Machine Learning with Python Cookbook 学习笔记 第15章
Chapter 15. Dimensionality Reduction Using Feature Selection
前言
-
本笔记系列可能更新较慢,因为笔者大三了事情较多
-
学习的实战代码都放在代码压缩包中
-
实战代码的运行环境是python3.9 numpy 1.23.1 **anaconda 4.12.0 **
-
上一章:(97条消息) Machine Learning with Python Cookbook 学习笔记 第9章_五舍橘橘的博客-CSDN博客
-
代码仓库
- Github:yy6768/Machine-Learning-with-Python-Cookbook-notebook: 人工智能典型算法笔记 (github.com)
- Gitee:yyorange/机器学习笔记代码仓库 (gitee.com)
15.0 Introduction
- KNN是有监督学习中最简单的分类器之一
- KNN通常是认为为懒惰的学习者
- 观测者被预测为k个最近的观测值
15.1 Finding an Observation’s Nearest Neighbors
问题
寻找k个最近的样本
解决方案
scikit-learn NearestNeighbors
nearest_neighbor.py
# 加载库
from sklearn import datasets
from sklearn.neighbors import NearestNeighbors
from sklearn.preprocessing import StandardScaler
# 莺尾花数据集
iris = datasets.load_iris()
features = iris.data
# 标准化
standardizer = StandardScaler()
features_standardized = standardizer.fit_transform(features)
# 2个最近邻
nearest_neighbors = NearestNeighbors(n_neighbors=2).fit(features_standardized)
# 创建一个新的样本
new_observation = [ 1, 1, 1, 1]
# 最近的2个样本
distances, indices = nearest_neighbors.kneighbors([new_observation])
# View the nearest neighbors
print(features_standardized[indices])
Discussion
-
new_observation是我们创建出的模拟样本
-
indices表示距离new_observation最近的样本在数据集中的索引
-
如何计算距离:
-
欧拉距离:
d e u c i l d e a n = Σ i = 1 n ( x i − y i ) 2 d_{eucildean} = \sqrt{\Sigma_{i=1}^n(x_i-y_i)^2} deucildean=Σi=1n(xi−yi)2
-
曼哈顿距离:
d m a n h a t t a n = Σ i = 1 n ∣ x i − y i ∣ d_{manhattan} = \Sigma_{i =1} ^n |x_i-y_i| dmanhattan=Σi=1n∣xi−yi∣
-
(默认) Minkowski 距离
d M i n k o w s k i = ( Σ i = 1 n ∣ x i − y i ∣ p ) 1 p d_{Minkowski} = (\Sigma_{i=1}^n|x_i-y_i|^p)^{\frac 1 p} dMinkowski=(Σi=1n∣xi−yi∣p)p1
默认情况下p=2(曼哈顿距离)
-
-
指定距离
metric参数nearestneighbors_euclidean = NearestNeighbors( n_neighbors=2, metric='euclidean').fit(features_standardized) -
可以计算每个observation的最近邻
# 根据欧拉距离计算 nearestneighbors_euclidean = NearestNeighbors( n_neighbors=3, metric="euclidean").fit(features_standardized) # List of lists indicating each observation's 3 nearest neighbors # 包含它自身 nearest_neighbors_with_self = nearestneighbors_euclidean.kneighbors_graph( features_standardized).toarray() # 1就是最近邻 for i, x in enumerate(nearest_neighbors_with_self): x[i] = 0 # 第一个样本的最近邻 print(nearest_neighbors_with_self[0])
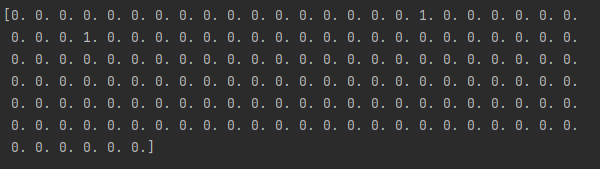
可以看到众多样本中有两个标为1的为最近邻
- 当我们使用距离进行模型训练时,最终要的一件事是对模型进行标准化(保证数据的规模一致),不然较大的数据会影响较大。
- 使用
StandardScaler
- 使用
15.2 Creating a K-Nearest Neighbor Classifier
Problem
- 给定未知类的观察结果,需要根据其邻居的类来预测其类。
Solution
KNeighborsClassifier
knn_classifier.py
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
from sklearn import datasets
# 数据
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 标准化
standardizer = StandardScaler()
# 标准化特征
X_std = standardizer.fit_transform(X)
# 以5为最近邻个数进行分类
knn = KNeighborsClassifier(n_neighbors=5, n_jobs=-1).fit(X_std, y)
# 创造两个模拟的数据
new_observations = [[0.75, 0.75, 0.75, 0.75],
[1, 1, 1, 1]]
# 预测
print(knn.predict(new_observations))
Discussion
-
预测一个样本,经历这几个步骤:
-
找到它的k近邻
-
根据最近邻进行投票
投票公式: 1 k Σ i ∈ v I ( y i = j ) \frac 1 k \Sigma_{i\in v} I(y_i = j) k1Σi∈vI(yi=j)
其中:k是k近邻参数,v是邻居的集合,I(boolean)是指示函数,参数为真则为1,为假伪0
-
我们可以通过
predict_proba查看投票情况
print(knn.predict_proba(new_observations))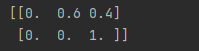
-
-
KNeighborsClassifier的重要参数- metric:距离计算方法
- n_jobs:CPU多少核心参与计算,-1表示全部
- algorithm:选择的邻居的算法,默认的情况会自动选择最好的算法,使用者一般不用担心底层实现
- weight:投票的权重,如果设置了权重,越近的点权重越大
- 其他参数类似14.1节所讲的参数,我的笔记详情看到:(146条消息) Machine Learning with Python Cookbook 学习笔记 第14章_五舍橘橘的博客-CSDN博客
15.3 Identifying the Best Neighborhood Size
Problem
怎么选取kNN的k值呢?
Solution
GridSearchCV
bestk.py
from sklearn.neighbors import KNeighborsClassifier
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline, FeatureUnion
from sklearn.model_selection import GridSearchCV
iris = datasets.load_iris()
features = iris.data
target = iris.target
# 标准化
standardizer = StandardScaler()
features_standardized = standardizer.fit_transform(features)
# 创建knn分类器
knn = KNeighborsClassifier(n_neighbors=5, n_jobs=-1)
# 创建一个pipe(管道)
pipe = Pipeline([("standardizer", standardizer), ("knn", knn)])
# 创建k值的参数空间
search_space = [{"knn__n_neighbors": [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]}]
# 进行grid搜索
classifier = GridSearchCV(
pipe, search_space, cv=5, verbose=0).fit(features_standardized, target)
Discussion
-
k值在KNN算法中是有真实含义的
-
在机器学习中,我们需要找到**bias(偏差)和variance(方差)**的平衡
- bias:模型误差
- variance:数据集误差
-
1->n , bias 上升, variance下降(很好理解,分类分的越多,类内的方差一定越小,但是分类容错减少,bias会增加)
-
GridSearchCV是一种5折交叉检验,检验完后,我们就能得到最好的k值和模型
from sklearn.neighbors import KNeighborsClassifier from sklearn import datasets from sklearn.preprocessing import StandardScaler from sklearn.pipeline import Pipeline, FeatureUnion from sklearn.model_selection import GridSearchCV iris = datasets.load_iris() features = iris.data target = iris.target # 标准化 standardizer = StandardScaler() features_standardized = standardizer.fit_transform(features) # 创建knn分类器 knn = KNeighborsClassifier(n_neighbors=5, n_jobs=-1) # 创建一个pipe(管道) pipe = Pipeline([("standardizer", standardizer), ("knn", knn)]) # 创建k值的参数空间 search_space = [{"knn__n_neighbors": [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]}] # 进行grid搜索 classifier = GridSearchCV( pipe, search_space, cv=5, verbose=0).fit(features_standardized, target) # 最好的k值 print(classifier.best_estimator_.get_params()["knn__n_neighbors"])
![]()
最好的k值是6
15.4 Creating a Radius-Based Nearest Neighbor Classifier
Problem
如果不是根据k近邻,而是给定一个距离,根据距离之内的所有邻居进行分类
Solution
RadiusNeighborsClassifier
radius_neighbors.py
from sklearn.neighbors import RadiusNeighborsClassifier
from sklearn.preprocessing import StandardScaler
from sklearn import datasets
iris = datasets.load_iris()
features = iris.data
target = iris.target
# 标准化
standardizer = StandardScaler()
features_standardized = standardizer.fit_transform(features)
# 训练一个RadiusNeighborsClassifier
rnn = RadiusNeighborsClassifier(
radius=.5, n_jobs=-1).fit(features_standardized, target)
# 创建一个新的样本
new_observations = [[1, 1, 1, 1]]
# 预测
print(rnn.predict(new_observations))
![]()
Discussion
- radius-based(RNN) classifier不那么常用
RadiusNeighborsClassifier与KNeighborsClassifier非常相似- 不同之处:
- radius:我们需要指定固定区域的半径
- outier_label:如果半径内没有邻居,那么需要用户指定具体是什么标签(类)