轻量级网络EdgeViTs论文翻译
论文地址:
https://arxiv.org/abs/2205.03436
EdgeViTs: Competing Light-weight CNNs on Mobile Devices with Vision Transformers
EdgeViTs: 轻量级视觉Transformer新工作,可与最好的轻量级CNN在移动设备上竞争!
摘要:
Self-attention based models such as vision transformers (ViTs) have emerged as a very competitive architecture alternative to convolutional neural networks (CNNs) in computer vision.
在计算机视觉领域,基于Self-attention的模型(如(ViTs))已经成为CNN之外的一种极具竞争力的架构。
Despite increasingly stronger variants with ever higher recognition accuracies, due to the quadratic complexity of self-attention, existing ViTs are typically demanding in computation and model size.
尽管越来越强的变种具有越来越高的识别精度,但由于Self-attention的二次复杂度,现有的ViT在计算和模型大小方面都有较高的要求。
Although several successful design choices (e.g., the convolutions and hierarchical multi-stage structure) of prior CNNs have been reintroduced into recent ViTs, they are still not sufficient to meet the limited resource requirements of mobile devices.
虽然之前的CNN的一些成功的设计选择(例如,卷积和分层结构)已经被引入到最近的ViT中,但它们仍然不足以满足移动设备有限的计算资源需求。
This motivates a very recent attempt to develop light ViTs based on the state-of-the-art MobileNet-v2, but still leaves a performance gap behind.
这促使人们最近尝试开发基于最先进的MobileNet-v2的轻型MobileViT,但MobileViT与MobileNet-v2仍然存在性能差距。
In this work, pushing further along this under-studied direction we introduce EdgeViTs, a new family of light-weight ViTs that, for the first time, enable attention based vision models to compete with the best light-weight CNNs in the tradeoff between accuracy and ondevice efficiency.
在这项工作中,作者进一步推进这一研究方向,引入了EdgeViTs,一个新的轻量级ViTs家族,也是首次使基于Self-attention的视觉模型在准确性和设备效率之间的权衡中达到最佳轻量级CNN的性能。
This is realized by introducing a highly cost-effective local-global-local (LGL) information exchange bottleneck based on optimal integration of self-attention and convolutions.For device-dedicated evaluation, rather than relying on inaccurate proxies like the number of FLOPs or parameters, we adopt a practical approach of focusing directly on on-device latency and, for the first time, energy efficiency.
这是通过引入一个基于Self-attention和卷积的最优集成的高成本的local-global-local(LGL)信息交换瓶颈来实现的。对于移动设备专用的评估,不依赖于不准确的proxies,如FLOPs的数量或参数,而是采用了一种直接关注设备延迟和能源效率的实用方法。
Extensive experiments on image classification, object detection and semantic segmentation validate high efficiency of our EdgeViTs when compared to the state-of-the-art efficient CNNs and ViTs in terms of accuracy-efficiency tradeoff on mobile hardware.
在图像分类、目标检测和语义分割方面的大量实验验证了EdgeViTs在移动硬件上的准确性-效率权衡方面与最先进的高效CNN和ViTs相比具有更高的性能。
Specifically, we show that our models are Pareto-optimal when both accuracy-latency and accuracy-energy trade-offs are considered, achieving strict dominance over other ViTs in almost
all cases and competing with the most efficient CNNs.
具体地说,EdgeViTs在考虑精度-延迟和精度-能量权衡时是帕累托最优的,几乎在所有情况下都实现了对其他ViT的超越,并可以达到最高效CNN的性能。
1. 简介
Vision transformers (ViTs) have rapidly superseded convolutional neural networks (CNNs) on a variety of visual recognition tasks [10,52], particularly when the priors and successful designs of previous CNNs are reintroduced for lever aging the induction bias of visual data such as local grid structures [55,31,7,16].
在各种视觉识别任务中,视觉transformer(ViTs)已经迅速取代了卷积神经网络(CNNs) [10,52],特别当重新引入了目前CNN的先验与成功设计,以利用局部网格结构等视觉数据的诱导偏差的时候[55,31,7,16]。
Due to the quadratic complexity of ViTs and the high-dimension property of visual data, it is indispensable that the computational cost needs to be taken into account in design [55].
由于ViT的二次复杂度和可视化数据的高维性,在网络设计时考虑计算代价是必不可少的[55]。
Three representative designs to make computationally viable ViTs are (1) the use of a hierarchical architecture with the spatial resolution (i.e., the token sequence length) progressively down-sampled across the stages[12,55,7], (2) the locally-grouped self-attention mechanisms for controlling the length of input token sequences and parameter sharing [31,16], (3) the pooling
attention schemes to subsample the key and value by a factor [54,35,60,55].
三种具有典型的设计使得ViT在计算上代价上更小:
(1)使用具有空间分辨率(即token序列长度)的分层体系结构,在各个阶段逐步向下采样[12,55,7];
(2)用于控制输入token序列长度和参数共享的局部分组自我注意机制[31,16];
(3)池化注意方案以因子对key和value进行子抽样[54,35,60,55]。
The general trend has been on designing more complicated and stronger ViTs to challenge the dominance of top-performing CNNs [20,40,48] in computer vision by achieving ever higher accuracies [53,66].
总体趋势是设计更复杂、更强大的ViT,通过实现更高的准确性[53,66],来挑战性能最好的CNN[20,40,48]在计算机视觉领域的主导地位。
These advances however are still insufficient to satisfy the design requirements and constraints for mobile and edge platforms (e.g., smart phones, robotics, self-driving cars, AR/VR devices),
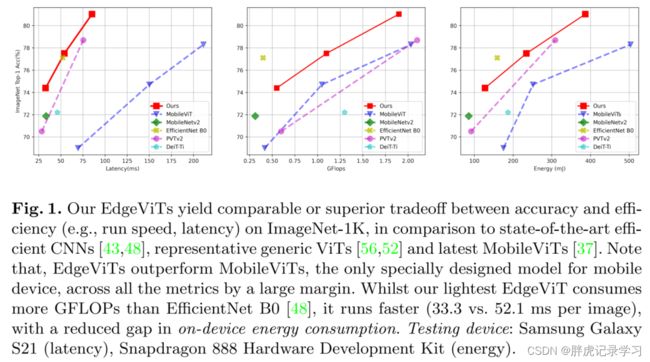
where the vision tasks need to carry out in a timely manner under certain computational budgets. Prior efficient CNNs (e.g., MobileNets [23,43,22], ShuffleNets[36,64], EfficientNets [48,51,49], and etc.) remain the state-of-the-art network architectures for such platforms in the tradeoff between running latency and recognition accuracy (Fig. 1).
然而,这些进展仍不足以满足移动和边缘平台(如智能手机、机器人、自动驾驶汽车、AR/VR设备)的设计要求和限制,视觉任务需要在一定的计算代价下快速完成。权衡运行延迟和识别精度之间进行,目前有效的CNN(例如MobileNets[23,43,22]、ShuffleNets[36,64]、EfficientNets[48,51,49]等)仍然是这些平台的最先进的网络架构(图1)。
In this work, we focus on the development of largely under-studied efficient ViTs with the aim to surpass the CNN counterparts on mobile devices.We consider a collection of very practical design requirements for running a ViT model on a target real-world platform as follows:
(1) Inference efficiency needs to be high (e.g., low latency and energy consumption) so that the running cost becomes generically affordable and more on-device applications can be supported.
This is a direct metric that we really care about in practice. In contrast, the often-used efficiency metric, FLOPs (i.e., the number of multiply-adds), cannot directly translate into the latency and energy consumption on a specific device,with several conditional factors including memory access cost, degree of parallelism, and the platform’s characteristics [36]. This is, not all operations of a model can be carried out at the same speed and energy cost on a device. Hence,
FLOPs is merely an approximate and indirect metric of efficiency. (2) Model size (i.e., parameter number) is affordable for modern average devices. Given the availability of ever cheaper and larger storage spaces, this constraint has been relaxed significantly. For example, an average smart phone often comes with 32GB or more storage. As a consequence, using it as a threshold metric is no longer valid in most cases. (3) Implementational friendliness is also critical in real-world applications. For a wider range of deployment, it is necessary that a model can be implemented efficiently using the standard computing operations supported and optimized in the generic deep learning frameworks (e.g., ONNX, TensorRT, and TorchScript), without costly per-framework specialization. Otherwise, the on-device speed of a model might be unsatisfactory even with low FLOPs.
在这项工作中,我们专注于开发大量没有研究的高效ViT,目的是在移动设备上超越CNN同行。我们考虑了在现实设备上运行ViT模型的一系列非常实用的设计要求:
(1)推理效率需要高(例如低延迟和能源消耗),这样运行成本就普遍负担得起,更多设备上的应用程序逗可以支持应用,这才是我们在实践中真正关心的直接指标。相比之下,经常使用的效率指标FLOPs(即加法与乘法运算量),不能直接转化为特定设备上的延迟和能源消耗,而是考虑几个条件因素,包括内存访问成本、并行度和平台的特征等等;也就是说,并不是一个模型的所有操作都可以在一个设备上以相同的速度和能量消耗进行。因此,FLOPs仅仅是效率的近似和间接度量。
(2)模型尺寸(即参数量)对于现今的移动设备来说是负担得起的。由于存储空间越来越便宜、越来越大,这一限制已经大大放宽。例如,一般的智能手机通常有32GB或更多的存储空间。因此,在大多数情况下,使用它作为阈值指标不再有效。
(3)实现的简易性在实际应用中也是至关重要的。对于更广泛的部署,有必要使用通用深度学习框架(如ONNX、TensorRT和TorchScript)支持和优化的标准计算操作高效地实现模型,而不需要花费昂贵的代价为每个网络框架进行专门化设计。否则,即使使用低FLOPs,模型在移动设备上速度也可能不令人满意。
For instance, the cyclic shift and its reverse operations introduced in Swin Transformers [31] are rarely supported by the mainstream frameworks, i.e., deployment unfriendly.In the literature, very recent MobileViTs [37] are the only series of ViTs designed for mobile devices. In architecture design, they are a straightforward combination of MobileNetv2 [43] and ViTs [10].
例如,Swin transformer中引入的循环移位及其反向操作很少得到主流框架的支持,也就是说,部署不友好[31]。 在文献中,最近的MobileViTs[37]是唯一为移动设备设计的ViT系列。在架构设计中,它们是MobileNetv2[43]和ViTs[10]的直接组合。
As a very initial attempt in this direction, MobileViTs still lag behind CNN counterparts.Further, its evaluation protocol takes the model size (i.e. the parameter number) as the competitor selection criteria (i.e., comparing the accuracy of models only with similar parameter numbers), which however is no longer a hard constraint with modern hardware as discussed above and is hence out of date.
作为这一方向的初步尝试,MobileViTs仍然落后于CNN系列。 此外,它的评估方案将模型大小(即参数量)作为竞争对手的选择标准(即仅用相似的参数量比较模型的准确性),然而,正如上面讨论的那样,这在现在的移动硬件中不再是一个硬约束,因此已经过时。
We present a family of light-weight attention based vision models, dubbed as EdgeViTs, for the first time, enabling ViTs to compete with best light weight CNNs (e.g., MobileNetv2 [43] and EfficientNets [48]) in terms of accuracy efficiency tradeoff on mobile devices. This sets a milestone in the landscape of light weight ViTs vs. CNNs in the mobile device regime with low resource budgets.Concretely, our EdgeViTs are based on a novel factorization of the standard
self-attention for more cost-effective information exchange within every individual layer.
我们首次提出了一系列基于注意力的轻量级视觉模型,称为EdgeViTs,使ViTs能够在移动设备上的准确性和效率权衡方面与最佳轻量级CNN(例如,MobileNetv2[43]和EfficientNets[48])竞争。这在低资源预算的移动设备中,轻量级ViT与CNN的发展前景中树立了一个里程碑。具体地说,我们的EdgeViTs是基于标准的自注意力的一种新的因式分解,以便在每个层中进行更经济有效的信息交换。
This is made possible by introducing a highly light-weight and easy-to-implement local-global-local (LGL) information exchange bottleneck characterized with three operations: (i) Local information aggregation from neighbor tokens (each corresponding to a specific patch) using efficient depth-wise convolutions; (ii) Forming a sparse set of evenly distributed delegate tokens for long-range information exchange by self-attention; (iii) Diffusing updated information from delegate tokens to the non-delegate tokens in local neighborhoods via transposed convolutions. As we will show in experiments, this design presents a favorable hybrid of self-attention, convolutions, and transposed convolutions,achieving best accuracy-efficiency tradeoff. It is efficient in that the self-attention is applied to a sparse set of delegate tokens. To support a variety of computational budgets, with our primitive module we establish a family of EdgeViT variants with three computational complexities (S: small, XS: extra small, and XXS:
extra extra small).
这是通过引入一个高度轻量级的、易于实现的局部-全局-局部(LGL)信息交换瓶颈实现的,该瓶颈以三种操作为特征:
(1)利用高效的深度卷积从邻近tokens(每个token对应一个特定的patch)聚合局部信息;
(2)通过自注意力机制形成均匀分布的代表tokens的稀疏集合以实现远程信息交换;
(3)通过转置卷积从代表tokens扩散到局部邻近的非代表tokens进行信息更新;
正如我们将在实验中展示的,这种设计提供了良好的自我注意、卷积和转置卷积的混合,实现了最佳的准确性和效率折衷。它的有效性在于将自我注意力机制应用于代表tokens的稀疏集。为了支持各种计算预算,通过我们的初始模块,我们建立了具有三种计算复杂性的EdgeViTs系列(S,XS,XXS)。
We make the following contributions: (1) We investigate the design of light-weight ViTs from the practical on-device deployment and execution perspective. (2) For best scalability and deployment, we present a novel family of efficient ViTs, termed as EdgeViTs, designed based on an optimal decomposition of self-attention using standard primitive operations. (3) Regarding on-device performance, towards relevance for real-world deployment, we directly consider latency and energy consumption of different models rather than relying on high level proxies like number of FLOPs or parameters. Our results experimentally verify efficiency of our models in a practical setting and refute some of the claims made in the existing literature. More specifically, extensive experiments on three visual tasks show that our EdgeViTs can match or surpass state-of-the-
art light-weight CNNs, whilst consistently outperform the recent MobileViTs in accuracy-efficiency tradeoff, including largely ignored on-device energy evaluation. Importantly, EdgeViTs are consistently Pareto-optimal in terms of both latency and energy efficiency, achieving strict dominance over other ViTs in almost all cases and competing with the most efficient CNNs. On ImageNet classification our EdgeViT-XXS outperforms MobileNetv2 by 2.2% subject to the similar energy-aware efficiency.
我们的贡献如下:
(1)我们从实际设备上部署和执行的角度研究轻量级ViT的设计;
(2)为了获得最佳的延展性和部署,我们提出了一种新的高效ViT家族,称为EdgeViT,它是基于使用标准初始模块的自注意力机制的最优分解而设计的。
(3)关于设备上的性能,为了现实部署的相关性,我们直接考虑不同模型的延迟和能源消耗,而不是依赖于其他标准,如FLOPs数量或参数量。
我们的结果在实验上验证了我们的模型在实际设置中的效率,并驳斥了现有文献中的一些主张。更具体地说,在三个视觉任务上的广泛实验表明,我们的EdgeViTd可以匹配或超过最先进的轻型CNN,同时在准确性和效率的权衡方面始终优于最近的MobileViTs,包括在很大程度上被忽略的设备上的能源评估。重要的是,EdgeViT在延迟和能源效率方面始终是帕累托最优的,几乎在所有情况下都严格优于其他ViT,并与效率最高的CNN竞争。在ImageNet分类中,我们的EdgeViT-XXS在能源利用效率方面比MobileNetv2高出2.2%。
2. 相关工作
Efficient CNNs. Since the advent of modern CNN architectures [20,46], there has been a steady stream of works focusing on efficient architecture design for on-device deployment. The first widely adopted families bring depthwise separable convolutions in a ResNet-like structure, e.g., MobileNets [23,43], ShuffleNets[64,36]. These works define a space of well-performing efficient architectures,resulting in widespread usage. Successive works further exploit this design space
by automating the architectural design choices [48,22,47,50]. As a parallel line of research, net pruning creates efficient architectures by removing spurious parts of a larger network with close-to-zero weights [17,57], or via first training a super network that is further slimmed to meet a pre-specified computational budget[32,3]. Dynamic computing has also been explored, consisting of the mechanisms that condition the network parameters on the input data [62,6]. Finally, using
low bit-width is a very critical technique that can offer different tradeoffs between the accuracy and efficiency [17,24,5].
高效的CNNs。自从现代CNN架构出现以来[20,46],一直有一个稳定的工作专注于on-device部署的高效架构设计。第一个被广泛采用的网络家族在类似resnet的结构中带来了深度可分离卷积,例如MobileNets [23,43], ShuffleNets[64,36]。这些作品定义了一个性能良好的高效架构的空间,得到了广泛的使用。后续的工作通过自动化架构设计选择进一步利用了这种设计空间[48,22,47,50]。作为一种平行研究,网络剪枝通过去除一个较大网络中接近于零权值的虚假部分[17,57],或首先训练一个进一步精简的超级网络以满足预先指定的计算预算[32,3]来创建高效的体系结构。动态计算也已被探索,包括机制条件下的网络参数的输入数据[62,6]。最后,使用低的位宽是一种非常关键的技术,可以在精度和效率之间提供不同的权衡[17,24,5]。
Vision transformers. ViTs [10] quickly popularize transformer-based architectures for computer vision. A series of works followed instantly, offering large improvements to the original ViTs in terms of data efficiency [52,30] and architecture design [31,63,12,4]. Among these works, one of the main modifications is to introduce hierarchical designs in multiple stages from convolutional architectures [31,7,55,56]. Several works also focus on improving the positional encoding by using a relative positional embedding [45,44], making it learnable [14], oreven replacing it by a attention bias element [15]. All these approaches mostly aim to improve the model performance.
Recently, more efforts have been made towards finding efficient alternatives to the multi-head self-attention (MHSA) module, which is typically the computational bottleneck in the ViT architectures. A particularly effective solution is to reduce the internal spatial dimensions within the MHSA. The MHSA involves projecting the input tensor into key, query and value tensors. Several recent works, e.g. [7,55,56], find that the key and value tensors could be down sampled with a limited loss in accuracy, leading to a better efficiency-accuracy tradeoff. Our work extends this idea by also downsampling the query tensors,which further improves the efficiency, as shown in Fig. 2.
There are also alternative approaches reducing the number of tokens dynamically [41,61,38,13].
That is, in the forward pass, tokens deemed to not contain the important information for the target task are pruned or pooled together, reducing the overall complexity thereafter. Finally, encouraged by their potential complementarity, many works have attempted to combine convolutional designs with self-attentions. This ranges from using convolutions at the stem [59], integrating convolutional operations into the MHSA block [26,58], or incorporating the
MHSA block into ResNet-like architectures [45]. It is interesting to note that even the original ViTs explored similar tradeoffs. [10].
视觉transformers。ViTs[10]很快普及了基于transformer的计算机视觉架构。随后,一系列的工作接踵而至,在数据效率[52,30]和架构设计[31,63,12,4]方面对原来的ViT提供了很大的改进。其中,主要的修改之一就是从卷积架构引入了多阶段的分层设计[31,7,55,56]。有几个工作还着重于通过使用相对位置嵌入来改进位置编码,使其可以学习,甚至用注意力偏差取代它。所有这些方法都是为了提高模型的性能。
近年来,越来越多的人致力于寻找有效的方法来替代在ViT体系结构中典型的计算瓶颈——多头自注意(MHSA)模块。一个特别有效的解决方案是减少MHSA内部的空间维度。MHSA包括将输入张量投影为key张量、query张量和value张量。最近的一些工作,如[7,55,56],发现key张量和value张量可以在精度损失有限的情况下进行下采样,从而获得更好的效率-精度折中。我们的工作通过降低query张量的采样扩展了这一思想,进一步提高了效率,如图2所示。
还有一些替代方法可以动态地减少token的数量[41,61,38,13]。
也就是说,在前向传递中,被认为不包含目标任务重要信息的tokens将被修剪或合并在一起,从而降低之后的整体复杂性。最后,在他们潜在的互补性的激励下,许多工作尝试将卷积设计与自注意结合起来。这包括在stem [59]使用卷积,将卷积操作集成到MHSA区块[26,58],或将MHSA区块集成到类似resnet的架构[45]。有趣的是,即使是最初的ViT也探索了这种权衡[10]。
Vision transformers for mobile devices. Whilst the efficiency issue has been taken into account in designing the ViT variants discussed above, they are still not dedicated and satisfactory architectures for on-device applications. There is only one exception, MobileViTs [37], which are introduced very recently. However, compared to the current best light-weight CNNs such as MobileNets [43,22] and EfficicentNets [48], these ViTs are still clearly inferior in terms of the on-
device accuracy-efficiency tradeoff. In this work, we present the first family of efficient ViTs that can deliver comparable or even superior tradeoffs in comparison to the best CNNs and ViTs. We also extensively carry out the critical yet largely lacking on-device evaluations with energy consumption analysis.
移动设备的视觉transformer。虽然在设计上面讨论的ViT变体时考虑到了效率问题,但它们仍然不是用于设备上应用程序的专用和令人满意的架构。只有一个例外,MobileViTs[37],它是最近才推出的。然而,与目前最好的轻量级CNN(如MobileNets[43,22]和efficentnets[48])相比,这些ViT在设备精度-效率权衡方面仍明显较差。在这项工作中,我们提出了第一组高效的ViT,与最好的CNN和ViT相比,可以提供可比的甚至更好的权衡。我们还广泛开展了关键但在很大程度上缺乏的设备能耗分析评估。
3. EdgeViTs
3.1 概述
For designing light-weight ViTs suitable for mobile/edge devices, we adopt a hierarchical pyramid network structure (Fig. 2(a)) used in recent ViT variants[55,8,7,56,12]. A pyramid transformer model typically reduces the spatial resolution but expands the channel dimension across different stages. Each stage consists of multiple transformer-based blocks processing tensors of the same shape,mimicking the ResNet-like networks. The transformer-based blocks heavily rely on the self-attention operations at a quadratic complexity w.r.t the spatial resolution of the visual features. By progressively aggregating the spatial tokens, pyramid vision transformers are potentially more efficient than isotropic models [10].
为了设计适用于移动/边缘设备的轻量级ViT,作者采用了最近ViT变体中使用的分层金字塔结构(图2(a))。Pyramid Transformer模型通常在不同阶段降低了空间分辨率同时也扩展了通道维度。每个阶段由多个基于Transformer Block处理相同形状的张量,类似ResNet的层次设计结构。
基于Transformer Block严重依赖于具有二次复杂度的Self-attention操作,其复杂度与视觉特征的空间分辨率呈2次关系。通过逐步聚集空间Token,Pyramid Transformer可能比各向同性模型(ViT)更有效。
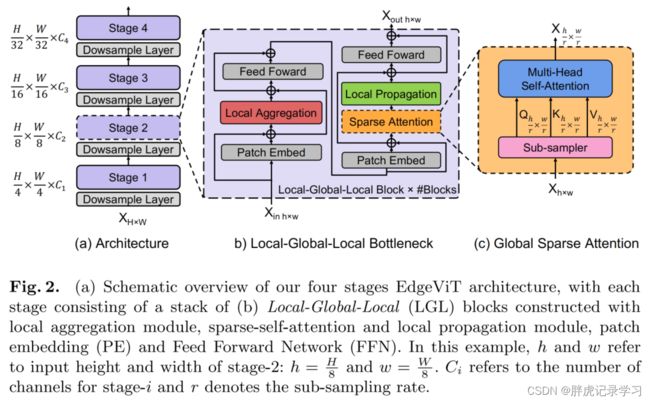
In this work, we dive deeper into the transformer-based block and introduce a cost-effective bottleneck, Local-Global-Local (LGL) (Fig. 2(b)). LGL further reduces the overhead of self-attention with a sparse attention module (Fig. 2(c)),achieving better accuracy-latency balancing.
在这项工作中,作者深入到Transformer Block,并引入了一个比较划算的Bottlneck,Local-Global-Local(LGL)(图2(b))。LGL通过一个稀疏注意力模块进一步减少了Self-attention的开销(图2(c)),实现了更好的准确性-延迟平衡。
3.2 Local-Global-Local bottleneck
Self-attention has been shown to be very effective for learning the global context or long-range spatial dependency of an image, which is critical for visual recognition. On the other hand, as images have high spatial redundancy (e.g.,nearby patches are semantically similar) [18],applying attention to all the spatial tokens, even in a down-sampled feature map, is inefficient. There is hence an opportunity to reduce the scope of tokens whilst still preserving the underlying information flows that model the global and local contexts. In contrast to previous transformer blocks that perform self-attention at each spatial location,our LGL bottleneck only computes self-attention for a subset of the input tokens but enables full spatial interactions, as in the standard multi-head self-attention (MHSA) [10].
To achieve this, we decompose the self-attention into consecutive modules that process the spatial tokens within different ranges (Fig. 2(b)). We introduce three efficient operations: i) Local aggregation that integrates signals only from locally proximate tokens; ii) Global sparse attention that model long-range relations among a set of delegate tokens where each of them is treated as a representative for a local window; iii) Local propagation that diffuses the global contextual information learned by the delegates to the non-delegate tokens with the same window. Combining these, our LGL bottleneck enables information exchanges between any pair of tokens in the same feature map at a low-compute cost. Each of these components is described in detail below:
Self-attention已被证明是非常有效的学习全局信息或长距离空间依赖性的方法,这是视觉识别的关键。另一方面,由于图像具有高度的空间冗余(例如,附近的Patch在语义上是相似的),将注意力集中到所有的空间Patch上,即使是在一个下采样的特征映射中,也是低效的。因此,与以前在每个空间位置执行Self-attention的Transformer Block相比,LGL Bottleneck只对输入Token的子集计算Self-attention,但支持完整的空间交互,如在标准的Multi-Head Self-attention(MHSA)中。既会减少Token的作用域,同时也保留建模全局和局部上下文的底层信息流。
为了实现这一点,作者将Self-attention分解为连续的模块,处理不同范围内的空间Token(图2(b))。
这里引入了3种有效的操作:
-
Local aggregation:仅集成来自局部近似
Token信号的局部聚合 -
Global sparse attention:建模一组代表性
Token之间的长期关系,其中每个Token都被视为一个局部窗口的代表; -
Local propagation:将委托学习到的全局上下文信息扩散到具有相同窗口的非代表
Token。
将这些结合起来,LGL Bottleneck就能够以低计算成本在同一特征映射中的任何一对Token之间进行信息交换。下面将详细说明每一个组成部分:
 – Local aggregation: for each token, we leverage depth-wise and point-wise convolutions to aggregate information in local windows with a size of k × k(Fig. 3(a)).
– Local aggregation: for each token, we leverage depth-wise and point-wise convolutions to aggregate information in local windows with a size of k × k(Fig. 3(a)).
– Global sparse attention: we sample a sparse set of delegate tokens distributed evenly across the space, one delegate token for each r × r window. Here, rdenotes the sub-sample rate. We then apply self-attention on these selected tokens only (Fig. 3(b)). This is distinct from all the existing ViTs [7,55,56] where all the spatial tokens are involved as queries in the self-attention computation.
– Local propagation: We propagate the global contextual information encoded in the delegate tokens to their neighbor tokens by transposed convolutions(Fig. 3(c)).
1、Local aggregation
对于每个Token,利用Depth-wise和Point-wise卷积在大小为k×k的局部窗口中聚合信息(图3(a))。
2、Global sparse attention
对均匀分布在空间中的稀疏代表性Token集进行采样,每个r×r窗口有一个代表性Token。这里,r表示子样本率。然后,只对这些被选择的Token应用Self-attention(图3(b))。这与所有现有的ViTs不同,在那里,所有的空间Token都作为Self-attention计算中的query被涉及到。
3、Local propagation
通过转置卷积将代表性Token中编码的全局上下文信息传播到它们的相邻的Token中(图3(c))。
Formally, our LGL bottleneck can be formulated as:
X = LocalAgg(Norm(Xin)) + Xin,
Y = FFN(Norm(X)) + X,
Z = LocalProp(GlobalSparseAttn(Norm(Y ))) + Y,
Xout = FFN(Norm(Z)) + Z.
Here Xin ∈ RH×W ×C indicates the input tensors. Norm is the layer normalization operation[2]. LocalAgg represents the local aggregation operator, FFN is a two layer perceptron, similar to the position-wise feed-forward network introduced in [10]. GlobalSparseAttn is the global sparse self-attention. LocalProp is the local propagation operator. For simplicity, positional encoding is omitted. Note that, all these operators can be implemented by commonly used and highly
optimized operations in the standard deep learning platforms. Hence, our LGLbottleneck is implementation friendly.
最终,LGL bottleneck可以表达为:

这里,![]() 表示输入张量。
表示输入张量。Norm是Layer Normalization操作。LocalAgg表示局部聚合算子,FFN是一个双层感知器。GlobalSparseAttn是全局稀疏Self-attention。LocalProp是局部传播运算符。为简单起见,这里省略了位置编码。注意,所有这些操作符都可以通过在标准深度学习平台上的常用和高度优化的操作来实现。因此,LGL bottleneck对于实现是友好的。
Comparisons to existing designs. Our LGL bottleneck shares a similar goal with the recent PVTs [55,56] and Twins-SVTs [7] models that attempt to reduce the self-attention overhead. However, they differ in the core design. PVTs[55,56] perform self-attention where the number of keys and values are reduced by strided-convolutions, whilst the number of queries remains the same.In other words, PVTs still perform self-attention at each grid location. In this work, we question the necessity of positional-wise self-attention and explore to what extent the information exchange enabled by our LGL bottleneck could approximate the standard MHSA (see Section 4 for more details). Twins-SVTs[7] combine local-window self-attention [31] with global pooled attention from PvTs [55]. This is different from our hybrid design using both self-attention and convolution operations distributed in a series of local-global-local operations. As demonstrated in the experiments (Table 2 and 3), our design achieve a better tradeoff between the model performance and the computation overhead (e.g. latency, energy consumption, etc).
与现有设计的比较。我们的LGL瓶颈与最近PVTs[55,56]和Twin - SVTs[7]模型有着相似的目标,这些模型试图减少自注意的开销。然而,它们在核心设计上有所不同。PVTs[55,56]执行自注意,其中key和value的数量通过跨卷积减少,而query的数量保持不变。换句话说,PVTs仍然在每个网络位置执行自注意。在这项工作中,我们质疑空间位置自注意的必要性,并探索了由我们的LGL瓶颈激活的信息交换在多大程度上可以接近标准的MHSA(详见第4节)。Twin - SVTs[7]将局部窗口自注意[31]与来自PVTs的全局集中注意[55]结合起来。这与我们的混合设计不同,我们使用了自关注和卷积运算分布在一系列局部-全局-局部运算中。正如实验(表2和表3)所示,我们的设计在模型性能和计算开销(例如延迟、能量消耗等)上有更好的权衡。
3.3 Architectures
We build a family of EdgeViTs with the proposed LGL bottleneck at different computational complexities (0.5G, 1G, and 2G to be specific). The configurations are summarized in Table 1. Following the previous hierarchical ViTs [7,55,31,26],EdgeViTs consist of four stages with the spatial resolution (i.e., the token sequence length) gradually reduced throughout, and their self-attention module replaced with our LGL bottleneck. For the stage-wise down-sampling, we use a
conv-layer with a kernel size of 2×2 and stride 2, except for the first stage where we down-sample the input feature by ×4, and use a 4 × 4 kernel and a stride of 4. We adopt the conditional positional encoding [8] that has been shown to be superior to the absolute positional encoding. This can be implemented using 2D depth-wise convolutions plus a residual connection. In our model, we use 3 × 3 depth-wise convolutions with zero paddings. It is placed before the local aggregation and before global sparse self-attention. The FFN consists of two linear layers with GeLU non-linearlity [21] placed in-between. Our local aggregation operator is implemented as a stack of pointwise and depthwise convolutions. The global sparse attention is composed of a spatial uniform sampler with sample rates of (4, 2, 2, 1) for the four stages, and a standard MHSA. The local propagation is implemented with a depthwise separable transposed convolution with the kernel size and stride equal to the sample rate used in the global sparse attention.The exact architecture for the LGL bottleneck is described in the supplementary material.
我们在不同的计算复杂性(0.5G、1G和2G)下构建了一系列带有建议的LGL瓶颈的EdgeViTs。表1总结了这些配置。继之前的分层ViT[7,55,31,26]之后,EdgeViT由四个阶段组成,空间分辨率(即token序列长度)逐渐减少,它们的self-attention模块被我们的LGL瓶颈取代。

对于逐级下采样,我们使用内核大小为2×2,步长为2的conv-layer,除了第一阶段,我们对输入特性进行了×4的下采样,并使用4 ×4的内核,步长为4。我们采用条件位置编码[8],该编码已被证明优于绝对位置编码。 这可以使用2D深度卷积加上残差连接来实现。在我们的模型中,我们使用3 × 3的深度卷积,没有填充。它被放在局部聚合和全局稀疏自我注意之前。FFN由两个线性层组成,中间是GeLU非线性[21]。我们的局部聚合操作实现为点卷积和深度卷积的堆栈。全局稀疏注意由四个阶段的采样率为(4,2,2,1)的空间均匀采样器和标准的MHSA组成。局部传播采用深度可分离卷积实现,其核大小和步长等于全局稀疏注意的采样率,LGL瓶颈的确切架构在补充材料中进行了描述。
4. 实验
We benchmark EdgeViTs on visual recognition tasks. We pre-train EdgeViTs on the Imagenet1K recognition task [42], comparing the performances and computation overheads against alternative approaches. We also evaluate the generalization capacity of EdgeViTs on downstream dense prediction tasks: object detection and instance segmentation on the COCO benchmark [29], and semantic segmentation on the ADE20K Scene Parsing benchmark [65]. For on-device execution, we report exucution time (latency) and energy consumption of all relevant models on ImageNet. We do not report on-device measurements on downstream tasks as they reuse ImageNet models.
我们在视觉识别任务上对EdgeViTs进行了基准测试。我们在Imagenet1K识别任务[42]上对EdgeViTs进行了预训练,比较了与其他方法相比的性能和计算开销。我们还评估了EdgeViTs在下游密集预测任务上的泛化能力:在COCO基准[29]上的对象检测和实例分割,以及在ADE20K Scene Parsing基准上的语义分割[65]。对于设备上的执行,我们报告所有相关模型在ImageNet上的执行时间(延迟)和能源消耗。在下游任务重用ImageNet模型时,我们不报告设备上的测量结果。
4.1 ImageNet-1K上的图像分类
Training Settings. ImageNet-1K [42] provides 1.28 million training images and 50,000 validation images from 1000 categories. We follow the training recipe introduced in DeiT [52]. We optimize the models using AdamW [33] with a batch size of 1024, weight decay of 5 × 10−2, and momentum of 0.9. The models are trained from scratch for 300 epochs with a linear warm-up during the first 5 epochs. Our base learning rate is set as 1 × 10−3, and decay after the warm-
up using a cosine schedule [34]. We apply the same data augmentations as in [52,7,56,26] which include random cropping, random horizontal flipping, mixup, random erasing and label-smoothing. During training, the images are randomly cropped to 224 × 224. During testing, we use a single center crop of 224 × 224. We report the top-1 accuracy on the validation set.
训练设置。ImageNet-1K[42]提供了来自1000个类别的128万张训练图像和5万张验证图像。我们遵循DeiT[52]中介绍的训练方法。我们使用批量大小为1024、权重衰减为5 × 10−2、动量为0.9的AdamW[33]对模型进行优化。模型从头开始训练300个阶段,前5个阶段进行线性warm-up。我们的基础学习速率设置为1 × 10−3,并在warm-up后使用余弦[34]衰减。我们应用了与[52,7,56,26]相同的数据增强,包括随机裁剪、随机水平翻转、混合、随机擦除和标签平滑。在训练过程中,图像被随机裁剪为224 × 224。在试验中,我们使用一个224 × 224的单中心crop。我们报告了验证集中top-1的准确性。

 4.2 Dense Prediction
4.2 Dense Prediction
COCO Object Detection/Instance Segmentation(目标检测/实例分割)
。。。。。。
5 结论
In this work, we have investigated the design of efficient ViTs from the scalable on-device deployment perspective. By introducing a novel decomposition of self-attention, we present a family of EdgeViTsthat, for the first time, achieve comparable or even superior accuracy-efficiency tradeoff on generic visual recognition tasks, in comparison to a variety of state-of-the-art efficient CNNs and ViTs. Critically, we conduct extensive on-device experiments using practically critical and previously underestimated metrics (e.g., energy-aware efficiency) and reveal new insights and observations in the comparison of light-weight CNN and ViT models.
在这项工作中,我们从可延展的设备部署的角度研究了高效ViT的设计。通过引入一种新的自注意分解,我们提出了EdgeViT家族,与各种最先进的高效的CNN和ViT相比,第一次在一般视觉识别任务中实现了可媲美的甚至优越的准确性-效率折中。关键的是,我们使用实际关键的和以前被低估的指标(例如,能源感知效率)进行了广泛的设备上的实验,并在轻型CNN和ViT模型的比较中揭示了新的见解和观察。
附录
A.1 Computing Complexity
We calculate the computational cost of spatial context modeling involved in our proposed LGL bottleneck. We omit point-wise operations for simplicity as the key difference is on the spatial modeling part. Let us assume an input![]() where h, w, c denotes the height, the width, and the channel dimension, respectively. The cost of the local aggregation is O(
where h, w, c denotes the height, the width, and the channel dimension, respectively. The cost of the local aggregation is O(![]() ), where
), where![]() is the local group size. By selecting one delegate out of
is the local group size. By selecting one delegate out of 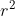 tokens with r the sub-sampling rate, the complexity of our Sparse Global Self-Attention is then O(
tokens with r the sub-sampling rate, the complexity of our Sparse Global Self-Attention is then O( ![]() ). Finally, the local propagation step takes a cost of O(
). Finally, the local propagation step takes a cost of O(![]() ). Putting all these together we have a total cost of LGL is O(
). Putting all these together we have a total cost of LGL is O(![]() ).When comparing with the cost of a standard multi-head self-attention O(
).When comparing with the cost of a standard multi-head self-attention O(![]() ),we can see that our LGL significantly reduces the computation overhead whenk ≪ h, w; and r > 1. In our experiments, for simplicity we set k = 3, and r to (4,2,2,1) for the four stages.
),we can see that our LGL significantly reduces the computation overhead whenk ≪ h, w; and r > 1. In our experiments, for simplicity we set k = 3, and r to (4,2,2,1) for the four stages.
计算复杂度我们计算了涉及我们提出的LGL瓶颈的空间上下文建模的计算成本。为了简单起见,我们省略了逐点卷积操作,因为关键在于空间建模部分。假设输入![]() ,其中h、w、c分别表示高度、宽度和通道。局部聚合的开销为
,其中h、w、c分别表示高度、宽度和通道。局部聚合的开销为![]() ,其中
,其中![]() 为局部分组的大小。通过从个tokens中选择子采样率为r的一个token,我们的稀疏全局自注意复杂度为
为局部分组的大小。通过从个tokens中选择子采样率为r的一个token,我们的稀疏全局自注意复杂度为![]() ,最后,局部传播步骤的代价为
,最后,局部传播步骤的代价为![]() ,把所有这些放在一起,我们所有LGL的总成本是
,把所有这些放在一起,我们所有LGL的总成本是![]() ,与标准多头自我注意O(h2w2c)的成本相比,我们可以看到当k≪h, w;r > 1。在我们的实验中,为了简单起见,我们设这四个阶段的k = 3, r为(4,2,2,1)。
,与标准多头自我注意O(h2w2c)的成本相比,我们可以看到当k≪h, w;r > 1。在我们的实验中,为了简单起见,我们设这四个阶段的k = 3, r为(4,2,2,1)。
A.2 Implementation Details
In Algorithm 1, we provide Pytorch Style pseudo-code for all the build blocks of our EdgeViTs. All variants of EdgeViTs can be built upon these components according to the schematic overview (Fig. 2a of the main paper), and the model configuration parameters (Table 1a. of the main paper). For reproducibility, we will make our source code publicly available.For more details with the ablation studies in the main paper, we have replaced or removed one of these blocks with the details given below.
(1) In Table 4a, for the case of w/o LA, we aim to test the importance of separate local and global context modeling. Thus we remove both LocalAgg and GlobalSparseAttn, and instead use the Spatial-Reduced Self-Attention4 introduced in PVT [56], resulting in a single Self-Attention Block for both local and global context modeling. For the case of LA(LSA) we simply replace LocalAgg
with Local-grouped Self-Attention5 introduced in [7].
(2) In Table 4b, we replace the default sampler (Center) with Avg and Max functions which can be implemented with AvgPool2d() and MaxPool2d() in Pytorch [39], respectively. Note, for both cases the kernel size is set to sample rate.
(3) In Table 4c, in the case of w/o LP, we replace our GlobalSparseAttn with Spatial-Reduce Self-Attention from PVT [56], but different from w/o LA, we keep the LocalAgg. For the case of LP(Bilinear), the LocalProp is instantiated as a bilinear interpolation function (Upsample(mode=‘bilinear’) in Pytorch).
Note, the number of layers for each of these variants is down-scaled to have 0.5GFLOPs for fair comparison
在算法1中,我们为EdgeViTs的所有构建块提供了Pytorch Style伪代码。根据原理图概述(图2a)和模型配置参数(表1a),可以在这些组件上构建EdgeViTs的所有变体。(主论文的)。为了方便再现,我们将公开源代码。
关于消融实验的更多细节,我们已经替换或移除了其中一块,详细信息如下所示。
(1)在表4a中,对于w/o LA的情况,我们旨在测试单独的局部和全局上下文建模的重要性。因此,我们去掉了LocalAgg和GlobalSparseAttn,而是使用PVT[56]中引入的空间减少的自注意4,从而产生一个用于局部和全局上下文建模的单独的自注意块。对于LA(LSA),我们只需用[7]中引入的Local-grouped Self-Attention5替换LocalAgg。
(2)在表4b中,我们将默认的采样器(Center)替换为Avg和Max函数,可以分别通过Pytorch[39]中的AvgPool2d()和MaxPool2d()实现。注意,对于这两种情况,内核大小都设置为采样速率。
(3)在表4c中,在w/o LP的情况下,我们将GlobalSparseAttn替换为PVT[56]中的Spatial-Reduce Self-Attention,但与w/o LA不同,我们保留了LocalAgg。对于LP(双线性)的情况,LocalProp被实例化为双线性插值函数(Pytorch中Upsample(mode= '双线性'))。
注意,每个变量的层数被缩减为0.5GFLOPs,以便进行公平比较。
代码地址:
https://github.com/whai362/PVT/blob/v2/classification/pvt v2.py#L54-L126
https://github.com/Meituan-AutoML/Twins/blob/main/gvt.py#L32-L71
A.3 Accuracy-Speed Pareto-Optimal Models
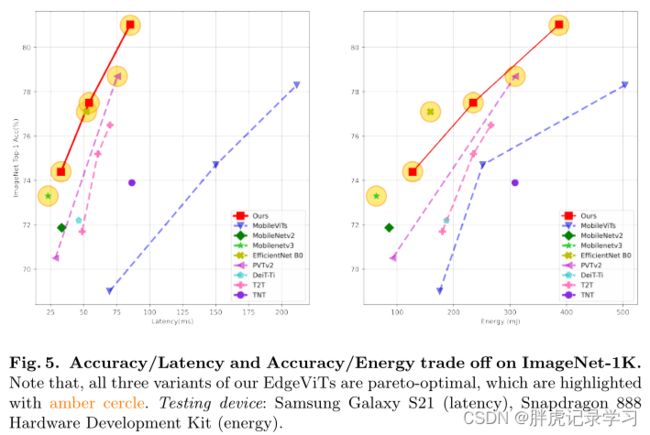
In order to facilitate the Accuracy vs. Speed interpretation. We identify pareto-optimal models when comparing trade-off between accuracy and latency [9]. In our context, the accuracy-latency pareto-optimal models are defined as those upon which no other models can improve in either accuracy or latency without degrading other metrics. As shown in Fig. 1, our EdgeViTs are well comparable with best efficient CNNs [43,22,48], whilst significantly dominating over all prior ViT counterparts. Specifically, EdgeViTs are all pareto-optimal in both trade-offs.
为了便于精确度与速度的解释。当比较准确性和延迟[9]之间的权衡时,我们确定了帕累托最优模型。在我们的环境中,精确度-延迟帕累托最优模型被定义为其他模型无法在不降低其他指标的情况下提高精确度或延迟的模型。如图1所示,我们的EdgeViTs与最高效的CNN相当[43,22,48],同时显著优于所有之前的ViT类型。具体来说,EdgeViT在两种权衡中都是帕累托最优的。