0;
end
else
begin
read_frame_href_dy <= {read_frame_href_dy[1:0], read_frame_href};
read1_frame_href_dy <= {read1_frame_href_dy[1:0], read1_frame_href};
read_frame_clken_dy <= {read_frame_clken_dy[0], read_frame_clken};
read1_frame_clken_dy <= {read1_frame_clken_dy[0], read1_frame_clken};
end
end
assign read_frame_href_bu0=read_frame_href_dy[2];
assign read1_frame_href_bu0=read1_frame_href_dy[2];
assign read_frame_clken_bu0=read_frame_clken_dy[1];
assign read1_frame_clken_bu0=read1_frame_clken_dy[1];
assign bu0_tag=((read1_frame_href_bu0&(~read1_frame_href))||(read_frame_href_bu0&(~read_frame_href)))?1:0;
endmodule3、结果图


4、参考资料
https://blog.csdn.net/qq_40995480/article/details/126831740
https://zhuanlan.zhihu.com/p/76188487