初入Kaggle之数据集的使用及预测结果生成
目录
划分数据集
读取数据集
使用数据集
预测结果生成
单次预测
结果生成
使用resnet网络预测植物幼苗分类。
kaggle链接:weiliutao | Novice | Kaggle
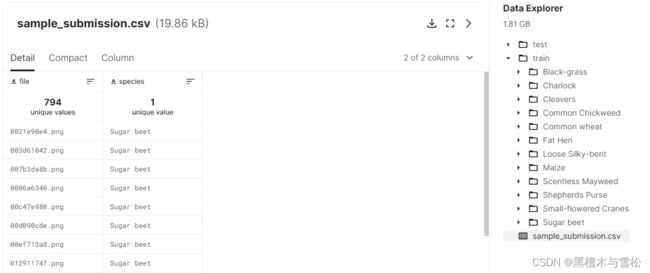
给的数据分为三部门,第一个是test文件夹,存放所有要预测的图片。第二个是train文件夹,里面是各个已经分好类别的植物幼苗图片文件夹,用来进行训练模型。还有一个提交样例的csv文件。
划分数据集
由于我们在训练网络时要关注模型在每一轮的正确率,因此需要将train(在实现时防止混淆我将这个名称改为train1)下的数据划分为训练集和验证集,即将train1文件夹划分为train和val文件夹,一般以0.9:0.1进行划分。train和val文件夹下仍然是各个种类幼苗的文件夹,使用一个划分脚本来实现。
代码源自:同济子豪兄的个人空间_哔哩哔哩_bilibili
import os
from shutil import copy, rmtree
import random
def mk_file(file_path: str):
if os.path.exists(file_path):
# 如果文件夹存在,则先删除原文件夹在重新创建
rmtree(file_path)
os.makedirs(file_path)
def main():
# 保证随机可复现
random.seed(0)
# 将数据集中10%的数据划分到验证集中
split_rate = 0.1
# 指向你解压后的flower_photos文件夹
#这里的os.getcwd方法是获取当前代码所在路径
#我的数据集在上上一级目录下的data_set的plant下的train_1中
cwd = os.getcwd()
data_root = os.path.join(cwd, "../data_set/plant")
origin_flower_path = os.path.join(data_root, "train_1")
assert os.path.exists(origin_flower_path), "path '{}' does not exist.".format(origin_flower_path)
flower_class = [cla for cla in os.listdir(origin_flower_path)
if os.path.isdir(os.path.join(origin_flower_path, cla))]
# 建立保存训练集的文件夹,生成在data_root目录下
train_root = os.path.join(data_root, "train")
mk_file(train_root)
for cla in flower_class:
# 建立每个类别对应的文件夹
mk_file(os.path.join(train_root, cla))
# 建立保存验证集的文件夹
val_root = os.path.join(data_root, "val")
mk_file(val_root)
for cla in flower_class:
# 建立每个类别对应的文件夹
mk_file(os.path.join(val_root, cla))
for cla in flower_class:
cla_path = os.path.join(origin_flower_path, cla)
images = os.listdir(cla_path)
num = len(images)
# 随机采样验证集的索引
eval_index = random.sample(images, k=int(num*split_rate))
for index, image in enumerate(images):
if image in eval_index:
# 将分配至验证集中的文件复制到相应目录
image_path = os.path.join(cla_path, image)
new_path = os.path.join(val_root, cla)
copy(image_path, new_path)
else:
# 将分配至训练集中的文件复制到相应目录
image_path = os.path.join(cla_path, image)
new_path = os.path.join(train_root, cla)
copy(image_path, new_path)
print("\r[{}] processing [{}/{}]".format(cla, index+1, num), end="") # processing bar
print()
print("processing done!")
if __name__ == '__main__':
main()
读取数据集
在train模块中使用这个数据集时: 首先将路径指定到存放train和val的文件夹下,也就是plant,这里我存储的位置是上上级目录的data_set文件夹下的plant。
data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # get data root path
image_path = os.path.join(data_root, "data_set", "plant") # flower data set path
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"])找到文件夹后使用torchvision下的datasets包的ImageFolder方法读取‘train’文件中的训练图片 ,这里的transform是对图片做出的处理,先不管。
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=nw)
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),
transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=batch_size, shuffle=False,
num_workers=nw)train_loader是使用DataLoader方法处理刚刚读取的train_dataset,batch_size是将图片按照给定的batch_size分组,shuffle是否打乱顺序,num_workers是使用cpu或GPU的个数。
有了数据集,便能使用神经网络进行训练。在训练时如何使用这些图片。
使用数据集
tqdm是为了记录时间。
通过enumerate遍历训练集(此时的训练集分为若干个batch_size大小的集合),每次step都会得到一个batch_size大小的集合,分别为images集合和labels集合,将images送到模型得到结果。再将结果与真实标签label作损失函数处理,再反向传播。
for epoch in range(epochs):
# train
net.train()
running_loss = 0.0
train_bar = tqdm(train_loader, file=sys.stdout)
for step, data in enumerate(train_bar):
images, labels = data
optimizer.zero_grad()
logits = net(images.to(device))
loss = loss_function(logits, labels.to(device))
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
loss)
# validate
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
val_bar = tqdm(validate_loader, file=sys.stdout)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
# loss = loss_function(outputs, test_labels)
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_bar.desc = "valid epoch[{}/{}]".format(epoch + 1,
epochs)
val_accurate = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print('Finished Training')预测结果生成
因为不会将一个列表写入到一个csv文件中,所以搜了一下写了个测试代码:
import pandas as pd
import numpy as np
# predict_kind = np.array([np.arange(794) , np.arange(2)] , dtype=str)
# predict_kind[0][0]='12323'
# print(predict_kind)
# import numpy as np
# m = np.array([np.arange(2), np.arange(5)], dtype=str) # 创建一个二维数组
# m[0][1] = "love"
# print(m)
# print(m[0][1])
# a = np.array(794*2,dtype=object)
# a[1] = "12sdsds"
# print(a)
a = [[] for i in range(5)]
a[0].append("asdasda")
a[0].append("ppppp")
a[1].append(("dddd"))
print(a)
data1 = pd.DataFrame(a)
data1.to_csv('d.csv')测试了很多发现最后没有注释的可以实现,因为我想要两列数据,一列是图片名称,一列是预测值,在此处定义一个二维列表,每个一维维度都代表一行数据,也就是一行中的两个数据,将列表转换为DataFrame格式才能写入csv文件中。
单次预测
这里我稍微改了预测方法为带参方法,传入的是图片的路径,进行预处理后(和训练时方式一样)将这张图片拿给模型,模型给出概率最大的结果。
Image是PIL包中的类,可以通过给定图片路径拿到图片
data_transform是对图片做出的处理,这时候的图片是一个三维[C,H,W],在最前面加上一个维度。
def result(image_name):
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_transform = transforms.Compose(
[transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
# load image
img_path = image_name
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path)
#plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
json_path = './class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
with open(json_path, "r") as f:
class_indict = json.load(f)
# create model
model = resnet101(num_classes=12).to(device)
# load model weights
weights_path = "./resNet101.pth"
assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)
model.load_state_dict(torch.load(weights_path, map_location=device))
# prediction
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
return class_indict[str(predict_cla)]model(img)将图片给到模型,再压缩batch方向维度。通过softmax处理得到概率分布。通过argmax找到最大值所对应的索引。在class_indict找到索引对应的类别。
结果生成
通过os.listdir可以遍历文件夹下的所有文件名称,先将名称加入进去,将路径加上图片名称传给result,将每个预测结果存放到名称后面,最后转换为DataFrame存储到CSV文件中。
data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # get data root path
image_path = os.path.join(data_root, "data_set", "plant","test") # flower data set path
predict_kind = [[] for i in range(794)]
i=0
for filename in os.listdir(image_path):
#image_name.append(filename)
predict_kind[i].append(filename)
path_image = os.path.join(image_path, filename)
predict_kind[i].append(result(path_image))
#print(path_image)
#predict_kind.append(result(path_image))
i+=1
print(i)
#print(predict_kind)
data1 = pd.DataFrame(predict_kind)
data1.to_csv('predict_2.csv')