PyTorch 源码解读之 DP & DDP:模型并行和分布式训练解析
本文介绍 PyTorch 里的数据并行训练,涉及 nn.DataParallel (DP) 和 nn.parallel.DistributedDataParallel (DDP) 两个模块(基于 1.7 版本),涵盖分布式训练的原理以及源码解读(大多以汉字注释,记得仔细读一下 comment )。内容组织如下:
0 数据并行
1 DP
1.1 使用
1.2 原理
1.3 实现
1.4 分析
2 DDP
2.1 使用
2.2 原理
2.3 实现
0 数据并行
当一张 GPU 可以存储一个模型时,可以采用数据并行得到更准确的梯度或者加速训练,即每个 GPU 复制一份模型,将一批样本分为多份输入各个模型并行计算。因为求导以及加和都是线性的,数据并行在数学上也有效。
假设我们一个 batch 有  个样本,一共有
个样本,一共有  个 GPU 每个 GPU 分到
个 GPU 每个 GPU 分到 ![]() 个样本。假设样本刚好等分,则有
个样本。假设样本刚好等分,则有 ![]() 。我们考虑总的损失函数
。我们考虑总的损失函数 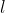 对参数
对参数  的导数:
的导数:
那么接下来我们看一下 PyTorch 究竟是怎么实现数据并行的。
1 DP
1.1 使用
DP 的好处是,使用起来非常方便,只需要将原来单卡的 module 用 DP 改成多卡:
model = nn.DataParallel(model)1.2 原理
DP 基于单机多卡,所有设备都负责计算和训练网络,除此之外, device[0] (并非 GPU 真实标号而是输入参数 device_ids 首位) 还要负责整合梯度,更新参数。图 1 即为 GPU 0 作为 device[0] 的例子。从图中我们可以看出,有三个主要过程:
- 过程一(图中红色部分):各卡分别计算损失和梯度
- 过程二(图中蓝色部分):所有梯度整合到 device[0]
- 过程三(图中绿色部分):device[0] 进行参数更新,其他卡拉取 device[0] 的参数进行更新
所有卡都并行运算(图中红色),将梯度收集到 device[0](图中浅蓝色)和 device[0] 分享模型参数给其他 GPU(图中绿色)三个主要过程。
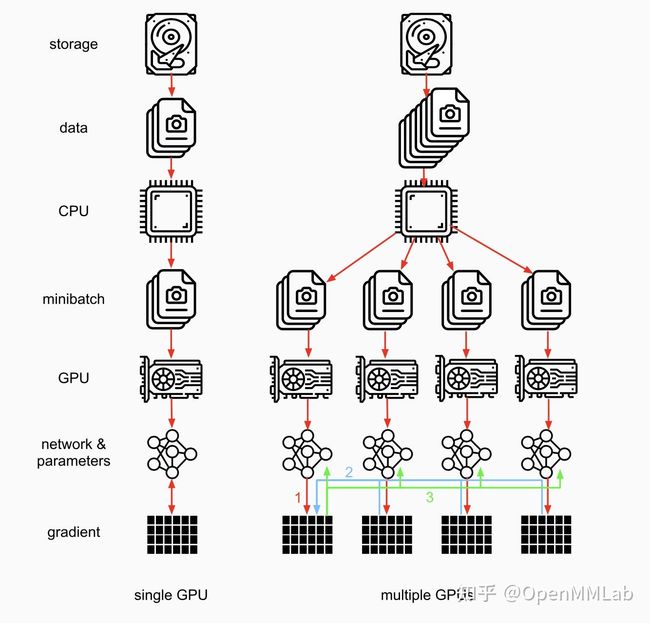
图 1: GPU 0 as device[0],原图见 [2]
虽然 DP 只能实现单机训练不能算是严格意义上的分布式训练(多个节点),但是其原理和分布式训练算法里的 Parameter Server 架构很相近,我们借用 PS 的伪代码来说明一下。

图 2: PS,原图见 [3]
我们可以看到 PS 的并行梯度下降流程分为四部分:
Task Scheduler:负责加载数据并分发数据至每个 worker 节点,并执行多轮迭代。
在每轮迭代中,worker 负责:
- 初始化:载入数据并将全部模型参数从 server 节点拉下来(图 1 绿色)
- 梯度计算:利用该节点的数据计算梯度(图 1 红色)并将梯度更新到 server 节点(图 1 蓝色)
Server 负责:
- 汇总梯度
- 更新参数
OK, 现在我们已经知道了 DP 使用的算法,接下来我们看一下 PyTorch 是如何实现的。
1.3 实现
这一节主要讨论 DP 的实现,首先先贴上源码(顺便看一下comment 部分):
class DataParallel(Module):
def __init__(self, module, device_ids=None, output_device=None, dim=0):
super(DataParallel, self).__init__()
# 检查是否有可用的 GPU
device_type = _get_available_device_type()
if device_type is None:
self.module = module
self.device_ids = []
return
# 默认使用所有可见的 GPU
if device_ids is None:
device_ids = _get_all_device_indices()
# 默认 server 是 device_ids 列表上第一个
if output_device is None:
output_device = device_ids[0]
self.dim = dim
self.module = module
self.device_ids = list(map(lambda x: _get_device_index(x, True), device_ids))
self.output_device = _get_device_index(output_device, True)
self.src_device_obj = torch.device(device_type, self.device_ids[0])
# 检查负载是否平衡, 不平衡(指内存或者处理器 max/min > 0.75 会有警告)
_check_balance(self.device_ids)
# 单卡
if len(self.device_ids) == 1:
self.module.to(self.src_device_obj)
def forward(self, *inputs, **kwargs):
# 没 GPU 可用
if not self.device_ids:
return self.module(*inputs, **kwargs)
# 运行前 GPU device_ids[0] (即我们的 server )上必须有 parallelized module 的parameters 和 buffers
# 因为 DP 保证 GPU device_ids[0] 和 base parallelized module 共享存储
# 所以在device[0] 上的 in-place 更新也会被保留下来,其他的则不会
for t in chain(self.module.parameters(), self.module.buffers()):
if t.device != self.src_device_obj:
raise RuntimeError("module must have its parameters and buffers "
"on device {} (device_ids[0]) but found one of "
"them on device: {}".format(self.src_device_obj, t.device))
# nice 现在 device[0] 上已经有了 module 和 input, 接下来我们就要开始 PS 算法了
# 可以开始看正文了
inputs, kwargs = self.scatter(inputs, kwargs, self.device_ids)
# 如果仅有单卡可用,直接单卡计算,不用并行
if len(self.device_ids) == 1:
return self.module(*inputs[0], **kwargs[0])
replicas = self.replicate(self.module, self.device_ids[:len(inputs)])
outputs = self.parallel_apply(replicas, inputs, kwargs)
return self.gather(outputs, self.output_device)
def replicate(self, module, device_ids):
return replicate(module, device_ids, not torch.is_grad_enabled())
def scatter(self, inputs, kwargs, device_ids):
return scatter_kwargs(inputs, kwargs, device_ids, dim=self.dim)
def parallel_apply(self, replicas, inputs, kwargs):
return parallel_apply(replicas, inputs, kwargs, self.device_ids[:len(replicas)])
def gather(self, outputs, output_device):
return gather(outputs, output_device, dim=self.dim)从 forward 函数可以看出,关键函数有 scatter, replicate, parallel_apply 和 gather,我们一个一个看一下。
首先是 scatter 函数,即 scatter_kwargs 函数。
def scatter_kwargs(inputs, kwargs, target_gpus, dim=0):
r"""Scatter with support for kwargs dictionary"""
# 主要函数
inputs = scatter(inputs, target_gpus, dim) if inputs else []
kwargs = scatter(kwargs, target_gpus, dim) if kwargs else []
# 用空项补全使 inputs 和 kwargs 长度相当
if len(inputs) < len(kwargs):
inputs.extend([() for _ in range(len(kwargs) - len(inputs))])
elif len(kwargs) < len(inputs):
kwargs.extend([{} for _ in range(len(inputs) - len(kwargs))])
# 返回 tuple
inputs = tuple(inputs)
kwargs = tuple(kwargs)
return inputs, kwargsscatter_kwargs 函数中最重要的就是 scatter 函数,负责将 tensor 分成大概相等的块并将他们分给不同的 GPU。对其他的数据类型,则是复制分散给不同的 GPU 。
def scatter(inputs, target_gpus, dim=0):
r"""
Slices tensors into approximately equal chunks and
distributes them across given GPUs. Duplicates
references to objects that are not tensors.
"""
def scatter_map(obj):
if isinstance(obj, torch.Tensor):
return Scatter.apply(target_gpus, None, dim, obj)
if is_namedtuple(obj):
return [type(obj)(*args) for args in zip(*map(scatter_map, obj))]
if isinstance(obj, tuple) and len(obj) > 0:
return list(zip(*map(scatter_map, obj)))
if isinstance(obj, list) and len(obj) > 0:
return [list(i) for i in zip(*map(scatter_map, obj))]
if isinstance(obj, dict) and len(obj) > 0:
return [type(obj)(i) for i in zip(*map(scatter_map, obj.items()))]
return [obj for targets in target_gpus]
# After scatter_map is called, a scatter_map cell will exist. This cell
# has a reference to the actual function scatter_map, which has references
# to a closure that has a reference to the scatter_map cell (because the
# fn is recursive). To avoid this reference cycle, we set the function to
# None, clearing the cell
try:
res = scatter_map(inputs)
finally:
scatter_map = None
return res其中,针对 tensor 的函数,
class Scatter(Function):
@staticmethod
def forward(ctx, target_gpus, chunk_sizes, dim, input):
target_gpus = [_get_device_index(x, True) for x in target_gpus]
ctx.dim = dim
ctx.input_device = input.get_device() if input.device.type != "cpu" else -1
streams = None
if torch.cuda.is_available() and ctx.input_device == -1:
# Perform CPU to GPU copies in a background stream
# 新建 cuda stream
streams = [_get_stream(device) for device in target_gpus]
# 真正的操作
outputs = comm.scatter(input, target_gpus, chunk_sizes, ctx.dim, streams)
# Synchronize with the copy stream
if streams is not None:
for i, output in enumerate(outputs):
with torch.cuda.device(target_gpus[i]):
main_stream = torch.cuda.current_stream()
main_stream.wait_stream(streams[i])
output.record_stream(main_stream)
return outputs
@staticmethod
def backward(ctx, *grad_output):
return None, None, None, Gather.apply(ctx.input_device, ctx.dim, *grad_output)comm.scatter 依赖于 C++,就不介绍了。
回顾 DP 代码块,我们已经运行完 scatter函数,即将一个 batch 近似等分成更小的 batch。接下来我们要看 replicate 函数和 gather 函数 (假设我们有不少于两张卡)。
# DP forward 里的代码
replicas = self.replicate(self.module, self.device_ids[:len(inputs)])
# 实现
def replicate(network, devices, detach=False):
if not _replicatable_module(network):
raise RuntimeError("Cannot replicate network where python modules are "
"childrens of ScriptModule")
if not devices:
return []
# 需要复制到哪些 GPU, 复制多少份
devices = [_get_device_index(x, True) for x in devices]
num_replicas = len(devices)
# 复制 parameters
params = list(network.parameters())
param_indices = {param: idx for idx, param in enumerate(params)}
# 拉到代码块底部看原函数,然后再回来
param_copies = _broadcast_coalesced_reshape(params, devices, detach)
# 复制 buffers
buffers = list(network.buffers())
buffers_rg = []
buffers_not_rg = []
for buf in buffers:
if buf.requires_grad and not detach:
buffers_rg.append(buf)
else:
buffers_not_rg.append(buf)
# 记录需要和不需要求导的 buffer 的 index
buffer_indices_rg = {buf: idx for idx, buf in enumerate(buffers_rg)}
buffer_indices_not_rg = {buf: idx for idx, buf in enumerate(buffers_not_rg)}
# 分别拷贝,这个咱们已经会了
buffer_copies_rg = _broadcast_coalesced_reshape(buffers_rg, devices, detach=detach)
buffer_copies_not_rg = _broadcast_coalesced_reshape(buffers_not_rg, devices, detach=True)
# 现在开始拷贝网络
# 准备过程:将 network.modules() 变成list
# 然后再为之后复制的模型准备好空的 list 和 indices
modules = list(network.modules())
module_copies = [[] for device in devices]
module_indices = {}
scriptmodule_skip_attr = {"_parameters", "_buffers", "_modules", "forward", "_c"}
for i, module in enumerate(modules):
module_indices[module] = i
for j in range(num_replicas):
replica = module._replicate_for_data_parallel()
# This is a temporary fix for DDP. DDP needs to access the
# replicated model parameters. It used to do so through
# `mode.parameters()`. The fix added in #33907 for DP stops the
# `parameters()` API from exposing the replicated parameters.
# Hence, we add a `_former_parameters` dict here to support DDP.
replica._former_parameters = OrderedDict()
module_copies[j].append(replica)
# 接下来分别复制 module,param,buffer
for i, module in enumerate(modules):
for key, child in module._modules.items():
if child is None:
for j in range(num_replicas):
replica = module_copies[j][i]
replica._modules[key] = None
else:
module_idx = module_indices[child]
for j in range(num_replicas):
replica = module_copies[j][i]
setattr(replica, key, module_copies[j][module_idx])
for key, param in module._parameters.items():
if param is None:
for j in range(num_replicas):
replica = module_copies[j][i]
replica._parameters[key] = None
else:
param_idx = param_indices[param]
for j in range(num_replicas):
replica = module_copies[j][i]
param = param_copies[j][param_idx]
# parameters in replicas are no longer leaves,
# so setattr them as non-parameter attributes
setattr(replica, key, param)
# expose the parameter for DDP
replica._former_parameters[key] = param
for key, buf in module._buffers.items():
if buf is None:
for j in range(num_replicas):
replica = module_copies[j][i]
replica._buffers[key] = None
else:
if buf.requires_grad and not detach:
buffer_copies = buffer_copies_rg
buffer_idx = buffer_indices_rg[buf]
else:
buffer_copies = buffer_copies_not_rg
buffer_idx = buffer_indices_not_rg[buf]
for j in range(num_replicas):
replica = module_copies[j][i]
setattr(replica, key, buffer_copies[j][buffer_idx])
return [module_copies[j][0] for j in range(num_replicas)]
# !!!从replicate来看这里
def _broadcast_coalesced_reshape(tensors, devices, detach=False):
from ._functions import Broadcast
# 先看 else 的 comment,因为不 detach 也会用到同样的函数
if detach:
return comm.broadcast_coalesced(tensors, devices)
else:
# Use the autograd function to broadcast if not detach
if len(tensors) > 0:
# 下拉看源码
tensor_copies = Broadcast.apply(devices, *tensors)
return [tensor_copies[i:i + len(tensors)]
for i in range(0, len(tensor_copies), len(tensors))]
else:
return []
# Broadcast.apply
class Broadcast(Function):
@staticmethod
def forward(ctx, target_gpus, *inputs):
assert all(i.device.type != 'cpu' for i in inputs), (
'Broadcast function not implemented for CPU tensors'
)
target_gpus = [_get_device_index(x, True) for x in target_gpus]
ctx.target_gpus = target_gpus
if len(inputs) == 0:
return tuple()
ctx.num_inputs = len(inputs)
# input 放在 device[0]
ctx.input_device = inputs[0].get_device()
# 和 detach 的情况一样
outputs = comm.broadcast_coalesced(inputs, ctx.target_gpus)
# comm.broadcast_coalesced 的代码
# tensors 必须在同一个设备,CPU 或者 GPU; devices 即是要拷贝到的设备;buffer_size 则是最大的buffer
# 这里用到 buffer 将小张量合并到缓冲区以减少同步次数
# def broadcast_coalesced(tensors, devices, buffer_size=10485760):
# devices = [_get_device_index(d) for d in devices]
# return torch._C._broadcast_coalesced(tensors, devices, buffer_size)
non_differentiables = []
for idx, input_requires_grad in enumerate(ctx.needs_input_grad[1:]):
if not input_requires_grad:
for output in outputs:
non_differentiables.append(output[idx])
ctx.mark_non_differentiable(*non_differentiables)
return tuple([t for tensors in outputs for t in tensors])
@staticmethod
def backward(ctx, *grad_outputs):
return (None,) + ReduceAddCoalesced.apply(ctx.input_device, ctx.num_inputs, *grad_outputs)下面继续 parallel_apply 部分。⚠️ DP 和 DDP 共用 parallel_apply 代码
# DP 代码
outputs = self.parallel_apply(replicas, inputs, kwargs)
# threading 实现,用前面准备好的 replica 和输入数据,然后
# for 循环启动多线程
# 源码
def parallel_apply(modules, inputs, kwargs_tup=None, devices=None):
# 每个 GPU 都有模型和输入
assert len(modules) == len(inputs)
# 确保每个 GPU 都有相应的数据,如没有就空白补全
if kwargs_tup is not None:
# 咱们在 scatter 已经补全了
assert len(modules) == len(kwargs_tup)
else:
kwargs_tup = ({},) * len(modules)
if devices is not None:
assert len(modules) == len(devices)
else:
devices = [None] * len(modules)
devices = [_get_device_index(x, True) for x in devices]
# 多线程实现
lock = threading.Lock()
results = {}
grad_enabled, autocast_enabled = torch.is_grad_enabled(), torch.is_autocast_enabled()
# 定义 worker
def _worker(i, module, input, kwargs, device=None):
torch.set_grad_enabled(grad_enabled)
if device is None:
device = get_a_var(input).get_device()
try:
with torch.cuda.device(device), autocast(enabled=autocast_enabled):
# this also avoids accidental slicing of `input` if it is a Tensor
if not isinstance(input, (list, tuple)):
input = (input,)
output = module(*input, **kwargs)
with lock:
# 并行计算得到输出
results[i] = output
except Exception:
with lock:
results[i] = ExceptionWrapper(
where="in replica {} on device {}".format(i, device))
if len(modules) > 1:
# 如有一个进程控制多个 GPU ,起多个线程
# 需要强调一下,虽然 DDP 推荐单卡单进程,即每次调用 DDP device_ids 都只输入一张卡的 id(通常是 args.local_rank),但是如果输入多个 device_id,此时 DDP 就是单进程多线程控制多卡,和 DP 一样,关于 DDP 的解读可以看下文
threads = [threading.Thread(target=_worker,
args=(i, module, input, kwargs, device))
for i, (module, input, kwargs, device) in
enumerate(zip(modules, inputs, kwargs_tup, devices))]
for thread in threads:
thread.start()
for thread in threads:
thread.join()
else:
# 一个 GPU 一个进程 ( DDP 推荐操作)
_worker(0, modules[0], inputs[0], kwargs_tup[0], devices[0])
outputs = []
for i in range(len(inputs)):
output = results[i]
# error handle
if isinstance(output, ExceptionWrapper):
output.reraise()
outputs.append(output)
# 输出 n 个计算结果
return outputs现在我们已经得到并行计算的结果了,接下来我们要将结果收集到 device[0]。
# DP 代码
return self.gather(outputs, self.output_device)
# 收集到 devices[0]
# 源码
def gather(outputs, target_device, dim=0):
r"""
Gathers tensors from different GPUs on a specified device
(-1 means the CPU).
"""
def gather_map(outputs):
out = outputs[0]
if isinstance(out, torch.Tensor):
return Gather.apply(target_device, dim, *outputs)
if out is None:
return None
if isinstance(out, dict):
if not all((len(out) == len(d) for d in outputs)):
raise ValueError('All dicts must have the same number of keys')
return type(out)(((k, gather_map([d[k] for d in outputs]))
for k in out))
return type(out)(map(gather_map, zip(*outputs)))
# Recursive function calls like this create reference cycles.
# Setting the function to None clears the refcycle.
try:
res = gather_map(outputs)
finally:
gather_map = None
return res
# Gather 源码
class Gather(Function):
@staticmethod
def forward(ctx, target_device, dim, *inputs):
assert all(i.device.type != 'cpu' for i in inputs), (
'Gather function not implemented for CPU tensors'
)
target_device = _get_device_index(target_device, True)
ctx.target_device = target_device
ctx.dim = dim
ctx.input_gpus = tuple(i.get_device() for i in inputs)
if all(t.dim() == 0 for t in inputs) and dim == 0:
inputs = tuple(t.view(1) for t in inputs)
warnings.warn('Was asked to gather along dimension 0, but all '
'input tensors were scalars; will instead unsqueeze '
'and return a vector.')
ctx.unsqueezed_scalar = True
else:
ctx.unsqueezed_scalar = False
ctx.input_sizes = tuple(i.size(ctx.dim) for i in inputs)
return comm.gather(inputs, ctx.dim, ctx.target_device)
@staticmethod
def backward(ctx, grad_output):
scattered_grads = Scatter.apply(ctx.input_gpus, ctx.input_sizes, ctx.dim, grad_output)
if ctx.unsqueezed_scalar:
scattered_grads = tuple(g[0] for g in scattered_grads)
return (None, None) + scattered_grads
# comm.gather 涉及到 C++,具体实现咱也不讲了 ;)
# Gathers tensors from multiple GPU devices.
def gather(tensors, dim=0, destination=None, *, out=None):
tensors = [_handle_complex(t) for t in tensors]
if out is None:
if destination == -1:
warnings.warn(
'Using -1 to represent CPU tensor is deprecated. Please use a '
'device object or string instead, e.g., "cpu".')
destination = _get_device_index(destination, allow_cpu=True, optional=True)
return torch._C._gather(tensors, dim, destination)
else:
if destination is not None:
raise RuntimeError(
"'destination' must not be specified when 'out' is specified, but "
"got destination={}".format(destination))
return torch._C._gather_out(tensors, out, dim)因为大量实现都依赖 C++,这篇笔记就不涉及了。
最后,用一张图形象地看一下 DP Module 究竟怎么执行的,具体看第一行和第三行:
前向传播的时候我们会先用 Scatter 函数将数据从 device[0] 分配并复制到不同的卡,之后用 Replicate 函数将模型从 device[0] 复制到不同的卡,之后各个卡都有了同样的模型和不同的数据,分别调用 forward 计算损失和梯度。
反向传播的时候,我们会将梯度收集到 device[0] 然后在 device[0] 更新参数。
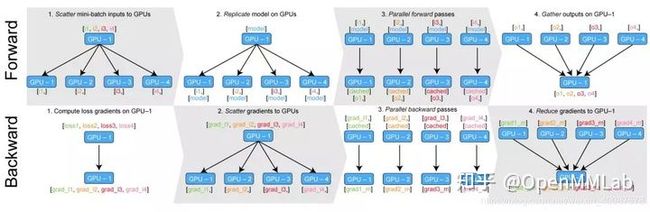
Fig. 3: DP Module流程图,原图见[4]
1.4 分析
- 负载不均衡
device[0] 负载大一些
- 通信开销
假设有 个 GPU, 完成一次通信需要时间 ![]() ,那么使用 PS 算法,总共需要花费时间
,那么使用 PS 算法,总共需要花费时间 ![]()
- 单进程
The difference betweenDistributedDataParallelandDataParallelis:DistributedDataParalleluses multiprocessing where a process is created for each GPU, whileDataParalleluses multithreading. By using multiprocessing, each GPU has its dedicated process, this avoids the performance overhead caused by GIL of Python interpreter.
官方文档
- Global Interpreter Lock (GIL)全局解释器锁,简单来说就是,一个 Python 进程只能利用一个 CPU kernel,即单核多线程并发时,只能执行一个线程。考虑多核,多核多线程可能出现线程颠簸 (thrashing) 造成资源浪费,所以 Python 想要利用多核最好是多进程。
2 DDP
2.1 使用
import argparse
import torch
from torch.nn.parallel import DistributedDataParallel as DDP
parser = argparse.ArgumentParser()
parser.add_argument("--save_dir", default='')
parser.add_argument("--local_rank", default=-1)
parser.add_argument("--world_size", default=1)
args = parser.parse_args()
# 初始化后端
# world_size 指的是总的并行进程数目
# 比如16张卡单卡单进程 就是 16
# 但是如果是8卡单进程 就是 1
# 等到连接的进程数等于world_size,程序才会继续运行
torch.distributed.init_process_group(backend='nccl',
world_size=ws,
init_method='env://')
torch.cuda.set_device(args.local_rank)
device = torch.device(f'cuda:{args.local_rank}')
model = nn.Linear(2,3).to(device)
# train dataset
# train_sampler
# train_loader
# 初始化 DDP,这里我们通过规定 device_id 用了单卡单进程
# 实际上根据我们前面对 parallel_apply 的解读,DDP 也支持一个进程控制多个线程利用多卡
model = DDP(model,
device_ids=[args.local_rank],
output_device=args.local_rank).to(device)
# 保存模型
if torch.distributed.get_rank() == 0:
torch.save(model.module.state_dict(),
'results/%s/model.pth' % args.save_dir)2.2 原理
- 区别
- 多进程
和 DP 不同, DDP 采用多进程,最推荐的做法是每张卡一个进程从而避免上一节所说单进程带来的影响。前文也提到了 DP 和 DDP 共用一个 parallel_apply 函数,所以 DDP 同样支持单进程多线程多卡操作,自然也支持多进程多线程,不过需要注意一下 world_size。 - 通信效率
DP 的通信成本随着 GPU 数量线性增长,而 DDP 支持 Ring AllReduce,其通信成本是恒定的,与 GPU 数量无关。 - 同步参数
DP 通过收集梯度到 device[0],在device[0] 更新参数,然后其他设备复制 device[0] 的参数实现各个模型同步;
DDP 通过保证初始状态相同并且改变量也相同(指同步梯度) ,保证模型同步。
- 多进程
- Ring AllReduce
Fig. 4: Ring AllReduce 流程图,原图见 [7]
假设我们有 个 GPU,传输总量是  ,
,  为每次通信上限。
为每次通信上限。
首先我们将要传输的梯度等分成 份,则每台机器每次需要传输 ![]() 。传输
。传输  次可以收集到一个完整梯度(如动图 5 所示),之后再传输 次将梯度分给所有 GPU(如动图 6 所示)。
次可以收集到一个完整梯度(如动图 5 所示),之后再传输 次将梯度分给所有 GPU(如动图 6 所示)。
举个例子,假设现有 5 个 GPU,那么就将梯度分为 5 份,如下图,分别是 ![]() , 这里的
, 这里的  指的是 GPU 编号。
指的是 GPU 编号。
Scatter Reduce 流程,从 diagonal 的位置开始传,每次传输时 GPU 之间只有一个块在传输,比如 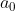 ,在传播 4 次后 GPU 4 上就有了一个完整的梯度块。
,在传播 4 次后 GPU 4 上就有了一个完整的梯度块。

图 5: Scatter Reduce 流程图,原图见 [7], gif 见 [8]
All Gather 的过程也类似,只是将收集到的完整梯度通过通信传播给所有参与的 GPU。
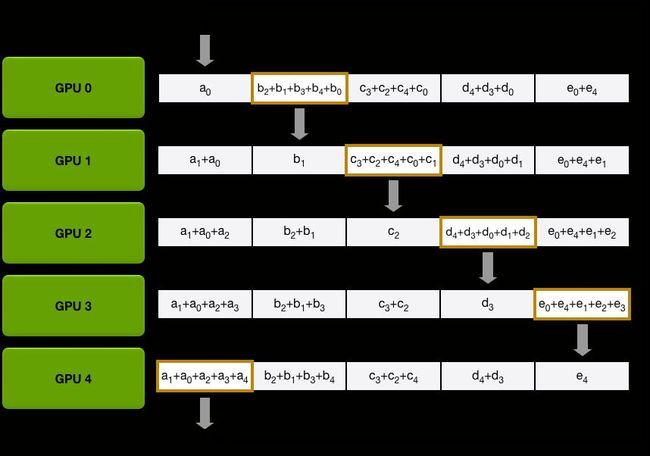
图 6: All Gather 流程图,原图见 [7], gif 见 [8]
这样,通信开销就只有 ![]() ,和 GPU 数量无关了。
,和 GPU 数量无关了。
- DDP
DDP 也是数据并行,所以每张卡都有模型和输入。我们以多进程多线程为例,每起一个进程,该进程的 device[0] 都会从本地复制模型,如果该进程仍有多线程,就像 DP,模型会从 device[0] 复制到其他设备。
DDP 通过 Reducer 来管理梯度同步。为了提高通讯效率, Reducer 会将梯度归到不同的桶里(按照模型参数的 reverse order, 因为反向传播需要符合这样的顺序),一次归约一个桶。其中桶的大小为参数 bucket_cap_mb 默认为 25,可根据需要调整。下图即为一个例子。
可以看到每个进程里,模型参数都按照倒序放在桶里,每次归约一个桶。
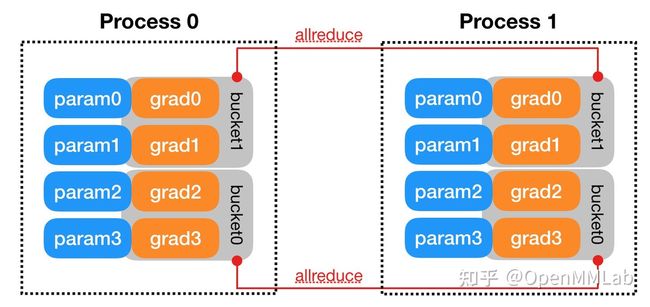
图 7: Gradient Bucketing 示意图,原图见 [10]
DDP 通过在构建时注册 autograd hook 进行梯度同步。反向传播时,当一个梯度计算好后,相应的 hook 会告诉 DDP 可以用来归约。当一个桶里的梯度都可以了,Reducer 就会启动异步 allreduce 去计算所有进程的平均值。allreduce 异步启动使得 DDP 可以边计算边通信,提高效率。当所有桶都可以了,Reducer 会等所有 allreduce 完成,然后将得到的梯度写到 param.grad。
2.3 实现
DDP 主要基于下图所示结构,本节我们会着重讲解 distributed.py 和 reducer.cpp 两个文件。至于 backend,NCCL 已经最优化了,建议直接用 NCCL,不过 NCCL 只支持 GPU Tensor 间通信。
图 8: 代码架构,原图见 [10]
终于可以看 DDP 的实现了!!首先我们贴上伪代码!
- 伪代码

图 9: DDP 伪代码,原图见 [11]
从 DDP 的伪代码我们可以看出,DDP 最重要的包括三部分:
- constructor
- 负责在构建的时候将 rank 0 的 state_dict() 广播 ➜ 保证所有网络初始状态相同;
- 初始化 buckets 并尽可能按逆序将 parameters 分配进 buckets ➜ 按桶通信提高效率;
- 为每个 parameter 加上 grad_accumulator 以及在 autograd_graph 注册 autograd_hook ➜ 在 backward 时负责梯度同步。
- forward
- 正常的 forward 操作;
- 如果 self.find_unused_parameters 设置为 True,DDP 会在 forward 结束时 traverse autograd graph 找到所有没用过的parameters 并标记为 ready ➜ 虽说这一步开销很大,但是有时计算动态图会改变,所以很必要。
- autograd_hook
- 这个 hook 是挂在 autograd graph 在 backward 时负责梯度同步的。当一个梯度计算好后,相应的 hook 会告诉 DDP 可以用来归约。当一个桶里的梯度都可以了,Reducer 就会启动异步 allreduce 去计算所有进程的平均值。当所有桶都可以了,Reducer 会等所有 allreduce 完成,然后将得到的梯度写到 param.grad。
好的,但现在为止我们应该对 DDP 有了大致了解了,接下来就一起看一下代码是怎么实现的!
- 通信
因为 DDP 依赖 c10d 的 ProcessGroup 进行通信,所以开始前我们先要有个 ProcessGroup 实例。这步可以通过 torch.distributed.init_process_group 实现。
- 构建
我们先贴上 DDP 初始化的源码,最重要的是 _ddp_init_helper 这个函数,负责多线程时复制模型、将 parameters 分组、创建 reducer 以及为 SyncBN 做准备等。这部分代码看 comment 就能懂,我们会重点说一下 dist.Reducer,作为管理器,自然很重要了。
class DistributedDataParallel(Module):
def __init__(self, module, device_ids=None,
output_device=None, dim=0, broadcast_buffers=True,
process_group=None,
bucket_cap_mb=25,
find_unused_parameters=False,
check_reduction=False,
gradient_as_bucket_view=False):
super(DistributedDataParallel, self).__init__()
assert any((p.requires_grad for p in module.parameters())), (
"DistributedDataParallel is not needed when a module "
"doesn't have any parameter that requires a gradient."
)
self.is_multi_device_module = len({p.device for p in module.parameters()}) > 1
distinct_device_types = {p.device.type for p in module.parameters()}
assert len(distinct_device_types) == 1, (
"DistributedDataParallel's input module must be on "
"the same type of devices, but input module parameters locate in {}."
).format(distinct_device_types)
self.device_type = list(distinct_device_types)[0]
if self.device_type == "cpu" or self.is_multi_device_module:
assert not device_ids and not output_device, (
"DistributedDataParallel device_ids and output_device arguments "
"only work with single-device GPU modules, but got "
"device_ids {}, output_device {}, and module parameters {}."
).format(device_ids, output_device, {p.device for p in module.parameters()})
self.device_ids = None
self.output_device = None
else:
# Use all devices by default for single-device GPU modules
if device_ids is None:
device_ids = _get_all_device_indices()
self.device_ids = list(map(lambda x: _get_device_index(x, True), device_ids))
if output_device is None:
output_device = device_ids[0]
self.output_device = _get_device_index(output_device, True)
if process_group is None:
self.process_group = _get_default_group()
else:
self.process_group = process_group
self.dim = dim
self.module = module
self.device = list(self.module.parameters())[0].device
self.broadcast_buffers = broadcast_buffers
self.find_unused_parameters = find_unused_parameters
self.require_backward_grad_sync = True
self.require_forward_param_sync = True
self.ddp_join_enabled = False
self.gradient_as_bucket_view = gradient_as_bucket_view
if check_reduction:
# This argument is no longer used since the reducer
# will ensure reduction completes even if some parameters
# do not receive gradients.
warnings.warn(
"The `check_reduction` argument in `DistributedDataParallel` "
"module is deprecated. Please avoid using it."
)
pass
# used for intra-node param sync and inter-node sync as well
self.broadcast_bucket_size = int(250 * 1024 * 1024)
#
# reduction bucket size
self.bucket_bytes_cap = int(bucket_cap_mb * 1024 * 1024)
# 保证初始状态一样
# Sync params and buffers
self._sync_params_and_buffers(authoritative_rank=0)
# 下拉看源码
self._ddp_init_helper()
def _sync_params_and_buffers(self, authoritative_rank=0):
module_states = list(self.module.state_dict().values())
if len(module_states) > 0:
self._distributed_broadcast_coalesced(
module_states,
self.broadcast_bucket_size,
authoritative_rank)
def _ddp_init_helper(self):
"""
Initialization helper function that does the following:
(1) replicating the module from device[0] to the other devices (前文提到 DDP 也支持一个进程多线程利用多卡,类似 DP ,这时候就会用到第一步)
(2) bucketing the parameters for reductions (把 parameter 分组,梯度通讯时,先得到梯度的会通讯)
(3) resetting the bucketing states
(4) registering the grad hooks (创建管理器)
(5) passing a handle of DDP to SyncBatchNorm Layer (为 SyncBN 准备)
"""
def parameters(m, recurse=True):
def model_parameters(m):
ps = m._former_parameters.values() \
if hasattr(m, "_former_parameters") \
else m.parameters(recurse=False)
for p in ps:
yield p
for m in m.modules() if recurse else [m]:
for p in model_parameters(m):
yield p
if self.device_ids and len(self.device_ids) > 1:
warnings.warn(
"Single-Process Multi-GPU is not the recommended mode for "
"DDP. In this mode, each DDP instance operates on multiple "
"devices and creates multiple module replicas within one "
"process. The overhead of scatter/gather and GIL contention "
"in every forward pass can slow down training. "
"Please consider using one DDP instance per device or per "
"module replica by explicitly setting device_ids or "
"CUDA_VISIBLE_DEVICES. "
)
# only create replicas for single-device CUDA modules
#
# TODO: we don't need to replicate params in here. they're always going to
# be broadcasted using larger blocks in broadcast_coalesced, so it might be
# better to not pollute the caches with these small blocks
self._module_copies = replicate(self.module, self.device_ids, detach=True)
self._module_copies[0] = self.module
for module_copy in self._module_copies[1:]:
for param, copy_param in zip(self.module.parameters(), parameters(module_copy)):
# Reducer requires param copies have the same strides across replicas.
# Fixes up copy_param strides in case replicate didn't match param strides.
if param.layout is torch.strided and param.stride() != copy_param.stride():
with torch.no_grad():
copy_param.set_(copy_param.clone()
.as_strided(param.size(), param.stride())
.copy_(copy_param))
copy_param.requires_grad = param.requires_grad
else:
self._module_copies = [self.module]
self.modules_params = [list(parameters(m)) for m in self._module_copies]
self.modules_buffers = [list(m.buffers()) for m in self._module_copies]
# Build tuple of (module, parameter) for all parameters that require grads.
modules_and_parameters = [
[
(module, parameter)
for module in replica.modules()
for parameter in filter(
lambda parameter: parameter.requires_grad,
parameters(module, recurse=False))
] for replica in self._module_copies]
# Build list of parameters.
parameters = [
list(parameter for _, parameter in replica)
for replica in modules_and_parameters]
# Checks if a module will produce a sparse gradient.
def produces_sparse_gradient(module):
if isinstance(module, torch.nn.Embedding):
return module.sparse
if isinstance(module, torch.nn.EmbeddingBag):
return module.sparse
return False
# Build list of booleans indicating whether or not to expect sparse
# gradients for the corresponding parameters.
expect_sparse_gradient = [
list(produces_sparse_gradient(module) for module, _ in replica)
for replica in modules_and_parameters]
# The bucket size limit is specified in the constructor.
# Additionally, we allow for a single small bucket for parameters
# that are defined first, such that their gradients don't spill into
# a much larger bucket, adding unnecessary latency after gradient
# computation finishes. Experiments showed 1MB is a reasonable value.
bucket_indices = dist._compute_bucket_assignment_by_size(
parameters[0],
[dist._DEFAULT_FIRST_BUCKET_BYTES, self.bucket_bytes_cap],
expect_sparse_gradient[0])
# Note: reverse list of buckets because we want to approximate the
# order in which their gradients are produced, and assume they
# are used in the forward pass in the order they are defined.
# 管理器
self.reducer = dist.Reducer(
parameters,
list(reversed(bucket_indices)),
self.process_group,
expect_sparse_gradient,
self.bucket_bytes_cap,
self.find_unused_parameters,
self.gradient_as_bucket_view)
# passing a handle to torch.nn.SyncBatchNorm layer
self._passing_sync_batchnorm_handle(self._module_copies)每个 DDP 进程都会创建本地 Reducer 在 backward 时管理梯度。
self.reducer = dist.Reducer(
parameters,
list(reversed(bucket_indices)),
self.process_group,
expect_sparse_gradient,
self.bucket_bytes_cap,
self.find_unused_parameters,
self.gradient_as_bucket_view)我们看 Reducer.cpp 可以发现,构建 Reducer 时,除了各种初始化,最重要的一步就是
{
const auto replica_count = replicas_.size();
grad_accumulators_.resize(replica_count);
for (size_t replica_index = 0; replica_index < replica_count;
replica_index++) {
const auto variable_count = replicas_[replica_index].size();
grad_accumulators_[replica_index].resize(variable_count);
for (size_t variable_index = 0; variable_index < variable_count;
variable_index++)
{
auto& variable = replicas_[replica_index][variable_index];
const auto index = VariableIndex(replica_index, variable_index);
// The gradient accumulator function is lazily initialized once.
// Therefore we can use its presence in the autograd graph as
// evidence that the parameter has participated in an iteration.
auto grad_accumulator =
torch::autograd::impl::grad_accumulator(variable);
#ifndef _WIN32
using torch::distributed::autograd::ThreadLocalDistAutogradContext;
#endif
// grad_accumulator 执行完后,autograd_hook 就会运行
hooks.emplace_back(
grad_accumulator->add_post_hook(
torch::make_unique(
[=](const torch::autograd::variable_list& outputs,
const torch::autograd::variable_list& /* unused */){
#ifndef WIN32
this->rpc_context.set(
ThreadLocalDistAutogradContext::getContextPtr());
#endif
this->autograd_hook(index);
return outputs;
})),
grad_accumulator);
// Map raw function pointer to replica index and parameter index.
// This is used later on when the autograd graph is traversed
// to check for parameters for which no gradient is computed.
func_[grad_accumulator.get()] = index;
// The gradient accumulator is stored as weak_ptr in the autograd
// metadata of the variable, so we have to keep it alive here for
// the raw pointer to be valid.
grad_accumulators_[replica_index][variable_index] =
std::move(grad_accumulator);
}
}
}
// std::unordered_map func_;
// func_ 存了grad_accumulator & index 的对应,方便我们之后在 autograd graph 寻找 unused parameters
// std::vector>>
// grad_accumulators_;
// grad_accumulators_ 对应的 index 存了相应的 grad_accumulator
// std::vector>>
// hooks_;
其中,发挥重要功能的 autograd_hook 如下:
void Reducer::autograd_hook(VariableIndex index) {
std::lock_guard lock(this->mutex_);
if (find_unused_parameters_) {
// 在 no_sync 时,只要参数被用过一次,就会被标记为用过
// Since it gets here, this param has been used for this iteration. We want
// to mark it in local_used_maps_. During no_sync session, the same var can
// be set multiple times, which is OK as does not affect correctness. As
// long as it is used once during no_sync session, it is marked as used.
local_used_maps_[index.replica_index][index.variable_index] = 1;
}
// Ignore if we don't expect to be called.
// This may be the case if the user wants to accumulate gradients
// for number of iterations before reducing them.
if (!expect_autograd_hooks_) {
return;
}
// Rebuild bucket only if 1) it is the first time to rebuild bucket 2)
// find_unused_parameters_ is false, currently it does not support when there
// are unused parameters 3) this backward pass needs to run allreduce. Here,
// we just dump tensors and their parameter indices into rebuilt_params_ and
// rebuilt_param_indices_ based on gradient arriving order, and then at the
// end of finalize_backward(), buckets will be rebuilt based on
// rebuilt_params_ and rebuilt_param_indices_, and then will be broadcasted
// and initialized. Also we only need to dump tensors and parameter indices of
// one replica.
push_rebuilt_params(index);
// If `find_unused_parameters_` is true there may be model parameters that
// went unused when computing the model output, they won't be part of the
// autograd graph, and won't receive gradients. These parameters are
// discovered in the `prepare_for_backward` function and their indexes stored
// in the `unused_parameters_` vector.
if (!has_marked_unused_parameters_ && find_unused_parameters_) {
has_marked_unused_parameters_ = true;
for (const auto& unused_index : unused_parameters_) {
mark_variable_ready(unused_index);
}
}
// Finally mark variable for which this function was originally called.
mark_variable_ready(index);
}
- 前向传播
def forward(self, inputs, *kwargs): if self.ddp_join_enabled: ones = torch.ones( 1, device=self.device ) work = dist.all_reduce(ones, group=self.process_group, async_op=True) self.reducer._set_forward_pass_work_handle( work, self.ddp_join_divide_by_initial_world_size )
# Calling _rebuild_buckets before forward compuation,
# It may allocate new buckets before deallocating old buckets
# inside _rebuild_buckets. To save peak memory usage,
# call _rebuild_buckets before the peak memory usage increases
# during forward computation.
# This should be called only once during whole training period.
if self.reducer._rebuild_buckets():
logging.info("Reducer buckets have been rebuilt in this iteration.")
if self.require_forward_param_sync:
self._sync_params()
if self.ddp_join_enabled:
# Notify joined ranks whether they should sync in backwards pass or not.
self._check_global_requires_backward_grad_sync(is_joined_rank=False)
# !!!
if self.device_ids:
inputs, kwargs = self.scatter(inputs, kwargs, self.device_ids)
if len(self.device_ids) == 1:
output = self.module(*inputs[0], **kwargs[0])
else:
# 单进程多线程多卡的情况
outputs = self.parallel_apply(self._module_copies[:len(inputs)], inputs, kwargs)
output = self.gather(outputs, self.output_device)
else:
output = self.module(*inputs, **kwargs)
if torch.is_grad_enabled() and self.require_backward_grad_sync:
self.require_forward_param_sync = True
# We'll return the output object verbatim since it is a freeform
# object. We need to find any tensors in this object, though,
# because we need to figure out which parameters were used during
# this forward pass, to ensure we short circuit reduction for any
# unused parameters. Only if `find_unused_parameters` is set.
if self.find_unused_parameters:
# 当DDP参数 find_unused_parameter 为 true 时,其会在 forward 结束时,启动一个回溯,标记出所有没被用到的 parameter,提前把这些设定为 ready,这样 backward 就可以在一个 subgraph 进行,但这样会牺牲一部分时间。
self.reducer.prepare_for_backward(list(_find_tensors(output)))
else:
self.reducer.prepare_for_backward([])
else:
self.require_forward_param_sync = False
return output- 反向传播
那么,DDP 究竟是怎么启动 allreduce 的呢?我们看一下 reducer.cpp 里对桶的定义以及用法,主要是在mark_*_ready。
struct Bucket { std::vector replicas;
// Global indices of participating variables in the bucket
std::vector variable_indices;
// Number of replicas to be marked done before this bucket is ready.
// 计数
size_t pending;
// Keep work handle around when this set of buckets is being reduced.
std::shared_ptr work;
// Keep future work handle around if DDP comm hook is registered.
c10::intrusive_ptr future_work;
// If this bucket should expect a single sparse gradient.
// Implies: replicas[i].variables.size() == 1.
bool expect_sparse_gradient = false;
};
先看 mark_variable_ready,截取片段(指去除报错信息)
void Reducer::mark_variable_ready(VariableIndex index) { const auto replica_index = index.replica_index; const auto variable_index = index.variable_index; TORCH_CHECK(replica_index < replicas_.size(), "Out of range replica index."); TORCH_CHECK( variable_index < variable_locators_.size(), "Out of range variable index."); backward_stats_[replica_index][variable_index] = current_time_in_nanos() - backward_stats_base_;
// 每当变量被标记成 ready 了,都要调用一下 finalize
require_finalize_ = true;
const auto& bucket_index = variable_locators_[variable_index];
auto& bucket = buckets_[bucket_index.bucket_index];
auto& replica = bucket.replicas[replica_index];
// If it was scheduled, wait on allreduce in forward pass that tells us
// division factor based on no. of currently participating processes.
if (divFactor_ == kUnsetDivFactor) {
divFactor_ = process_group_->getSize();
auto& workHandle = forwardPassWorkHandle_.workHandle;
if (workHandle && !forwardPassWorkHandle_.useStaticWorldSize) {
workHandle->wait();
auto results = workHandle->result();
// Guard against the results being empty
TORCH_INTERNAL_ASSERT(results.size() > 0);
at::Tensor& res = results.front();
divFactor_ = res.item().to();
}
}
if (bucket.expect_sparse_gradient) {
mark_variable_ready_sparse(index);
} else {
mark_variable_ready_dense(index);
}
// 检查桶里的变量是不是都ready了,如果没有东西 pending,那就是都 ready了
if (--replica.pending == 0) {
if (--bucket.pending == 0) {
mark_bucket_ready(bucket_index.bucket_index);
}
}
// Run finalizer function and kick off reduction for local_used_maps once the
// final bucket was marked ready.
if (next_bucket_ == buckets_.size()) {
if (find_unused_parameters_) {
// H2D from local_used_maps_ to local_used_maps_dev_
for (size_t i = 0; i < local_used_maps_.size(); i++) {
// We do async H2D to avoid the blocking overhead. The async copy and
// allreduce respect the current stream, so will be sequenced correctly.
local_used_maps_dev_[i].copy_(local_used_maps_[i], true);
}
local_used_work_ = process_group_->allreduce(local_used_maps_dev_);
}
// The autograd engine uses the default stream when running callbacks, so we
// pass in the current CUDA stream in case it is not the default.
c10::DeviceType deviceType = replica.contents.device().type();
const c10::impl::VirtualGuardImpl guard =
c10::impl::VirtualGuardImpl{deviceType};
const c10::Stream currentStream =
guard.getStream(replica.contents.device());
torch::autograd::Engine::get_default_engine().queue_callback([=] {
std::lock_guard lock(this->mutex_);
// Run callback with the current stream
c10::OptionalStreamGuard currentStreamGuard{currentStream};
this->finalize_backward();
});
}
}
void Reducer::mark_bucket_ready(size_t bucket_index) { TORCH_INTERNAL_ASSERT(bucket_index >= next_bucket_);
// Buckets are reduced in sequence. Ignore this bucket if
// it's not its turn to be reduced.
if (bucket_index > next_bucket_) {
return;
}
// Keep going, until we either:
// - 所有桶都在 allreduce 那就等着 or
// - 还有桶没好,那也等着.
for (; next_bucket_ < buckets_.size() && buckets_[next_bucket_].pending == 0;
next_bucket_++) {
auto& bucket = buckets_[next_bucket_];
std::vector tensors;
tensors.reserve(bucket.replicas.size());
for (const auto& replica : bucket.replicas) {
// CUDA default stream 都按时序排好了
tensors.push_back(replica.contents);
}
if (comm_hook_ == nullptr) {
// 如果没注册 comm_hook,直接 allreduce
bucket.work = process_group_->allreduce(tensors);
} else {
// 注册了 comm_hook 那就先跑 hook
// 需要注意的是,这个comm_hook 只是处理通信的底层hook,如果想在 reduce 前分别进行梯度裁剪,还是需要在 autograph 挂 hook
bucket.future_work = comm_hook_->runHook(GradBucket(tensors));
}
}
}
除了正常的前向传播,DDP 还允许在 subgraph 进行反向传播,只需将 self.find_unused_parameters 设置为 True。或许有朋友会问,如果 find_unused_parameters 设置为 True,那每次都要 traverse 计算图,明明开销很大,为什么有时候我们还要将 self.find_unused_parameters 设置为 True? 这是因为训练时有可能某次迭代只用到整个模型的一个 subgraph, 并且这个 subgraph 迭代时可能会改变,就是说某些参数可能会在训练时被跳过。但因为所有parameters 在一开始就被分好桶了,而我们的 hook 又规定了只有整个桶 ready 了(pending==0)才会通信,如果我们不将 unused parameter 标记为 ready,整个过程会没法进行。我们在这节结束的部分附上一个小实验验证一下。
DDP 通过在构建时注册 autograd hook 进行梯度同步。当一个梯度计算好后,相应的 hook 会告诉 DDP 可以用来归约。当一个桶里的梯度都可以了,Reducer 就会启动异步 allreduce 去计算所有进程的平均值。当所有桶都可以了,Reducer 会等所有 allreduce 完成,然后将得到的梯度写到 param.grad。
- optimizer step 独立于 DDP,所有进程的模型能够同步是因为初始状态相同并且改变量也相同。
- no_sync
@contextmanager
def no_sync(self):
old_require_backward_grad_sync = self.require_backward_grad_sync
self.require_backward_grad_sync = False
try:
yield
finally:
self.require_backward_grad_sync = old_require_backward_grad_sync
>>> ddp = torch.nn.DistributedDataParallel(model, pg)
>>> with ddp.no_sync():
>>> for input in inputs:
>>> ddp(input).backward() # 不同步梯度
>>> ddp(another_input).backward() # 同步梯度迭代多次再同步梯度。
- 实验:find_unused_params
import os
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
from timeit import default_timer as timer
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12138'
# sync
seed = 0
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
def example(rank, world_size):
# create default process group
dist.init_process_group("gloo",rank=rank,
world_size=world_size,init_method='env://')
# create local model
model = nn.Linear(10, 10).to(rank)
# construct DDP model
ddp_model = DDP(model, device_ids=[rank])
# define loss function and optimizer
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
buf = 0
tmp = 0
for i in range(10000):
start = timer()
# forward pass
outputs = ddp_model(torch.randn(20, 10).to(rank))
end = timer()
tmp = end-start
buf+=tmp
labels = torch.randn(20, 10).to(rank)
# backward pass
loss_fn(outputs, labels).backward()
# update parameters
optimizer.step()
print(tmp)
print(buf)
print(buf/10000)
def main():
world_size = 1
mp.spawn(example,
args=(world_size,),
nprocs=world_size,
join=True)
if __name__=="__main__":
for i in range(10):
main()将 find_unused_params 分别设置成 True 或者 False 跑多次取平均,可以得到:
- find_unused_params=True: 0.3367 ms
- find_unused_params=False: 0.2993 ms
小结
关于 DP 和 DDP 的分享到这里就结束啦~
参考资料
[1] https://leimao.github.io/blog/Data-Parallelism-vs-Model-Paralelism/
[2] https://d2l.ai/chapter_computational-performance/parameterserver.html
[3] https://kknews.cc/code/y5aejon.html
[4] https://medium.com/huggingface/training-larger-batches-practical-tips-on-1-gpu-multi-gpu-distributed-setups-ec88c3e51255
[5] https://opensource.com/article/17/4/grok-gil
[6] 谈谈python的GIL、多线程、多进程 - 知乎
[7] https://andrew.gibiansky.com/blog/machine-learning/baidu-allreduce/
[8] 【分布式训练】单机多卡的正确打开方式(一):理论基础 - 知乎
[9] [原创][深度][PyTorch] DDP系列第二篇:实现原理与源代码解析 - 知乎
[10] https://pytorch.org/docs/stable/notes/ddp.html
[11] http://www.vldb.org/pvldb/vol13/p3