【论文翻译】异构信息网络挖掘的活动边缘中心多标签分类
异构信息网络挖掘的活动边缘中心多标签分类
摘要
异构信息网络的多标签分类在社会网络分析中受到了新的关注。本文提出了一个以活动边缘为中心的多标签分类框架,用于分析具有三个独特特征的异构信息网络。首先,我们根据一个协作图和多个相关联的活动图来建模一个异构信息网络。我们根据顶点标签和边标签引入了一个新的点边同态概念,并通过基于活动的边分类,用每个活动图的类标签来扩充边,从而将一般的协作图转化为基于活动的协作多图。第二,在基于活动的协作多图标记的基础上,利用标记邻域来获取成对的顶点贴近度。我们将结构相似性和标签邻近性结合到一个统一的分类器中,以加速分类收敛。第三,我们设计了一个迭代学习算法AEClass,通过不断调整来自多个活动图的不同基于活动的边缘分类方案上的权重来动态细化分类结果,同时不断学习统一分类器中的结构相似度和标签邻近度的贡献。对真实数据集的广泛评估表明,AEClasses在有效性和效率方面都优于现有的代表性方法。
关键词
多标签分类;异构网络;基于活动的边缘分类;协作多图;标签邻域
1导言
在过去十年中,多标签分类在数据挖掘和机器学习中得到了越来越多的关注[10–22]。与单标签分类相比,多标签分类分析采用了一种更现实的观点,即现实世界中的实体往往同时与多个类标签关联。例如,一个社会网络中的大多数人属于多个社会群体,参与不同参与程度的多种活动。web图中的大多数网页可能涵盖不同强度的多个主题。
现有的网络数据多标签分类工作主要集中在设计有效且可扩展的算法上[17-22]。尽管之前的研究在挖掘连锁结构的具体方法上有所不同,但据我们所知,它们都有两个弱点:(1)以往的研究都没有将不同类型的活动图从异构信息网络中分离出来,也没有利用每个活动图中以及跨多个活动图的类标签集之间的相关性;(2)以往的工作都没有将以顶点为中心的多标签分类和以边缘为中心的多标签分类相结合来提高分类的有效性和效率。
在本文中,我们利用以活动边缘为中心的方法,可以合并两个缺失维度,以提高多标签分类分析的准确性和复杂性。首先,我们认为现实世界中的实体可能会参与多种活动网络。这些活动网络可以提供关于异构实体和链接的丰富信息,以及如何在每个活动网络的上下文中链接实体。我们的目标是利用这些活动网络找到一种自然而廉价的方法来识别标签之间的相互依赖关系。第二,基于不同的活动网络,一个实体可以由K个具有不同类成员分布的标签的子集来标记。我们将每个活动网络的类成员分布建模为多标记边。第三,我们不仅考虑相关顶点的标签,还考虑相关边的可能标签,以进一步提高多标签分类的准确性。我们将以顶点为中心的标记和以边缘为中心的标记集成到一个具有不同权重的统一分类器中。提出了一种迭代的方法来学习分类目标的权值。
本文对网络数据的多标签分类做了以下贡献。
- 我们用一个协作图和多个相关的活动图对异构信息网络进行建模,并用给定的K类标签将每个活动图中的活动顶点聚类为K个类别。对每个活动图进行聚类提供了一种自然的方法来捕获活动图中活动类别之间的依赖关系。
- 我们从顶点标签和边标签两个方面引入了一个新的顶点-边同胚概念,并通过基于活动的边分类,用每个活动图的类标签扩充其边,将一般的协作图转化为基于活动的协作多图。
- •我们利用结构亲和性来捕捉顶点的成对拓扑相似性,利用标签邻域来捕捉基于活动的协作多重图上的标签的成对顶点贴近度。我们将结构亲和力和标签邻域结合到一个统一的分类器中,以加速分类收敛。
- 我们设计了一个迭代学习算法AEClass,通过不断调整多个活动图中不同基于活动的边缘分类方案的权重,动态细化分类结果,同时不断学习统一分类器中结构亲和力和标签邻域的贡献。为了使分类过程快速收敛,将复杂的多权非线性分式规划问题转化为简单的单变量参数规划问题。
- 对真实多标签数据集的实证评估表明,在推理性能和时间复杂性方面,AEClass与最新方法相比具有竞争力。
2问题定义、
我们采用以活动边缘为中心的多标签分类算法来解决网络数据的多标签分类问题。首先,我们用两种类型的信息网络来建模一个异构信息网络:(1)实例级的协作图,这是多标签分类的目标;(2)类别级的关联活动图的集合。例如,DBLP书目数据集可能由三种类型的顶点组成:作者、出版场所(如会议、期刊)和出版物中的标题术语。一个作者可以在多个地点发表文章,他的论文可能包含多个术语。如果多标签分类的目标是推断作者的标签,那么我们在实例级将DBLP数据集转化为作者的主要协作网络,在类别级将其转化为两个相关的活动网络(会议相似网络和术语相似网络)。协作网络是基于给定K类标签的标记实例和未标记实例定义的,其中每个顶点表示一个实例,每个边反映成对实例之间的协作关系,例如,合著出版物的数量。每个关联的活动网络都是以所有关联的活动为顶点构建的。相似的活动被连接在一起,每个边值表示成对活动之间的相似性,例如产品购买活动网络、体育活动网络或会议活动网络。考虑到协作网络中的每个实体可能参与每个活动网络中的多个活动,我们将每个活动网络中的所有活动聚类为K类。然后,通过对基于N个活动网络的协作图进行扩充,构造了一个协作多重图:对于协作图中每一对有边的顶点,如果两个顶点都至少参与了N个活动网络中的一个,那么我们将在这对顶点之间加上K条边。


图1给出了一个从DBLP数据集中提取的示例,由三个图组成:作者协作图、会议活动图和术语活动图。为了便于发表,我们只选择发表在SIGMOD、VLDB和ICDE三个顶级DB会议上的合著论文,以及KDD、ICDM和SDM三个顶级DM会议上的合著论文。在图1(a)中,赭色标签和绿色标签表示作者分别获得了DB和DM的预定义类标签。此外,每个顶点矩形中的赭色块或绿色块表示属于DB或DM类的作者的比例。我们想利用四个标签作者的标签信息来学习Philip S.Yu在DB和DM类上的类成员概率。在图1(b)中,蓝色数字度量两两会议之间的相似性得分。我们利用一个多类型的软集群框架NetClus[25],将会议和术语同时集群到24个CS研究领域[31]。根据会议在24个类别上的聚类分布和每个类别中的排名得分,计算会议活动图中会议之间的相似度。类似地,图1(c)中的红色数字度量术语之间的相似性得分。然后,我们选择每个会议或每个术语的概率最高的类别作为其主要类别,并将其放入相应的主要类别中。这个操作实际上为每个活动网络生成一个硬聚类结果。如图2所示,图1(b)和(c)中的会议和术语分别被归入各自的主要类别。
我们将上述概念正式定义如下。
协作图表示为CG=(V,F),其中V是表示CG中实体(如客户或作者)的顶点集,F是表示成员之间协作关系的边集。我们用![]() 来表示V的大小,即
来表示V的大小,即![]() 。
。
活动图由 定义,其中
定义,其中![]() 表示第i个关联活动网络
表示第i个关联活动网络![]() 中的一个活动顶点,
中的一个活动顶点,![]() 是表示两个活动顶点之间相似性的加权边,如功能相似性或制造相似性。我们将每个活动顶点集的大小表示为
是表示两个活动顶点之间相似性的加权边,如功能相似性或制造相似性。我们将每个活动顶点集的大小表示为![]() 。顶点集
。顶点集![]() 被划分为K个不相交的基本类别,用
被划分为K个不相交的基本类别,用![]() 表示,使得
表示,使得![]() 和
和
 ,对于
,对于![]() ,每个活动类别
,每个活动类别![]() 用K类标签
用K类标签 中的一个来标记。
中的一个来标记。
给定协作图CG=(V,F)及其N个相关活动图![]() ,则表示为MG=(V,E)的协作多图是一个活动边增广多图,其中V在CG中具有相同的定义,E是满足以下条件的边集:对于CG中的每个边
,则表示为MG=(V,E)的协作多图是一个活动边增广多图,其中V在CG中具有相同的定义,E是满足以下条件的边集:对于CG中的每个边![]() ,我们创建E中一组顶点对之间的平行边。每一组边都有高达K标记的边,每个边对应于N个活动图中(p∈{1,···,K})标记的一个活动类别。
,我们创建E中一组顶点对之间的平行边。每一组边都有高达K标记的边,每个边对应于N个活动图中(p∈{1,···,K})标记的一个活动类别。
多图的多标号分类问题定义如下:设![]() 是K个可能的类标号的有限集。给定一个协作多图MG=(V,E),其中一组多标签训练实例
是K个可能的类标号的有限集。给定一个协作多图MG=(V,E),其中一组多标签训练实例![]() 最初使用给定的K类标签标记,一组多标签测试实例
最初使用给定的K类标签标记,一组多标签测试实例![]() 未标记。为了简洁起见,我们假设V中的顶点是有序的,第一个l顶点是有标签的,其余的顶点是无标签的。因此我们得到
未标记。为了简洁起见,我们假设V中的顶点是有序的,第一个l顶点是有标签的,其余的顶点是无标签的。因此我们得到![]() 。假设一个实例
。假设一个实例![]() 与C中的一个标签子集相关联,即使用一个二元向量
与C中的一个标签子集相关联,即使用一个二元向量![]() ,其中当且仅当标签
,其中当且仅当标签 在
在 的标签集中,则
的标签集中,则![]() 。我们使用
。我们使用![]() 来表示实例集V的可能标记。
来表示实例集V的可能标记。![]() 表示分配给Vl的观察到的多标签集,
表示分配给Vl的观察到的多标签集,![]() 表示要确定的多标签集。以活动边为中心的多重图多标签分类的任务是利用
表示要确定的多标签集。以活动边为中心的多重图多标签分类的任务是利用![]() 中训练实例的标签信息来预测
中训练实例的标签信息来预测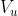 中测试实例的标签集
中测试实例的标签集![]() 。
。
3 AEClass方法
与第1节中概述的现有多标签关系分类器相比,AEClass通过结合四种挖掘策略来提高多标签分类的准确性和效率:(1)基于活动的边缘分类;(2)边缘标签依赖性;(3)顶点标签邻近性;(4)权重学习。首先介绍了AEClass的总体设计。接下来的小节将详细描述AecClass的每个部分。
- 基于活动的边缘分类,包括五项任务。(1) 给定一个协作图CG,根据分类目标定义的特定上下文选择N个合适的活动图
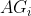 ;(2)将所有聚类成K个活动类别;(3)基于每个的聚类构造一个标签依赖图,识别K个类别标签之间的相互依赖关系;(4)基于K个类别对于每个,将CG中的每一条未标记边拆分并分类为最多K条标记边;(5)根据每个的
;(2)将所有聚类成K个活动类别;(3)基于每个的聚类构造一个标签依赖图,识别K个类别标签之间的相互依赖关系;(4)基于K个类别对于每个,将CG中的每一条未标记边拆分并分类为最多K条标记边;(5)根据每个的 加权,将CG和所有合并为一个统一的多重图MG
加权,将CG和所有合并为一个统一的多重图MG - 活动以边为中心的顶点分类,包括四个任务。(1) 初始化MG的转移概率
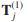 ;(2)初始化分类核
;(2)初始化分类核 ;(3)推断每个类cj上的类隶属度向量
;(3)推断每个类cj上的类隶属度向量 ;(4)用标签依赖图细化,生成类隶属度向量
;(4)用标签依赖图细化,生成类隶属度向量 。
。 - 迭代学习,包括四个步骤。(1) 解决分类目标的参数规划问题,更新
 ;(2)用
;(2)用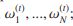 调整CG的结构亲和性
调整CG的结构亲和性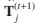 ;(3) 通过组合结构亲和力
;(3) 通过组合结构亲和力 和标签邻域
和标签邻域 ,用
,用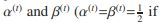
 加权,更新
加权,更新 ;(4)进行分类
;(4)进行分类 并进入下一轮。
并进入下一轮。
3.1基于活动的边缘分类
现有的分类模型假设顶点同态的存在,即自然界中相似的顶点通过社会联系相互连接。例如,Philip S.Yu和Wei Fan有许多在DM会议上发表的合著作品,如图4(a)所示。然而,事实并非总是这样。对于给定的K类标签集,连接在一起的实体可以以不同的方式相似。众所周知,PhilipS.Yu和MingSyanChen是数据挖掘专家,即他们在数据挖掘领域的研究出版物都比数据库等任何其他学术领域都多。然而,如图4(a)所示,他们在DB会议上发表了更多的合著论文。因此,顶点同向性不足以准确推断作者的可能标签。这促使我们提出顶点-边同态的概念,即链接及其相关顶点应相似且可能属于同一类的原则,以进一步提高多标签分类的准确性。



为了捕获多标签分类中的顶点-边缘同质性,首先进行基于活动的边缘检测分类。用于每个活动图和原始协作图CG,首先,通过对CG中的每一个边和一对连通实体的检查,构造了一个活动边缘增强协作图![]() ,并根据这对实体共同存在的
,并根据这对实体共同存在的![]() 活动将每一条边分割成一组平行边。每组平行边的大小最多为
活动将每一条边分割成一组平行边。每组平行边的大小最多为![]() ,即
,即![]() 中活动顶点的数量。图3(a)和(b)分别基于图1(b)中的会议活动和图(c)中的学期活动呈现了图1(a)中的活动边缘增强协作图。图1(a)中的每一条边根据共同会议地点或两位共同作者之间合著出版物中的共同标题术语分为多条边。
中活动顶点的数量。图3(a)和(b)分别基于图1(b)中的会议活动和图(c)中的学期活动呈现了图1(a)中的活动边缘增强协作图。图1(a)中的每一条边根据共同会议地点或两位共同作者之间合著出版物中的共同标题术语分为多条边。
然而,这种基于活动的边缘增强可能导致活动边缘增强协作图的大小的显著增加。我们通过引入基于活动的边缘增强和边缘分类来解决这个问题,以有效地提高分类的可扩展性。具体地说,我们利用NetClus的聚类结果,即K个类别上每个活动的概率分布,来推断K个类别上每个![]() 中平行边的类标签。
中平行边的类标签。
给定NetClus产生的属于簇(类)的![]() 中第m个活动的概率,用
中第m个活动的概率,用![]() 表示,我们可以根据
表示,我们可以根据![]() 表示的
表示的![]() 来计算属于类的边
来计算属于类的边![]() 的类隶属概率。
的类隶属概率。
![]()
其中W(p,q)表示CG中边![]() 上的值,
上的值,![]() 表示
表示![]() 中
中![]() 和
和![]() 之间第m条边上的值,该值基于
之间第m条边上的值,该值基于![]() 中的第m条活动。如果在
中的第m条活动。如果在![]() 和
和![]() 之间不存在这样的边,那么
之间不存在这样的边,那么![]() 等于0。
等于0。
在生成![]() 中每一条边的类隶属度分布后,通过将
中每一条边的类隶属度分布后,通过将![]() 中任意一对顶点之间的至多
中任意一对顶点之间的至多![]() 条平行边分组为
条平行边分组为![]() 中至多K条平行边,将
中至多K条平行边,将![]() 简化为一个具有分类边的活动边增广协作图
简化为一个具有分类边的活动边增广协作图![]()
![]()
其中,![]() 表示
表示![]() 中
中![]() 和
和![]() 之间带有标签的边上的值。为了便于展示,假设SIGMOD、VLDB、ICDE、database、query和relational只属于概率为1的DB类,KDD、ICDM、SDM、mining、clustering和frequent只属于概率为1的DM类,图4中两个
之间带有标签的边上的值。为了便于展示,假设SIGMOD、VLDB、ICDE、database、query和relational只属于概率为1的DB类,KDD、ICDM、SDM、mining、clustering和frequent只属于概率为1的DM类,图4中两个![]() 分别给出了图3中两个
分别给出了图3中两个![]() 的边缘分类结果。
的边缘分类结果。
3.2活动边中心顶点分类
由于CG(1≤i≤N)的N个边分类方案比如![]() ,对顶点分类的贡献程度不同,本文提出通过动态权值调整机制,将N个边分类方案集成到一个具有不同权因子
,对顶点分类的贡献程度不同,本文提出通过动态权值调整机制,将N个边分类方案集成到一个具有不同权因子![]()
![]() 的统一协作多重图中。因此,在第t次迭代时,
的统一协作多重图中。因此,在第t次迭代时,![]() 和
和![]() 之间带有标签的边上的统一权重值(单位:MG),用
之间带有标签的边上的统一权重值(单位:MG),用![]() 表示,可以如下计算。
表示,可以如下计算。

通过动态权值学习,![]() 随
随![]() 不断变化。我们设定初始
不断变化。我们设定初始![]() 加权因子为
加权因子为 。
。
图5(a)显示了我们在图1中运行的示例的统一多重图,它将图4中两个基于活动的边缘分类方案的相同顶点对之间具有相同标签的链接组合在一起,权重因子为0.5。
在统一多重图MG中,我们描述了以活动边为中心的顶点分类,它通过协作多重图上的转移概率将活动边标签与结构相关实例之间的顶点标签相结合。
定义1。[协作多重图上的转移概率]设MG=(V,E)是一个协作多重图,其中V是实体顶点集,E是表示MG的实体之间不同类上的协作关系的平行边集。在第t次迭代时MG上的转移概率可以通过如下标准化边缘值来定义。
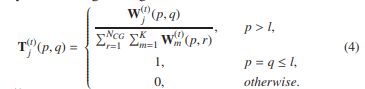
式中,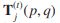 表示带标签的边上
表示带标签的边上![]() 和
和![]() 之间的转移概率,单位为MG。这里,我们假设
之间的转移概率,单位为MG。这里,我们假设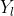 ,即
,即![]() 中顶点的标签,在分类过程中是固定的。图5(b)基于图5(a)中的协作多重图,给出了从Philip S.Yu到其他作者的平行边的转移概率。
中顶点的标签,在分类过程中是固定的。图5(b)基于图5(a)中的协作多重图,给出了从Philip S.Yu到其他作者的平行边的转移概率。
我们用矩阵形式表示上述转移概率。

其中,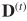 是对角线矩阵
是对角线矩阵![]() ,1,,1指定了l个1,并且
,1,,1指定了l个1,并且![]()
![]()
![]() 。
。![]() 确定在MG中类别标签为的那些边上的转移概率。
确定在MG中类别标签为的那些边上的转移概率。
我们不是将多标签分类问题分解成一组二进制分类问题,而是通过使用单个归一化因子![]() 来归一化具有不同类别标签的平行边,从而构建统一的多标签分类器。原过渡操作实际上分为两步:(1)根据分类目标选择那些带有目标类标签的边;以及(2)从上述边中选择具有最大值的边来跳转。
来归一化具有不同类别标签的平行边,从而构建统一的多标签分类器。原过渡操作实际上分为两步:(1)根据分类目标选择那些带有目标类标签的边;以及(2)从上述边中选择具有最大值的边来跳转。
现在我们定义了初始统一分类核![]() ,由于初始化时缺少标签邻域,只利用了MG的结构信息,即那些带有标签的边。
,由于初始化时缺少标签邻域,只利用了MG的结构信息,即那些带有标签的边。
![]()
由于我们已经对V中的顶点进行了排序,使得标记节点![]() 在未标记节点之前被索引,所以我们将统一分类核
在未标记节点之前被索引,所以我们将统一分类核![]() 重写为块矩阵。
重写为块矩阵。
其中![]() 是表示标记顶点之间转移概率的l×l单位矩阵,我们将
是表示标记顶点之间转移概率的l×l单位矩阵,我们将![]() 块矩阵
块矩阵 设置为零矩阵,因为
设置为零矩阵,因为![]() 中顶点上的标记是固定的,
中顶点上的标记是固定的,![]() 矩阵
矩阵![]() 指定了从未标记顶点到标记顶点的转移概率,
指定了从未标记顶点到标记顶点的转移概率,![]() 是
是![]() 矩阵,表示未标记顶点之间的转移概率。
矩阵,表示未标记顶点之间的转移概率。
假设类的隶属度矩阵由X=![]() 表示,对于基于类的每个类的隶属度向量
表示,对于基于类的每个类的隶属度向量 (1≤j≤K),我们使用其单独的分类核
(1≤j≤K),我们使用其单独的分类核![]() 迭代地推断类上顶点的概率
迭代地推断类上顶点的概率
.
设![]() 为类成员向量,其中
为类成员向量,其中![]() 表示
表示![]() 中属于类的标记顶点的概率,
中属于类的标记顶点的概率,![]() 表示中属于类的未标记顶点的概率。由于
表示中属于类的未标记顶点的概率。由于![]() 中顶点上的标签是固定的,等式(8)等价于以下公式。
中顶点上的标签是固定的,等式(8)等价于以下公式。
![]()
在第t次迭代之后,类成员矩阵更新如下。
![]()
与现有的多标签关系分类器相比,基于活动边增强协作多图的AEClass能够显著提高多标签分类的性能:(1)提高分类精度。基于顶点边的同态性,我们将CG中的每一条边划分为MG中最多K条平行边。在分类过程中,AEClass仅拾取与当前目标类具有相同标签的顶点和链接,即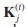 和
和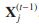 ,以执行推理。例如,给定Ming Syan Chen在图5(a)中DB类和DM类上的类成员概率,我们要推断Kun Lung Wu在DB类和DM类上的类成员概率。AEClass将在DB上产生正概率,在DM上产生零概率,因为这两个作者之间不存在带标签DM的边。相比之下,对于图1(a)中原始CG中两个作者之间的任何正边缘值,现有分类器在DM上输出的概率要比在DB上输出的概率高。事实上,Kun Lung Wu是一个没有任何数据挖掘出版物的数据库研究员。(2) 提高效率。基于顶点同态性,无论当前目标是哪一类,现有分类器都需要对每个顶点的邻域进行检查,并对所有邻域的标签进行汇总。相比之下,AEClass以更低的成本执行类似的摘要。当我们将CG中的一条边划分为m条MG中的平行边时,m通常比K类标签的数目小得多。假设当前目标类是,对于一个顶点的邻域,在该顶点和该邻域之间可能不存在带标签的边。因此,具有边标签的顶点的邻域的数目可以远小于其邻域的数目,从而减少不必要的计算量。具体地说,通过利用顶点-边同亲性,AEClass只需要考虑那些带有标签的链接和相关的邻居,并在下一次迭代中进一步阻止标签传播到那些不相关的邻居(没有带有标签的链接)的圆。对于上面的例子,我们可以安全地忽略推断DM上Kun Lung Wu概率的操作,因为两个作者之间不存在带标签DM的边。更重要的是,AEClass防止了Ming-Syan-Chen对DM的概率扩散到Kun Lung Wu和Kun Lung Wu的邻居圈。
,以执行推理。例如,给定Ming Syan Chen在图5(a)中DB类和DM类上的类成员概率,我们要推断Kun Lung Wu在DB类和DM类上的类成员概率。AEClass将在DB上产生正概率,在DM上产生零概率,因为这两个作者之间不存在带标签DM的边。相比之下,对于图1(a)中原始CG中两个作者之间的任何正边缘值,现有分类器在DM上输出的概率要比在DB上输出的概率高。事实上,Kun Lung Wu是一个没有任何数据挖掘出版物的数据库研究员。(2) 提高效率。基于顶点同态性,无论当前目标是哪一类,现有分类器都需要对每个顶点的邻域进行检查,并对所有邻域的标签进行汇总。相比之下,AEClass以更低的成本执行类似的摘要。当我们将CG中的一条边划分为m条MG中的平行边时,m通常比K类标签的数目小得多。假设当前目标类是,对于一个顶点的邻域,在该顶点和该邻域之间可能不存在带标签的边。因此,具有边标签的顶点的邻域的数目可以远小于其邻域的数目,从而减少不必要的计算量。具体地说,通过利用顶点-边同亲性,AEClass只需要考虑那些带有标签的链接和相关的邻居,并在下一次迭代中进一步阻止标签传播到那些不相关的邻居(没有带有标签的链接)的圆。对于上面的例子,我们可以安全地忽略推断DM上Kun Lung Wu概率的操作,因为两个作者之间不存在带标签DM的边。更重要的是,AEClass防止了Ming-Syan-Chen对DM的概率扩散到Kun Lung Wu和Kun Lung Wu的邻居圈。
3.3边缘标签依赖性改进
我们认为,不同活动类别之间的潜在相关性会对多标签分类的性能产生显著影响。在活动图划分的基础上,我们首先定义了边标签相似度,以获取N个活动图中K个活动类别之间的相互依赖关系。
定义2。[边标签相似度]设![]() 为第i个活动图(1≤i≤N),
为第i个活动图(1≤i≤N),![]() 为
为![]() 中两个活动
中两个活动![]() 的相似度得分,
的相似度得分,![]() 和
和![]() 分别为类标签为,
分别为类标签为,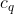 ∈C的两类
∈C的两类![]() 。和之间关于
。和之间关于![]() 的活动类别相似性也被称为两个边缘标签和之间的边缘标签依赖性,并且定义如下
的活动类别相似性也被称为两个边缘标签和之间的边缘标签依赖性,并且定义如下

图6显示了基于两个类标签DB和DM的活动类别相似性的两个边标签依赖图,分别与图2中的会议图和术语图相关。
因此,我们将它们合并到AEClass框架中,以调整类成员资格矩阵 。用
。用![]() 表示的类上的调整后的类隶属度向量,可以根据类与其他类之间的相似度得分,通过对其他类上的类隶属度向量进行积分来定义。
表示的类上的调整后的类隶属度向量,可以根据类与其他类之间的相似度得分,通过对其他类上的类隶属度向量进行积分来定义。
![]()
其中![]() 的权重
的权重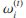 与式(3)中的相同。调整后的类成员矩阵定义如下
与式(3)中的相同。调整后的类成员矩阵定义如下
![]()
3.4顶点标签邻近细化
传统迭代分类器的一个缺点是需要大量的迭代才能收敛到一个平稳分布,而重复的标签传播会导致大量的计算开销。Wang等人[22]提出了一种融合数据特征和数据标签的动态标签传播(DLP)模型,以提高多类/多标签分类的有效性。然而,DLP模型未能量化数据特征和数据标签的加权贡献,因此它通常不能很好地用于实际的分类任务。在基于活动的协作多重图上,我们采用相似的思想,在标记的基础上建立标签邻域模型,以获取成对的顶点贴近度。为了提高分类的有效性和效率,我们设计了一种迭代学习方法,通过不断地量化和调整结构亲和力和标签邻域对分类目标的权重,动态地细化分类结果。
基于CG上的转移概率![]() ,定义了一个将多图空间映射为
,定义了一个将多图空间映射为![]() 维空间
维空间![]() 的扩散过程,其中每个元素
的扩散过程,其中每个元素![]() 表示标签从顶点到其他顶点的过渡概率
表示标签从顶点到其他顶点的过渡概率![]() 。另一方面,基于一个启发式规则:在输入多重图空间中,两个具有高度相似类隶属度分布的实例顶点很可能彼此高度相似,
。另一方面,基于一个启发式规则:在输入多重图空间中,两个具有高度相似类隶属度分布的实例顶点很可能彼此高度相似, 可以看作是基于类隶属度分布的顶点之间的相似性。类似地,我们将基于标签的相似空间映射到
可以看作是基于类隶属度分布的顶点之间的相似性。类似地,我们将基于标签的相似空间映射到![]() 维空间
维空间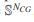 中,其中每个条目
中,其中每个条目![]() 指定顶点与其他顶点之间基于标签的相似性,以及
指定顶点与其他顶点之间基于标签的相似性,以及![]() 。然后定义了一个基于
。然后定义了一个基于![]() 的线性投影运算
的线性投影运算
![]()
式中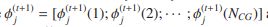 和
和![]()
![]() 。
。
利用线性投影,我们得到以下公式

相应的边际分布如下所示。
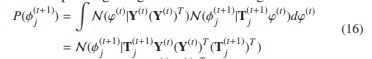
由于在统一分类核![]() 中直接组合
中直接组合![]() 可能导致分类开始时的退化,如果中顶点的学习标签信息不足以推断基于标签的相似性分数,我们通过
可能导致分类开始时的退化,如果中顶点的学习标签信息不足以推断基于标签的相似性分数,我们通过![]() 整合基于标签的相似性来调整
整合基于标签的相似性来调整![]() 。
。
![]()
服从![]()
![]() 和
和![]() 是衡量两类相似度的权重因子。标签附近
是衡量两类相似度的权重因子。标签附近![]() 基于当前标签定量测量顶点与其邻域之间的相似程度。
基于当前标签定量测量顶点与其邻域之间的相似程度。
3.5 权重学习
分类分析通常利用F1分数,即准确率和召回率的调和平均来评价测试实例的准确性。多重图的多标签分类的目的是最大化宏F1分数[32],即类上F1分数的未加权平均值。为了定义Macro-F1分数,我们首先引入一个指标函数
![]()
其中![]() 表示标签是否分配给实例顶点
表示标签是否分配给实例顶点
定义3。[Macro-F1]设MG=(V,E)为协作多重图, 为V中第i个实例顶点的真实标签向量,
为V中第i个实例顶点的真实标签向量,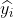 为预测标签向量,Macro-F1得分定义如下。
为预测标签向量,Macro-F1得分定义如下。

假设![]() ,我们定义一个s形函数来近似指示函数
,我们定义一个s形函数来近似指示函数

如果![]() ,即
,即![]() ,则确定
,则确定 的判定规则表示如下。
的判定规则表示如下。

因此,宏F1分数近似如下。

根据式(3)-(17),宏F1分数是多变量α,β,ω1,···,ωN的分数函数,具有非负实系数。另一方面,宏F1的分子和分母都是上述变量的多项式函数。在不丧失一般性的情况下,我们将公式(22)改写如下。

![]()
其中分子中有m个多项式项,分母中有n个多项式项, 和
和 分别是第i项的系数,
分别是第i项的系数, 、
、 、
、 、
、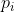 、
、 、
、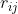 分别是第i项中相应变量的指数。
分别是第i项中相应变量的指数。
定义4。[多重图分类目标]设MG=(V,E)为协同多重图,α,β,ω1,···,ωN分别为式(3)和式(17)中定义的加权因子。多图的多标签分类的目标是最大化宏F1分数。
![]()
服从![]()
为了便于表述,我们将原目标修改为以下非线性分式规划问题(NFPP)。
定义5。[非线性分式规划问题]设 和
和![]()
 ,分类目标修订如下。
,分类目标修订如下。

服从![]()
我们的分类目标是使两个多元多项式函数的商最大化。为了确定解的存在性和唯一性,很难进行函数趋势的识别和估计。因此,我们希望将这个复杂的NFPP转换成一个容易解决的问题。
定理1。定义5中的NFPP等价于带多项式约束的多项式规划问题(PPC)

服从![]()
![]()
证据。如果![]() 是PPPPC的最优解,则
是PPPPC的最优解,则![]() 。所以
。所以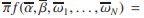
![]() 。对于NFPP任何可行的解决方案
。对于NFPP任何可行的解决方案![]()
,通过设置![]() 来满足PPPPC的约束。所以
来满足PPPPC的约束。所以![]()
 即
即![]()
![]()
相反,如果![]() 解决NFPP,然后为任何可行的PPPPC解决方案
解决NFPP,然后为任何可行的PPPPC解决方案![]() 我们有
我们有![]()


![]()
虽然ppc是一个多项式规划问题,但是多项式约束使得它很难求解。我们进一步将其简化为非线性参数规划问题(NPPP)。
定义6。[非线性参数规划问题]使![]() 和
和![]()

,NPPP定义如下
![]()
服从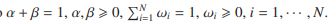
定理2。定义5中的NFPP等同于定义6中的NPPP,即。![]()
证据!如果![]() 是
是 的可行解,则
的可行解,则![]()
。所以![]()
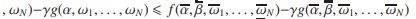
![]() .我们有
.我们有
![]() 。因此,γ是NFPP的最大值。
。因此,γ是NFPP的最大值。![]() 是NFPP的最优解。
是NFPP的最优解。
相反,如果 是NFPP的解,那么我们得到
是NFPP的解,那么我们得到
![]()
 。所以
。所以![]()
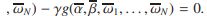 。我们F(γ)=0,最大值取在
。我们F(γ)=0,最大值取在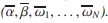
现在,原来的NFPP已经成功地转变为简单的NPPP。该变换具有以下特点,可以有效地加快分类收敛速度。
定理3 F(γ)是凸的。
定理4。F(γ)是单调递减的

定理5。F(γ)=0有唯一解。
证明:基于上述定理,我们知道F(γ)是连续的,也是递减的。另外,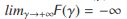 和
和![]() 。
。
求解这个NPPP的过程包括两个部分:(1)找到一个合理的参数γ(F(γ)=0),使NPPP等价于NFPP;(2)给定参数γ,求解一个关于原变量α,β,ω1。我们的权值调整机制是一个迭代过程,在分类过程的每次迭代之后,找F(γ)=0的解和相应的权值。我们首先生成一个初始统一分类核![]() ,其等权值为
,其等权值为![]() ,从而在协作多重图上产生一个初始分类结果。根据初始分类结果,计算初F(γ)。因F(γ)是单调递减函数并且
,从而在协作多重图上产生一个初始分类结果。根据初始分类结果,计算初F(γ)。因F(γ)是单调递减函数并且![]() 显然是非负的,我们从一个初始值γ=0开始,利用已有的快速多项式规划模型来更新权值α,β,ω1。,ωN。参数γ逐渐增大,
显然是非负的,我们从一个初始值γ=0开始,利用已有的快速多项式规划模型来更新权值α,β,ω1。,ωN。参数γ逐渐增大,![]() 帮助算法进入下一轮。算法重复上述迭代过程,直到F(γ)收敛到0。
帮助算法进入下一轮。算法重复上述迭代过程,直到F(γ)收敛到0。
通过将不同的片段组合在一起,我们在算法1中提供了AEClass分类器的伪代码。

4实验评价
我们已经进行了大量的实验来评估我们的AecClass分类器在真实图形数据集上的性能。
4.1实验数据集
第一个真实世界的数据集是从DBLP书目数据1中提取的。我们构建了一个由来自所有研究领域的高产量的100000名作者和712834个相关链接组成的合著者图,其中顶点表示作者,边表示他们的合著者关系,以及两个相关的活动图:会议图和术语图。根据[31],我们将研究领域分为24个领域:AI、AIGO、ARC、BIO、CV、DB、DIST、DM、EDU、GRP、HCI、IR、ML、MUL、NLP、NW、OS、PL、RT、SC、SE、SEC、SIM、WWW。我们利用多类型软聚类框架NetClus[25],将会议和术语同时分为24类。根据会议或术语在24个类别中的聚类分布和在每个类别中的排名得分,计算会议或术语之间的相似度。分类的目的是推断每个作者的研究领域。
Last..fm2是一个以音乐为导向的在线社交网络。我们使用API调用用户.getfriends收集好友列表并构建一个包含50000个用户和496611个相关链接的友谊图,其中顶点表示用户,边表示他们的友谊。两个活动网络:艺术家图和轨迹图是通过调用API调用生成的艺术家.getSimilar以及track.get类似分别。通过调用API调用user.getTopArtists以及用户.getTopTracks,我们根据相同的艺术家或两个用户共享的相同轨迹对每个友谊边进行分类。分类任务是将每个用户分配到数据库中21种音乐类型的子集:声学、环境音乐、蓝调、古典音乐、乡村音乐、电子音乐、情感音乐、民间音乐、硬核音乐、嘻哈音乐、独立音乐、爵士乐、拉丁音乐、金属音乐、流行音乐、流行朋克音乐、朋克音乐、雷鬼音乐、rnb音乐、摇滚音乐、灵魂音乐。
第三个真实的数据集是从互联网电影数据库(IMDb)3中提取的。我们构建了一个包含10000个高产演员和270227个链接的协作图,其中顶点代表演员,边根据演员在同一部电影中的共同出现来指定他们的共同演员关系。我们构建了一个电影活动图,其中边表示电影之间的直接关系,即电影由同一导演导演。目标是将每个演员与22种电影类型的子集相关联:动作、冒险、动画、传记、喜剧、犯罪、纪录片、戏剧、家庭、幻想、黑色电影、历史、恐怖、音乐、音乐、神秘、浪漫、科幻、体育、惊悚、战争、西部。
4.2比较方法与评价
我们将AEClass与两个具有代表性的基于链接的分类算法LBC[1],wvRN[2]和两个最近开发的多标签分类器EdgeCluster[18],SCRN[20]进行了比较。这四种方法都是基于顶点同胚的假设,对一个加权图进行多标签分类。第5节详细介绍了四种方法。注意,LBC最初是一个多类分类器。为了比较各种算法,我们修改了LBC算法的最后一步,使用K类上的后验概率分布作为多标签分类结果。AEClass将多个信息网络集成到一个统一的多重图中,同时结合了顶点中心多标签分类和基于顶点-边同胚的以边为中心的多标签分类。它还通过动态权值调整机制将结构亲和力和标签邻域集成到一个统一的分类器中。
评价指标 我们用三个指标来评价不同方法产生的分类结果的质量。第一个度量是定义3中定义的宏F1。给出等式(18)中相同的定义,其他两个度量定义如下。

Micro-F1[32]表示精度和召回率的微平均值的调和平均值。价值越大,质量越好
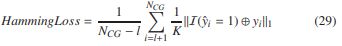
其中,⊕表示异或运算,![]() 指定l1-范数。汉明损失[33]衡量真实标签和预测标签之间的损失。值越小,质量越好。
指定l1-范数。汉明损失[33]衡量真实标签和预测标签之间的损失。值越小,质量越好。
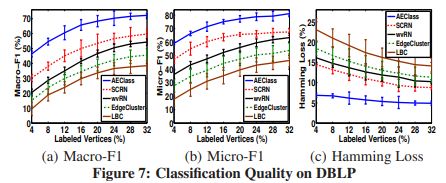
4.3分类质量
图7-9展示了DBLP的分类质量,Last.fm分别通过改变标记顶点的比例来实现IMDb。对于每个比例的标记顶点,我们平均性能分数超过10交叉验证。本文报道了五种多标签分类方法在宏观F1、微观F1和汉明损失三种评价指标下的平均性能得分及其标准差。我们用不同的方法对其性能作了如下观察。


首先,AEClass、SCRN和wvRN在所有三个评估指标上都显著优于LBC和EdgeCluster。我们首先根据五种多标签分类方法如何利用拓扑结构信息,将它们分为非归纳学习方法和归纳学习方法。LBC和EdgeCluster作为一种非递归学习方法,都只利用图中顶点之间的直接联系,即一跳结构信息来产生顶点的特征。AEClass、SCRN和wvRN作为一种跨导学习方法,通过迭代图传播,充分利用顶点间的直接联系和间接边(朋友圈),即多跳结构信息,进一步提高分类质量。这些结果证明了在网络数据中利用直接链接和间接边缘进行多标签分类的重要性。
第二,在三图数据集上,SCRN总是优于wvRN。尽管SCRN和wvRN利用了非常相似的关系推理框架,但是SCRN将网络拓扑结构和edecluster提取的社会上下文特征结合到分类器中,改进了wvRN。仔细的检验表明,尽管SCRN采用了优化方法,但这两种方法在许多情况下的预测性能都非常接近。合理的解释是,两者都是基于顶点同亲的假设,即自然界中相似顶点与社会联系的原理。
最后,在所有五种分类方法中,AEClass在所有三种真实数据集上的分类性能最好。与其他算法相比,AEClass算法在DBLP上平均宏F1增长14.6%,微F1增长12.1%,损失减少5.2%,宏F1增长10.2%,微F1增长9.9%,损失减少4.1%Last.fm宏F1增加16.7%,微F1增强16.2%,IMDb损耗降低7.5%。请注意,即使标记顶点的比例非常小(例如2%和4%),AEClass仍然可以在所有数据集上实现相当的精度。具体来说,AEClass分类精度高的原因有四个:(1)关联活动网络的结构信息提高了分类的有效性。活动网络划分为我们提供了额外的活动标签;(2)多图组织集成了基于顶点同态的以顶点为中心的多标签分类和基于顶点-边同态的以边为中心的多标签分类,以提高分类性能;(3) 活动网络划分捕获了多个类别标签之间的相互依赖关系;(4)迭代学习算法有助于分类器在不同的基于活动的边缘分类方案之间实现良好的平衡,有效地集成了结构亲和力和标签邻域。
4.5分类收敛
图11(a)和(b)展示了在4%标签节点的DBLP上分类收敛的趋势,包括f Macro-F1, Micro-F1和汉明损失Last..fm有5%的标签顶点。在分类过程中,我们迭代地进行顶点标注、权值更新和核调整等任务,两幅图中的宏F1值和微观F1值都在不断增加,并且都有凹曲线。另一方面,汉明损失值随分类迭代次数的增加而减小,并呈凸曲线。分类过程收敛得非常快,通常为8次迭代Last.fm DBLP有9次迭代。
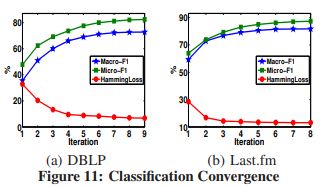

图12(a)和(b)显示了DBLP上的权重更新趋势,以及Last.fm分别。两个图中的α和β分别表示式(17)中统一分类器![]() j中结构亲和力和标签附近的权重。图12(a)中的ω1和ω2分别表示会议图和术语图的权重。图12(b)中的ω1和ω2分别表示艺术家图和轨迹图的权重。在分类过程中,我们保持约束条件α+β=1和ω1+ω2=1。我们观察到,随着聚类过程的收敛,所有权重都收敛。一个有趣的现象是α随迭代次数的增加先增加后减小,β曲线呈逆趋势。合理的解释是,在分类开始时缺乏足够的标记信息,使得统一分类器必须主要依靠结构亲和力来实现良好的分类性能。经过几次迭代,我们得到了足够的标签信息,可以利用结构亲和力和标签附近来对顶点进行分类。一个有趣的发现是,术语权重在增加,但会议权重随着迭代次数的增加而减小。一个合理的解释是,在同一次会议上有许多出版物的人可能有不同的研究主题,但是有许多论文的人,同一术语通常有相同的研究主题。例如,数据库论文和数据挖掘论文都发表在VLDB上。同样,轨迹权重增加,但艺术家的权重随着迭代次数的增加而减小。这是因为喜欢同一个艺术家的用户可能属于不同的音乐类型,因为艺术家通常与多种类型相关,但喜欢同一曲目的用户通常属于同一音乐类型。
j中结构亲和力和标签附近的权重。图12(a)中的ω1和ω2分别表示会议图和术语图的权重。图12(b)中的ω1和ω2分别表示艺术家图和轨迹图的权重。在分类过程中,我们保持约束条件α+β=1和ω1+ω2=1。我们观察到,随着聚类过程的收敛,所有权重都收敛。一个有趣的现象是α随迭代次数的增加先增加后减小,β曲线呈逆趋势。合理的解释是,在分类开始时缺乏足够的标记信息,使得统一分类器必须主要依靠结构亲和力来实现良好的分类性能。经过几次迭代,我们得到了足够的标签信息,可以利用结构亲和力和标签附近来对顶点进行分类。一个有趣的发现是,术语权重在增加,但会议权重随着迭代次数的增加而减小。一个合理的解释是,在同一次会议上有许多出版物的人可能有不同的研究主题,但是有许多论文的人,同一术语通常有相同的研究主题。例如,数据库论文和数据挖掘论文都发表在VLDB上。同样,轨迹权重增加,但艺术家的权重随着迭代次数的增加而减小。这是因为喜欢同一个艺术家的用户可能属于不同的音乐类型,因为艺术家通常与多种类型相关,但喜欢同一曲目的用户通常属于同一音乐类型。
4.6案例研究
基于合著图、会议图和术语图,研究了标记顶点比例为32%的dblp100000作者实验结果的一些细节。表1显示了基于24个会议类别和24个术语类别的作者集和他们在7次迭代后的类成员概率。我们只介绍了数据库(DB)、数据挖掘(DM)、机器学习(ML)和信息检索(IR)领域最丰富的DBLP专家。表1中的班级成员分数按每个作者的不同类别(会议或学期)标准化。我们观察到,作者的预测类成员资格与他们的实际研究领域是一致的。对于具有独特研究领域的专家,如Michael J.Carey和Michael Stonebraker,其预测结果中的主要研究领域与实际研究领域明显一致;对于已知在多个研究领域工作的研究人员,其预测的班级成员分布也与实际相一致当前的研究活动。例如,Jiawei Han和Philip S.Yu都是数据挖掘和数据库方面的专家,尽管他们的数据挖掘概率稍高,因为他们和他们的合著者圈子都有更多的数据挖掘论文。此表还显示每个作者在每个类别中都有一个班级成员分数。这表明我们的AecClass模型可以使每个作者快速到达每个类标签。
5相关工作
在过去的十年中,网络数据中的节点分类吸引了大量的研究[1–9]。LBC[1]是基于链路的分类器的纯网络派生,它通过聚集相邻节点的标签为节点创建一个特征向量,然后使用logistic回归建立基于这些特征向量的判别模型。wvRN[2]提出了一种加权投票关系邻域分类器来解决基于链接的分类问题。DYCOS[6]提出了一个同时包含文本内容和链接的动态信息网络节点分类模型。RankClass[7]在一个相互增强的过程中集成了分类和排序,为异构信息网络提供类摘要。
近年来,多标签分类越来越受到关注[10–16]。Read等人[12]通过修剪过程减少了复杂度和出错的可能性,以集中于多标签集中的核心关系。IBLR[13]提出了一种基于模型和相似性的推理与最优回归系数估计相结合的多标签分类方法。LEAD[15]将多标签学习任务分解为一组贝叶斯网络的单标签分类问题,对标签的条件依赖性和特征集进行编码。郭和顾[16]提出了一种基于二值分类器的广义条件依赖网络,并利用Gibbs抽样推理对模型进行了标签预测。
近年来,网络数据中的多标签分类得到了广泛的研究[17–22]。Sun等人[17]提出了一种用于多标签分类的超图谱学习公式,其中构造一个超图来利用不同标签之间的相关信息。EdgeCluster[18]提出了一种基于社会维度的集体行为预测方法,采用边缘聚类方案提取稀疏的社会维度,采用线性SVM分类器进行判别学习。SCRN[20]是一种综合考虑网络拓扑和社会上下文特征的多标签迭代关系邻居分类器。PIPL[21]通过从异构网络中挖掘标签关联和实例关联,促进了多标签学习过程。
最近关于异构社会网络分析的工作[7,9,23–30]将链接和内容结合到异构信息网络中,以提高查询、排序和聚类的质量。Cai等人[23]提出,根据不同关系在某个查询中的重要性,学习异构社会网络上不同关系的最佳线性组合。GenClus[28]提出了一种基于模型的异构网络聚类方法,该方法具有不同的链路类型和不同属性类型。Yu等人[29]提出了一个查询驱动的发现系统,用于在异构网络中发现语义相似的子结构。
据我们所知,这项工作是第一个利用多个活动图的先验知识,通过动态调整它们各自的贡献来解决异构多图的以活动边为中心的多标签分类问题。
6结论
提出了一种以边缘为中心的多标签分类方法来挖掘异构信息网络。首先,我们将主要的社会网络和多个相关的活动网络整合成一个统一的多图,并进行边缘分类。其次,我们将基于多活动网络的结构亲和力和标签邻域结合成一个统一的分类器。第三,提出了一种迭代学习算法,通过不断调整多个活动图中不同基于活动的边缘分类方案的权值,动态细化分类结果,同时不断学习统一分类器中结构亲和度和标签邻域的贡献。