KDD CUP 2022 风能预测赛题冠军方案分享
KDD CUP竞赛是由ACM 的数据挖掘及知识发现专委会(SIGKDD)主办的数据挖掘研究领域的国际赛事,从1997年开始,每年举办一次,被称为数据挖掘领域的“世界杯”,是该领域水平最高、最有影响力的顶级赛事。今年KDD CUP 共有2个赛题,分别是有百度承办的风电功率预测赛道和亚马逊承办的商品搜索赛道。我们时空大数据小组有幸邀请到了KDD CUP 2022 风电功率预测赛道的冠军团队来分享一下他们的竞赛方案。
Spatial Dynamic Wind Power Forecasting
1. 赛题介绍
1.1. 背景
风电预测(WPF)旨在准确估计风电场在不同时间尺度上的风能供应。风电是一种清洁安全的可再生能源,但不能持续生产,导致高波动性。这种可变性可能对将风力发电并入电网系统提出重大挑战。为了保持发电和消费之间的平衡,风力发电的波动需要从其他可能无法在短时间内获得的电力替代(例如,通常至少需要 6 个小时才能点燃一个燃煤电厂)。因此,WPF被广泛认为是风电并网运行中最关键的问题之一。
本次竞赛提供了龙源电力集团有限公司独特的空间动态风力预测数据集:SDWPF;其中包括风力涡轮机的空间分布,以及时间、天气和涡轮机内部状态等动态背景因素。然而,大多数现有的数据集和竞赛将 WPF 视为时间序列预测问题,没有注意到风力涡轮机的位置和上下文信息。
本次竞赛的特点就是提供了空间分布和动态上下文信息。
空间分布:本次竞赛将提供给定风电场的所有风力涡轮机的相对位置,用于建模风力涡轮机之间的空间相关性。
动态上下文:提供由每个风力涡轮机监控的重要天气情况和涡轮机内部上下文,以促进预测任务。
1.2. 数据概况
竞赛提供的SDWPF 数据集是从风电场的监控和数据采集 (SCADA) 系统收集的。 SCADA 数据每 10 分钟从风电场中的每个风力发电机采样一次,该风电场由 134 台风力发电机组成,共245天数据。数据集包括影响风力发电的关键外部特征,例如风速、风向和外部温度;以及重要的内部特征,例如内部温度、机舱方向和叶片角度,可以指示每个风力涡轮机的运行状态。

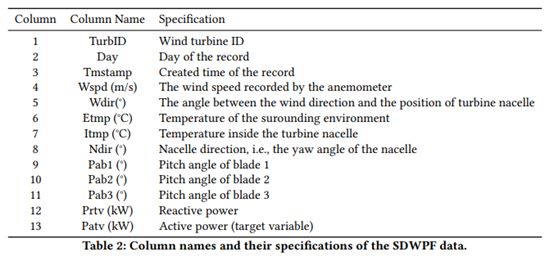
每台风力发电机可以单独产生风能,风电场的输出功率是所有风力发电机的总和。数据集中发布了风电场中所有风机的相对位置,以表征风机之间的空间相关性。

1.3. 赛题任务
要求提前48小时进行空间动态风电预测。例如,在上午 6:00 给出。今天,需要有效地预测从早上 6:00 开始的风力发电量。从今天到后天早上 5 点 50 分,给出了风电场和相关风力发电机的一系列历史记录。要求每 10 分钟输出一次预测值。具体来说,在某一时间点,每个风机需要预测一个未来长度为 288 的风电功率时间序列。
评价方式: RMSE(均方根误差)和 MAE(平均绝对误差)的平均值作为评估分数。
线上评测会从特定时间范围内随机抽取n个时间点,该时间点前14天的数据可以获得,来预测该时间点每个风机后两天(288步)的功率。提交源代码至竞赛官网,进行线上分数评测。
当数据存在以下情况时,该时刻的功率值会被过滤,不参与评估:
- 零值:if Patv < 0, then Patv = 0
- 缺失值:Nan
- 未知值:(Patv <=0 and Wspd > 2.5) or (Pab1 > 89°or Pab2 > 89°or Pab3 > 89°)
- 异常值: (Ndir > 720° or Ndir < -720°) or (Wdir > 180° or Wdir < -180°)
官方提供的评测运行代码demo链接,https://github.com/PaddlePaddle/PaddleSpatial/tree/main/apps/wpf_baseline_gru/kddcup22-sdwpf-evaluation。
2. 数据探索
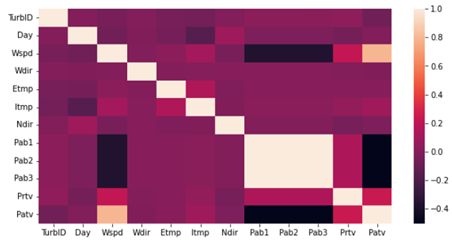
2.1. 探索不同特征之间的相关性
可以下图可以看出风速与功率成正相关,风速越大功率越大;叶片角度与功率成负相关,叶片角度小时迎风面积大功率越大。
查阅文献可以得知,理论上风速的三次方与功率成正比。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Csnn7B4I-1666256689573)(https://files.mdnice.com/user/35597/ba731869-6b79-410e-8858-87bce6f26f0e.png)]

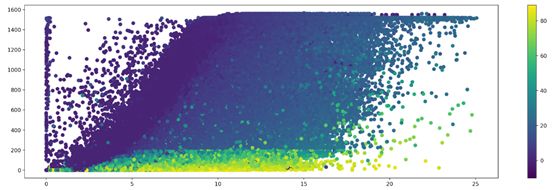
但是从竞赛的给出的实际数据来看,由于风机人为控制、测量误差等因素,在某些情况下功率产生比理论值有较大差距。相同风速下叶片角度越大功率越低,控制叶片角度等同于控制风机的受风面积。1号风机具有特殊性,从叶片角度数据上自始至终没有控制,角度都很小,但是存在部分高风速低功率的数据。但在评测样例数据中1号风机存在叶片角度控制。

同一风机每天功率变化的相关性很低,风速和功率的变化没有发现较强的周期性。

不同风机的功率变化高度相关,同一时段风机功率的变化几乎相同,但是考虑到风电场的尾流效应,依然可以对风机进行聚类。
2.2. 风场聚类
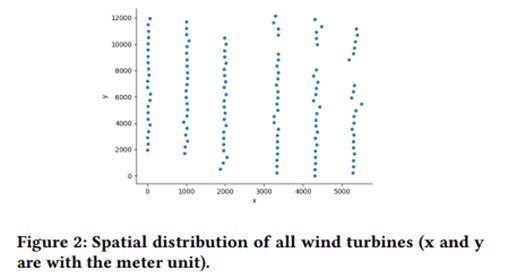
- 可视化风场的风机位置,如下图所示,右上角15个风电机与其他风机的间隙可能是一条道路。
- 通过风速相关性将风电机聚成2类和3类,地址位置和风速有一定关系。
- 猜测不同位置的地形和地面粗糙度有一定影响,建模时可以考虑相似地形位置的因素。
通过龙源电力、134台风机、风场形状可以检索到风场地点在瓜州县柳沟站(火车站)附近,刚好右上角的那条空隙就是一条铁路,虽然可以推测到风场地点,但是竞赛主办方把线上测评数据的Day字段也给脱敏了,即线上测试的Day跟离线数据没有关系,全都是重新从第一天开始计数的,所以无法将风场当地的历史风速变化规律用起来。


2.3. 异常值与缺失值
统计全量离线数据中的异常值和缺失值,其中不参与测评的四种异常值情况在全量数据中占比29.7%左右。对于缺失值和异常值尝试过均值填补、中位数填补、KNN填补和0值填补,从预测效果上影响都不大,最终采用简单的0值填补,即将风速、有功功率和无功功率小于0的赋值为0,风向、外部温度、机舱内部温度、机舱角度等特征把超出合理范围的值赋值为0。
3. 模型方案
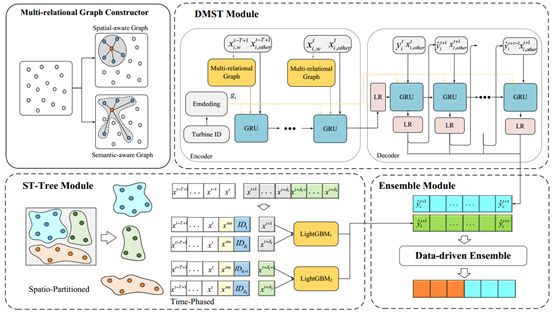
整体方案由四个模块组成,第一部分:多关系图用于时空信息的聚合;第二部分:DMST模块以编码器-解码器形式来聚集空间信息、捕获时间模式;第三部分:ST-Tree模块在空间维度上进行划分,并对每个时间段进行预测,以提高准确性和鲁棒性;第四部分:集成模块以数据驱动的形式,动态融合两个模型的结果。
3.1. 多关系图模块
我们统计了风机间距离与功率相似度的分布,该图显示了空间距离和功率相似性之间的关系,我们发现风力涡轮机之间的空间距离越小,功率相关性越大。然而,当空间距离较大时,一些风力涡轮机的功率相似性也非常强。


所以我们尝试从多个空间距离内构造感知图,而不仅仅单从欧几里德距离来构建感知图。我们从欧几里德距离和风速语义距离两个空间构建感知图。一是计算两个节点之间的欧几里得距离以获得空间距离矩阵,然后将顶部K个最近节点作为每个节点的邻居。二是使用风速变化来计算节点之间的相似度,并构造语义感知图,获得每个节点的语义邻居的top-K最相似节点。
3.2.DMST模块
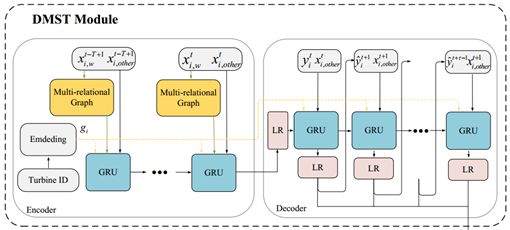
我们聚合来自空间感知图和语义感知图的1阶邻居的风速信息,将其作为风速空间特征。通过向模型添加嵌入层,用向量表示每个涡轮机ID,作为风机embedding。使用GRU建立Seq2Seq模型,在编码器输入中,我们将风速空间特征与风力涡轮机嵌入和其他风力涡轮机特征(例如,温度、天气、涡轮机内部状态等)作为GRU输入。在解码器输入中,我们使用编码器的hti作为解码器中GRU的初始隐藏状态,然后使用风力涡轮机嵌入和其他已知未来特征(例如,时间和风力涡轮机位置)作为时间戳t加1的模型输入,在前一时间戳t处计算预测功率。
3.3.ST-Tree模块

我们使用LightGBM构建了一个空间分区的时间分阶段树模型。在空间维度上,考虑到风电场的尾流效应和风力涡轮机的位置分布,类似风力条件下的风力涡轮机可能具有类似的状态。这里,我们使用pearson相关系数来计算风机之间的相似性,我们利用K均值基于风速相似性对风电场进行空间聚类,并为每个聚类分区建立单独的树模型。在时间维度上,因为树模型仅支持单输出预测。为每个时间戳构建树模型将导致模型过多,并有模型过度拟合的风险。因此,通过分割时间步长来构建树模型。我们在每个子预测区间建立模型,并在样本特征中添加一列唯一ID特征,以区分不同的时间戳。
3.4.动态集成模块
由于风力涡轮机数据分布不稳定,通过模型学习融合策略可能导致模型过拟合,而简单加权平均融合策略不能应用于分布不一致的风力涡轮机数据。因此,我们采用动态融合方法,根据风电场的当前功率状态选择不同的融合方法,可以有效解决风电场分布不稳定的问题。
动态融合方法的提出主要基于以下几点分析:
- 不同的模型对不同的时间段具有不同的预测能力。ST-Tree模型的短期预测能力优于DMST模型,而DMST模型的中长期预测能力优于ST-Tree模型。
- 当风场风力发电功率过大或过小时,DMST的短期预测曲线陡峭,误差相对较大。
- DMST对风场的中长期预测的功率趋势有较强的预测能力,但由于线上评测数据分布差异较大。当线上风速整体偏高时,DMST的预测是保守的,虽然整体预测趋势准确,但是可能会整体偏低。
具体逻辑如下图伪代码所示

4. 实验结果
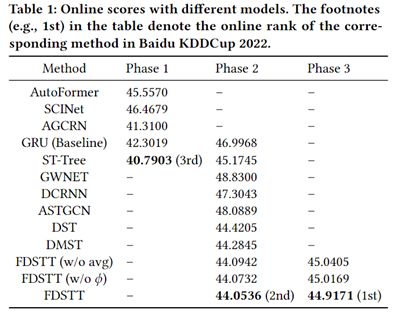
竞赛阶段我们尝试了许多模型,例如GRU, AutoFormer, SCINet等时序模型,AGCRN, GWNET, DCRNN, ASTGCN, DST等时空模型。上表描述了在我们队在竞赛的三个阶段线上得分,得分为误差,越小越好。从该表中,我们可以观察到,许多经典预测模型在这个赛题上效果并不好,我们最终提出的集成预测模型在所有三个阶段都优于经典模型,这验证了我们方案的优越性。
此外,我们方案在比赛的最后阶段赢得了第一名,在第二阶段赢得了第二名,第一阶段获得了第三名,唯一一个队伍在三个阶段排名都在TOP3的队伍。这些结果表明,我们方案可以在不同的测试数据集上实现一致的优越性能。
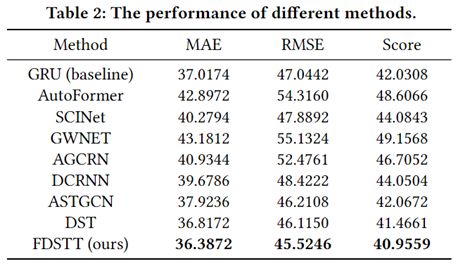
我们也在线下构建了测试数据集,将我们尝试过的多个方案进行比较。比较结果见表2。我们的最优方案跟线上评测的最优方案保持一致。
5. 总结
整个比赛过程中,我们尝试了多种方案,包括传统机器学习模型、CNN base、RNN base、transformer等等,最终我们基于不同的模型效果,提出了一种新的风能功率长序列预测集成模型FDSTT,该集成模型由多关系图构造模块、基于深度多关系图的时空模块、空间分区时间分段树模块和数据驱动集成模块组成。
在多关系图构造模块中,我们基于距离邻居和语义邻居构造多关系图。在深度多关系时空网络(DMST)中,我们使用风速数据通过多关系图进行空间特征提取,并采用基于GRU的Seq2Seq模型来捕捉时间特征。在空间分块时相树模型(ST-Tree)中,基于风速数据的相关性对风电场进行空间聚类,并通过时间相位而不是每个时间戳建立模型。它不仅有效地减少了模型的数量,而且增强了模型的鲁棒性。基于该模型集成策略,我们根据WPF中不同模型的特点,提出了一种数据驱动的集成策略,用于不稳定的数据分布。最后,我们提出的模型FDSTT赢得了2022年KDD CUP决赛阶段的第一名,并且也是唯一一支三个阶段都在前三名的队伍。
更多内容,敬请关注同名微信公众号:时空大数据兴趣小组。
