python之dict1——创建与序列: dataframe转dict; 直接编写创建dict;dict序列问题,创建为空值的dict
- 读取dict
以dataframe的形式从csv中读取,再转为dict比较容易整理。
(1)df.to_dict() / df.to_dict("dict") 在dict里面再套dict,最外面的键为列名。
不过需要注意的是:dict没有重复的键,如果有重复的index,需要注意别漏了。
比如这种情况:
df = pd.DataFrame({ 'col1': [1, 2, 3], 'col2': [0.5, 0.75, 0.2]}, index=['row1', 'row2', 'row2'])
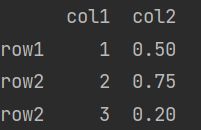
df.to_dict()
![]()
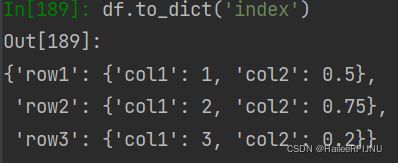
(2) df.to_dict('index')
如果index不是唯一的,这个就会报错。让我们试试全部唯一的dataframe,这个是不是正好和“dict”的互补?这个是以row作为外键。
df = pd.DataFrame({ 'col1': [1, 2, 3], 'col2': [0.5, 0.75, 0.2]}, index=['row1', 'row2', 'row3'])
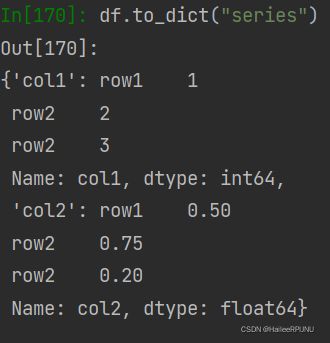
(3)df.to_dict("series") 在df里面套series
可保留重复的index,但是不可以有重复的列名,当然,如果列名重复,在dataframe中就没法出现了。
(4)df.to_dict('records')
将index省略,这样即使有重复的index也没问题了。
![]()
(5) df.to_dict('split')
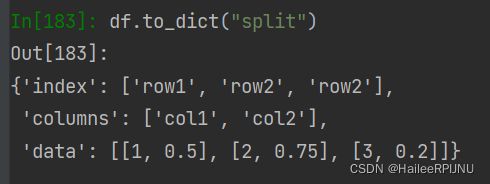
将dict进行拆分,可以方便地得到data、columns和index

2. dict里的序列
有人会担心dict里面的序列会不会乱,ordereddict可以避免这个问题。根据python官方文档, python3.6及之后Dict就都有序了。OrderedDict变得不那么重要了
from collections import OrderedDict
df.to_dict(into=OrderedDict)

3. 如何创造dict
(1)直接
a = dict(one=1, two=2, three=3)
b = {'one': 1, 'two': 2, 'three': 3}
c = dict(zip(['one', 'two', 'three'], [1, 2, 3]))
d = dict([('two', 2), ('one', 1), ('three', 3)])
e = dict({'three': 3, 'one': 1, 'two': 2})
(2)fromkeys
dict. fromkeys(keys, value) : 将键和值代入新字典
keys:必须,指定字典的键
value:可选,所有键的值
x =[ 'key1', 'key2', 'key3']
dict.fromkeys(x)
