如何实现高速卷积?深度学习库使用了这些「黑魔法」
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达来源:公众号 机器之心 授权转载
使用深度学习库可以大幅加速CNN模型运行,那么这些库中的哪些具体的做法实现了这种高速度和高性能呢?佐治亚理工学院计算机科学硕士研究生Manas Sahni在自己的电脑上试验了多种方法的策略,深入剖析高速卷积的实现过程。
我的笔记本电脑CPU还可以,在TensorFlow等库的加持下,这台计算机可以在 10-100 毫秒内运行大部分常见CNN模型。2019年,即使是智能手机也能在不到半秒内运行「重量级」CNN模型。而当我自己做了一个简单的卷积层实现,发现这一个层的运行时间竟然超过2秒时,我非常震惊。
大家都知道,现代深度学习库对大部分运算具备高度优化的生产级实现。但是这些库使用了哪些人类不具备的「黑魔法」呢?它们如何将性能提升100倍?当它们「优化」或加速神经网络运算时,它们在做什么?当谈及高性能/高效DNN时,我常常问(或被问及)这些问题。
本文尝试介绍在DNN库中如何实现一个卷积层。卷积不仅是很多DNN模型中最常见和最繁重的操作,它也是导致上述高性能实现的代表性trick:一点点算法智慧 + 大量调参 + 充分利用低级架构。
本文所涉及的很多内容来自这篇开创性论文《Anatomy of High-Performance Matrix Multiplication》,这篇论文形成了线性代数库(如OpenBLAS)所用算法的基础;本文还涵盖 Stefan Hadjis 博士和 Chris Rose的教程。
论文地址:https://www.cs.utexas.edu/~flame/pubs/GotoTOMS_revision.pdf
教程地址:https://cs.stanford.edu/people/shadjis/blas.html
朴素卷积(Naive Convolution)
不成熟的优化是万恶之源。——Donald Knuth
在探讨优化之前,我们先来了解一下基线和瓶颈。这里是一个朴素 numpy/for-loop 卷积:
'''Convolve `input` with `kernel` to generate `output`
input.shape = [input_channels, input_height, input_width]
kernel.shape = [num_filters, input_channels, kernel_height, kernel_width]
output.shape = [num_filters, output_height, output_width]
'''
for filter in 0..num_filters
for channel in 0..input_channels
for out_h in 0..output_height
for out_w in 0..output_width
for k_h in 0..kernel_height *for* k_w *in* 0..kernel_width output[filter, channel, out_h, out_h] += kernel[filter, channel, k_h, k_w] * input[channel, out_h + k_h, out_w + k_w]这个卷积包含6个嵌套的for loop,这里不涉及步幅(stride)、扩张(dilation)等参数。假如这是MobileNet第一层的规模,我们在纯C中运行该层,花费的时间竟然高达22秒!在使用最强悍的编译器优化后(如-O3 或 -Ofast),该卷积层的运行时间降至2.2秒。但是就一个层而言,这个速度仍然太慢了。
那么如果我使用Caffe运行这个层呢?在同一台计算机上使用Caffe运行同一个层所花费的时间仅为18毫秒,实现了100倍的加速!整个网络运行时间才大约100毫秒。
那么「瓶颈」是什么?我们应该从哪儿开始优化呢?
最内的循环进行了两次浮点运算(乘和加)。对于实验所使用的卷积层规模,它执行了8516万次,即该卷积需要1.7亿次浮点运算(170MFLOPs)。我的电脑CPU的峰值性能是每秒800亿FLOPs,也就是说理论上它可以在0.002秒内完成运行。但是很明显我们做不到,同样很明显的是,电脑的原始处理能力是非常充足的。
理论峰值无法实现的原因在于,内存访问同样需要时间:无法快速获取数据则无法快速处理数据。上述高度嵌套的for-loop使得数据访问非常艰难,从而无法充分利用缓存。
贯穿本文的问题是:如何访问正在处理的数据,以及这与数据存储方式有何关联。
先决条件
FLOP/s
性能或者速度的度量指标是吞吐量(throughput),即每秒浮点运算数(FLoating Point Operations per Second,FLOP/s)。使用较多浮点运算的大型运算自然运行速度较慢,因此FLOP/s是对比性能的一种较为可行的指标。
我们还可以用它了解运行性能与CPU峰值性能的差距。我的计算机CPU具备以下属性:
2个物理内核;
每个内核的频率为2.5 GHz,即每秒运行2.5×10^9个CPU循环;
每个循环可处理32 FLOPs(使用AVX & FMA)。
因此,该CPU的峰值性能为:
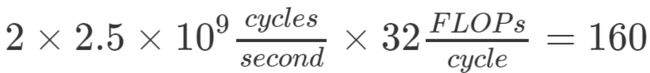
GFLOP/s。这就是我的CPU的理论峰值性能。类似地,我们可以得出单核CPU的峰值性能为80 GFLOP/s。
存储顺序和行优先
逻辑上我们将矩阵/图像/张量看作是多维度的,但实际上它们存储在线性、一维的计算机内存中。我们必须定义一个惯例,来规定如何将多个维度展开到线性一维存储空间中,反之亦然。
大部分现代深度学习库使用行主序作为存储顺序。这意味着同一行的连续元素被存储在相邻位置。对于多维度而言,行主序通常意味着:在线性扫描内存时第一个维度的变化速度最慢。
那么维度本身的存储顺序呢?通常4维张量(如CNN中的张量)的存储顺序是NCHW、NHWC等。本文假设CNN中的张量使用NCHW存储顺序,即如果HxW 图像的block为N,通道数为C,则具备相同N的所有图像是连续的,同一block内通道数C相同的所有像素是连续的,等等。
Halide语言
本文讨论的优化有时需要使用C语法甚至汇编语言这类底层的低级语言。这会影响代码的可读性,还会使尝试不同优化方法变得困难,因为它需要重写全部代码。Halide是一种嵌入到 C++ 中的语言,它可以帮助抽象概念,旨在帮助用户写出快速的图像处理代码。它可以分离算法(需要计算的东西)和调度策略(如何计算算法以及何时计算),因此使用Halide试验不同优化方法会更加简便。我们可以保持算法不变,试用不用的调度策略。
本文将使用Halide语言展示这些低级概念,但是你需要首先了解函数名称。
从卷积到矩阵相乘
上文讨论的朴素卷积已经够慢了,本节要介绍的实现则更加复杂,它包含步幅、扩张、填充(padding)等参数。我们将继续使用基础卷积作为运行示例,但是最大程度利用计算机的性能需要一些技巧——在多个层次上精心调参,以及充分利用所用计算机架构的具体知识。换言之,解决所有难题是一项艰巨任务。
那么我们可以将它转换成容易解决的问题吗?比如矩阵相乘。
矩阵相乘(又称matmul,或者Generalized Matrix Multiplication,GEMM)是深度学习的核心。全连接层、RNN等中都有它的身影,它还可用于实现卷积。
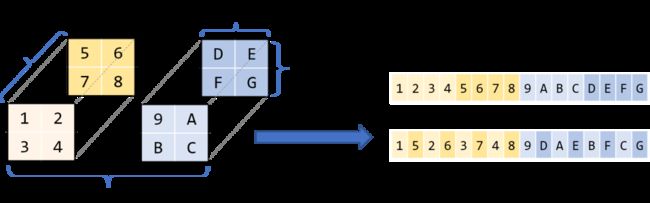
卷积是滤波器和输入图像块(patch)的点乘。如果我们将滤波器展开为2-D矩阵,将输入块展开为另一个2-D矩阵,则将两个矩阵相乘可以得到同样的数字。与CNN不同,近几十年来矩阵相乘已经得到广泛研究和优化,成为多个科学领域中的重要问题。将图像块展开为矩阵的过程叫做im2col(image to column)。我们将图像重新排列为矩阵的列,每个列对应一个输入块,卷积滤波器就应用于这些输入块上。
下图展示了一个正常的3x3卷积:
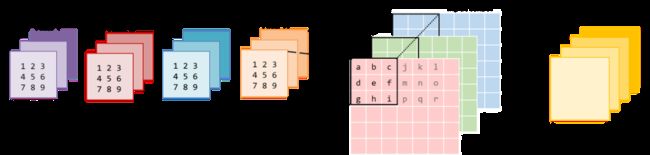
下图展示的是该卷积运算被实现为矩阵相乘的形式。右侧的矩阵是im2col的结果,它需要从原始图像中复制像素才能得以构建。左侧的矩阵是卷积的权重,它们已经以这种形式储存在内存中。
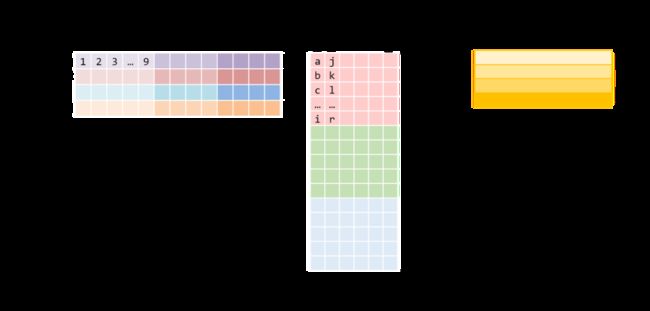
注意,矩阵乘积直接得出了卷积输出,无需额外「转换」至原始形式。
出于视觉简洁考虑,此处将每个图像块作为独立的个体进行展示。而在现实中,不同图像块之间通常会有重叠,因而im2col可能导致内存重叠。生成im2col 缓冲(im2col buffer)和过多内存(inflated memory)所花费的时间必须通过GEMM实现的加速来抵消。
使用im2col可以将卷积运算转换为矩阵相乘。现在我们可以使用更加通用和流行的线性代数库(如OpenBLAS、Eigen)对矩阵相乘执行高效计算,而这是基于几十年的优化和微调而实现的。
如果要抵消im2col变换带来的额外工作和内存,我们需要一些加速。接下来我们来看这些库是如何实现此类加速的。本文还介绍了在系统级别进行优化时的一些通用方法。
加速GEMM
朴素
本文剩余部分将假设GEMM按照该公式执行:
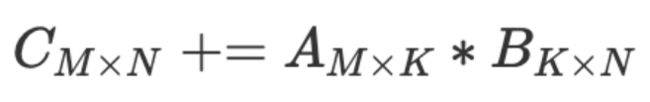
我们首先计算基础标准矩阵相乘的时间:
for i in 0..M:
for j in 0..N:
for k in 0..K:
C[i, j] += A[i, k] * B[k, j]使用Halide语言:
Halide::Buffer C, A, B;
Halide::Var x, y;
C(x,y) += A(k, x) *= B(y, k); // loop bounds, dims, etc. are taken care of automatically最内的代码行做了2次浮点运算(乘和加),代码执行了M∗N∗K次,因此该GEMM的FLOPs数为2MNK。
下图展示了不同矩阵大小对应的性能:
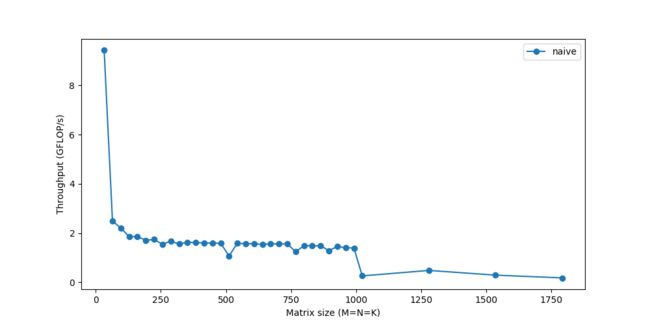
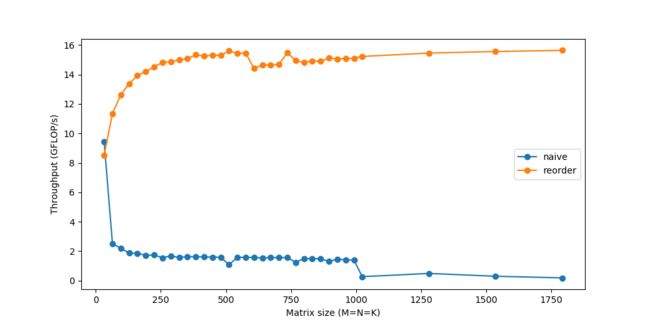
仅仅达到峰值性能的10%!接下来我们将探索加速计算的方式,但不变的主题仍然是:如果无法快速获取数据,则仅仅快速计算数据并不足够。随着矩阵规模越来越大,内存成为更加严重的问题,而性能也会继续逐渐下降。你看到图中的剧烈下跌了吗?这表示当矩阵太大无法适应缓存时,吞吐量突然下跌。
缓存
RAM是大的存储空间,但速度较慢。CPU缓存的速度要快得多,但其规模较小,因此恰当地使用CPU缓存至关重要。但是并不存在明确的指令:「将该数据加载到缓存」。该过程是由CPU自动管理的。
每一次从主内存中获取数据时,CPU会将该数据及其邻近的数据加载到缓存中,以便利用访问局部性(locality of reference)。

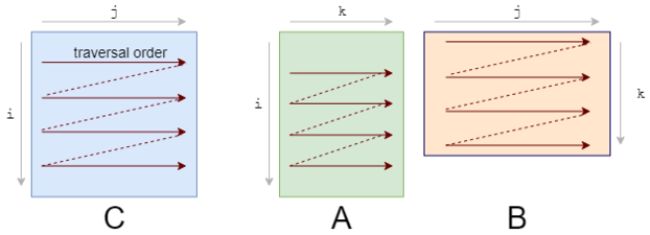
你应该首先注意到我们访问数据的模式。我们按照下图A的形式逐行遍历数据,按照下图B的形式逐列遍历数据。
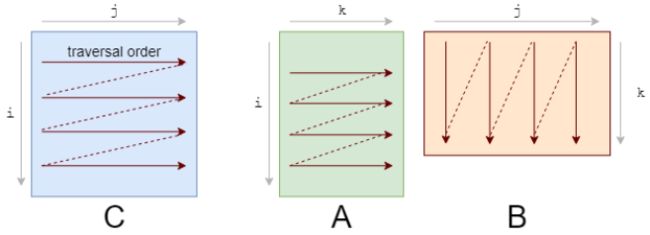
它们的存储也是行优先的,因此一旦我们找到 A[i, k],则它在该行中的下一个元素A[i, k+1]已经被缓存了。接下来我们来看B中发生了什么:
列的下一个元素并未出现在缓存中,即出现了缓存缺失(cache miss)。这时尽管获取到了数据,CPU也出现了一次停顿。
获取数据后,缓存同时也被 B 中同一行的其他元素填满。我们实际上并不会使用到它们,因此它们很快就会被删除。多次迭代后,当我们需要那些元素时,我们将再次获取它们。我们在用实际上不需要的值污染缓存。
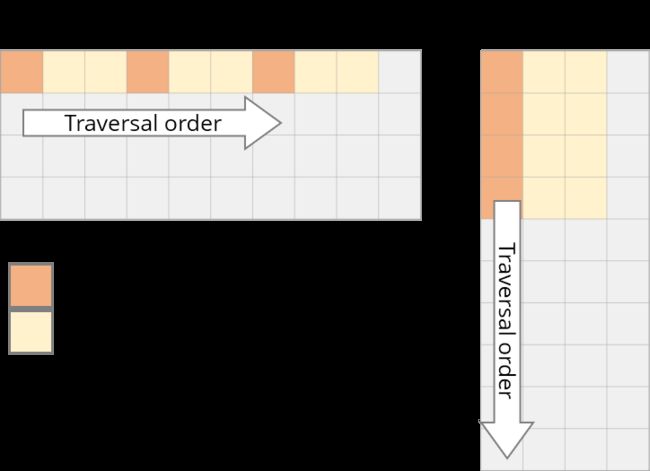
我们需要重新修改loop,以充分利用缓存能力。如果数据被读取,则我们要使用它。这就是我们所做的第一项改变:循环重排序(loop reordering)。
我们将i,j,k 循环重新排序为 i,k,j:
for i in 0..M:
for k in 0..K:
for j in 0..N:答案仍然是正确的,因为乘/加的顺序对结果没有影响。而遍历顺序则变成了如下状态:
循环重排序这一简单的变化,却带来了相当可观的加速:
平铺(Tiling)
要想进一步改进重排序,我们需要考虑另一个缓存问题。
对于A中的每一行,我们针对B中所有列进行循环。而对于 B 中的每一步,我们会在缓存中加载一些新的列,去除一些旧的列。当到达A的下一行时,我们仍旧重新从第一列开始循环。我们不断在缓存中添加和删除同样的数据,即缓存颠簸(cache thrashing)。
如果所有数据均适应缓存,则颠簸不会出现。如果我们处理的是小型矩阵,则它们会舒适地待在缓存里,不用经历重复的驱逐。庆幸的是,我们可以将矩阵相乘分解为子矩阵。要想计算 C 的r×c平铺,我们仅需要A的r行和B的c列。接下来,我们将 C 分解为6x16的平铺:
C(x, y) += A(k, y) * B(x, k);
C.update().tile(x, y, xo, yo, xi, yi, 6, 16)
/*in pseudocode:for xo in 0..N/16:
for yo in 0..M/6:
for yi in 6:
for xi in 0..16:
for k in 0..K:
C(...) = ...*/我们将x,y 维度分解为外侧的xo,yo和内侧的xi,yi。我们将为该6x16 block优化micro-kernel(即xi,yi),然后在所有block上运行micro-kernel(通过xo,yo进行迭代)。
向量化 & FMA
大部分现代CPU支持SIMD(Single Instruction Multiple Data,单指令流多数据流)。在同一个CPU循环中,SIMD可在多个值上同时执行相同的运算/指令(如加、乘等)。如果我们在4个数据点上同时运行SIMD指令,就会直接实现4倍的加速。
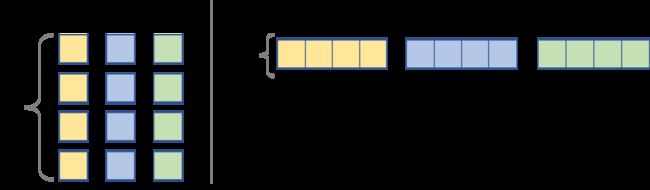
因此,当我们计算处理器的峰值速度时,我们其实有些作弊,把该向量化性能作为峰值性能。对于向量等数据而言,SIMD用处多多,在处理此类数据时,我们必须对每一个向量元素执行同样的指令。但是我们仍然需要设计计算核心,以充分利用它。
计算峰值FLOPs时,我们所使用的第二个技巧是FMA(Fused Multiply-Add)。尽管乘和加是两种独立的浮点运算,但它们非常常见,有些专用硬件单元可以将二者融合为一,作为单个指令来执行。编译器通常会管理FMA的使用。
在英特尔CPU上,我们可以使用SIMD(AVX & SSE)在单个指令中处理多达8个浮点数。编译器优化通常能够独自识别向量化的时机,但是我们需要掌控向量化以确保无误。
C.update().tile(x, y, xo, yo, xi, yi, 6, 16).reorder(xi, yi, k, xo, yo).vectorize(xi, 8)
/*in pseudocode:for xo in 0..N/16:
for yo in 0..M/6:
for k in 0..K:
for yi in 6:
for vectorized xi in 0..16:
C(...) = ...*/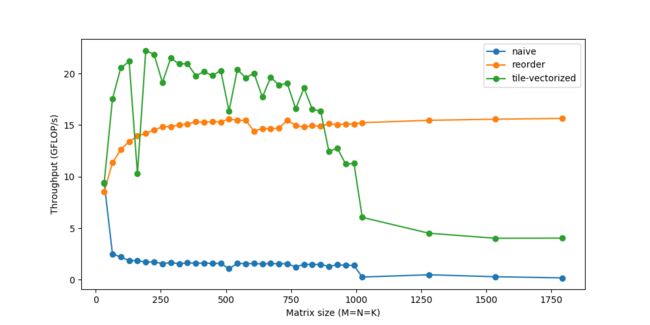
多线程处理(Threading)
到现在为止,我们仅使用了一个CPU内核。我们拥有多个内核,每个内核可同时执行多个指令。一个程序可被分割为多个线程,每个线程在单独的内核上运行。
C.update().tile(x, y, xo, yo, xi, yi, 6, 16).reorder(xi, yi, k, xo, yo).vectorize(xi, 8).parallel(yo)
/*in pseudocode:for xo in 0..N/16 in steps of 16:
for parallel yo in steps of 6:
for k in 0..K:
for yi in 6:
for vectorized xi in 0..16 in steps of 8:
C(...) = ...*/你可能注意到,对于非常小的规模而言,性能反而下降了。这是因为工作负载很小,线程花费较少的时间来处理工作负载,而花费较多的时间同步其他线程。多线程处理存在大量此类问题。
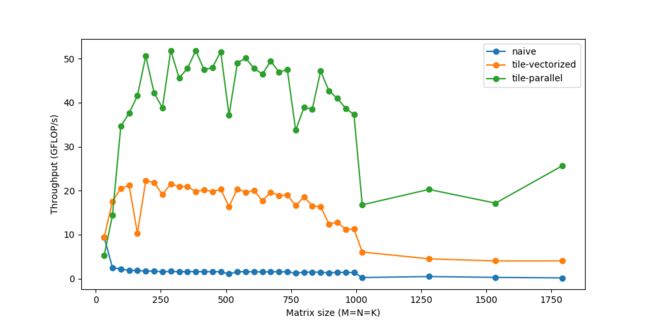
展开(Unrolling)
循环使我们避免重复写同样代码的痛苦,但同时它也引入了一些额外的工作,如检查循环终止、更新循环计数器、指针运算等。如果手动写出重复的循环语句并展开循环,我们就可以减少这一开销。例如,不对1个语句执行8次迭代,而是对4个语句执行2次迭代。
这种看似微不足道的开销实际上是很重要的,最初意识到这一点时我很惊讶。尽管这些循环操作可能「成本低廉」,但它们肯定不是免费的。每次迭代2-3个额外指令的成本会很快累积起来,因为此处的迭代次数是数百万。随着循环开销越来越小,这种优势也在不断减小。
展开是几乎完全被编译器负责的另一种优化方式,除了我们想要更多掌控的micro-kernel。
C.update().tile(x, y, xo, yo, xi, yi, 6, 16).reorder(xi, yi, k, xo, yo).vectorize(xi, 8).unroll(xi).unroll(yi)
/*in pseudocode:for xo in 0..N/16:
for parallel yo:
for k in 0..K:
C(xi:xi+8, yi+0)
C(xi:xi+8, yi+1)
...
C(xi:xi+8, yi+5)
C(xi+8:xi+16, yi+0)
C(xi+8:xi+16, yi+1)
...
C(xi+8:xi+16, yi+5)*/现在我们可以将速度提升到接近60 GFLOP/s。
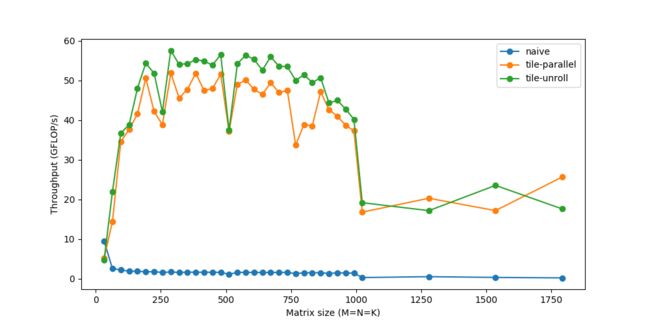
总结
上述步骤涵盖一些性能加速最常用的变换。它们通常以不同方式组合,从而得到更加复杂的调度策略来计算同样的任务。
下面就是用Halide语言写的一个调度策略:
matrix_mul(x, y) += A(k, y) * B(x, k);
out(x, y) = matrix_mul(x, y);
out.tile(x, y, xi, yi, 24, 32)
.fuse(x, y, xy).parallel(xy)
.split(yi, yi, yii, 4)
.vectorize(xi, 8)
.unroll(xi)
.unroll(yii);
matrix_mul.compute_at(out, yi)
.vectorize(x, 8).unroll(y);
matrix_mul.update(0)
.reorder(x, y, k)
.vectorize(x, 8)
.unroll(x)
.unroll(y)
.unroll(k, 2);它执行了:
将out分解为32x24的平铺,然后将每个平铺进一步分解为8x24的子平铺。
使用类似的重排序、向量化和展开,在临时缓冲区(matrix_mul)计算8x24 matmul。
使用向量化、展开等方法将临时缓冲区matrix_mul 复制回out。
在全部32x24平铺上并行化这一过程。
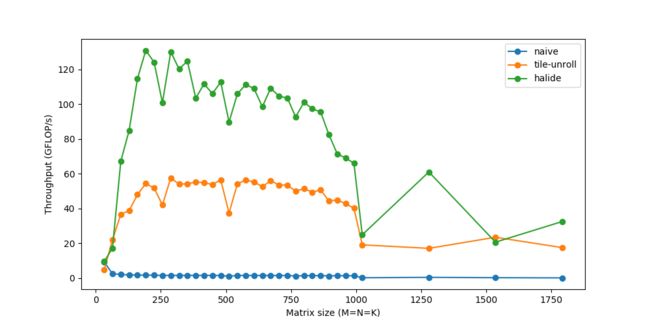
最后,我们将速度提升至超过120 GFLOPs,接近峰值性能160 GFLOPs,堪比OpenBLAS等生产级库。使用im2col类似的微调代码和矩阵相乘,同样的卷积可以在大约20毫秒内完成运行。如想深入了解,你可以尝试自行试验不同的调度策略。作为一名工程师,我经常听到关于缓存、性能等的语句,而亲眼看到它们的实际效果是非常有趣和值得的。
注意:im2col+gemm方法是大部分深度学习库中流行的通用方法。但是,对于特定的常用规模、不同的架构(GPU)和不同的运算参数(如扩张、分组等),专门化(specialization)是关键。这些库可能也有更专门化的实现,这些实现利用类似的trick或具体的假设。经过不断试错的高度迭代过程之后,我们构建了这些micro-kernel。对于什么方法效果好/不好、必须基于结果考虑注释,程序员通常只有直观的想法。听起来和深度学习研究差不多,不是吗?
原文链接:
https://sahnimanas.github.io/post/anatomy-of-a-high-performance-convolution/
好消息!
小白学视觉知识星球
开始面向外开放啦

下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~