模式识别与机器学习 第一章 绪论
引言
课程介绍
1956年夏天达特茅斯会议标志着人工智能学科的诞生 人工智能之父 约翰·麦卡锡
基础:线性代数、概率统计、最优化理论
交叉课程:图像处理、计算机视觉、数据挖掘、自然语言处理、多媒体技术
参考书目:《机器学习》西瓜书《统计学习方法》李航《深度学习》《模式分类》
参考期刊:TPAMI、ICML、ICLR、NeurIPS、CVPR、ICCV & Arxiv网站 Valse研讨会
授课内容:
模式识别与机器学习基本概念
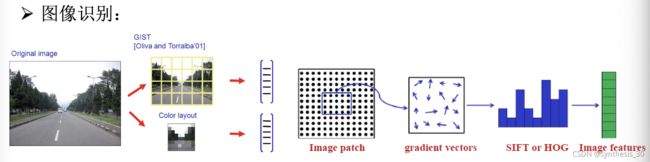
典型的模式识别特征描述子(cv)
传统机器学习算法:监督学习、线性回归、逻辑斯蒂回归Boosting,K-Means,Naive Bayes,支持向量机
神经网络与深度学习,稀疏表示与低秩矩阵
模式识别与机器学习前沿:迁移学习,对抗学习
模式识别:
定义:通过计算机用数学技术方法来研究模式的自动处理和判读。特别是光学信息和声学信息
以汉字为例:对汉字进行处理,抽取主要特征并将特征与汉字的代码存储在计算机中。
识别就是将输入与计算机中所有字比较 “训练、匹配”
机器学习:
设计与分析一些让计算机可以自动“学习”的算法,利用经验改善系统自身性能
机器学习算法是一类从数据中自动分析获得规律,并利用规律对未知数据进行预测的算法。
常用领域:计算机视觉、自然语言处理、生物特征识别etc
模式识别=机器学习(没有定论),前者主要从工业界发展起来,后者源于计算机科学。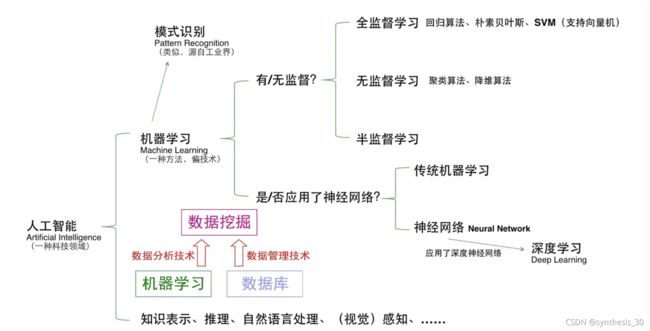
机器学习是从人工智能产生的一个重要学科分支,是实现智能化的关键
典型机器学习过程: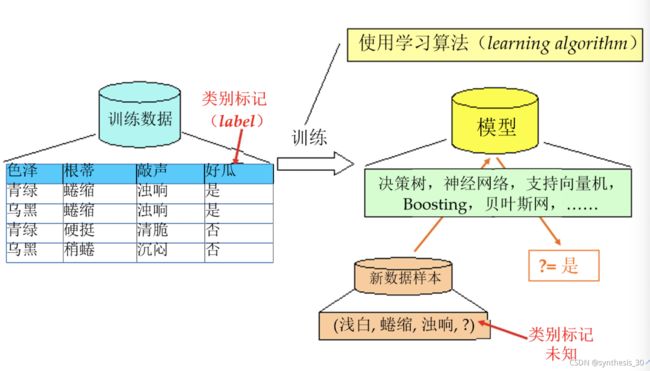
大数据时代,机器学习必不可少。收集、传输、存储大数据然后利用。若没有机器学习分析大数据,利用便无法做到。
数据转变为信息的三大关键技术:机器学习、云计算、众包
基本术语:
监督学习:分类回归
无监督学习:聚类、密度估计
强化学习:基于环境而行动,以取得最大化预期利益
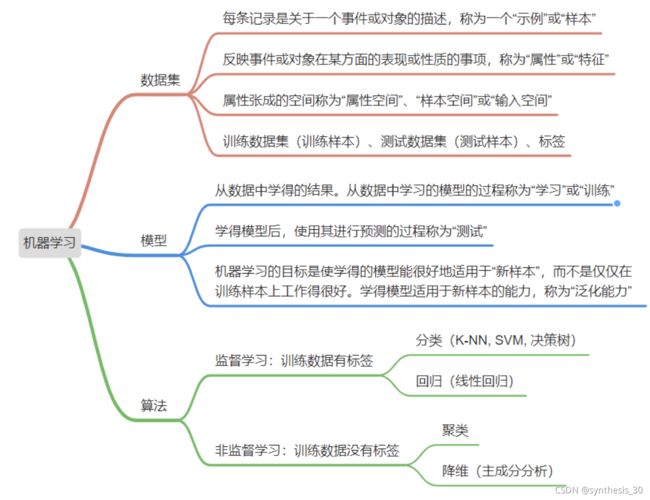
数据集:记录的组合
训练,学习:从数据中学得模型的过程,通过执行学习算法完成
测试:学得模型后使用模型进行预测的过程
示例=样本:记录一个事件或对象的描述(melon)
样例:拥有了标记信息的示例(good melon)
属性=特征:反映事件或对象在某方面的表现或性质的事项
属性值:red/green;2/3;etc
属性空间=样本空间=输入空间:将三个属性作为3个坐标轴,长成一个描述西瓜的三维空间
特征向量(=示例):空间中每个点对应一个坐标向量
标记空间、输出空间:所有标记的集合(good/bad/soso)
假设,真相,学习器:对应关于数据的某种潜在的规律;这种潜在规律自身;学习算法在给定数据和参数空间上的实例化。
分类问题(二分类:正类反类、多分类、正类负类):想要预测的是离散值(好/坏)
回归问题:想要预测的是连续值(0.95/0.32)
聚类(clustering):训练集中的西瓜分为若干组 簇:每一组
未见样本、未知分布、独立同分布i.i.d.:假设样本空间中全部样本服从于一个未知分布D,我们获得的每个样本都是独立地从这个分布上采样获得的
泛化generalization:学得的模型适用于新样本的能力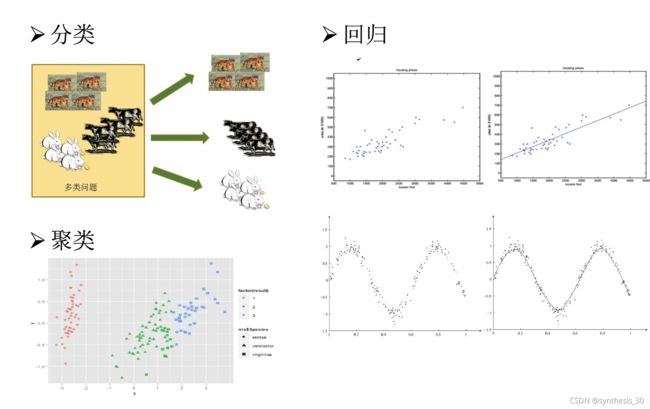
机器学习基本过程:
表示:将数据对象特征化表示
训练:给定一个数据样本集,从中学习出规律(模型)不仅适用于训练数据,也适用于未知样本
测试:对于一个新的数据样本,利用学到的模型进行预测
样本表示的方法
向量表示法
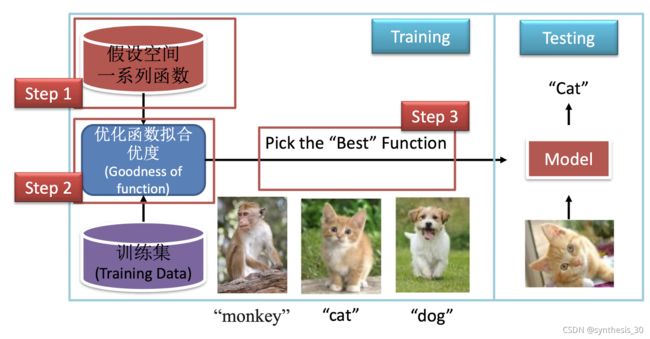
训练和测试
机器学习大概是寻找学习函数f的过程
模型评估与选择
NO Free Lunch Theorem
每个硬币都有两面。在所有问题出现机会相同的情况下,一个算法a在某些问题上比另一个算法b好,必然存在另一些问题b比a好。
实际工程中我们关注是有重点的,因此可以选出“较好的算法”。但学理上,脱离具体问题空谈“什么学习算法更好”是没有意义的事情。
机器判断的基本假设:特征差距小的样本更可能是同一类
概念
误差
样本输出与预测输出之间的差异
分为:训练误差、测试误差、泛化误差
泛化误差越小越好,经验误差是否越小越好?不是!会出现过拟合
欠拟合
对训练样本的一般性质尚未学好
过拟合
学习器把训练样本学习的太好,将训练样本本身的特点当作所有样本的一般性质,导致泛化能力下降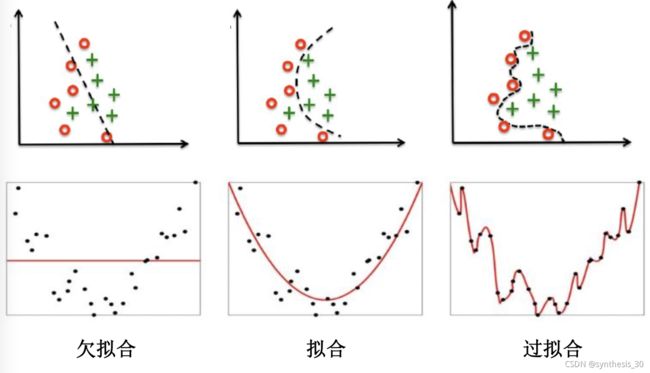
模型选择
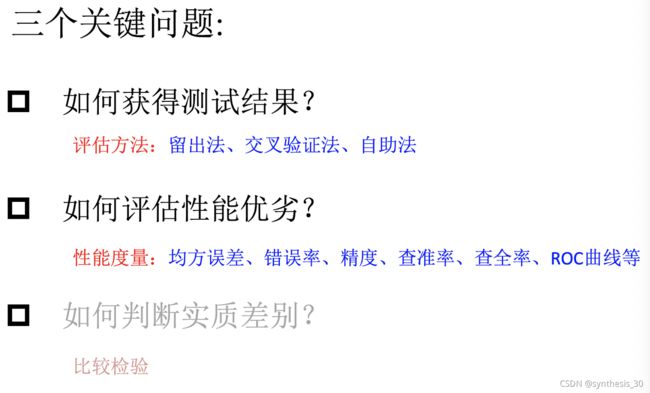
评估方法:获取测试结果
关键:如何获得测试集?假设测试集是从样本真实分布中独立采样获得,将测试集上的测试误差作为泛化误差的近似,测试集和训练集应当互斥
常见方法:留出法、k-折交叉验证法、自助法
留出法
直接将数据集划分为两个互斥集合
训练/测试集划分要尽可能保持数据分布的一致性
一般若干次随机划分,重复实验取平均值
训练测试样本比例通常2:1~4:1
k-折交叉验证法
将数据集分层采样划分为k个大小相似的互斥子集,每次用k-1个子集并集作为训练集,余下的子集作为测试集,最终返回k个测试结果的均值,k最常用取值为10

由于划分k个子集存在多种方式,为了减小样本划分引起的区别,k折交叉验证通常随机使用不同的划分重复p次,最终评估结果是p次k折验证结果的均值。eg:10次10折交叉验证

自助法
自助采样法作为基础,对数据集D有放回采样m次得到训练集D‘,D/D’用作测试集
实际模型与预期模型都使用m个训练样本
约有1/3的样本没有在训练集中出现
从初始数据集中产生多个不同的训练集,对集成学习有很大的好处
在数据集较小,难以有效划分训练/测试集时很有用;由于改变了数据集分布可能引入估计偏差,在数据量足够时,留出法和交叉验证法更加常用。
“调参”与最终模型
算法的参数:超参数,人工设定
模型参数:由学习确定
调参过程类似:先产生若干模型,然后基于某种评估方法进行选择
参数调的好不好对最终性能有关键影响
区分:训练集、测试集、验证集(validation set)
算法参数选定后,注意要用“训练集+验证集”重新训练最终模型
性能度量:评估性能优劣
衡量模型泛化能力的评价标准,反应任务需求
使用不同性能度量往往导致不同评判结果

什么样的模型好,不仅取决于算法和数据,还取决于任务需求

信息检索,Web搜索等场景中经常需要衡量正例被预测出来的比率或者预测出来正例中正确的比率,此时查准率和查全率比错误率和精度更加合适。
统计真实标记和预测结果的组合可得到“混淆矩阵”
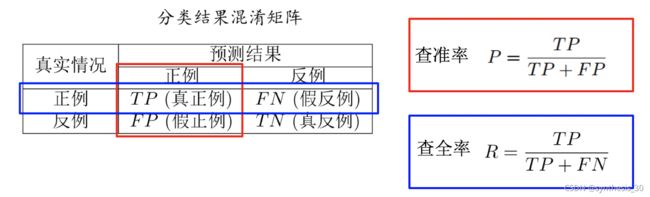

根据学习器的预测结果按照正例可能性大小对样例进行排序,并逐个把样本作为正例进行预测,可以得到查准率-查全率曲线——P-R曲线 。
平衡点BEP是曲线上查准率=查全率时的取值,可用来度量P-R曲线有交叉的分类器性能高低

比BEP更常用的F1度量 (F-score)
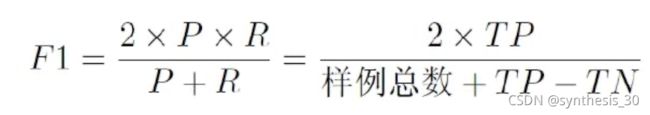
如果对查准率/查全率有不同偏好:

AUC、ROC:
 关于性能比较:
关于性能比较:
1、测试性能并不等于泛化性能
2、测试性能随着测试集的变化而变化
3、很多机器学习算法本身具有一定随机性
直接选取相应的评估方法在相应的度量下比较大小是不可取的QAQ
假设检验为学习器性能比较提供了重要依据,基于其结果我们可以推断出若在测试集上观察到学习器A比B好,则A的泛化性能是否在统计意义上优于B,以及这个结论的可靠性有多大。
误差:

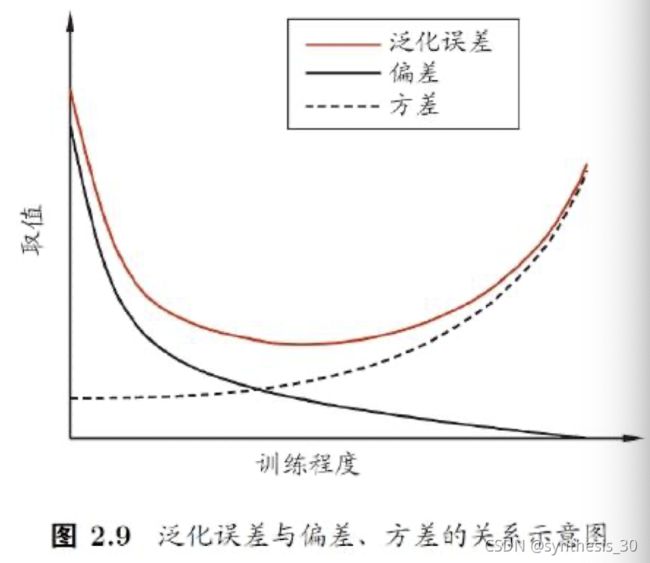
偏差-方差窘境:
一般而言,偏差和方差存在冲突。
当训练能力不足时,学习器拟合能力不强,偏差主导
随着训练程度加深,学习器拟合能力逐渐增强,方差逐渐主导
训练充足后,拟合能力很强,方差主导
比较检验:判断实质差别(暂略)
小结