【YOLO】物体识别算法的核心思想
文章目录
- 前言
- 物体检测基础
- YOLO —— 对图像碎片进行物体检测
-
- 检测单个物体
- 同时检测多个物体
- 多边界框的处理 —— IOU方法
- 参考链接
前言
YOLO是目前比较流行的物体检测算法,有着体积小,检测准确度高的强大优点。这里对YOLO的核心思想知识点,使用可视化的方法做一总结。
物体检测基础
YOLO是用于识别图像中的物体的网络。这类网络解决的问题通常是找到图片中是否存在某种物体(如是否有狗或人),以及找到物体在图片中的位置并标记出来(如使用红色方框标记物体)。
比如,对于一个检测图片中人和狗的网络来说,在神经网络的输出端,需要表达两类信息:
-
某物体是否存在于图片中。通常会使用数字
0、1来分别表示目标物体不存在、目标物体存在。
-
如果目标物体存在,目标物体在图片中的位置。YOLO使用
物体的中心坐标和物体的长、宽来表示。

YOLO —— 对图像碎片进行物体检测
YOLO作为一个图像物体检测算法,输出一个向量来表示图像中目标物体的信息

P c P_c Pc:图像中是否不存在任何目标物体,1代表存在,0代表完全不存在
B x B_x Bx:目标物体几何中心的横坐标
B y B_y By:目标物体几何中心的纵坐标
B w B_w Bw:目标物体的宽度
B h B_h Bh:目标物体的高度
C 1 C_1 C1:是否存在类别1的物体(狗)
C 2 C_2 C2:是否存在类别2的物体(人)
检测单个物体
比如,将下面的图片传入训练好的YOLO网络,就会得到这样的一个向量。根据这个向量标出对应的物体中心和方形轮廓,就会得我们想要的结果。
当图片中没有任何目标物体时, P c P_c Pc 的值为0,向量中的其他值就不必理会。

同时检测多个物体
但是如果图中同时有多个目标物体,一个向量不够用怎么办?
直觉性的答案是将原本的 7 ∗ 1 7*1 7∗1 的向量扩大,使之同时包含 n n n 个物体的信息,也就是变成 7 n ∗ 1 7n*1 7n∗1 (形如下图)的格式。
[ P c 1 B x 1 B y 1 B w 1 B h 1 C 11 C 21 . . . . . . . . . P c n B x n B y n B w n B h n C 1 n C 2 n ] \left[ \begin{matrix} P_{c1} \\ B_{x1} \\ B_{y1} \\ B_{w1} \\ B_{h1} \\ C_{11} \\ C_{21} \\ ... \\ ... \\ ... \\ P_{cn} \\ B_{xn} \\ B_{yn} \\ B_{wn} \\ B_{hn} \\ C_{1n} \\ C_{2n} \\ \end{matrix} \right] ⎣ ⎡Pc1Bx1By1Bw1Bh1C11C21.........PcnBxnBynBwnBhnC1nC2n⎦ ⎤
P c k P_{ck} Pck:图像中是否存在第k个目标物体,1代表存在,0代表完全不存在
B x k B_{xk} Bxk:第k个目标物体几何中心的横坐标
B y k B_{yk} Byk:第k个目标物体几何中心的纵坐标
B w k B_{wk} Bwk:第k个目标物体的宽度
B h k B_{hk} Bhk:第k个目标物体的高度
C 1 k C_{1k} C1k:第k个目标物体是否属于类别1(狗)
C 2 k C_{2k} C2k:第k个目标物体是否属于类别2(人)
但由于神经网络的输出结构是固定的,无法灵活的根据情况来自由变动,那么一种简单的解决方法就是让用于表示输出的向量足够大(比如每次检测 10000 10000 10000 个物体,神经网络每次输出一个 70000 ∗ 1 70000*1 70000∗1 的向量)。但是这个方法,对于常见的只有数个目标物体的情况时就会有很大的浪费,而对于个别的出现非常多物体的情况来说又会不够用,适用性非常差。
YOLO所使用的思想的一大杰出之处就是优雅的解决了这个问题。
它将图片分割为数个小的碎片(比如 4 ∗ 4 4*4 4∗4),然后对于每个碎片进行单一物体检测。这样一来,只要切割图像得到的单个碎片足够小,就能够保证每个图像碎片中的目标物体数量足够少(比如只有1~2个)。
这样一来,对于每个图像碎片,我们可以让神经网络只尝试找到固定数量个目标物体即可,神经网络的输出格式就可以固定下来(比如我们设为 16 16 16 个碎片,每个碎片 2 2 2 个目标物体,那么神经网络的输出就是一个 14 ∗ 16 14*16 14∗16 的矩阵)。
下图就是一个例子。(不过值得注意的是,为了便于表示,对目标物体的中心坐标、宽度、高度做了归一化处理,可能与YOLO算法的实际情况不符。其次,对于每个碎片中目标物体的中心坐标,究竟是碎片内的局部目标物体的中心坐标,还是目标物体在没打碎图像前的全局中心坐标,参考资料没讲解清楚,这里存疑。笔者按照局部目标物体的中心坐标的方法进行处理。)
多边界框的处理 —— IOU方法
通过使用上述方法,将目标图片切割成小碎片,然后逐一进行检测,得到的检测结果就是这样一个 7 ∗ 16 7*16 7∗16 的矩阵(这里假设切割图片为 4 ∗ 4 4*4 4∗4 个碎片,每个碎片中只寻找一个物体)。再对输出的结果进行处理,就可以得到目标物体的边界框(下图中用黄色和红色的方框来表示),以及这些边界框的精确度(下图中用每个方框边角的黑色数字来表示)。
但是目标检测问题中,经常会遇见的问题是出现多个边界框,都画出来的话显然会造成混乱:这么多个边界框对应的究竟是几个目标物体?对于某个目标物体来说,哪个边界框属于它?对应某一目标物体的多个边界框中,哪个最精确?
该如何选择边界框呢?
一种直觉性的方法是保留准确度最大的边界框。但是这个方法的问题是,只会保留 1 1 1 个边界框用于标出图像中狗的位置、 1 1 1 个边界框用于标出图像中人的位置。但如果图像中有多个同类目标物体,就会丢失信息了,导致无法接受的偏差。我们需要更好的方法。
这一问题的常用解法是利用IOU(交并比)判断两个边界框是否属于同一物体。计算方法是,对于任意两个边框,用二者重叠部分(交集)的面积,除以二者合并起来(并集)的面积,得到一个比值。图像化公式见下图
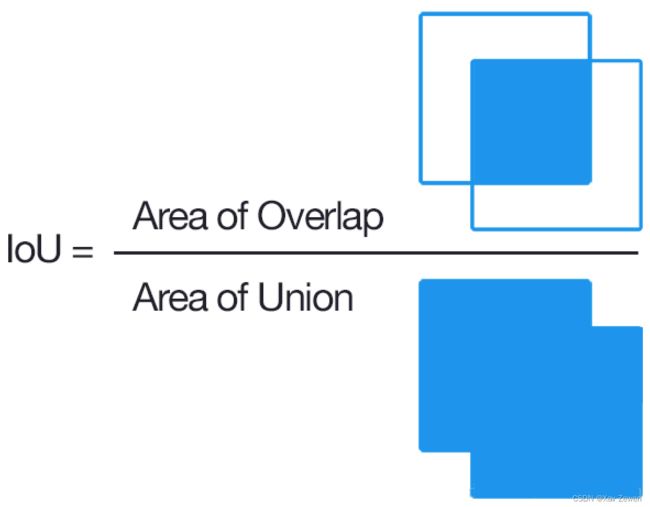
通常我们会设定一个阈值,当IOU超过这个阈值,就判断两个边框属于同一个物体。这样一来,就能首先确定每个目标物体对应那些边界框,随后再借助每个边界框所对应的精确度,找出属于每个目标物体的最精确的边界框。(利用这种方法而非粗暴的找全局最大值,从而提高物体检测精确度的方法,被称为Non maximum suppression,非极大值抑制)
参考链接
https://www.youtube.com/watch?v=ag3DLKsl2vk
https://www.cnblogs.com/happyamyhope/p/9629358.html
https://zhuanlan.zhihu.com/p/37489043