mmdet训练+测试 (windows, cpu)
目录
-
- 数据集准备:
-
- 1. 数据集格式化
- 2. 修改类别和类别数
- 训练
-
- CPU训练
- 测试
-
- VOC格式数据集(训练)
- 其他问题
官方文档:
https://mmdetection.readthedocs.io/zh_CN/stable/tutorials/config.html
数据集准备:
注:我的数据集是是VOC的xml格式,且已经划分好train、val、trainval、test的了,即\VOCdevkit\VOC2007\ImageSets\Main中已经有相应的txt文件了。
1. 数据集格式化
运行pascal_voc.py将xml转json文件格式:
python tools\dataset_converters\pascal_voc.py data\VOCdevkit --out-dir data\coco\annotations --out-format coco
需注意的细节:
- 这里的split 我增加了test,因为我的数据集里包含test set

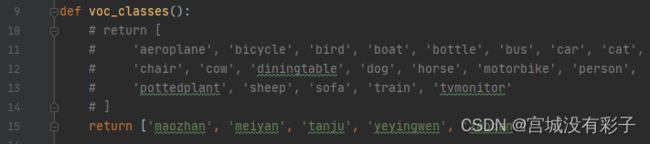
- mmdet\core\evaluation -> class_names.py里的voc_classes修改为自己数据集的类
- 将图片按训练集、验证集、测试集划分复制到coco文件夹下(参考他的):
import mmcv
import shutil
root_path = 'E:/litchi_project/mmdetection/data/VOCdevkit/VOC2007/' # 绝对路径,按需修改
txt_path = root_path + 'ImageSets/Main/'
jpg_path = root_path + 'JPEGImages/'
splits = ['train', 'val', 'test'] # 我只复制了这三个部分的图,trainval不知有必要不
for split in splits:
print('copy images by', split)
src_path = txt_path + split + '.txt'
save_path = "E:/litchi_project/mmdetection/data/coco/" + split + '2017/'
mmcv.mkdir_or_exist(save_path)
with open(src_path, 'r') as f:
for ele in f.readlines():
cur_jpgname = ele.strip() # 提取当前图像的文件名
total_jpgname = jpg_path + cur_jpgname + '.jpg' # 获取图像全部路径
shutil.copy(total_jpgname, save_path + cur_jpgname + '.jpg')
print(split, 'copy done!')
- 生成的json文件中,图片的filename路径为"VOC2007/JPEGImages/2021-11-19-04019.jpg",这里不知会不会为后续训练等造成影响;
果然还是有影响:
FileNotFoundError: [Errno 2] No such file or directory: 'data/coco/train2017/VOC2007/JPEGImages/2021-11-19-04000.jpg'
于是将tools\dataset_converters\pascal_voc.py中55行进行如下更改:
# 'filename': img_path, 这是原来的代码
'filename': img_path.split('/')[-1], # 去掉路径前缀,只保留图片名
- 自行将文件名修改为:

2. 修改类别和类别数
- mmdet/core/evaluation/classnames.py,找到
def coco_classes():

- mmdet/datasets/coco.py,找到
class CoCoDataset(CustomDataset):

- 修改类别数目,\configs\fcos\fcos_r50_caffe_fpn_gn-head_1x_coco.py找到配置文件的num_classes

可以使用该命令查看json文件和图片是否有格式等错误:
python tools\misc\browse_dataset.py configs\fcos\fcos_r50_caffe_fpn_gn-head_1x_coco.py --output-dir data\browse
打印config配置信息(即索引的根), > config.txt表示导出至该文件中:
python tools\miscprint_config.py configs\{model_name}\{model_config_file}.py > config.txt
训练
在conig文件中添加或修改某些字段(按需选择):
model = dict(
backbone=dict(
init_cfg=None) # 不再直接从官网下载预训练模型,使用我自己下载好的预训练模型
)
load_from = 'checkpoints/fcos_center-normbbox-centeronreg-giou_r50_caffe_fpn_gn-head_dcn_1x_coco-ae4d8b3d.pth' # 自己下载的预训练模型路径
evaluation = dict(interval=12, metric='bbox') # 12个epoch进行一次评估
checkpoint_config = dict(interval=2) # 2个epoch保存一次checkpoint
runner = dict(type='EpochBasedRunner', max_epochs=12) # 最大epochs
其他具体见根config文件以及官方文档,最后运行:
python tools/train.py configs\fcos\fcos_center-normbbox-centeronreg-giou_r50_caffe_fpn_gn-head_dcn_1x_coco.py # 单GPU
指定GPU(未试过):
在tools/train.py中添加下面这句代码,再运行上面命令
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
多GPU训练 尝试了很多次也没成功过,下面是参考别人的一种方法:
将tools/dist_train.sh中做如下更改再按官方运行
#PORT=${PORT:-29500}
PORT=${PORT:-$((29500 + $RANDOM % 10))}
bash ./tools/dist_train.sh configs\fcos\fcos_center-normbbox-centeronreg-giou_r50_caffe_fpn_gn-head_dcn_1x_coco.py 2
CPU训练
在tools/train.py中添加下面这句代码,再运行训练命令:
os.environ["CUDA_VISIBLE_DEVICES"] = "-1" # '-1'禁用GPU,'0'使用第0快GPU,'1'使用第1快GPU,以此类推
测试
python tools/test.py configs\fcos\fcos_center-normbbox-centeronreg-giou_r50_caffe_fpn_gn-head_dcn_1x_coco.py work_dirs\...pth --out results\fcos10_7.pkl --eval mAP --show-dir fcos_test_results --gpu-id 1
VOC格式数据集(训练)
- 修改:mmdet/datasets/voc.py中的CLASSES,以及mmdet/core/evaluation/class_names.py中的voc_classes()
class VOCDataset(XMLDataset):
CLASSES = ('maozhan', 'meiyan', 'tanju', 'yeyingwen', 'zaoban')
# CLASSES = ('aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car',
# 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse',
# 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train',
# 'tvmonitor')
def voc_classes():
# return [
# 'aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat',
# 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person',
# 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor'
# ]
return ['maozhan', 'meiyan', 'tanju', 'yeyingwen', 'zaoban']
- configs/base/datasets/voc0712.py中修改路径:
data_root 好像不改也行。要改就改为自己的路径
按需修改训练集、验证集、测试集所用txt文件(有时验证和测试是同一个数据集)
data = dict(
samples_per_gpu=2,
workers_per_gpu=2,
train=dict(
type='RepeatDataset',
times=3,
dataset=dict(
type=dataset_type,
ann_file=[
data_root + 'VOC2007/ImageSets/Main/train.txt',
# data_root + 'VOC2007/ImageSets/Main/trainval.txt',
# data_root + 'VOC2012/ImageSets/Main/trainval.txt' #2012舍弃了应该没问题
],
# img_prefix=[data_root + 'VOC2007/', data_root + 'VOC2012/'],
img_prefix=[data_root + 'VOC2007/'],
pipeline=train_pipeline)),
val=dict(
type=dataset_type,
# ann_file=data_root + 'VOC2007/ImageSets/Main/test.txt',
ann_file=data_root + 'VOC2007/ImageSets/Main/val.txt',
img_prefix=data_root + 'VOC2007/',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
ann_file=data_root + 'VOC2007/ImageSets/Main/test.txt',
img_prefix=data_root + 'VOC2007/',
pipeline=test_pipeline))
- 修改配置文件
configs\fcos\fcos_r50_caffe_fpn_gn-head_1x_coco.py修改:
_base_ = [
# '../_base_/datasets/coco_detection.py',
'../_base_/datasets/voc0712.py',
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
]
修改配置文件中的类别数参考上面 数据集准备->2.修改类别和类别数->3。
其他问题
因为该错误:
(mmlab) E:\litchi_project\mmdetection>python tools\misc\browse_dataset.py configs\fcos\fcos_r50_caffe_fpn_gn-head_1x_coco.py
tools\misc\browse_dataset.py:4: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated since Python 3.3, and in 3.10 it will stop working
from collections import Sequence
No CUDA runtime is found, using CUDA_HOME='C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1'
Traceback (most recent call last):
File "tools\misc\browse_dataset.py", line 137, in <module>
main()
File "tools\misc\browse_dataset.py", line 83, in main
cfg = retrieve_data_cfg(args.config, args.skip_type, args.cfg_options)
File "tools\misc\browse_dataset.py", line 61, in retrieve_data_cfg
cfg = replace_cfg_vals(cfg)
File "e:\litchi_project\mmdetection\mmdet\utils\replace_cfg_vals.py", line 64, in replace_cfg_vals
updated_cfg = Config(
File "D:\ProgramData\Anaconda3\envs\mmlab\lib\site-packages\mmcv\utils\config.py", line 405, in __init__
text = f.read()
UnicodeDecodeError: 'gbk' codec can't decode byte 0xaf in position 883: illegal multibyte sequence
在D:\ProgramData\Anaconda3\envs\mmlab\lib\site-packages\mmcv\utils\config.py", line 404中, 将with open(filename) as f:改为了with open(filename, encoding="utf_8") as f: