Let Images Give You More
-
目录
背景
知识蒸馏
方法
网络架构
算法步骤
Learning Image Priors
Cross-Modal Point Generator
Image Priors Assisted Training
Classifier Loss
Feature Enhancement Loss
Classifier Enhancement Loss
Final Loss
实验
Classification on ModelNet40
Classification on ScanObjectNN
Part Segmentation on ShapeNet
总结
引用
-
背景
作者认为单纯从点云上提取特征(单模态)已经达到瓶颈,应该从多模态入手(例如点云的渲染图),而这个方法先前也有人做过,但都有一个缺点——不仅在训练过程需要图片,推理过程同样需要图片作为输入,于是作者认为这是不合理的,于是就想仅在训练时用起多模态,而推理过程仍然只需要输入点云即可,受知识蒸馏启发,作者提出了PointCMT。在此之前,先来了解一下什么叫知识蒸馏,这里考虑其最简单的基本思想,其它多种变体有兴趣可以自行了解。
-
知识蒸馏
先看其基本架构

这里对原图做了些许改进(说明了输入是同一分布的,模型具体长什么样不用管,黑匣子完事了)。可以看到,整体包含一个蓝色的Teacher model以及绿色的Student model(顾名思义Teacher是学识渊博的,即一个预训练好而且规模较大的;相反Student是一个等着老师教的,即待学习,规模较小的)。可以看到,这里值得注意的有两个地方:
(1)softmax多了一个参数T。
(2)除了平时和label之间的Loss,还有一个和老师输出的做Loss。
下面分别讲解:
带有参数T的softmax:上公式
![]()
相当于就是每项除了一个T,再看随着T变化,输出会有什么变化
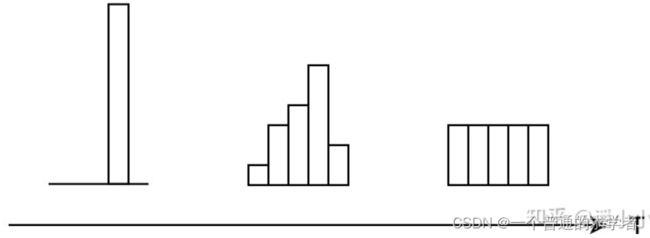
这是一个one hot vec,T=1时候就是平常的softmax,随着t增大,标签值会被慢慢拉下来,而其他会被慢慢拉高,当T趋于无穷时候每个都相等。所以前文的soft就是T>1时候的输出,而hard就是T=1时候的输出。那这有什么用呢?别急。
Teacher的作用
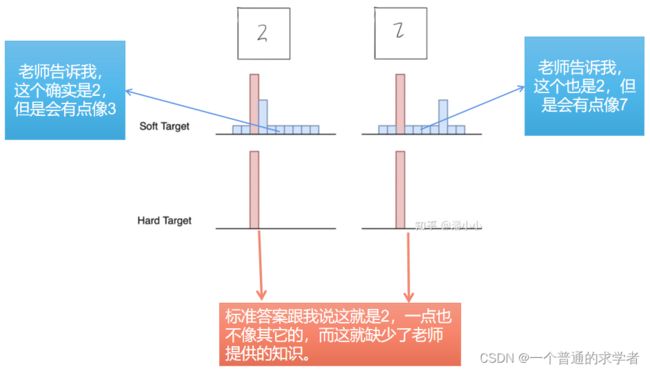
这个图依旧是加了点东西的,看上面,非常简介易懂。看回那个T,T越大,说明我越要模型去关注负标签,这个自然就是一个自己控制的超参了。因为T叫温度系数,所以高温蒸馏,也是顾名思义,T取大点。
为什么要知识蒸馏?在基本架构那里说过,Teacher是一个规模大精度高的模型,Student是一个待学习的小规模模型,所以知识蒸馏作用就是压缩模型,训练时可以搞大模型,但是在推理时用小模型,说白了就是叫一个学识渊博的老师先教他,考试时候还得是学生,知识蒸馏,老师把知识提取出来给学生。
-
方法
可以先看看PointCMT的properties
- 通用性:PointCMT可以用在任何一个网络,即使在网络不做结构上的改变时。
- 有效性:用了PointCMT,其精度确实提升了。
- 高效性:训练要图片,推理不需要。
- 灵活性:图片不是彩色或者其它什么专门渲染的也可以。
-
网络架构
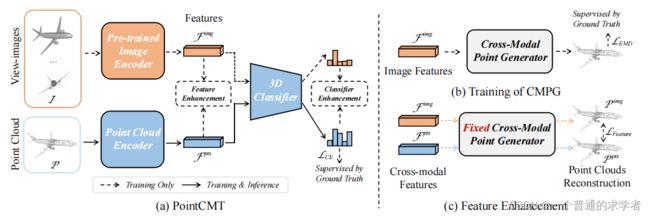
主要三个小板块,PointCMT,CMPG以及Feature Enhancement。先说一下整体(左到右,假设我不了解具体算法的情况下):单看网络架构,很明显,ImgEncoder是一个预训练好的(前面的Teacher),PCEncoder是待学习的(前面的Student),两个的输出(只有一个维度的全局特征),做了一个叫Feature Enhancement的东西,感觉上是要同一个点云模型两个Net输出尽可能相似(这不就有点像之前那篇Cross Point吗???)。再看,3D Classifier,肯定是一个全连接层,用来做任务头的。最后又来个Classifier Enhancement,噢,这不就是前面说的知识蒸馏模型那里老师要给学生蒸馏知识那一步嘛,可是为什么都是同一个3D Classifier,不应该各自输出吗?继续往右看,CMPG,有个Generator,输出又是一个点云模型,还和Ground Truth做对比,噢,非常明显,这就是一个利用前面的Img全局特征来重构点云。下一个,Feature Enhancement,更明显,Fixed了的重构器(固定参数,变成不可学习的),两个全局特征都拿来重构,比一下你两重构出来的像不像。好了,正式看算法。
算法步骤
这里说一下整个网络是怎么运转的,主要分为三个步骤
- 先训练Image Network,就是得到Teacher,ImgEncoder+ImgClassifier(这不是3D Classifier)。
- 训练CMPG,得到根据全局特征生成点云的重构器。
- 拿前面两个,ImageNet以及CMPG正式训练学生。
下面分别对应这三个步骤详细说明。
Learning Image Priors
这里非常简单,就是训练一个CNN嘛,具体呢,作者就是用ImageNet数据集训练ResNet-18。
Cross-Modal Point Generator

这里是利用点云图片的全局特征(因为前面已经训练好了一个ImageNet)来训练一个生成器,label就是这个点云,Loss是一个叫推土机距离的东西,具体就不展开说了,因为我没深入学习重构生成方面(哈哈)。具体呢,网络就是一个三层的MLP,没错,就这么简单,下一个。
Image Priors Assisted Training
这一步是正式训练点云模型了。首先,这里要根据3个Loss分三部分,Classifier Loss、Feature Enhancement Loss以及Classifier Enhancement Loss,都是利用前面得到的(与训练好了,在这一步会把参数固定住)来正式训练学生。
Classifier Loss
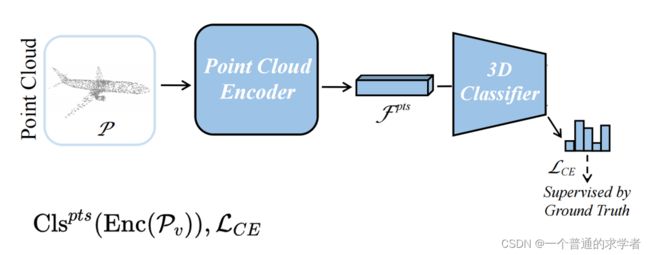
这里其实 就是很常规的训练点云模型,和label做交叉熵,因此那个3D Classifier其实就是点云模型后面的全连接层,前面的PCEncoder就是比较重点的东西。说白了这就是前面Student model和hard label做Loss的部分。
Feature Enhancement Loss
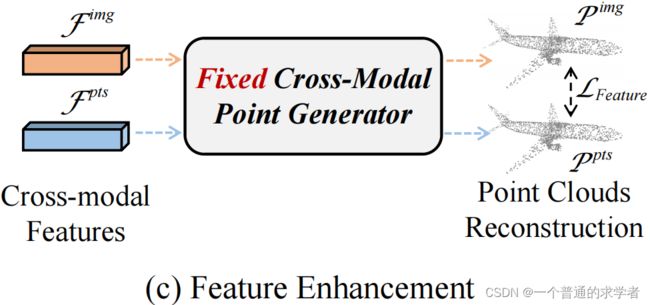
这里是利用第二步骤得到的重构器,在这一步骤中固定参数,把两个全局特征都往里丢,得到的重构点云做一个Loss,这里有一个问题需要思考,那就是为什么要这么做?直接拿两个全局特征做对比不就完事了。不不不,两个模型训练时输入天差地别,你要说Cross Point那个,图片训练也用点云渲染图,两个全局特征相似还情有可原,但这里用的是ImageNet数据集训练出来的Image Network,即使现在是点云图片,但此时点云图片和点云的全局特征也会天差地别,这里利用一个重构器把他们先重构,转换到欧式空间再来对比,就可以不需要两个全局特征相似,重构相似即可。最后Loss同样是一个推土机距离。
Classifier Enhancement Loss
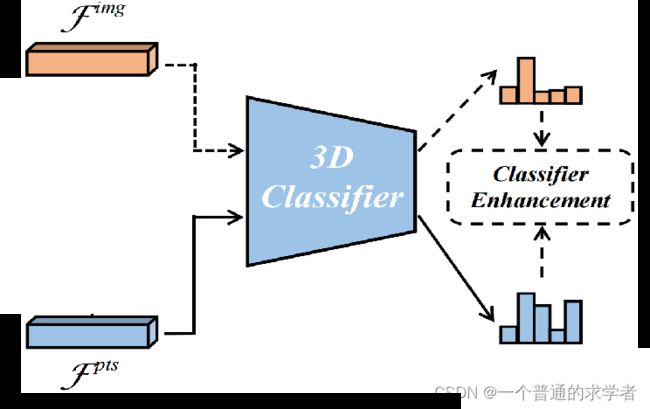
前面说过了,这个3D Classifier是点云后的全连接层,那么问题来了,为什么不用各自的Classifier,都往点云的Classifier丢。这同样是因为,前面训练Image Network所用数据集,ImageNet数据集,分类数都不一样,自然后面的Classifier不能用了。还有一个问题,这一步干嘛了,说是知识蒸馏,但是也没看见温度系数T的应用,这个确实没用到,但是作者在这里用了KL散度作为Loss(KL散度=交叉熵-信息熵,特别的,对于一个Label来说,信息熵是常数,所以两个导数没区别,但在这里,里面包含Classifier里的可学习参数,就不是常数了),公式如下:

就是图像端的输出与点云端输出的KL散度,也可以说图像端输出与点云点输出的交叉熵-图像端的信息熵。作者说这个Loss是起一个增强作用。
Final Loss
因此最终的Loss就是:

依次为与标签的交叉熵、重构点云的推土机距离、教师与学生之间的KL散度。而重构点云那里权重非常大,KL散度那里又非常小,可能都没起太大作用,大部分在全局特征Encoder那边。
-
实验
下面看一下实验,常规的分类,分割
Classification on ModelNet40

效果还是不错的 ,据我所知SOTA是94.7,这篇达到了94.4,不过反倒是PointMLP挺亮眼。而PoinMLP仅仅是引入了残差块的纯MLP网络,但是效果非常不俗,估计参数量大是缺点吧。
Classification on ScanObjectNN
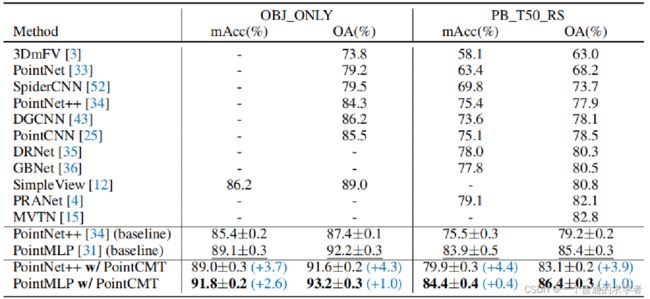
这是在ScanObjectNN数据集上的分类结果,效果不错。顺带一提,这个数据集有五种格式,对应五个难度,上面的OBJ_ONLY就是最简单,PT_T50_RS就是最难的。
Part Segmentation on ShapeNet

这是部件分割,藏在附录了中,估计是效果一般,就没展示了。
总结
这篇文章出发点还是不错的,实现起来也不难,利用知识蒸馏也挺新颖,最重要的是在分类任务上效果也可以。但是本文并没有跑语义分割,有可能室内大型场景不好渲染图片,在部件分割上的效果一般。纵观整个网络结构,不难发现,其实原本的模型并没有任何改变(也就是前面说的通用性),模型决定性能上限,这种基于“引导式”的训练方法(推理过程不需要图片),可能也只是逼近模型的上限。本次分享到此结束,如有不对的地方还请指正。
引用
[1] 【经典简读】知识蒸馏(Knowledge Distillation) 经典之作
[2] Let Images Give You More: Point Cloud Cross-Modal Training for Shape Analysis