AI模型的大一统!多模态领域乱杀的十二边形战士
作者丨战斗系牧师@知乎
来源丨https://zhuanlan.zhihu.com/p/558533740
编辑丨极市平台
说在前面的话(有点小长,可以直接跳过的)
期待
在Swin-v2出来不久之后,我预感一个很棒的大一统模型很快就会到来了,当时,我躺在床上,给我的好伙伴写下了必胜的AI模型配方!
大数据量+大模型架构+MAE(mask data)+多模态训练方式
写下这条配方时候我其实就觉得下一个无敌的模型估计很快就可以出现了。没想到,学都还没有开,BEIT-3就迎面向我们走来了。一个能在多模态领域乱杀的无敌十二边形战士,在纯视觉领域都能是妥妥的SOTA。一个真正做到了大一统的模型框架!
疲惫
但是经过这么多轮的,大模型的轰炸。其实人工智能组成的中坚力量(实验室小作坊们)已经没有办法顶得住这些核弹的压力了。这么大的模型,这么庞大的训练量,效果再炸裂又能怎样,我又复现不出来。 这种声音成为了现在开发者们的主流心声。大家都疲惫了,这种工作再棒其实也是无效工作,follow的成本太高了。那么这时候很又前瞻性的研究员们就要站出来抵抗了,问出那个最知乎的问题,那有没有大模型有没有不能覆盖到的方向呢?”核弹“到底有没有炸不到的点呢?
其实是有的,不如我先BEIT-3的工作内容大概内容和大家讲一遍,然后慢慢和大家分析有没有这个答案吧!
为什么会有这样的一个工作?
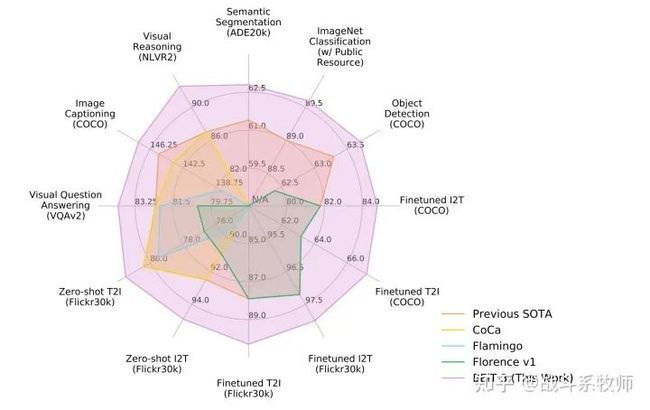
其实先当前的大一统的思路其实很清晰。发展的方向也是主要主要沿着以下三点进行更新迭代,合适的骨干架构、各任务的预训练模型、大参数量的模型架构。 本文的BEIT-3也是顺着这个思路对模型进行迭代的,不仅在图像+语言的方向取得SOTA,甚至在纯图像领域,也是一马当先,把分数又往前卷了一步!其实我觉得ADE20k超过了大杀器Swin-V2、在coco上虽然不是涨点很多,但是也破了DINO的记录,在图像分类任务上也击败了我的白月光CLIP,涨了0.6个点,这个可是真正无敌的存在。
合适的骨干架构—Multiway Transformer
从Transformer在语言翻译上的大获成功,再到ViT在视觉领域上的大放异彩,Transformer架构已经成为了视觉、语言通用的大杀器。对于多模态来说,有一个能够在语言和视觉同时work的网络架构体系,使得无缝处理多种模态的任务成为可能。但是因为视觉和语言毕竟不是一个体系的数据类型,一般来说未来适配不同的下游任务,我们都会重新设计Transformer架构。这种方案其实不利于大一统的思路发展,所以我们需要有一个整体化的架构范式,帮助我们完成大一统的理想。

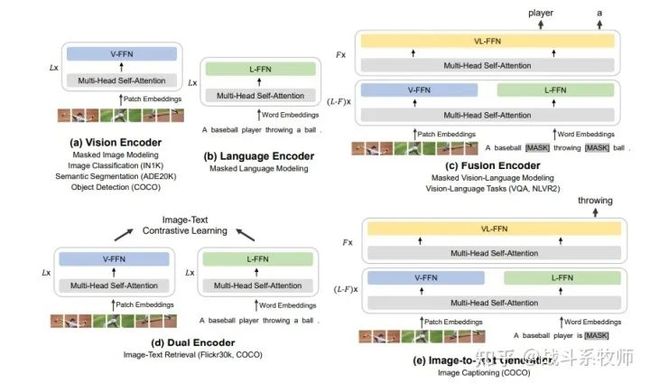
其实不同的任务能不能集成在一个框架,其实有几种的思考模式,比如第一种,弱联系框架。多分支独立进行特征提取工作,最后只借助loss函数回归彼此的信息,完成信息交互。但是这样的操作其实无法做到充分的信息共享,而且参数没有办法有效地跨模态共享,所以一个大一统多模态框架需要满足信息共享、信息交互的两个特点。考虑到Transformer整体架构的特性,这项工作中使用Multiway transformer作为骨干模型来编码不同的模态。上图所示,每个Multiway Transformer模块由一个共享的自注意模块和一组用于不同模态的前馈网络(即单一模态专家)组成。我们根据每个输入类型,将其转化为token的形式输入到给各个模态的支路当中。 在我们的实现中,每一层都包含一个视觉支路和一个语言支路。
此外,在前三层还有为融合多模态数据而设计的视觉-语言融合支路。以获得更详细的全局特征信息。通过共享自注意模块学习到的不同特征,并对不同模态之间特征一一对齐,使得多模态(如视觉-语言)任务信息融合得更加紧密。与各自为营的集成化的多模态模型相比,大一统体系结构的BEIT-3能够支持更广泛的下游任务。例如,BEIT-3可以用作各种视觉任务的图像主干,包括图像分类、目标检测、实例分割和语义分割。它还可以通过微调,转化为一个有效的图像-文本检索双编码器,以及多模态的推理任务和视频理解任务。
 一个模型可以同时满足abcde个心愿!
一个模型可以同时满足abcde个心愿!
Masked Data modeling自监督学习
基于掩码数据的训练方法已经成功的运用在各个任务上。无论是及BEIT还是MAE,这种掩码的自监督的学习方法都让模型变得更加的鲁棒!我们通过统一的mask data的模式下在单模态(即图像或者文本)和多模态(即图像+文本)数据上对BEIT-3进行进一步的训练。
在预训练过程中,我们随机屏蔽一定比例的文本标记或给图像数据加上补丁,并通过模型的训练使其达到恢复屏蔽标记的能力。这种做法其实已经在早期的BEIT实验中取得了成功,MAE也在最近的CVPR上大放异彩。那么我们的多模态的信息还原其实也是如此。不仅能学习各自模态的表征信息,而且还可以通过这种方式学习到不同模态之间的对齐。具体地说,文本数据通过SentencePiece标记器进行标记。图像数据则通过BEIT-v2 的tokener将其转化为token,并将这里离散的图像信息作为重构的对象,以此来增强不同模态之间的理解,对齐两种模态的信息。
在实验中BEIT-3随机屏蔽15%的单模文本的标记和50%的图像-文本对的文本标记。对于图像,我们使用像BEIT中那样的block-wise级别的掩膜策略来遮蔽40%的图像补丁。我们只使用一个预训练的模型,来与之前的工作进行更明显的训练效果对比。相比之下,以往的视觉-语言多模态模型通常采用多种预训练任务,如图像-文本对比,图文匹配,我们证明了一个更小的预训练模型,更小的batch size也可以用于自监督的图像恢复的训练任务。
基于对比学习的方法通常需要非常大的批规模进行预训练,这带来了更多的工程挑战,比如烧卡!烧GPU!
其实这里我想说的是CLIP,其实CLIP的效果确实非常炸裂,而且zero-short的特点也具有足够的卖点。但是确实强大的预训练模型就是CLIP狂妄的资本,如果脱离了预训练与数据的支撑,CLIP的思路是无法有效work的,从CLIP在MNIST数字识别的数据集上的效果我们大概也知道这种情况了。强大的预训练与数据集其实终究是饮鸠止渴,在强大的模型架构才是发展的第一顺位!
大模型,大爆炸
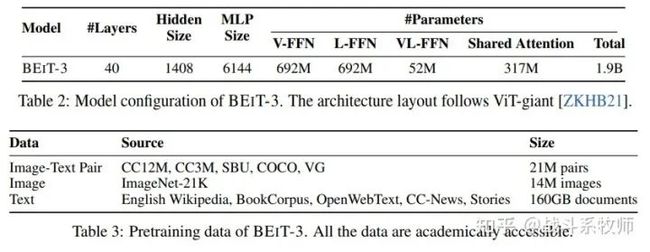
BEIT-3骨干网是继ViT-giant之后建立的一个巨型基础模型。所示,该模型由一个40层的Multiway Transformer组成,其中隐藏尺寸为1408,中间尺寸为6144,注意力头为16。每一层都包含视觉支路和语言支路。视觉-语言支路也被在前三个Multiway Transformer层。自注意机制模块也在不同的模态中参与共享。
BEIT-3共包含1.9Billion参数,其中视觉专家参数692M,语言专家参数692M,视觉语言专家参数52M,共享自注意模块参数317M。
当和ViT-giant使用形同的图像尺度时会有1B的参数量被激活。
BEIT-3下表所示的单模态和多模态数据进行了训练。对于多模态数据,大约有15M幅图像和21M幅文本对,收集自五个公共数据集:Conceptual 12M (CC12M), Conceptual Captions (CC3M) , SBU Captions (SBU) , COCO和Visual Genome (VG) 。
 模型参数+训练数据参数
模型参数+训练数据参数
对于图像和文本的单模态数据,我们使用来自ImageNet-21K的14M图像和Wikipedia、BookCorpus 、OpenWebText3、CC-News和Stories的160GB英文文本语料库。我们预训练BEIT-3为1M步。每个batch共包含6144个样本,其中图像2048张,文本2048张,图文对2048对。我们的模型训练的时候batch要比对比学习的模型小很多。
文章的总结
在本文中,提出了BEIT-3,一个通用的多模态基础模型,它在广泛的视觉和视觉语言基准上实现了最先进的性能。
BEIT-3的核心思想是将图像也理解为一种外语,这样我们就可以对图像、文本以及图像-文本对进行统一的mask-data的“语言”建模。
还展示了Multiway transformer可以有效地为帮助不同的视觉和视觉-语言任务进行模型的学习。
相比于其他的多模态的工作,BEIT-3要显得简单有效,是扩大多模态基础模型的一个有前途的方向。
在未来的工作中,BEIT团队正在对BEIT-3进行多语言的预训练模型的构建工作,并在BEIT-3中加入更多的模态信息(如音频),以促进大一统的任务更够更加的统一。
我的总结
其实没有读这篇文章之前,我只是觉得我戏谑的配方竟然真的成为了一个推动大一统工作的一个方向,这其实让我对这篇工作的期待度并没有很高。但是仔细阅读之后,其实我觉得BEIT-3给了我很多的思考。原来结构真的可以不必如此复杂,利用数据量+自监督+大参数量模型是真的可以做到一个很棒的效果。其实在VIT-MLP出来的时候,我觉得数据才是王道,在CLIP出来的时候我觉得预训练模型才是王道,在Swin-T和ConvNext出来之后我一直都觉得其实架构才是王道,到MAE出来的时候,我觉得训练方式才是王道。其实我一直都没有很能get到能够影响CV模型精度的到底是什么。好在,看了文章之后我起码知道了CLIP是错的。这也算是没有白看这篇论文~
回到我刚开始埋下来的坑中,那到底啥才是核弹炸不到的地方呢?其实答案很简单,我们回到数据本身,其实如果这个模态之间没有必然的联系和规律,自然这种方法就无法有效的捕捉模态之间的特征,退化为单一模态的样式了。我再举个例子,如果两个模态的信息不是一一对齐,而是相互互补的呢?这种多路的注意力同就肯定无法合理化的进行特征相互的补充了。
我觉得我们对于大模型的探索会一直继续,一直未完待续的!所以写这篇知乎的时候我人还在吃Pizza,我的钱包也因为假期的挥霍所剩无几了,所以其实吃完Pizza的我要继续的写文章了,真的是不知道啥时候才能休息一会儿啊!

推荐阅读
西电IEEE Fellow团队出品!最新《Transformer视觉表征学习全面综述》
润了!大龄码农从北京到荷兰的躺平生活(文末有福利哟!)
如何做好科研?这份《科研阅读、写作与报告》PPT,手把手教你做科研
一位博士在华为的22年
奖金675万!3位科学家,斩获“中国诺贝尔奖”!
又一名视觉大牛从大厂离开!阿里达摩院 XR 实验室负责人谭平离职
最新 2022「深度学习视觉注意力 」研究概述,包括50种注意力机制和方法!
【重磅】斯坦福李飞飞《注意力与Transformer》总结,84页ppt开放下载!
2021李宏毅老师最新40节机器学习课程!附课件+视频资料
欢迎大家加入DLer-计算机视觉技术交流群!
大家好,群里会第一时间发布计算机视觉方向的前沿论文解读和交流分享,主要方向有:图像分类、Transformer、目标检测、目标跟踪、点云与语义分割、GAN、超分辨率、人脸检测与识别、动作行为与时空运动、模型压缩和量化剪枝、迁移学习、人体姿态估计等内容。
进群请备注:研究方向+学校/公司+昵称(如图像分类+上交+小明)

长按识别,邀请您进群!