李宏毅机器学习笔记 Regression含作业
欢迎学习李宏毅老师课程的小伙伴一起进群讨论:980704621
本节课主要内容有
Regression
- regression应用
- regression训练方式
- Regression结果
- 结论
- Regression作业
-
- 作业说明
- 官方答案
- **Load 'train.csv'**
- **Preprocessing**
- **Extract Features (1)**
- **Extract Features (2)**
- **Normalize (1)**
- **Training**
- **Testing**
- **Prediction**
- **Save Prediction to CSV File**
这节课的视频主要在这https://www.bilibili.com/video/av94411666?p=3,这节课分了两部分,以休息前和休息后为界,分两部分做笔记。
regression应用
1.股票预测
2.自动驾驶
3.推荐系统

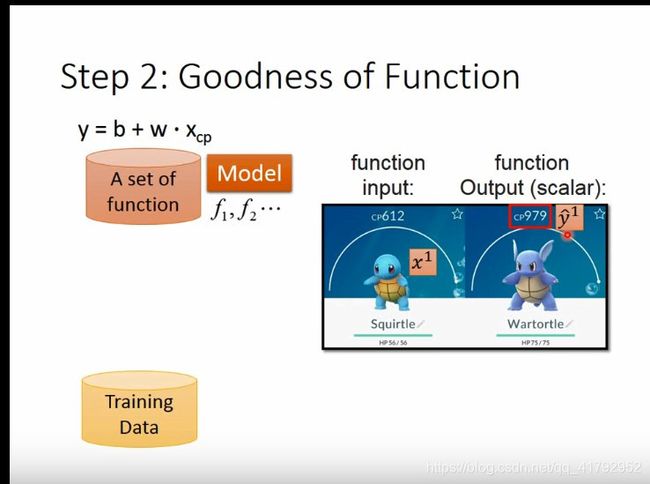
这节课主要讲CP值,就是神奇宝贝进化后的CP值。【捂脸,果然还是熟悉的李老师】
这里的输入就是所有宝可梦相关的属性值
一只宝可梦用x表示,它的进化前CP值用 x c p x_{cp} xcp值来进行表示, x s x_{s} xs表示这只宝可梦属于哪只物种, x h p x_{hp} xhp表示这只宝可梦的hp值, x w x_{w} xw表示这只宝可梦的重量, x h x_{h} xh表示这只宝可梦的高度。输出就是进化后的CP,用y表示。

怎么去训练呢?
regression训练方式
step 1: Model
找一个Model。这里选用的是线性关系,找一个最好的线性关系去拟合。使用training data去找最好的线性关系。

step 2: Goodness of Function
使用训练集来找到最好的拟合函数。得手机训练集,就得抓很多宝贝来试试,嘿嘿嘿。
这里加帽子上标的变量表示为正确的值。
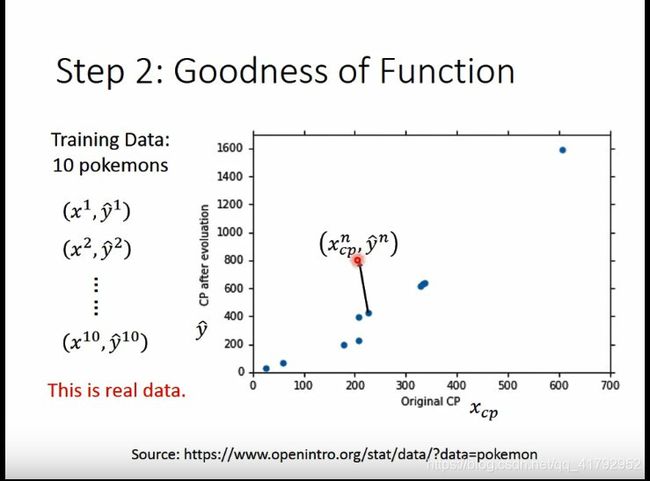
这里有了十只的数据,图中展示的就是十只宝可梦进化后的CP值,横坐标为原来的CP值
有了训练数据,就可以定义函数的好坏:Loss function L。损失函数。
损失函数,输入就是函数,输出就是这个函数多不好,也就是衡量W,b的好坏。可以自己定义loss function。
这里使用的是误差(真正的数值减去估测的数值)平方和

Loss function 的形状如图。图上每个点都代表一个function。相当于一个W和一个b,对应的误差有多少,越蓝说明误差越小。

step 3 Best Function
从步骤二里,挑选出最好的function。也就是使损失函数最小的那个W,b就是最好的函数。
其实也就是解下图公式L的最小值。如果学过线性回归的话,我们可以很简单地用最小二乘进行求解出来。但是这里为了和后面的训练接轨,这里选用的是梯度下降的方法(Gradient Descent)。梯度下降的方法好处在于,不怕L再复杂都可以践行训练。

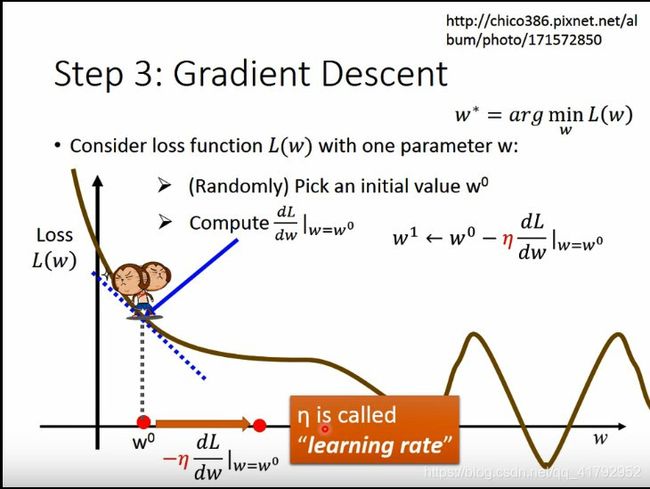
好了怎么去找一个最好的w呢, 一个很直观的方法就是穷举法,但这样非常没有效率。梯度下降的方法会更好。梯度下降是通过先随机选取个初值,然后在w0位置对w求导。然后取其负导数,然后用这个负导数 w 1 ← w 0 − η d L d w ∣ w = w 0 w^{1} \leftarrow w^{0}-\left.\eta \frac{d L}{d w}\right|_{w=w^{0}} w1←w0−ηdwdL∣∣w=w0来更新参数值。当然,增加这个多少的话,就用一个学习率 η \eta η来描述,这个值越大学习得越快,但越大也存在不收敛的风险。
就这样,一步步迭代,最后得出最后满足条件的w值。当然,在这个过程,你可能找到的只是一个local optimal就是局部最小值,而不是全局最小值。但是在线性回归中,不会存在局部最小值。

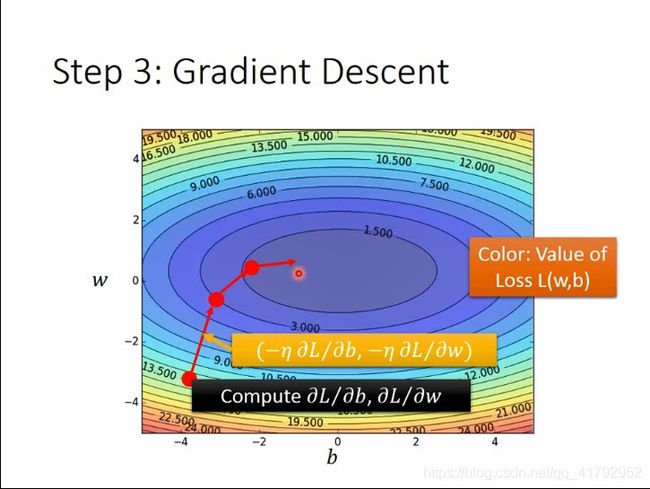
之前讲的是单参数的更新。那么多参数该怎么办呢?其实是一样的,也是一步步地求偏微分。先求w,再求b,再求w,再求b,反复进行这个步骤。最后就可以找到loss比较小的位置。这个要补充的就是,gradient其实就是对个变量的偏微分,也就是雅各比矩阵。

下面这个图的颜色代表loss的大小。可以看红点的位置是怎么更新的。可以发现,红点一直是在往loss比较小的地方前进。
但是gradient descent也有麻烦的地方,就是有很多局部最小的函数上,很容易就收敛在局部最小值了,需要很小心选择起始点。还好线性回归没有局部最小值的。可以随机选起始点。

好了,接下来讲下公式推导的过程:
对w和b求导,可以发现,这个偏微分是非常容易求得,大家可以自己动手算算哦。

Regression结果
上一部分主要讲了Regression的步骤。这一部分主要讲结果。
根据上一部分我们得出的结果是怎么样的呢?从下图可以看到,我们得出的直线和点之间关系还是很强的。每个点到直线的平均误差也不是很大。

但是在训练集的效果并不是我们关心的。我们关心的是我们算出的这个模型,在新的数据中表现出的效果。因此,这里我们新抓了十只宝可梦。看一下我们的模型在新的宝可梦上的效果。可以看出在新的数据中表现也是不错的。
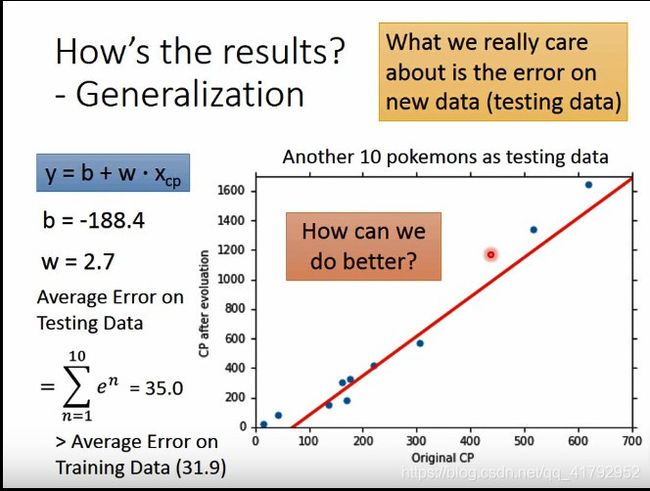
那么我们可以让模型做到更好吗?这里我们可以试一下更复杂的模型。这里我们加了一个二次式。见图中最上面的公式。最后我们算出来的参数,画在图上与我们原来的数据对比一下。可以发现我们新的模型更加准确一些。当然我们真正关心的的是在测试集上。同时,也发现在我们的测试集中,效果也会好一些。平均误差变小了。

那我们还可以做到更好呢?我们再加一个三次项试试(见图中第一个公式)。我们再训练得到参数。结果看起来和之前二次的结果差不多,但稍微好一点点。
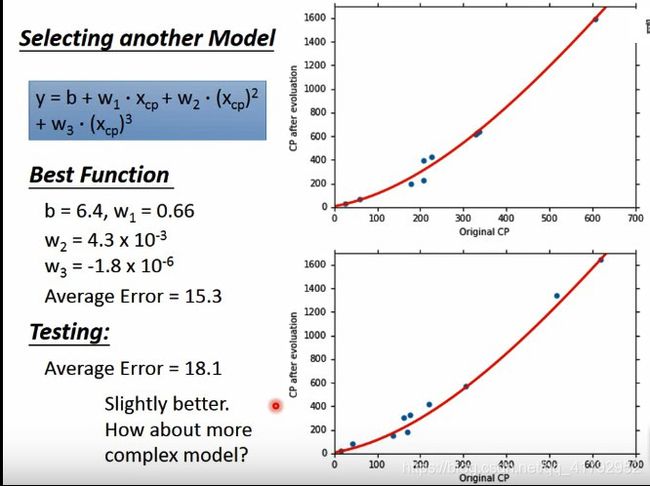
那有没有更复杂的模型可以让效果变得更好呢?我们再加个四次方试试。发现加了四次方之后,在训练集中确实表现得更好。但是我们真正关心的还是在测试集。发现,我们在测试集的结果却变差了。更复杂的模型在测试集中效果变差了,不如三次里的效果。
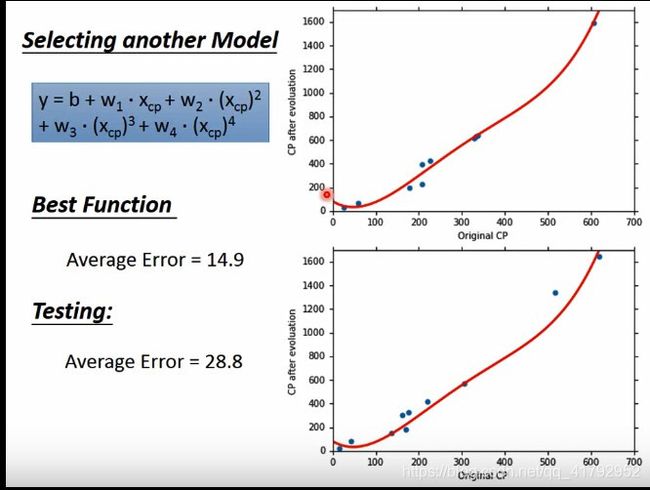
我们再试试更复杂的模型,再加个五次方试试。在训练集发现,虽然拟合得很好。但是却出现了负的CP值,明显不合理!!!虽然误差小了,结果却不合理。我们再看看测试集中,发现结果变得很不准。结果变得又变差了。
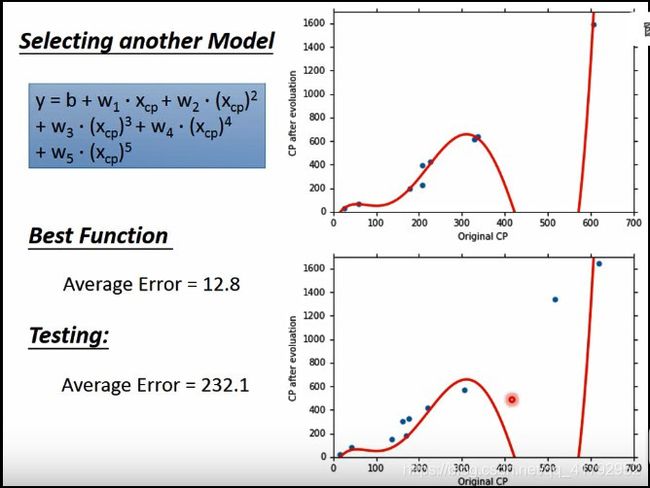
所以目前为止,我们试了五个不同的model。可以发现,在训练集中,随着模型的负责,误差在减小。为什么会这样呢?因为我们模型越复杂,就可以把简单的模型考虑的东西包含在里面。可以看图中的同心圆,越复杂的模型包含的越多。
当然这里有个前提,就是你的梯度下降可以帮你找出最好的拟合函数,没有困在局部最优解。
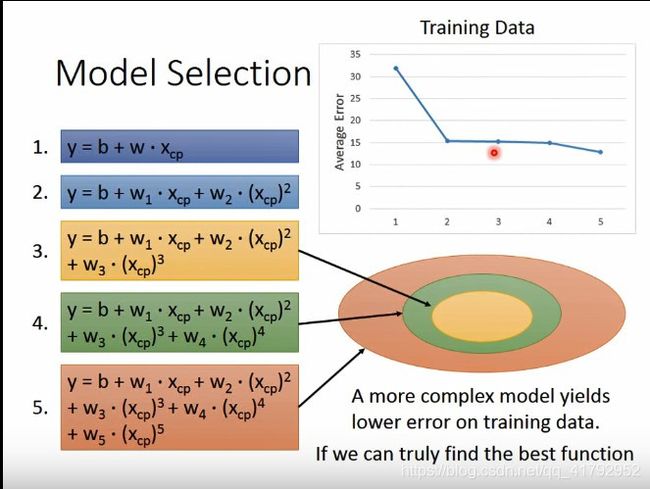
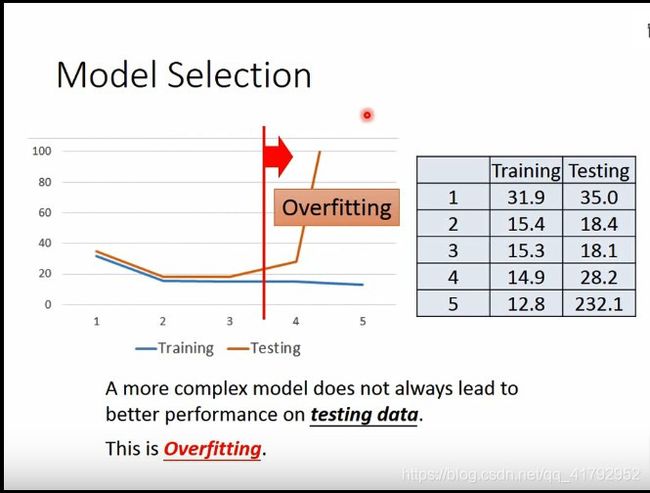
但是在测试集中,结果却是不一样的。可以发现前面误差在减小,而后面模型越复杂,测试集误差越大。越复杂的模型不一定在测试集中有更好的结果。这种现象就是过拟合。
好了,这个实验还没结束。之前我们的训练数据太少了。现在我们试试用60个宝可梦的数据来试试。可以发现60个数据并不能用简单的关系来描述。数据比较散乱,可能是由于物种关系造成的,我们先对数据进行分类。所以之前只考虑CP值是不对的,我们这里再把物种考虑进去。

对之前的输入和输出进行修正。此时,我们在输入中再把物种也当成变量加入,不同的物种,带入不同的公式。但是有人可能会有疑问,这里把if带入后还是线性方程组吗。当然是,只要我们把形式改一下。

我们可以用一个δ函数来表示if。发现我们图中的蓝色方框的内容还就是我们之前的x。

好了,我们来看看结果。
可以发现,我们用不同种类来进行训练后,发现我们的误差就小很多。
在测试集中,我们的结果也fit得很好。
但是还有有一些高值和低值的部分拟合的不一样。

是不是,进化后的CP值和其他一些属性有关系的呢?例如,重量、高度、HP值这些有关系呢?
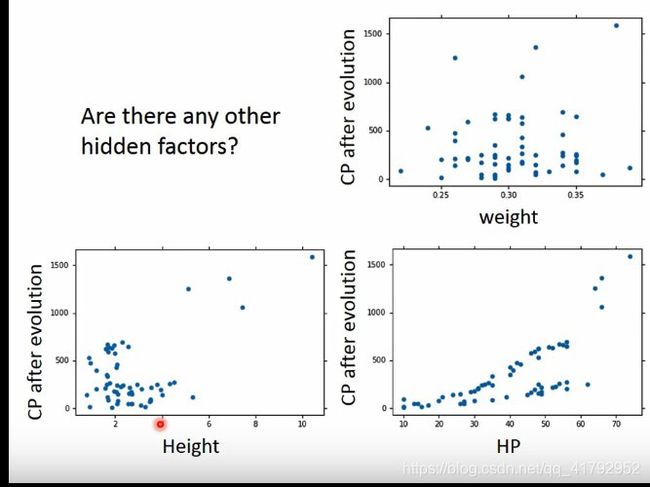
那我们不知道有哪些因素影响,那该怎么训练呢?就不用多想了,把我们能考虑到的因素都加进去。那我们的输入就是所有考虑进去的因素。
那这么复杂的模型我们的结果会不会更好呢?确实,在训练集中,我们的误差变得非常小。但是,在训练集中,又过拟合了!!!

那怎么去解决过拟合的问题呢?这里我们提出正则化来解决。
正则化是什么意思呢?就是原来我们误差中,只考虑了拟合差,这里我们在加一个考虑值,就是让参数接近0。这样我们预期就是我们的参数非常小。参数小可以让我们的函数更加平滑。因为参数越接近0,变化量也就越小,函数也就越加光滑。因为光滑对噪声没那么敏感,噪声干扰更小。

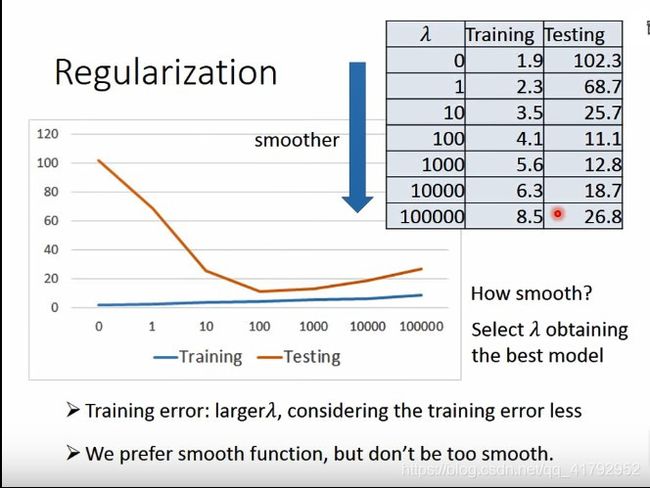
好了,看一下这样加了正则化项的结果。
可以发现加了正则项后,我们模型越复杂,我们训练集的误差反而变大了。但是在测试集中却大概率是变小的。
但是我们也不会想要太平滑的结果。这个时候,我们就需要控制这个λ值。λ越大越考虑光滑。
光滑项是不用考虑bias的。
结论
最后,这节课的结论:
1.进化后宝可梦的CP值和进化前的CP值有很大关系,但是还是与有一些其他因素有关系
2.梯度下降
3.过拟合和正则化
4.如果把我们的模型放在网上让别人使用的话,他们的误差会大于11.1还是小于11.1

Regression作业
这次笔记主要分享Regression课程的课后作业。
作业说明
这次的作业是根据数据,利用线性回归模型来预测PM2.5。

作业资料说明:
这里面有训练资料train.csv以及测试资料test.csv。

其他的作业格式规定就不说了,反正我们也提交不了【狗头】。
我们这里把这道题做一做就好。
官方答案
这里我就复制上官方的答案,并把步骤走一遍。
因为数据集我已经下载好了,就把下载数据集的代码给删了。
Load 'train.csv’
train.csv 的资料为 12 个月中,每个月取 20 天,每天 24 小时的资料(每小时资料有 18 个 features)。
import sys
import pandas as pd
import numpy as np
data = pd.read_csv('./train.csv', encoding = 'big5')
Preprocessing
取需要的数值部分,将 ‘RAINFALL’ 栏位全部补 0。
另外,如果要在 colab 重覆这段程式码的执行,请从头开始执行(把上面的都重新跑一次),以避免跑出不是自己要的结果(若自己写程式不会遇到,但 colab 重複跑这段会一直往下取资料。意即第一次取原本资料的第三栏之后的资料,第二次取第一次取的资料掉三栏之后的资料,…)。
data = data.iloc[:, 3:]
data[data == 'NR'] = 0
raw_data = data.to_numpy()
Extract Features (1)
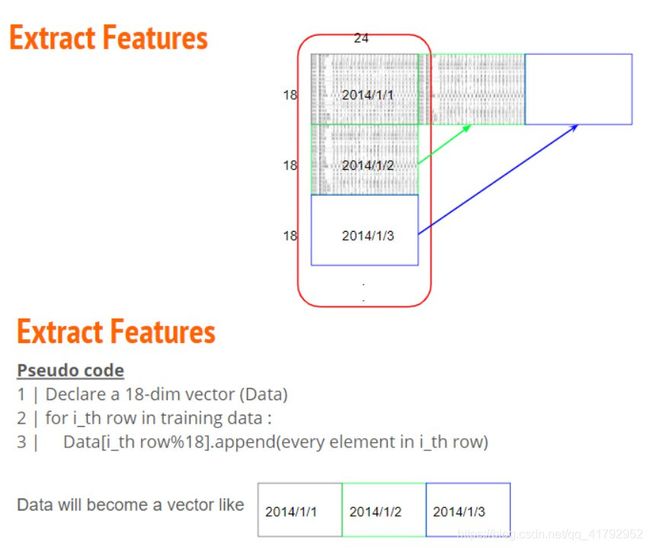
将原始 4320 * 18 的资料依照每个月分重组成 12 个 18 (features) * 480 (hours) 的资料。
month_data = {}
for month in range(12):
sample = np.empty([18, 480])
for day in range(20):
sample[:, day * 24 : (day + 1) * 24] = raw_data[18 * (20 * month + day) : 18 * (20 * month + day + 1), :]
month_data[month] = sample
Extract Features (2)
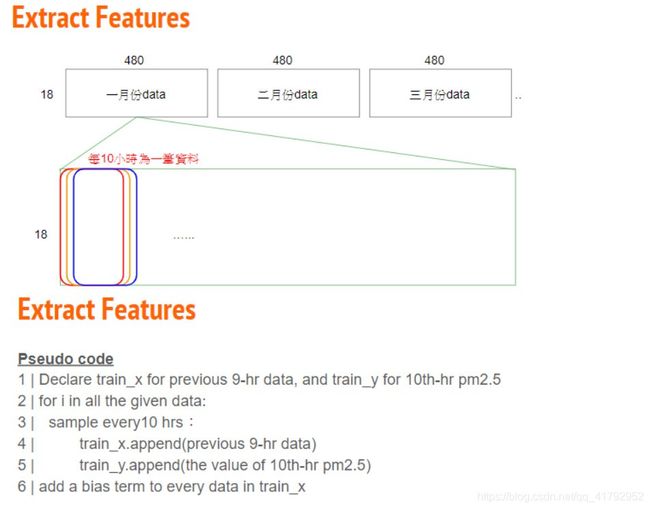
每个月会有 480hrs,每 9 小时形成一个 data,每个月会有 471 个 data,故总资料数为 471 * 12 笔,而每笔 data 有 9 * 18 的 features (一小时 18 个 features * 9 小时)。
对应的 target 则有 471 * 12 个(第 10 个小时的 PM2.5)
x = np.empty([12 * 471, 18 * 9], dtype = float)
y = np.empty([12 * 471, 1], dtype = float)
for month in range(12):
for day in range(20):
for hour in range(24):
if day == 19 and hour > 14:
continue
x[month * 471 + day * 24 + hour, :] = month_data[month][:,day * 24 + hour : day * 24 + hour + 9].reshape(1, -1) #vector dim:18*9 (9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9)
y[month * 471 + day * 24 + hour, 0] = month_data[month][9, day * 24 + hour + 9] #value
print(x)
print(y)
[[14. 14. 14. ... 2. 2. 0.5]
[14. 14. 13. ... 2. 0.5 0.3]
[14. 13. 12. ... 0.5 0.3 0.8]
...
[17. 18. 19. ... 1.1 1.4 1.3]
[18. 19. 18. ... 1.4 1.3 1.6]
[19. 18. 17. ... 1.3 1.6 1.8]]
[[30.]
[41.]
[44.]
...
[17.]
[24.]
[29.]]
Normalize (1)
mean_x = np.mean(x, axis = 0) #18 * 9
std_x = np.std(x, axis = 0) #18 * 9
for i in range(len(x)): #12 * 471
for j in range(len(x[0])): #18 * 9
if std_x[j] != 0:
x[i][j] = (x[i][j] - mean_x[j]) / std_x[j]
x
array([[-1.35825331, -1.35883937, -1.359222 , ..., 0.26650729,
0.2656797 , -1.14082131],
[-1.35825331, -1.35883937, -1.51819928, ..., 0.26650729,
-1.13963133, -1.32832904],
[-1.35825331, -1.51789368, -1.67717656, ..., -1.13923451,
-1.32700613, -0.85955971],
...,
[-0.88092053, -0.72262212, -0.56433559, ..., -0.57693779,
-0.29644471, -0.39079039],
[-0.7218096 , -0.56356781, -0.72331287, ..., -0.29578943,
-0.39013211, -0.1095288 ],
[-0.56269867, -0.72262212, -0.88229015, ..., -0.38950555,
-0.10906991, 0.07797893]])
#Split Training Data Into “train_set” and "validation_set"
这部分是针对作业中 report 的第二题、第三题做的简单示范,以生成比较中用来训练的 train_set 和不会被放入训练、只是用来验证的 validation_set。
import math
x_train_set = x[: math.floor(len(x) * 0.8), :]
y_train_set = y[: math.floor(len(y) * 0.8), :]
x_validation = x[math.floor(len(x) * 0.8): , :]
y_validation = y[math.floor(len(y) * 0.8): , :]
print(x_train_set)
print(y_train_set)
print(x_validation)
print(y_validation)
print(len(x_train_set))
print(len(y_train_set))
print(len(x_validation))
print(len(y_validation))
[[-1.35825331 -1.35883937 -1.359222 ... 0.26650729 0.2656797
-1.14082131]
[-1.35825331 -1.35883937 -1.51819928 ... 0.26650729 -1.13963133
-1.32832904]
[-1.35825331 -1.51789368 -1.67717656 ... -1.13923451 -1.32700613
-0.85955971]
...
[ 0.86929969 0.70886668 0.38952809 ... 1.39110073 0.2656797
-0.39079039]
[ 0.71018876 0.39075806 0.07157353 ... 0.26650729 -0.39013211
-0.39079039]
[ 0.3919669 0.07264944 0.07157353 ... -0.38950555 -0.39013211
-0.85955971]]
[[30.]
[41.]
[44.]
...
[ 7.]
[ 5.]
[14.]]
[[ 0.07374504 0.07264944 0.07157353 ... -0.38950555 -0.85856912
-0.57829812]
[ 0.07374504 0.07264944 0.23055081 ... -0.85808615 -0.57750692
0.54674825]
[ 0.07374504 0.23170375 0.23055081 ... -0.57693779 0.54674191
-0.1095288 ]
...
[-0.88092053 -0.72262212 -0.56433559 ... -0.57693779 -0.29644471
-0.39079039]
[-0.7218096 -0.56356781 -0.72331287 ... -0.29578943 -0.39013211
-0.1095288 ]
[-0.56269867 -0.72262212 -0.88229015 ... -0.38950555 -0.10906991
0.07797893]]
[[13.]
[24.]
[22.]
...
[17.]
[24.]
[29.]]
4521
4521
1131
1131
Training



(和上图不同处: 下面的 code 採用 Root Mean Square Error)
因为常数项的存在,所以 dimension (dim) 需要多加一栏;eps 项是避免 adagrad 的分母为 0 而加的极小数值。
每一个 dimension (dim) 会对应到各自的 gradient, weight (w),透过一次次的 iteration (iter_time) 学习。
dim = 18 * 9 + 1
w = np.zeros([dim, 1])
x = np.concatenate((np.ones([12 * 471, 1]), x), axis = 1).astype(float)
learning_rate = 100
iter_time = 1000
adagrad = np.zeros([dim, 1])
eps = 0.0000000001
for t in range(iter_time):
loss = np.sqrt(np.sum(np.power(np.dot(x, w) - y, 2))/471/12)#rmse
if(t%100==0):
print(str(t) + ":" + str(loss))
gradient = 2 * np.dot(x.transpose(), np.dot(x, w) - y) #dim*1
adagrad += gradient ** 2
w = w - learning_rate * gradient / np.sqrt(adagrad + eps)
np.save('weight.npy', w)
w
0:27.071214829194115
100:33.78905859777454
200:19.91375129819709
300:13.531068193689686
400:10.645466158446165
500:9.27735345547506
600:8.518042045956497
700:8.014061987588416
800:7.636756824775686
900:7.33656374037112
array([[ 2.13740269e+01],
[ 3.58888909e+00],
[ 4.56386323e+00],
[ 2.16307023e+00],
[-6.58545223e+00],
[-3.38885580e+01],
[ 3.22235518e+01],
[ 3.49340354e+00],
[-4.60308671e+00],
[-1.02374754e+00],
[-3.96791501e-01],
[-1.06908800e-01],
[ 2.22488184e-01],
[ 8.99634117e-02],
[ 1.31243105e-01],
[ 2.15894989e-02],
[-1.52867263e-01],
[ 4.54087776e-02],
[ 5.20999235e-01],
[ 1.60824213e-01],
[-3.17709451e-02],
[ 1.28529025e-02],
[-1.76839437e-01],
[ 1.71241371e-01],
[-1.31190032e-01],
[-3.51614451e-02],
[ 1.00826192e-01],
[ 3.45018257e-01],
[ 4.00130315e-02],
[ 2.54331382e-02],
[-5.04425219e-01],
[ 3.71483018e-01],
[ 8.46357671e-01],
[-8.11920428e-01],
[-8.00217575e-02],
[ 1.52737711e-01],
[ 2.64915130e-01],
[-5.19860416e-02],
[-2.51988315e-01],
[ 3.85246517e-01],
[ 1.65431451e-01],
[-7.83633314e-02],
[-2.89457231e-01],
[ 1.77615023e-01],
[ 3.22506948e-01],
[-4.59955256e-01],
[-3.48635358e-02],
[-5.81764363e-01],
[-6.43394528e-02],
[-6.32876949e-01],
[ 6.36624507e-02],
[ 8.31592506e-02],
[-4.45157961e-01],
[-2.34526366e-01],
[ 9.86608594e-01],
[ 2.65230652e-01],
[ 3.51938093e-02],
[ 3.07464334e-01],
[-1.04311239e-01],
[-6.49166901e-02],
[ 2.11224757e-01],
[-2.43159815e-01],
[-1.31285604e-01],
[ 1.09045810e+00],
[-3.97913710e-02],
[ 9.19563678e-01],
[-9.44824150e-01],
[-5.04137735e-01],
[ 6.81272939e-01],
[-1.34494828e+00],
[-2.68009542e-01],
[ 4.36204342e-02],
[ 1.89619513e+00],
[-3.41873873e-01],
[ 1.89162461e-01],
[ 1.73251268e-02],
[ 3.14431930e-01],
[-3.40828467e-01],
[ 4.92385651e-01],
[ 9.29634214e-02],
[-4.50983589e-01],
[ 1.47456584e+00],
[-3.03417236e-02],
[ 7.71229328e-02],
[ 6.38314494e-01],
[-7.93287087e-01],
[ 8.82877506e-01],
[ 3.18965610e+00],
[-5.75671706e+00],
[ 1.60748945e+00],
[ 1.36142440e+01],
[ 1.50029111e-01],
[-4.78389603e-02],
[-6.29463755e-02],
[-2.85383032e-02],
[-3.01562821e-01],
[ 4.12058013e-01],
[-6.77534154e-02],
[-1.00985479e-01],
[-1.68972973e-01],
[ 1.64093233e+00],
[ 1.89670371e+00],
[ 3.94713816e-01],
[-4.71231449e+00],
[-7.42760774e+00],
[ 6.19781936e+00],
[ 3.53986244e+00],
[-9.56245861e-01],
[-1.04372792e+00],
[-4.92863713e-01],
[ 6.31608790e-01],
[-4.85175956e-01],
[ 2.58400216e-01],
[ 9.43846795e-02],
[-1.29323184e-01],
[-3.81235287e-01],
[ 3.86819479e-01],
[ 4.04211627e-01],
[ 3.75568914e-01],
[ 1.83512261e-01],
[-8.01417708e-02],
[-3.10188597e-01],
[-3.96124612e-01],
[ 3.66227853e-01],
[ 1.79488593e-01],
[-3.14477051e-01],
[-2.37611443e-01],
[ 3.97076104e-02],
[ 1.38775912e-01],
[-3.84015069e-02],
[-5.47557119e-02],
[ 4.19975207e-01],
[ 4.46120687e-01],
[-4.31074826e-01],
[-8.74450768e-02],
[-5.69534264e-02],
[-7.23980157e-02],
[-1.39880128e-02],
[ 1.40489658e-01],
[-2.44952334e-01],
[ 1.83646770e-01],
[-1.64135512e-01],
[-7.41216452e-02],
[-9.71414213e-02],
[ 1.98829041e-02],
[-4.46965919e-01],
[-2.63440959e-01],
[ 1.52924043e-01],
[ 6.52532847e-02],
[ 7.06818266e-01],
[ 9.73757051e-02],
[-3.35687787e-01],
[-2.26559165e-01],
[-3.00117086e-01],
[ 1.24185231e-01],
[ 4.18872344e-01],
[-2.51891946e-01],
[-1.29095731e-01],
[-5.57512471e-01],
[ 8.76239582e-02],
[ 3.02594902e-01],
[-4.23463160e-01],
[ 4.89922051e-01]])
Testing

载入 test data,并且以相似于训练资料预先处理和特徵萃取的方式处理,使 test data 形成 240 个维度为 18 * 9 + 1 的资料。
# testdata = pd.read_csv('gdrive/My Drive/hw1-regression/test.csv', header = None, encoding = 'big5')
testdata = pd.read_csv('./test.csv', header = None, encoding = 'big5')
test_data = testdata.iloc[:, 2:]
test_data[test_data == 'NR'] = 0
test_data = test_data.to_numpy()
test_x = np.empty([240, 18*9], dtype = float)
for i in range(240):
test_x[i, :] = test_data[18 * i: 18* (i + 1), :].reshape(1, -1)
for i in range(len(test_x)):
for j in range(len(test_x[0])):
if std_x[j] != 0:
test_x[i][j] = (test_x[i][j] - mean_x[j]) / std_x[j]
test_x = np.concatenate((np.ones([240, 1]), test_x), axis = 1).astype(float)
test_x
E:\programs\ana\lib\site-packages\ipykernel_launcher.py:4: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
after removing the cwd from sys.path.
E:\programs\ana\lib\site-packages\pandas\core\frame.py:3414: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
self._where(-key, value, inplace=True)
array([[ 1. , -0.24447681, -0.24545919, ..., -0.67065391,
-1.04594393, 0.07797893],
[ 1. , -1.35825331, -1.51789368, ..., 0.17279117,
-0.10906991, -0.48454426],
[ 1. , 1.5057434 , 1.34508393, ..., -1.32666675,
-1.04594393, -0.57829812],
...,
[ 1. , 0.3919669 , 0.54981237, ..., 0.26650729,
-0.20275731, 1.20302531],
[ 1. , -1.8355861 , -1.8360023 , ..., -1.04551839,
-1.13963133, -1.14082131],
[ 1. , -1.35825331, -1.35883937, ..., 2.98427476,
3.26367657, 1.76554849]])
Prediction
说明图同上

有了 weight 和测试资料就可以预测 target。
w = np.load('weight.npy')
ans_y = np.dot(test_x, w)
ans_y
array([[ 5.17496040e+00],
[ 1.83062143e+01],
[ 2.04912181e+01],
[ 1.15239429e+01],
[ 2.66160568e+01],
[ 2.05313481e+01],
[ 2.19065510e+01],
[ 3.17364687e+01],
[ 1.33916741e+01],
[ 6.44564665e+01],
[ 2.02645688e+01],
[ 1.53585761e+01],
[ 6.85894728e+01],
[ 4.84281137e+01],
[ 1.87023338e+01],
[ 1.01885957e+01],
[ 3.07403629e+01],
[ 7.11322178e+01],
[-4.13051739e+00],
[ 1.82356940e+01],
[ 3.85789223e+01],
[ 7.13115197e+01],
[ 7.41034816e+00],
[ 1.87179553e+01],
[ 1.49372503e+01],
[ 3.67197367e+01],
[ 1.79616970e+01],
[ 7.57894629e+01],
[ 1.23093102e+01],
[ 5.62953517e+01],
[ 2.51131609e+01],
[ 4.61024867e+00],
[ 2.48377055e+00],
[ 2.47594223e+01],
[ 3.04802805e+01],
[ 3.84639307e+01],
[ 4.42023106e+01],
[ 3.00868360e+01],
[ 4.04736750e+01],
[ 2.92264799e+01],
[ 5.60645605e+00],
[ 3.86660161e+01],
[ 3.46102134e+01],
[ 4.83896975e+01],
[ 1.47572477e+01],
[ 3.44668201e+01],
[ 2.74831069e+01],
[ 1.20008794e+01],
[ 2.13780362e+01],
[ 2.85444031e+01],
[ 2.01655138e+01],
[ 1.07966781e+01],
[ 2.21710358e+01],
[ 5.34462631e+01],
[ 1.22195811e+01],
[ 4.33009685e+01],
[ 3.21823351e+01],
[ 2.25672175e+01],
[ 5.67395142e+01],
[ 2.07450529e+01],
[ 1.50288546e+01],
[ 3.98553016e+01],
[ 1.29753407e+01],
[ 5.17416596e+01],
[ 1.87833696e+01],
[ 1.23487528e+01],
[ 1.56336237e+01],
[-5.88714707e-02],
[ 4.15080111e+01],
[ 3.15487475e+01],
[ 1.86042512e+01],
[ 3.74768197e+01],
[ 5.65203907e+01],
[ 6.58787719e+00],
[ 1.22293397e+01],
[ 5.20369640e+00],
[ 4.79273751e+01],
[ 1.30207057e+01],
[ 1.71103017e+01],
[ 2.06032345e+01],
[ 2.12844816e+01],
[ 3.86929353e+01],
[ 3.00207167e+01],
[ 8.87674067e+01],
[ 3.59847002e+01],
[ 2.67569136e+01],
[ 2.39635168e+01],
[ 3.27472428e+01],
[ 2.21890438e+01],
[ 2.09921589e+01],
[ 2.95559943e+01],
[ 4.09921689e+01],
[ 8.62511781e+00],
[ 3.23214718e+01],
[ 4.65980444e+01],
[ 2.28840708e+01],
[ 3.15181297e+01],
[ 1.11982335e+01],
[ 2.85274366e+01],
[ 2.91150680e-01],
[ 1.79669611e+01],
[ 2.71241639e+01],
[ 1.13982328e+01],
[ 1.64264269e+01],
[ 2.34252610e+01],
[ 4.06160827e+01],
[ 2.58641250e+01],
[ 5.42273695e+00],
[ 1.07949211e+01],
[ 7.28621369e+01],
[ 4.80228371e+01],
[ 1.57468083e+01],
[ 2.46704106e+01],
[ 1.28277933e+01],
[ 1.01580576e+01],
[ 2.72692233e+01],
[ 2.92087386e+01],
[ 8.83533962e+00],
[ 2.00510881e+01],
[ 2.02123337e+01],
[ 7.99060093e+01],
[ 1.80616143e+01],
[ 3.05428093e+01],
[ 2.59807924e+01],
[ 5.21257727e+00],
[ 3.03556973e+01],
[ 7.76832289e+00],
[ 1.53282683e+01],
[ 2.26663657e+01],
[ 6.27420542e+01],
[ 1.89507804e+01],
[ 1.90763556e+01],
[ 6.13715741e+01],
[ 1.58845621e+01],
[ 1.34094181e+01],
[ 8.48772484e-01],
[ 7.83499672e+00],
[ 5.70128290e+01],
[ 2.56079968e+01],
[ 4.96170473e+00],
[ 3.64148790e+01],
[ 2.87900067e+01],
[ 4.91941210e+01],
[ 4.03068699e+01],
[ 1.33161806e+01],
[ 2.76610119e+01],
[ 1.71580275e+01],
[ 4.96872626e+01],
[ 2.30302723e+01],
[ 3.92409365e+01],
[ 1.31967539e+01],
[ 5.94889370e+00],
[ 2.58216090e+01],
[ 8.25863421e+00],
[ 1.91463205e+01],
[ 4.31824865e+01],
[ 6.71784358e+00],
[ 3.38696152e+01],
[ 1.53699378e+01],
[ 1.69390450e+01],
[ 3.78853368e+01],
[ 1.92024845e+01],
[ 9.05950472e+00],
[ 1.02833996e+01],
[ 4.86724471e+01],
[ 3.05877162e+01],
[ 2.47740990e+00],
[ 1.28116039e+01],
[ 7.03247898e+01],
[ 1.48409677e+01],
[ 6.88655876e+01],
[ 4.27419924e+01],
[ 2.40002615e+01],
[ 2.34207249e+01],
[ 6.16721244e+01],
[ 2.54942028e+01],
[ 1.90048098e+01],
[ 3.48866829e+01],
[ 9.40231340e+00],
[ 2.95200113e+01],
[ 1.45739659e+01],
[ 9.12556314e+00],
[ 5.28125840e+01],
[ 4.50395380e+01],
[ 1.74524347e+01],
[ 3.84939353e+01],
[ 2.70389191e+01],
[ 6.55817097e+01],
[ 7.03730638e+00],
[ 5.27144771e+01],
[ 3.82064593e+01],
[ 2.11698011e+01],
[ 3.02475569e+01],
[ 2.71442299e+00],
[ 1.99329326e+01],
[-3.41333234e+00],
[ 3.24459994e+01],
[ 1.05829730e+01],
[ 2.17752257e+01],
[ 6.24652921e+01],
[ 2.41329437e+01],
[ 2.62012396e+01],
[ 6.37444772e+01],
[ 2.83429777e+00],
[ 1.43792470e+01],
[ 9.36985073e+00],
[ 9.88116661e+00],
[ 3.49494536e+00],
[ 1.22608049e+02],
[ 2.10835130e+01],
[ 1.75322206e+01],
[ 2.01830983e+01],
[ 3.63931322e+01],
[ 3.49351512e+01],
[ 1.88303127e+01],
[ 3.83445555e+01],
[ 7.79166341e+01],
[ 1.79532355e+00],
[ 1.34458279e+01],
[ 3.61311556e+01],
[ 1.51504035e+01],
[ 1.29418483e+01],
[ 1.13125241e+02],
[ 1.52246047e+01],
[ 1.48240260e+01],
[ 5.92673537e+01],
[ 1.05836953e+01],
[ 2.09930626e+01],
[ 9.78936588e+00],
[ 4.77118001e+00],
[ 4.79278069e+01],
[ 1.23994384e+01],
[ 4.81464766e+01],
[ 4.04663804e+01],
[ 1.69405903e+01],
[ 4.12665445e+01],
[ 6.90278920e+01],
[ 4.03462492e+01],
[ 1.43137440e+01],
[ 1.57707266e+01]])
Save Prediction to CSV File
import csv
with open('submit.csv', mode='w', newline='') as submit_file:
csv_writer = csv.writer(submit_file)
header = ['id', 'value']
print(header)
csv_writer.writerow(header)
for i in range(240):
row = ['id_' + str(i), ans_y[i][0]]
csv_writer.writerow(row)
print(row)
['id', 'value']
['id_0', 5.17496039898473]
['id_1', 18.306214253527884]
['id_2', 20.491218094180553]
['id_3', 11.523942869805396]
['id_4', 26.61605675230615]
['id_5', 20.531348081761205]
['id_6', 21.90655101879739]
['id_7', 31.736468747068834]
['id_8', 13.391674055111714]
['id_9', 64.45646650291955]
['id_10', 20.264568836159434]
['id_11', 15.35857607736122]
['id_12', 68.58947276926725]
['id_13', 48.428113747457175]
['id_14', 18.702333824193207]
['id_15', 10.188595737466695]
['id_16', 30.74036285982043]
['id_17', 71.13221776355115]
['id_18', -4.130517391262446]
['id_19', 18.23569401642868]
['id_20', 38.57892227500776]
['id_21', 71.3115197253133]
['id_22', 7.410348162634058]
['id_23', 18.717955330321416]
['id_24', 14.937250260084554]
['id_25', 36.71973669470531]
['id_26', 17.961697005662685]
['id_27', 75.78946287210539]
['id_28', 12.309310248614453]
['id_29', 56.29535173964959]
['id_30', 25.11316086566151]
['id_31', 4.610248674094034]
['id_32', 2.4837705545150186]
['id_33', 24.759422261321248]
['id_34', 30.480280465591157]
['id_35', 38.46393074642664]
['id_36', 44.20231060933004]
['id_37', 30.086836019865984]
['id_38', 40.4736750157401]
['id_39', 29.226479902317386]
['id_40', 5.606456054343951]
['id_41', 38.66601607878963]
['id_42', 34.61021343187721]
['id_43', 48.3896975073848]
['id_44', 14.757247666944162]
['id_45', 34.4668201108721]
['id_46', 27.483106874184347]
['id_47', 12.000879378154046]
['id_48', 21.37803615160376]
['id_49', 28.544403091663284]
['id_50', 20.165513818411576]
['id_51', 10.79667814974648]
['id_52', 22.171035755750097]
['id_53', 53.44626310935229]
['id_54', 12.219581121610055]
['id_55', 43.30096845517151]
['id_56', 32.18233510328544]
['id_57', 22.5672175145708]
['id_58', 56.73951416554707]
['id_59', 20.745052945295456]
['id_60', 15.028854557473316]
['id_61', 39.85530159038513]
['id_62', 12.975340680728312]
['id_63', 51.74165959283005]
['id_64', 18.783369632539838]
['id_65', 12.348752842777685]
['id_66', 15.63362365354191]
['id_67', -0.058871470685000205]
['id_68', 41.50801107307592]
['id_69', 31.54874753065601]
['id_70', 18.60425115754707]
['id_71', 37.47681972488069]
['id_72', 56.52039065762304]
['id_73', 6.587877193521948]
['id_74', 12.229339737434998]
['id_75', 5.203696404134661]
['id_76', 47.92737510380057]
['id_77', 13.020705685594685]
['id_78', 17.110301693903622]
['id_79', 20.603234531002034]
['id_80', 21.284481560784595]
['id_81', 38.692935290511784]
['id_82', 30.02071667572585]
['id_83', 88.76740666723549]
['id_84', 35.984700239668285]
['id_85', 26.756913553477247]
['id_86', 23.96351684356442]
['id_87', 32.74724282808308]
['id_88', 22.189043755319915]
['id_89', 20.99215885362659]
['id_90', 29.555994316645414]
['id_91', 40.99216886651783]
['id_92', 8.625117809911531]
['id_93', 32.321471808877895]
['id_94', 46.59804436536765]
['id_95', 22.88407082672351]
['id_96', 31.518129728251658]
['id_97', 11.198233479766118]
['id_98', 28.5274366425296]
['id_99', 0.2911506800896113]
['id_100', 17.96696107953969]
['id_101', 27.124163929470164]
['id_102', 11.398232780652839]
['id_103', 16.426426865673537]
['id_104', 23.425261046922216]
['id_105', 40.61608267056839]
['id_106', 25.8641250265604]
['id_107', 5.42273695167237]
['id_108', 10.794921122256113]
['id_109', 72.86213692992129]
['id_110', 48.02283705948139]
['id_111', 15.746808276902968]
['id_112', 24.67041061417796]
['id_113', 12.827793326536725]
['id_114', 10.158057570240508]
['id_115', 27.269223342020958]
['id_116', 29.208738577932436]
['id_117', 8.835339619930693]
['id_118', 20.051088137129703]
['id_119', 20.212333743764255]
['id_120', 79.90600929870558]
['id_121', 18.06161428826359]
['id_122', 30.542809341304366]
['id_123', 25.980792377728037]
['id_124', 5.212577268164768]
['id_125', 30.355697305856225]
['id_126', 7.7683228889146285]
['id_127', 15.32826825539334]
['id_128', 22.666365717697936]
['id_129', 62.742054211090064]
['id_130', 18.950780367988038]
['id_131', 19.076355630838528]
['id_132', 61.371574091637086]
['id_133', 15.884562052629676]
['id_134', 13.409418077705531]
['id_135', 0.8487724836112704]
['id_136', 7.834996717304147]
['id_137', 57.012829011796796]
['id_138', 25.607996751813808]
['id_139', 4.961704729242088]
['id_140', 36.414879039062725]
['id_141', 28.79000672197592]
['id_142', 49.19412096197631]
['id_143', 40.306869855734476]
['id_144', 13.31618059398265]
['id_145', 27.661011875229143]
['id_146', 17.158027524366755]
['id_147', 49.687262569296834]
['id_148', 23.030272291604806]
['id_149', 39.24093652484275]
['id_150', 13.196753889412532]
['id_151', 5.948893701039438]
['id_152', 25.82160897630426]
['id_153', 8.258634214291632]
['id_154', 19.146320517225583]
['id_155', 43.182486526516726]
['id_156', 6.717843578093014]
['id_157', 33.869615246810646]
['id_158', 15.369937846981848]
['id_159', 16.93904497355191]
['id_160', 37.88533679463485]
['id_161', 19.202484541054446]
['id_162', 9.059504715654704]
['id_163', 10.283399610648486]
['id_164', 48.6724471256983]
['id_165', 30.58771621323077]
['id_166', 2.477409897532155]
['id_167', 12.811603937805945]
['id_168', 70.32478980976464]
['id_169', 14.840967694067011]
['id_170', 68.8655875667886]
['id_171', 42.74199244486631]
['id_172', 24.000261542920157]
['id_173', 23.420724860321425]
['id_174', 61.672124435682356]
['id_175', 25.494202845059167]
['id_176', 19.004809786869064]
['id_177', 34.88668288189682]
['id_178', 9.402313398379732]
['id_179', 29.52001131440803]
['id_180', 14.573965885700474]
['id_181', 9.125563143203571]
['id_182', 52.8125839981319]
['id_183', 45.03953799438962]
['id_184', 17.452434679183277]
['id_185', 38.4939352797143]
['id_186', 27.03891909264381]
['id_187', 65.58170967424583]
['id_188', 7.0373063807696035]
['id_189', 52.71447713411571]
['id_190', 38.20645933704978]
['id_191', 21.16980105955784]
['id_192', 30.2475568794884]
['id_193', 2.7144229897163115]
['id_194', 19.932932587640824]
['id_195', -3.4133323376039186]
['id_196', 32.44599940281315]
['id_197', 10.5829730299799]
['id_198', 21.77522570725845]
['id_199', 62.46529206567796]
['id_200', 24.132943687316427]
['id_201', 26.201239647400946]
['id_202', 63.744477234402886]
['id_203', 2.8342977741290376]
['id_204', 14.379246986978856]
['id_205', 9.369850731753871]
['id_206', 9.881166613595408]
['id_207', 3.494945358972136]
['id_208', 122.60804937921779]
['id_209', 21.08351301448058]
['id_210', 17.5322205994551]
['id_211', 20.18309834459703]
['id_212', 36.39313221228185]
['id_213', 34.935151205290694]
['id_214', 18.830312661458635]
['id_215', 38.344555522723326]
['id_216', 77.9166341380704]
['id_217', 1.795323550888213]
['id_218', 13.445827939135782]
['id_219', 36.13115559041212]
['id_220', 15.150403498166295]
['id_221', 12.941848334417912]
['id_222', 113.1252409378639]
['id_223', 15.224604677934366]
['id_224', 14.824025968612084]
['id_225', 59.26735368854046]
['id_226', 10.58369529071846]
['id_227', 20.99306256353219]
['id_228', 9.789365880830376]
['id_229', 4.771180008705976]
['id_230', 47.92780690481288]
['id_231', 12.39943839475102]
['id_232', 48.14647656264414]
['id_233', 40.46638039656413]
['id_234', 16.940590270332923]
['id_235', 41.266544489418735]
['id_236', 69.027892033729]
['id_237', 40.346249244122404]
['id_238', 14.313743982871117]
['id_239', 15.770726634219777]
相关的reference 可以參考:
Adagrad :
https://youtu.be/yKKNr-QKz2Q?list=PLJV_el3uVTsPy9oCRY30oBPNLCo89yu49&t=705
RMSprop :
https://www.youtube.com/watch?v=5Yt-obwvMHI
Adam
https://www.youtube.com/watch?v=JXQT_vxqwIs
以上 print 的部分主要是为了看一下资料和结果的呈现,拿掉也无妨。另外,在自己的 linux 系统,可以将档案写死的的部分换成 sys.argv 的使用 (可在 terminal 自行输入档案和档案位置)。
最后,可以藉由调整 learning rate、iter_time (iteration 次数)、取用 features 的多少(取几个小时,取哪些特征),甚至是不同的 model 来超越 baseline。