主成分分析
主成分分析
-
- 1.摘要
- 2.数据降维
- 3.主成分分析
- 4.矩阵与向量相乘对向量的影响
- 5.最大方差理论
- 6.最小化降维损失
- 7.如何选择降维后的维度
- 8.scikit-learn PCA
1.摘要
本篇博客主要用于记录主成分分析的原理推导和用法,以加深理解和记忆。
2.数据降维
1)简介:机器学习领域中的数据降维是将高维空间中的数据点映射到某个低维空间中,是一种应用广泛的数据预处理方法
2)优点:使数据集更加易用;降低算法开销;去除噪声;使结果容易理解(低维可视化)
3)降维算法举例:主成分分析PCA;因子分析FA;独立成分分析ICA;等距映射;局部线性嵌入
3.主成分分析
主成分分析PCA(primary compoments analysis)是一种广泛使用的数据降维算法,其思想是在高维空间中寻找一个低维子空间,用高维空间中数据的低维映射作为降维后的数据表示。
在降维的过程中,我们希望降维后的数据具有更小的损失,也意味着保留尽可能多的信息(这是从数值大小上考量的)
沿着这两种等价的降维目标,主成分分析有两种理论推导方式:最大方差理论;最小化降维造成的损失。这两种思路都能推导出相同的结果,推导过程见5.6节。
4.矩阵与向量相乘对向量的影响
本节主要对更好的理解和推导主成分分析提供帮助
x = [ 1 2 3 ] = [ 1 0 0 0 1 0 0 0 1 ] [ 1 2 3 ] = 1 [ 1 0 0 ] + 2 [ 0 1 0 ] + 3 [ 0 0 1 ] x = \begin{bmatrix} 1 \\ 2 \\ 3 \end{bmatrix} = \begin{bmatrix} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{bmatrix} \begin{bmatrix} 1 \\ 2 \\ 3 \end{bmatrix} = 1 \begin{bmatrix} 1 \\ 0 \\ 0 \end{bmatrix} + 2 \begin{bmatrix} 0 \\ 1 \\ 0 \end{bmatrix} + 3 \begin{bmatrix} 0 \\ 0 \\ 1 \end{bmatrix} x=⎣ ⎡123⎦ ⎤=⎣ ⎡100010001⎦ ⎤⎣ ⎡123⎦ ⎤=1⎣ ⎡100⎦ ⎤+2⎣ ⎡010⎦ ⎤+3⎣ ⎡001⎦ ⎤
A x = [ A 1 , 1 A 1 , 2 A 1 , 3 A 2 , 1 A 2 , 2 A 2 , 3 A 3 , 1 A 3 , 2 A 3 , 3 ] [ 1 2 3 ] = 1 [ A 1 , 1 A 2 , 1 A 3 , 1 ] + 2 [ A 1 , 2 A 2 , 2 A 3 , 2 ] + 3 [ A 1 , 3 A 2 , 3 A 3 , 3 ] Ax = \begin{bmatrix} A_{1,1} & A_{1,2} & A_{1,3} \\ A_{2,1} & A_{2,2} & A_{2,3} \\ A_{3,1} & A_{3,2} & A_{3,3} \\ \end{bmatrix} \begin{bmatrix} 1 \\ 2 \\ 3 \end{bmatrix} = 1 \begin{bmatrix} A_{1,1} \\ A_{2,1} \\ A_{3,1} \end{bmatrix} + 2 \begin{bmatrix} A_{1,2} \\ A_{2,2} \\ A_{3,2} \end{bmatrix} + 3 \begin{bmatrix} A_{1,3} \\ A_{2,3} \\ A_{3,3} \end{bmatrix} Ax=⎣ ⎡A1,1A2,1A3,1A1,2A2,2A3,2A1,3A2,3A3,3⎦ ⎤⎣ ⎡123⎦ ⎤=1⎣ ⎡A1,1A2,1A3,1⎦ ⎤+2⎣ ⎡A1,2A2,2A3,2⎦ ⎤+3⎣ ⎡A1,3A2,3A3,3⎦ ⎤
矩阵乘以向量可以看作向量在从原始空间到矩阵列空间的一个映射,相当于将一个向量/坐标轴进行旋转、缩放、高低维度的映射
5.最大方差理论
1)思路
在信号处理中认为信号具有较大的方差,噪声具有较小的方差(信噪比是信号与噪声的方差比,越大越好)
沿着这种思路,我们通过旋转坐标轴,在高维空间中寻找一个低维子空间,使得原始数据在新空间相互正交的坐标轴(一组正交基)上的映射尽可能的分散(如下图,相比于紫色坐标轴上的映射,我们更倾向于绿色坐标轴上的映射)

原始数据在新空间坐标轴上的表示即是降维后的新数据表示
2)推导
设样本集合为: X = { x 1 , x 2 , . . . , x m } X = \{x_1,x_2,...,x_m\} X={x1,x2,...,xm}
设正交基集合为: U = { u 1 , u 2 , . . . , u k } U = \{u_1,u_2,...,u_k \} U={u1,u2,...,uk}
则某一样本点 x i x_i xi在某一基底 u j 上 u_j上 uj上的投影长度为: x i T u j x_i^{T}u_j xiTuj(两向量点积的几何意义)
所有样本点在某基底 u j u_j uj上的方差(目标函数):
a r g m a x D j = 1 m a r g m a x ∑ i = 1 m ( x i T u j − x c e n t e r T u j ) 2 在数据运算前对数据 X 进行中心化,即 x c e n t e r = 0 ∴ a r g m a x D j = 1 m a r g m a x ∑ i = 1 m ( x i T u j ) 2 = 1 m a r g m a x ∑ i = 1 m ( u j T x i x i T u j ) = 1 m a r g m a x u j T ∑ i = 1 m ( x i x i T ) u j ∴ a r g m a x D j = 1 m a r g m a x u j T ( X X T ) u j X X T 是实对称矩阵,必可相似对角化,通过特征分解,得 a r g m a x D j = 1 m a r g m a x Λ i argmax \ \ D_j =\frac 1margmax \sum_{i=1}^m(x_i^Tu_j -x_{center}^Tu_j)^2 \\ 在数据运算前对数据X进行中心化,即x_{center} = 0 \\ ∴ argmax \ \ D_j =\frac 1m argmax \sum_{i=1}^m(x_i^Tu_j )^2 \\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;=\frac 1m argmax \sum_{i=1}^m(u_j^Tx_ix_i^Tu_j ) \\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\; =\frac 1m argmax \ u_j^T \sum_{i=1}^m(x_ix_i^T ) u_j \\ ∴ argmax \ \ D_j \ \;=\frac 1m argmax \ u_j^T (XX^T ) u_j \\ XX^T是实对称矩阵,必可相似对角化,通过特征分解,得 \\ argmax\ D_j = \frac 1m \ argmax Λ_i argmax Dj=m1argmaxi=1∑m(xiTuj−xcenterTuj)2在数据运算前对数据X进行中心化,即xcenter=0∴argmax Dj=m1argmaxi=1∑m(xiTuj)2 =m1argmaxi=1∑m(ujTxixiTuj) =m1argmax ujTi=1∑m(xixiT)uj∴argmax Dj =m1argmax ujT(XXT)ujXXT是实对称矩阵,必可相似对角化,通过特征分解,得argmax Dj=m1 argmaxΛi
即,当基底 u j u_j uj为矩阵 X X T XX^T XXT最大特征值对应的特征向量时,目标函数 D j D_j Dj取最大值即为最大特征值。
求出 X X T XX^T XXT的特征值并按降序排列,其对应的特征向量组成的矩阵U即为编码矩阵(一组正交基),UX即为降维后数据的新表示。
3) X X T XX^T XXT的意义
在上面的推导中,X是样本每列中心化后的数据,即 X i = x i , j − x c e n t e r : j X_{i}=x_{i,j} - x_{center:j} Xi=xi,j−xcenter:j,那么 X X i , j T = ( x i : − x c e n t e r : j ) ( x : j − x c e n t e r : i ) XX^T_{i,j}=(x_{i:} - x_{center:j})(x_{:j} - x_{center:i}) XXi,jT=(xi:−xcenter:j)(x:j−xcenter:i),即 X X T XX^T XXT为样本集的协方差矩阵。
4)方法总结
通过以上推导,我们可以得出将原始数据进行主成分分析的一种方法。
- 对原始数据进行中心化,即每列各个元素减去该列全部元素的均值(这一步实际对矩阵进行了初等变换,可以看作每行元素分别减去各行的1/m)
- 对中心化后的数据 X X T XX^T XXT进行特征分解,将特征值降序排序,选择k维最大的特征值对应的特征向量作为新低维子空间中的正交基,组成编码矩阵E。
- 样本集X与编码矩阵E相乘得到降维后的数据表示
5)示例
- 原始数据: X = [ − 1 − 2 − 1 0 0 0 2 1 0 1 ] X=\begin{bmatrix} -1 & -2 \\ -1 & 0 \\ 0 & 0 \\ 2 & 1 \\ 0 & 1 \end{bmatrix} X=⎣ ⎡−1−1020−20011⎦ ⎤
- 中心化: X c e n t e r = [ − 1 − 2 − 1 0 0 0 2 1 0 1 ] X_{center} = \begin{bmatrix} -1 & -2 \\ -1 & 0 \\ 0 & 0 \\ 2 & 1 \\ 0 & 1 \end{bmatrix} Xcenter=⎣ ⎡−1−1020−20011⎦ ⎤
- 求协方差矩阵:
C o v = 1 5 X c e n t e r T X c e n t e r = 1 5 [ − 1 − 1 0 2 0 − 2 0 0 1 1 ] [ − 1 − 2 − 1 0 0 0 2 1 0 1 ] = [ 6 5 4 5 4 5 6 5 ] Cov = \frac 1 5 X_{center}^T X_{center} =\frac1 5 \begin{bmatrix} -1 & -1 & 0 & 2 & 0 \\ -2 & 0 & 0 & 1 & 1 \end{bmatrix} \begin{bmatrix} -1 & -2 \\ -1 & 0 \\ 0 & 0 \\ 2 & 1 \\ 0 & 1 \end{bmatrix}=\begin{bmatrix} \frac 6 5 & \frac 4 5 \\ \frac 4 5 & \frac 6 5 \end{bmatrix} Cov=51XcenterTXcenter=51[−1−2−10002101]⎣ ⎡−1−1020−20011⎦ ⎤=[56545456] - 求协方差矩阵的特征值及对应的特征向量,并将特征向量单位化
λ 1 = 2 , η 1 = [ 1 2 1 2 ] λ_1 = 2 ,η_1 =\begin{bmatrix} \frac {1} {\sqrt 2} \\ \frac {1} {\sqrt 2} \end{bmatrix} λ1=2,η1=[2121]
λ 2 = 2 5 , η 2 = [ − 1 2 1 2 ] λ_2 = \frac 2 5 ,η_2 =\begin{bmatrix} - \frac {1} {\sqrt 2} \\ \frac {1} {\sqrt 2} \end{bmatrix} λ2=52,η2=[−2121] - 将特征值降序排序,选择k(压缩到k维)个最大特征值对应的特征向量组成编码矩阵 E = [ η 1 , . . . , η k ] E=[η_1,...,η_k] E=[η1,...,ηk]
- 用原始矩阵与编码矩阵相乘得到映射后的新数据表示(这里取k=1)
X p c a = X E = [ − 1 − 2 − 1 0 0 0 2 1 0 1 ] [ 1 2 1 2 ] = [ − 3 2 − 1 2 0 3 2 1 2 ] X_{pca} =XE =\begin{bmatrix} -1 & -2 \\ -1 & 0 \\ 0 & 0 \\ 2 & 1 \\ 0 & 1 \end{bmatrix}\begin{bmatrix} \frac {1} {\sqrt 2} \\ \frac {1} {\sqrt 2} \end{bmatrix}=\begin{bmatrix} \frac {-3} {\sqrt 2} \\ \frac {-1} {\sqrt 2} \\ 0 \\ \frac {3} {\sqrt 2} \\ \frac {1} {\sqrt 2} \\\end{bmatrix} Xpca=XE=⎣ ⎡−1−1020−20011⎦ ⎤[2121]=⎣ ⎡2−32−102321⎦ ⎤
6)python代码实现
import numpy as np
def pca(_data, k):
"""
:description: 本方法提供从理论角度通过pca对数据进行降维,应注意数值问题
:author: LinCat
:param _data: 输入数据,矩阵
:param k: 目标降维数
:return: 降维后的数据,矩阵
"""
# 数组转矩阵
origin_matrix = np.mat(_data)
print('-' * 10, '原始矩阵', '-' * 10)
print(origin_matrix)
# 行列数
row_count = origin_matrix.shape[0]
column_count = origin_matrix.shape[1]
# 若所取维数不小于原矩阵维数,则直接返回
if k >= column_count:
return origin_matrix
# 中心化
center_matrix = origin_matrix
for i in range(column_count):
# 列向量
column_vector = center_matrix[:, i]
# 求列均值:注意这里直接仍以向量的形式求均值,后续计算时无需显式地迭代计算,使用矩阵计算方法
column_mean = column_vector.sum(0) / column_vector.shape[0]
# 该列每个元素减去对应列的列均值
center_matrix[:, i] = column_vector - column_mean
print('-' * 10, '中心化后的矩阵', '-' * 10)
print(center_matrix)
# 求转置矩阵
transpose_matrix = center_matrix.T
# 求协方差矩阵
cov_matrix = transpose_matrix * center_matrix / row_count
print('-' * 10, '协方差矩阵', '-' * 10)
print(cov_matrix)
# 求协方差矩阵的特征值与特征向量:注意特征值组成的矩阵中特征值按列向量组合
characteristic_value, characteristic_vector = np.linalg.eig(cov_matrix)
# 构造特征值与特征向量的字典数组,方便排序
value_vector_dict = []
for i in range(len(characteristic_value)):
value_vector_dict.append({'value': characteristic_value[i], 'vector': characteristic_vector.T[i]})
# 对数组字典根据特征值降序排序
value_vector_dict.sort(key=lambda x: x['value'], reverse=True)
print('-' * 10, '特征值与对应特征向量', '-' * 10)
for value_vector_item in value_vector_dict:
print(value_vector_item)
# 选择k维特征向量组成编码矩阵
encode_vector = None
for i in range(k):
encode_vector = value_vector_dict[i]['vector'] if encode_vector is None else np.vstack(
(encode_vector, value_vector_dict[i]['vector']))
print('-' * 10, '编码矩阵', '-' * 10)
print(encode_vector.T)
result_matrix = origin_matrix * encode_vector.T
print('-' * 10, '降维后的矩阵', '-' * 10)
print(result_matrix)
return result_matrix
if __name__ == '__main__':
# 初始数据集:5×2的矩阵,即5组2维数据
_data = [[-1, -2],
[-1, 0],
[0, 0],
[2, 1],
[0, 1]]
pca(_data, 1)
运行结果:

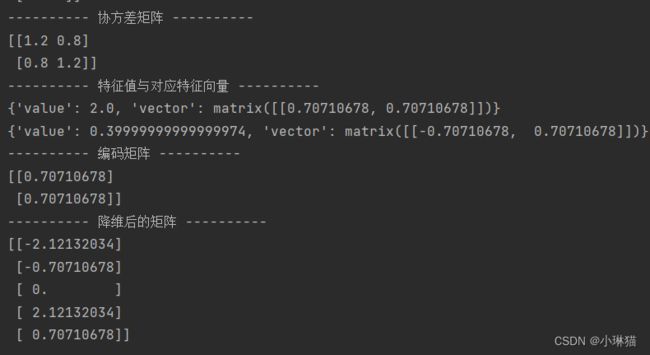
6.最小化降维损失
1)思路
将高维空间中的数据有损压缩到一个低维空间,再将其还原到原本的高维空间。我们希望原始数据和压缩还原后的数据(重构数据)之间的损失尽可能的小。
2)寻找编码器
通过编码矩阵E与m维列向量x相乘可以将原始向量从高维空间映射到n维低维空间: y = E n , m x m , 1 y=E_{n,m} \ x_{m,1} y=En,m xm,1
通过解码矩阵U与映射后的n维向量y相乘可以将映射后的向量还原到m维高维空间: x ′ = U m , n y n , 1 x'=U_{m,n} \ y_{n,1} x′=Um,n yn,1,这里限制解码矩阵U的各个列向量相互正交且都是单位向量。
沿着上面的思路,我们令原始输入向量和重构向量之间的距离(损失)最小:
E ∗ = a r g m i n E ∣ ∣ x − x ′ ∣ ∣ 2 2 平方 L 2 范数 E ∗ = a r g m i n E ( x − x ′ ) T ( x − x ′ ) 等价代换 E ∗ = a r g m i n E x T x − x T x ′ − x ′ T x + x ′ T x ′ 分配律 E ∗ = a r g m i n E x T x − 2 x T x ′ + x ′ T x ′ 标量的转置是自己 E ∗ = a r g m i n E − 2 x T x ′ + x ′ T x ′ 忽略无关项 E ∗ = a r g m i n E − 2 x T U y + ( U y ) T U y = − 2 x T U y + y T U T U y 代入 x ′ 意义 E ∗ = a r g m i n E − 2 x T U y + ( U y ) T U y = − 2 x T U y + y T y 解码矩阵约束 令 ▽ c ( − 2 x T U y + y T y ) = 0 向量微积分 得 − 2 U T x + 2 y = 0 得 y = U T x 所以 E = U T E^* = argmin_{E} \; || x- x' ||_2^2 \;\;\;\;\;\;\;\; 平方L2范数 \\ E^* = argmin_{E} \; (x-x')^T(x-x') \;\;\;等价代换 \\ E^*= argmin_E \; x^Tx - x^Tx' - x'^Tx + x'^Tx' \; 分配律 \\ E^* = argmin_{E} \; x^Tx - 2x^Tx' + x'^Tx' \;\; 标量的转置是自己 \\ E^* = argmin_{E} \; - 2x^Tx' + x'^Tx' \;\; 忽略无关项 \\ E^* = argmin_{E} \; - 2x^TUy + (Uy)^TUy = - 2x^TUy + y^TU^TUy \; 代入x'意义 \\ E^* = argmin_{E} \; - 2x^TUy + (Uy)^TUy = - 2x^TUy + y^Ty \; 解码矩阵约束 \\ 令 \;\; ▽_c( - 2x^TUy + y^Ty) =0 \;\;\; 向量微积分 \\ 得 \;\;\; -2U^Tx + 2y =0 \\ 得 \;\;\; y = U^Tx \\ 所以 \;\; E = U^T E∗=argminE∣∣x−x′∣∣22平方L2范数E∗=argminE(x−x′)T(x−x′)等价代换E∗=argminExTx−xTx′−x′Tx+x′Tx′分配律E∗=argminExTx−2xTx′+x′Tx′标量的转置是自己E∗=argminE−2xTx′+x′Tx′忽略无关项E∗=argminE−2xTUy+(Uy)TUy=−2xTUy+yTUTUy代入x′意义E∗=argminE−2xTUy+(Uy)TUy=−2xTUy+yTy解码矩阵约束令▽c(−2xTUy+yTy)=0向量微积分得−2UTx+2y=0得y=UTx所以E=UT
最终我们找到了编码器和解码器的关系,即编码器和解码器互为转置。
重构向量可以表示为: x ′ = U U T x x' = UU^Tx x′=UUTx
3)寻找解码器
编码器和解码器的关系已知,当我们找到解码器时,编码器也由此而生,寻找解码器时,我们需要考虑全部样本集合,不能再孤立地看待单个样本(向量),必须最小化所有维数和所有点上的误差矩阵的Frobenius范数。为了便于推导,我们约束解码器U为单一单位向量u。
u ∗ = a r g m i n u ∑ i ∣ ∣ x i − u u T x i ∣ ∣ 2 2 u ∗ = a r g m i n u ∑ i ∣ ∣ x i − x i T u u T ∣ ∣ 2 2 转置的 L 2 范数不变 u ∗ = a r g m i n u ∣ ∣ X T − X u u T ∣ ∣ F 2 向量堆叠成矩阵,注意 X i , : = x i T u ∗ = a r g m i n u T r ( ( X − X u u T ) T ( X − X u u T ) ) 等价代换 u ∗ = a r g m i n u T r ( X T X ) − T r ( X T X u u T ) − T r ( u u T X T X ) + T r ( u u T X T X u u T ) u ∗ = a r g m i n u − T r ( X T X u u T ) − T r ( u u T X T X ) + T r ( u u T X T X u u T ) 忽略无关项 u ∗ = a r g m i n u − 2 T r ( X T X u u T ) + T r ( X T X u u T u u T ) 循环转置 u ∗ = a r g m i n u − 2 T r ( X T X u u T ) + T r ( X T X u u T ) u 约束条件 u ∗ = a r g m i n u − T r ( X T X u u T ) 合并同类项 u ∗ = a r g m a x u T r ( X T X u u T ) 等价代换 u ∗ = a r g m a x u T r ( u T X T X u ) 循环转置 u^* = argmin_u \; \sum_i || x^i - uu^Tx^i ||_2^2 \\ u^* = argmin_u \; \sum_i ||{x^i} - {x^i}^Tuu^T ||_2^2 \;\; 转置的L2范数不变 \\ u^* = argmin_u \; ||X^T - Xuu^T ||_F^2 \;\; 向量堆叠成矩阵,注意X{i,:} ={x^i}^T\\ u^* = argmin_u \; Tr((X - Xuu^T)^T(X - Xuu^T)) \;\;等价代换 \\ u^* = argmin_u \; Tr(X^TX)-Tr(X^TXuu^T) - Tr(uu^TX^TX) + Tr(uu^TX^TXuu^T) \\ u^* = argmin_u \; -Tr(X^TXuu^T) - Tr(uu^TX^TX) + Tr(uu^TX^TXuu^T) \; 忽略无关项 \\ u^* = argmin_u \; -2Tr(X^TXuu^T) + Tr(X^TXuu^Tuu^T) \; 循环转置 \\ u^* = argmin_u \; -2Tr(X^TXuu^T) + Tr(X^TXuu^T) \; u约束条件 \\ u^* = argmin_u \; -Tr(X^TXuu^T) \; 合并同类项 \\ u^* = argmax_u \; Tr(X^TXuu^T) \; 等价代换 \\ u^* = argmax_u \; Tr(u^TX^TXu) \; 循环转置 \\ u∗=argminui∑∣∣xi−uuTxi∣∣22u∗=argminui∑∣∣xi−xiTuuT∣∣22转置的L2范数不变u∗=argminu∣∣XT−XuuT∣∣F2向量堆叠成矩阵,注意Xi,:=xiTu∗=argminuTr((X−XuuT)T(X−XuuT))等价代换u∗=argminuTr(XTX)−Tr(XTXuuT)−Tr(uuTXTX)+Tr(uuTXTXuuT)u∗=argminu−Tr(XTXuuT)−Tr(uuTXTX)+Tr(uuTXTXuuT)忽略无关项u∗=argminu−2Tr(XTXuuT)+Tr(XTXuuTuuT)循环转置u∗=argminu−2Tr(XTXuuT)+Tr(XTXuuT)u约束条件u∗=argminu−Tr(XTXuuT)合并同类项u∗=argmaxuTr(XTXuuT)等价代换u∗=argmaxuTr(uTXTXu)循环转置
最终化成了同最大方差理论推导一样的形式,通过对实对称矩阵 X T X X^TX XTX的特征值分解可得,当u取最大特征值对应的特征向量时,上述式子取最大,即最大特征值。当U不限定为一维向量时,令U取k个最大的特征向量对应的特征值即可。
7.如何选择降维后的维度
- 均方误差和 total squared projection error: 1 m ∑ i = 1 m ∣ ∣ x i − x ′ i ∣ ∣ 2 \frac 1 m \sum_{i=1}^m || x^i - x'^i ||^2 m1∑i=1m∣∣xi−x′i∣∣2 ,其中 x ′ i x'^i x′i为映射后的值
- 原数据总量 total variation in the data: 1 m ∑ i = 1 m ∣ ∣ x i ∣ ∣ 2 \frac 1m \sum_{i=1}^m || x^i ||^2 m1∑i=1m∣∣xi∣∣2
- 损失比: 均方误差和 原数据总量 \frac {均方误差和} {原数据总量} 原数据总量均方误差和
从k=1开始,到k=m为维度,分别计算损失比,直到损失比小于目标值退出循环,如设置损失比 ≤ 0.01,则意味着降维后的数据可以保留99%的数据成分
8.scikit-learn PCA
5中按照最大方差理论的方法通过numpy库手写了一遍PCA的实现代码,sklearn库通过SVD分解已经封装了现成的PCA方法,这里给出调用代码,仍使用5中的例子进行对比
# sklearn的PCA
from sklearn.decomposition import PCA
import numpy as np
# 输入数据
X = np.array([[-1, -2], [-1, 0], [0, 0], [2, 1], [0, 1]])
# 映射维度
pca = PCA(n_components=1)
pca.fit(X)
print(pca.transform(X))
运行结果:
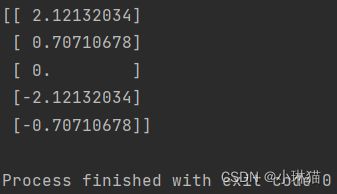
可以看出除了映射后坐标轴的顺序不同,计算的结果是一致的。