基于MAE的人脸素描图像属性识别和分类
0 前言
关于MAE的介绍和原理可以参考下面这篇博客
【论文和代码阅读】Masked Autoencoders Are Scalable Learners (MAE)_Toblerone_Wind的博客-CSDN博客1. 原文和代码先贴一下MAE的论文链接https://github.com/facebookresearch/maehttps://github.com/facebookresearch/mae紧随其后的是代码复现https://github.com/facebookresearch/maehttps://github.com/facebookresearch/mae2. 论文效果图论文标题是《Masked Autoencoders Are Scalable Vision Learnershttps://blog.csdn.net/qq_42276781/article/details/125010531 MAE主要工作:在海量无标注的图像上,通过图像重建任务来自监督训练模型,预训练好的模型通过简单的微调即可适用于下游图像任务(如图像分类)中。
1 本文工作
本文的数据集来自FS2K,是人脸的素描图像数据集,包含有2104对彩图与素描图,以及三个python文件,check.py,split_train_test.py和vis.py。
https://github.com/DengPingFan/FS2K https://github.com/DengPingFan/FS2K
https://github.com/DengPingFan/FS2K
如图,我挑选了3对彩图和素描图作为样例,上面的是彩色图像,下面的是彩色图像对应的素描图像。

根据图像的名称可以在JSON文件中查询得到图像的详细信息。
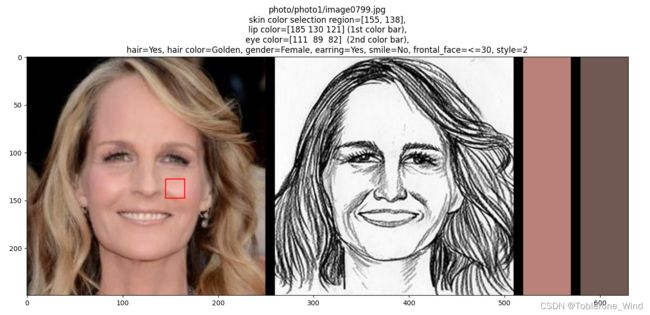
通过FS2K自带的vis.py文件,可以逐张查看图像的具体属性。通过下面这张图像,可以看到,基本的图像属性信息有嘴唇颜色(lip color),眼睛颜色(eye color),是否有头发(hair),头发颜色(hair color),性别(gender),是否带耳环(earring),是否微笑(smile),正面角度是否小于30度(frontal_face<=30),素描的风格(style)。
值得一提的是,素描图像会丢失彩色图像的一些细节信息,比如下面这张图,彩色原图中人物是佩戴耳环的,但是在素描图像中是没有佩戴的。
本文的主要工作:使用MAE对素描图像的属性进行识别,识别的属性包括发色(color)、性别(sex)、是否带耳环(earring)、正面角度是否大于 30°(frontal_face)、是否有头发(hair)以及是否微笑(smile)。
补充说明,原项目提供的用来切分数据集的split_train_test.py文件在运行的时候会报错,报错信息如下:
FileNotFoundError: [Errno 2] No such file or directory: '../FS2K/photo/photo3/image0449.png'仔细核对发现,FS2K/photo/photo3/image0449.png有误,原始图像的后缀是大写的JPG,不同与其他小写的jpg,需要手动将后缀更改为小写的jpg。

修改后,运行split_train_test.py来切分训练集和测试集,发现切分后的图像无法正常显示。问题出在这段代码中。在将原始图片移动到训练集和测试集的过程中,会调用这个函数创建路径,可以看到首先通过if语句判断该路径下是否有.jpg的文件,如果没有,就将后缀设置为jpg。但是万一原始图像是png格式的,在移动之前,目标路径下没有.jpg结尾的文件,那程序就移动的同时,把png格式的图像重命名为jpg格式。

众所周知,严格来说jpg和png格式是不能混用的,如果可以混用,那也没有必要用两个后缀来区分了,直接统一使用png不就好了吗?就我猜测,FK2K开源项目的贡献者应该是在Windows环境下编写的这些代码,因为Windows系统自带的图片查看器可以自动识别图像格式(即使你把png格式的图像后缀修改为jpg也能正常查看),另外Windows环境对后缀的大小写可能并不十分敏感,所以他也没有发现有一副图像的后缀名是大写的JPG。
这里我提供一个下载链接,里面包含正确的图像后缀,修改后的split_train_test.py,以及其他文件。确保在任何环境都可以正常运行程序。
FS2K人脸素描数据集和代码-统计分析文档类资源-CSDN下载https://download.csdn.net/download/qq_42276781/85930478
2 数据集转换
MAE的模型采用的是torchvision.dataset 的数据集导入方式,同时在微调过程中还需要验证集。因此,在切分数据集的过程中,需要将数据集转化为标准格式,并将原始的训练集按2:1的比例切分为训练集和验证集。
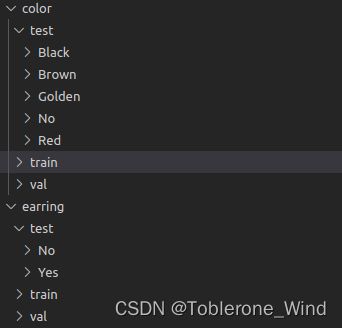
如下图所示。对于 color 这一属性,首先将其分为训练集、验证集和测试集。在每一个集合下,又将图像分别放入 Black、Brown、Golden、No 和 Red 文件夹中。
这里贴一个将训练集切分成训练集和验证集的代码train_val.py。
########### to transform the format of dataset to torchvision.datasets
import os
import json
import numpy as np
import shutil
import random
def makeDir(set):
def make(path):
if not os.path.exists(path):
os.makedirs(path)
make('hair/'+set)
make('hair/'+set+'No/')
make('hair/'+set+'Yes/')
make('color/'+set)
make('color/'+set+'Brown/')
make('color/'+set+'Black/')
make('color/'+set+'Red/')
make('color/'+set+'No/')
make('color/'+set+'Golden/')
make('sex/'+set)
make('sex/'+set+'Male/')
make('sex/'+set+'Female/')
make('earring/'+set)
make('earring/'+set+'No/')
make('earring/'+set+'Yes/')
make('smile/'+set)
make('smile/'+set+'No/')
make('smile/'+set+'Yes/')
make('frontal_face/'+set)
make('frontal_face/'+set+'Up/')
make('frontal_face/'+set+'Low/')
json_file_train = 'anno_train.json'
with open(json_file_train, 'r') as f:
json_data = json.loads(f.read())
inputDir = 'train/sketch/'
makeDir(set='train/')
makeDir(set='val/')
attrs = {}
for attr in json_data[0].keys():
attrs[attr] = []
for idx_fs, fs in enumerate(json_data):
for attr in fs:
attrs[attr].append(fs[attr])
photo_paths = []
for photo_dir in os.listdir(inputDir):
photo_paths.append(inputDir+photo_dir)
total = len(attrs['image_name'])
ran = random.sample(range(0, total), total)
val = ran[0:int(total/3)]
train = ran[int(total/3):]
for idx_image_name, image_name in enumerate(attrs['image_name']):
if idx_image_name < 0:
continue
print('{}/{},'.format(idx_image_name+1, total), image_name)
image_name = image_name.replace("photo1", "sketch1_sketch")
image_name = image_name.replace("photo2", "sketch2_sketch")
image_name = image_name.replace("photo3", "sketch3_sketch")
image_name = image_name.replace("/image", "")
for photo_path in photo_paths:
if image_name in photo_path:
src_path = photo_path
suffix = photo_path[-4:]
break
dst_file_name = image_name + suffix
hair = int(attrs['hair'][idx_image_name])
if 'nan' not in attrs['lip_color'][idx_image_name]:
hair_color = np.array(attrs['hair_color'][idx_image_name]).astype(np.uint8)
gender = int(attrs['gender'][idx_image_name])
earring = int(attrs['earring'][idx_image_name])
smile = int(attrs['smile'][idx_image_name])
frontal_face = int(attrs['frontal_face'][idx_image_name])
if idx_image_name in val:
set = 'val/'
else:
set = 'train/'
if hair == 0:
shutil.copy2(src_path, 'hair/'+set+'Yes/'+dst_file_name)
else:
shutil.copy2(src_path, 'hair/'+set+'No/'+dst_file_name)
if hair_color == 0:
shutil.copy2(src_path, 'color/'+set+'Brown/'+dst_file_name)
elif hair_color == 1:
shutil.copy2(src_path, 'color/'+set+'Black/'+dst_file_name)
elif hair_color == 2:
shutil.copy2(src_path, 'color/'+set+'Red/'+dst_file_name)
elif hair_color == 3:
shutil.copy2(src_path, 'color/'+set+'No/'+dst_file_name)
elif hair_color == 4:
shutil.copy2(src_path, 'color/'+set+'Golden/'+dst_file_name)
if gender == 0:
shutil.copy2(src_path, 'sex/'+set+'Male/'+dst_file_name)
else:
shutil.copy2(src_path, 'sex/'+set+'Female/'+dst_file_name)
if earring == 0:
shutil.copy2(src_path, 'earring/'+set+'Yes/'+dst_file_name)
else:
shutil.copy2(src_path, 'earring/'+set+'No/'+dst_file_name)
if smile == 0:
shutil.copy2(src_path, 'smile/'+set+'No/'+dst_file_name)
else:
shutil.copy2(src_path, 'smile/'+set+'Yes/'+dst_file_name)
if frontal_face == 0:
shutil.copy2(src_path, 'frontal_face/'+set+'Low/'+dst_file_name)
else:
shutil.copy2(src_path, 'frontal_face/'+set+'Up/'+dst_file_name)
完整代码和图像可以通过下面的链接获取。
FS2K数据集转换为torchvision.dataset格式-Python文档类资源-CSDN下载https://download.csdn.net/download/qq_42276781/85931316
3 预训练模型
本文没有单独训练一个MAE模型,而是使用了MAE开源代码提供的已经训练好的模型mae_visualize_vit_large.pth,下载链接如下。
https://dl.fbaipublicfiles.com/mae/visualize/mae_visualize_vit_large.pthhttps://dl.fbaipublicfiles.com/mae/visualize/mae_visualize_vit_large.pth 只需要将人脸素描数据输入到这个预训练模型中,进行参数微调,就可以获得较好的识别和分类性能。
4 模型微调
在mae开源代码的原始main_finetune.py的基础上,我进行了一些修改和删减,修改后的代码如下。实际运行时,只需跳转到第120行和第122行,修改分类属性和分类数量即可。
# Copyright (c) Meta Platforms, Inc. and affiliates.
# All rights reserved.
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
# --------------------------------------------------------
# References:
# DeiT: https://github.com/facebookresearch/deit
# BEiT: https://github.com/microsoft/unilm/tree/master/beit
# --------------------------------------------------------
import argparse
import datetime
import json
import numpy as np
import os
import time
from pathlib import Path
import torch
import torch.backends.cudnn as cudnn
from torch.utils.tensorboard import SummaryWriter
import timm
# assert timm.__version__ == "0.3.2" # version check
from timm.models.layers import trunc_normal_
from timm.data.mixup import Mixup
from timm.loss import LabelSmoothingCrossEntropy, SoftTargetCrossEntropy
import util.lr_decay as lrd
import util.misc as misc
from util.datasets import build_dataset
from util.pos_embed import interpolate_pos_embed
from util.misc import NativeScalerWithGradNormCount as NativeScaler
import models_vit
from engine_finetune import train_one_epoch, evaluate
def get_args_parser():
parser = argparse.ArgumentParser('MAE fine-tuning for image classification', add_help=False)
parser.add_argument('--batch_size', default=64, type=int,
help='Batch size per GPU (effective batch size is batch_size * accum_iter * # gpus')
parser.add_argument('--epochs', default=40, type=int)
parser.add_argument('--accum_iter', default=1, type=int,
help='Accumulate gradient iterations (for increasing the effective batch size under memory constraints)')
# Model parameters
parser.add_argument('--model', default='vit_large_patch16', type=str, metavar='MODEL',
help='Name of model to train')
parser.add_argument('--input_size', default=224, type=int,
help='images input size')
parser.add_argument('--drop_path', type=float, default=0.1, metavar='PCT',
help='Drop path rate (default: 0.1)')
# Optimizer parameters
parser.add_argument('--clip_grad', type=float, default=None, metavar='NORM',
help='Clip gradient norm (default: None, no clipping)')
parser.add_argument('--weight_decay', type=float, default=0.05,
help='weight decay (default: 0.05)')
parser.add_argument('--lr', type=float, default=None, metavar='LR',
help='learning rate (absolute lr)')
parser.add_argument('--blr', type=float, default=1e-3, metavar='LR',
help='base learning rate: absolute_lr = base_lr * total_batch_size / 256')
parser.add_argument('--layer_decay', type=float, default=0.75,
help='layer-wise lr decay from ELECTRA/BEiT')
parser.add_argument('--min_lr', type=float, default=1e-6, metavar='LR',
help='lower lr bound for cyclic schedulers that hit 0')
parser.add_argument('--warmup_epochs', type=int, default=5, metavar='N',
help='epochs to warmup LR')
# Augmentation parameters
parser.add_argument('--color_jitter', type=float, default=None, metavar='PCT',
help='Color jitter factor (enabled only when not using Auto/RandAug)')
parser.add_argument('--aa', type=str, default='rand-m9-mstd0.5-inc1', metavar='NAME',
help='Use AutoAugment policy. "v0" or "original". " + "(default: rand-m9-mstd0.5-inc1)'),
parser.add_argument('--smoothing', type=float, default=0.1,
help='Label smoothing (default: 0.1)')
# * Random Erase params
parser.add_argument('--reprob', type=float, default=0.25, metavar='PCT',
help='Random erase prob (default: 0.25)')
parser.add_argument('--remode', type=str, default='pixel',
help='Random erase mode (default: "pixel")')
parser.add_argument('--recount', type=int, default=1,
help='Random erase count (default: 1)')
parser.add_argument('--resplit', action='store_true', default=False,
help='Do not random erase first (clean) augmentation split')
# * Mixup params
parser.add_argument('--mixup', type=float, default=0,
help='mixup alpha, mixup enabled if > 0.')
parser.add_argument('--cutmix', type=float, default=0,
help='cutmix alpha, cutmix enabled if > 0.')
parser.add_argument('--cutmix_minmax', type=float, nargs='+', default=None,
help='cutmix min/max ratio, overrides alpha and enables cutmix if set (default: None)')
parser.add_argument('--mixup_prob', type=float, default=1.0,
help='Probability of performing mixup or cutmix when either/both is enabled')
parser.add_argument('--mixup_switch_prob', type=float, default=0.5,
help='Probability of switching to cutmix when both mixup and cutmix enabled')
parser.add_argument('--mixup_mode', type=str, default='batch',
help='How to apply mixup/cutmix params. Per "batch", "pair", or "elem"')
# * Finetuning params
parser.add_argument('--finetune', default='mae_visualize_vit_large.pth',
help='finetune from checkpoint')
parser.add_argument('--global_pool', action='store_true')
parser.set_defaults(global_pool=True)
parser.add_argument('--cls_token', action='store_false', dest='global_pool',
help='Use class token instead of global pool for classification')
# Dataset parameters
parser.add_argument('--data_path', default='hair/', type=str,
help='dataset path')
parser.add_argument('--nb_classes', default=2, type=int,
help='number of the classification types')
parser.add_argument('--output_dir', default='./output_dir',
help='path where to save, empty for no saving')
parser.add_argument('--log_dir', default='./output_dir',
help='path where to tensorboard log')
parser.add_argument('--device', default='cuda',
help='device to use for training / testing')
parser.add_argument('--seed', default=0, type=int)
parser.add_argument('--resume', default='',
help='resume from checkpoint')
parser.add_argument('--start_epoch', default=0, type=int, metavar='N',
help='start epoch')
parser.add_argument('--eval', action='store_true',
help='Perform evaluation only')
parser.add_argument('--dist_eval', action='store_true', default=False,
help='Enabling distributed evaluation (recommended during training for faster monitor')
parser.add_argument('--num_workers', default=10, type=int)
parser.add_argument('--pin_mem', action='store_true',
help='Pin CPU memory in DataLoader for more efficient (sometimes) transfer to GPU.')
parser.add_argument('--no_pin_mem', action='store_false', dest='pin_mem')
parser.set_defaults(pin_mem=True)
# distributed training parameters
parser.add_argument('--world_size', default=1, type=int,
help='number of distributed processes')
parser.add_argument('--local_rank', default=-1, type=int)
parser.add_argument('--dist_on_itp', action='store_true')
parser.add_argument('--dist_url', default='env://',
help='url used to set up distributed training')
return parser
def main(args):
misc.init_distributed_mode(args)
print('job dir: {}'.format(os.path.dirname(os.path.realpath(__file__))))
print("{}".format(args).replace(', ', ',\n'))
device = torch.device(args.device)
# fix the seed for reproducibility
seed = args.seed + misc.get_rank()
torch.manual_seed(seed)
np.random.seed(seed)
cudnn.benchmark = True
dataset_train = build_dataset(is_train=True, args=args)
dataset_val = build_dataset(is_train=False, args=args)
if True: # args.distributed:
num_tasks = misc.get_world_size()
global_rank = misc.get_rank()
sampler_train = torch.utils.data.DistributedSampler(
dataset_train, num_replicas=num_tasks, rank=global_rank, shuffle=True
)
print("Sampler_train = %s" % str(sampler_train))
if args.dist_eval:
if len(dataset_val) % num_tasks != 0:
print('Warning: Enabling distributed evaluation with an eval dataset not divisible by process number. '
'This will slightly alter validation results as extra duplicate entries are added to achieve '
'equal num of samples per-process.')
sampler_val = torch.utils.data.DistributedSampler(
dataset_val, num_replicas=num_tasks, rank=global_rank, shuffle=True) # shuffle=True to reduce monitor bias
else:
sampler_val = torch.utils.data.SequentialSampler(dataset_val)
else:
sampler_train = torch.utils.data.RandomSampler(dataset_train)
sampler_val = torch.utils.data.SequentialSampler(dataset_val)
if global_rank == 0 and args.log_dir is not None and not args.eval:
os.makedirs(args.log_dir, exist_ok=True)
log_writer = SummaryWriter(log_dir=args.log_dir)
else:
log_writer = None
data_loader_train = torch.utils.data.DataLoader(
dataset_train, sampler=sampler_train,
batch_size=args.batch_size,
num_workers=args.num_workers,
pin_memory=args.pin_mem,
drop_last=True,
)
data_loader_val = torch.utils.data.DataLoader(
dataset_val, sampler=sampler_val,
batch_size=args.batch_size,
num_workers=args.num_workers,
pin_memory=args.pin_mem,
drop_last=False
)
mixup_fn = None
mixup_active = args.mixup > 0 or args.cutmix > 0. or args.cutmix_minmax is not None
if mixup_active:
print("Mixup is activated!")
mixup_fn = Mixup(
mixup_alpha=args.mixup, cutmix_alpha=args.cutmix, cutmix_minmax=args.cutmix_minmax,
prob=args.mixup_prob, switch_prob=args.mixup_switch_prob, mode=args.mixup_mode,
label_smoothing=args.smoothing, num_classes=args.nb_classes)
model = models_vit.__dict__[args.model](
num_classes=args.nb_classes,
drop_path_rate=args.drop_path,
global_pool=args.global_pool,
)
if args.finetune and not args.eval:
checkpoint = torch.load(args.finetune, map_location='cpu')
print("Load pre-trained checkpoint from: %s" % args.finetune)
checkpoint_model = checkpoint['model']
state_dict = model.state_dict()
for k in ['head.weight', 'head.bias']:
if k in checkpoint_model and checkpoint_model[k].shape != state_dict[k].shape:
print(f"Removing key {k} from pretrained checkpoint")
del checkpoint_model[k]
# interpolate position embedding
interpolate_pos_embed(model, checkpoint_model)
# load pre-trained model
msg = model.load_state_dict(checkpoint_model, strict=False)
print(msg)
if args.global_pool:
assert set(msg.missing_keys) == {'head.weight', 'head.bias', 'fc_norm.weight', 'fc_norm.bias'}
else:
assert set(msg.missing_keys) == {'head.weight', 'head.bias'}
# manually initialize fc layer
trunc_normal_(model.head.weight, std=2e-5)
model.to(device)
model_without_ddp = model
n_parameters = sum(p.numel() for p in model.parameters() if p.requires_grad)
print("Model = %s" % str(model_without_ddp))
print('number of params (M): %.2f' % (n_parameters / 1.e6))
eff_batch_size = args.batch_size * args.accum_iter * misc.get_world_size()
if args.lr is None: # only base_lr is specified
args.lr = args.blr * eff_batch_size / 256
print("base lr: %.2e" % (args.lr * 256 / eff_batch_size))
print("actual lr: %.2e" % args.lr)
print("accumulate grad iterations: %d" % args.accum_iter)
print("effective batch size: %d" % eff_batch_size)
if args.distributed:
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.gpu])
model_without_ddp = model.module
# build optimizer with layer-wise lr decay (lrd)
param_groups = lrd.param_groups_lrd(model_without_ddp, args.weight_decay,
no_weight_decay_list=model_without_ddp.no_weight_decay(),
layer_decay=args.layer_decay
)
optimizer = torch.optim.AdamW(param_groups, lr=args.lr)
loss_scaler = NativeScaler()
if mixup_fn is not None:
# smoothing is handled with mixup label transform
criterion = SoftTargetCrossEntropy()
elif args.smoothing > 0.:
criterion = LabelSmoothingCrossEntropy(smoothing=args.smoothing)
else:
criterion = torch.nn.CrossEntropyLoss()
print("criterion = %s" % str(criterion))
misc.load_model(args=args, model_without_ddp=model_without_ddp, optimizer=optimizer, loss_scaler=loss_scaler)
if args.eval:
test_stats = evaluate(data_loader_val, model, device)
print(f"Accuracy of the network on the {len(dataset_val)} test images: {test_stats['acc1']:.1f}%")
exit(0)
print(f"Start training for {args.epochs} epochs")
start_time = time.time()
max_accuracy = 0.0
for epoch in range(args.start_epoch, args.epochs):
if args.distributed:
data_loader_train.sampler.set_epoch(epoch)
train_stats = train_one_epoch(
model, criterion, data_loader_train,
optimizer, device, epoch, loss_scaler,
args.clip_grad, mixup_fn,
log_writer=log_writer,
args=args
)
if args.output_dir and epoch==args.epochs-1:
misc.save_model(
args=args, model=model, model_without_ddp=model_without_ddp, optimizer=optimizer,
loss_scaler=loss_scaler, epoch=epoch)
test_stats = evaluate(data_loader_val, model, device)
print(f"Accuracy of the network on the {len(dataset_val)} test images: {test_stats['acc1']:.1f}%")
max_accuracy = max(max_accuracy, test_stats["acc1"])
print(f'Max accuracy: {max_accuracy:.2f}%')
# if log_writer is not None:
# log_writer.add_scalar('perf/test_acc1', test_stats['acc1'], epoch)
# log_writer.add_scalar('perf/test_acc5', test_stats['acc5'], epoch)
# log_writer.add_scalar('perf/test_loss', test_stats['loss'], epoch)
# log_stats = {**{f'train_{k}': v for k, v in train_stats.items()},
# **{f'test_{k}': v for k, v in test_stats.items()},
# 'epoch': epoch,
# 'n_parameters': n_parameters}
# if args.output_dir and misc.is_main_process():
# if log_writer is not None:
# log_writer.flush()
# with open(os.path.join(args.output_dir, "log.txt"), mode="a", encoding="utf-8") as f:
# f.write(json.dumps(log_stats) + "\n")
total_time = time.time() - start_time
total_time_str = str(datetime.timedelta(seconds=int(total_time)))
print('Training time {}'.format(total_time_str))
if __name__ == '__main__':
args = get_args_parser()
args = args.parse_args()
if args.output_dir:
Path(args.output_dir).mkdir(parents=True, exist_ok=True)
main(args)微调结束后会将模型保存到本地,再运行main_test.py,将测试集数据输入到微调后的模型中进行属性识别和分类。只需修改37-41行,分别设置分类属性,导入的模型和分类数量,即可运行程序。
import argparse
import torch
from util.datasets import build_dataset
from util.pos_embed import interpolate_pos_embed
import models_vit
from engine_finetune import evaluate_1 as evaluate
def get_args_parser():
parser = argparse.ArgumentParser('test for image classification', add_help=False)
parser.add_argument('--batch_size', default=523, type=int,
help='Batch size per GPU (effective batch size is batch_size * accum_iter * # gpus')
parser.add_argument('--lr', type=float, default=1e-4, metavar='LR',
help='learning rate (absolute lr)')
parser.add_argument('--drop_path', default=0.1, type=float, metavar='PCT',
help='Drop path rate (default: 0.1)')
parser.add_argument('--global_pool', action='store_true')
parser.set_defaults(global_pool=True)
parser.add_argument('--model', default='vit_large_patch16', type=str, metavar='MODEL',
help='Name of model to train')
parser.add_argument('--device', default='cuda',
help='device to use for training / testing')
parser.add_argument('--input_size', default=224, type=int,
help='images input size')
parser.add_argument('--pin_mem', action='store_true',
help='Pin CPU memory in DataLoader for more efficient (sometimes) transfer to GPU.')
parser.add_argument('--num_workers', default=10, type=int)
# change it for different classification tasks
parser.add_argument('--nb_classes', default=2, type=int,
help='number of the classfication types')
parser.add_argument('--predict', default='output_dir/checkpoint-9.pth',
help='predict from checkpoint')
parser.add_argument('--data_path', default='earring/', type=str,
help='dataset path')
return parser
def initMae(args):
model = models_vit.__dict__[args.model](
num_classes=args.nb_classes,
drop_path_rate=args.drop_path,
global_pool=args.global_pool,
)
checkpoint = torch.load(args.predict, map_location='cpu')
checkpoint_model = checkpoint['model']
interpolate_pos_embed(model, checkpoint_model)
msg = model.load_state_dict(checkpoint_model, strict=False)
print(msg)
return model
def main(args):
device = torch.device(args.device)
model = initMae(args).to(device)
dataset_test = build_dataset(is_train=False, is_test=True, args=args)
sampler_test = torch.utils.data.SequentialSampler(dataset_test)
data_loader_test = torch.utils.data.DataLoader(
dataset_test, sampler=sampler_test,
batch_size=args.batch_size,
num_workers=args.num_workers,
pin_memory=args.pin_mem,
drop_last=False
)
evaluate(data_loader_test, model, device, cls=args.nb_classes)
# print(f"Accuracy of the network on the {len(dataset_test)} test images: {test_stats['acc1']:.1f}%")
if __name__ == '__main__':
args = get_args_parser()
args = args.parse_args()
main(args)
5 实验结果
本文首先对发色(color)、性别(sex)、是否带耳环(earring)、正面角度大于30(frontal_face)、
是否有头发(hair)以及是否微笑(smile),进行初步实验。发现发色的准确率(accuracy)最低,于是
认为其分类难度最大,将其作为调参实验的对象。
由于 MAE 内部由 Transformer block 组成,在显存有限的情况下,batch 数和 block 数不能同时兼得,即 batch 数越大,则 block 数越小。我的显卡是3060,显存只有12GB,下表中的每一项测试所需显存基本上都达到了11GB。
可以看到在 batch 和 block 数目固定的情况下,在验证集和测试集上的 accuracy 随着epoch 轮数的增加而增加。此外,block 层数越多,模型越复杂,加上 batch 数必须相应减少,因此训练
时间会逐渐增加。
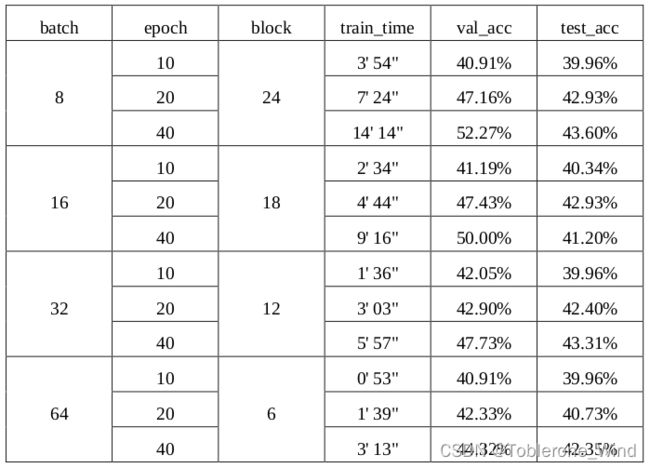
考虑到时间和实际收益,本文在之后的实验中默认采用 epoch=40,batch=64,block=6。
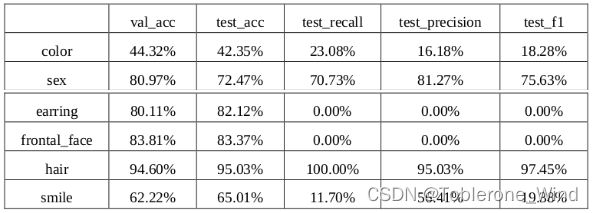
下面的表格展示了微调后的模型对各个属性的分类结果。可以看到,模型对 hair 和 sex 有着不错的理解,可以较为准确地识别。对于 color 和 smile,模型的理解能力稍差,召回率偏低。
特别的,模型似乎很难捕获到 earring 和 frontal_face 这两个属性。事实上,当我实际去看的时候,也很难分别人物的正面角度是否大于 30。此外,就如上文所展示的图片样例,很多素描图都会将耳环信息丢失(即,原始彩图有耳环的图像,其对应的素描图经常会出现没有耳环的情景)。综上,模型无法理解这两个属性,单一地将结果预测为同一个值,导致TP=0,所以最后的 recall、precision 和 f1 值均为 0。
4 总结
本文使用了 MAE 在大型图像数据集上预训练好的模型,将其在下游的素描属性分类任务上进行微调,并验证了模型的有效性。
实际上,由于预训练模型是在海量的彩色图像上进行学习,因此其并不非常适合用于素描属性的分类任务。不进行微调,直接将预训练模型用于属性分类的结果非常差,accuracy 只有 10%左右。
在微调后,对于一些较为明显的属性,模型可以很好地捕获,也从侧面验证了在 CV 上采用预训练模型的可行性和 Transformer 架构的通用性。
更一般地,如果能提供无标注的海量素描数据集,在其上面预训练的模型肯定会更契合 FS2K 素描数据集。
完整开源代码在下方链接中
GitHub - Lucienxhh/FS2K_MAE_ClassificationContribute to Lucienxhh/FS2K_MAE_Classification development by creating an account on GitHub. https://github.com/Lucienxhh/FS2K_MAE_Classification
https://github.com/Lucienxhh/FS2K_MAE_Classification