神经网络预测未来人口数量
以 1953 年、1964 年、1982 年、1990 年、2000 年、2010 年和 2020 年进行过的七次全国人口普查总人数为基础,再从国家统计局网站(国家统计局>>统计数据)获取从 1949 年到 2020 年的数据。本文采用 pandas 库对相关数据进行处理,使用 pytorch 框架搭建神经网络预测 2030 年全国人口普查总人数。
为方便演示,本例子选择考虑“人均 GDP ”和“受教育年限”作为影响总人口数的两个特征。观察数据,图左 为 1949-2020 年历年总人口数据,图中 为 1989-2017 年人均 GDP,图右 为 1989-2017 年人均受教育年限。

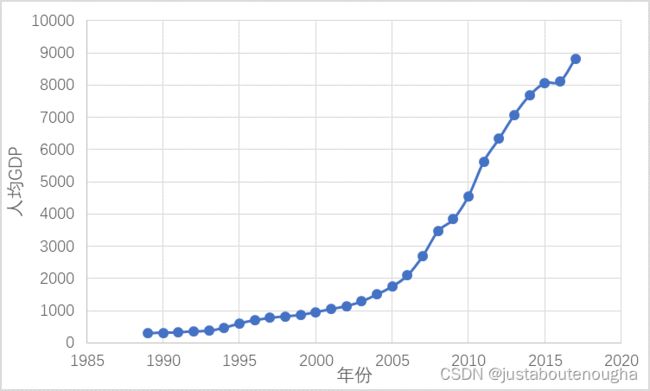

计算历年人口数量与人均GDP、人均受教育年限的皮尔逊相关系数判断其中的相关性。
| 年份 | GDP | 受教育年限 | |
|---|---|---|---|
| 年份 | 1.000000 | 0.912819 | 0.939085 |
| GDP | 0.912819 | 1.000000 | 0.885052 |
| 受教育年限 | 0.939085 | 0.885052 | 1.000000 |
如表中相关系数可知,人口数量与人均GDP、人口数量与人均受教育年限都具有相关性,因此可以使用人均GDP和人均受教育年限作为影响人口数量的因素。
观察一下表格数据,分别为历年总人口部分数据、人均 GDP ”和“受教育年限部分数据和 test 数据。接下来对数据进行处理以及人口预测。



(一)处理.xlsx文件数据
提取 .xlsx文件数据。
import pandas as pd
people_num_path ='./dataset_3/全国人口数量.xlsx'
people_num = pd.read_excel(people_num_path)
gpu_edu_path = './dataset_3/GDP_受教育年限.xlsx'
gpu_edu = pd.read_excel(gpu_edu_path)
test_data_path = './dataset_3/test.xlsx'
test = pd.read_excel(test_data_path)“总人口”数据多于“人均 GDP ”和“受教育年限”数据,对大段连续缺失的数据,采取删除含有缺失值的样本,本例中将保留 1989-2017 年数据,并把全国人口数量.xlsx与GDP_受教育年限.xlsx整合。
train = pd.merge(gpu_edu, people_num, on='年份')
# print(train) # 查看整合后数据将 “总人口”作为要拟合的目标值,并在表格中将其删除,只保留输入特征。为了增强测试数据的预测效果,将 test.xlsx 与 train 合并。
# 整合数据
train = pd.merge(gpu_edu, people_num, on='年份')
# print(train) # 查看整合后数据
# 总人口,要拟合的目标值
target = train['总人口']
# 输入特征
train.drop(['总人口'],axis = 1 , inplace = True)
# print(train) # 查看输入特征
num_of_train = train.shape[0]
# 将train与test整合到一起,方便预测test的总人口
combined = train.append(test).reset_index(drop=True)
# print(combined) # 查看整合后的输入特征若输入特征中有空列,则删除空列,保留非空列。
# 选出非空列
def get_cols_with_no_nans(df,col_type):
'''
Arguments :
df : The dataframe to process
col_type :
num : to only get numerical columns with no nans
no_num : to only get nun-numerical columns with no nans
all : to get any columns with no nans
'''
if (col_type == 'num'):
trains = df.select_dtypes(exclude=['object'])
elif (col_type == 'no_num'):
trains = df.select_dtypes(include=['object'])
elif (col_type == 'all'):
trains = df
else :
print('Error : choose a type (num, no_num, all)')
return 0
cols_with_no_nans = []
for col in trains.columns:
if not df[col].isnull().any():
cols_with_no_nans.append(col)
return cols_with_no_nans
# 分别对数值特征和分类特征进行处理
num_cols = get_cols_with_no_nans(combined, 'num')
cat_cols = get_cols_with_no_nans(combined, 'no_num')
combined = combined[num_cols + cat_cols]若数据中包含分类特征,需要对分类特征进行 one-hot 编码,转化成能进行模型训练的数值。
def oneHotEncode(df,cat_cols):
for col in cat_cols:
if( df[col].dtype == np.dtype('object')):
dummies = pd.get_dummies(df[col],prefix=col) # pandas.get_dummies 可以对分类特征进行One-Hot编码
df = pd.concat([df,dummies],axis=1)
df.drop([col],axis=1 , inplace=True)
return df
combined = oneHotEncode(combined, cat_cols)(二) 神经网络与预测
再将这些数据转化为 Tensor 形式。
训练数据集特征
train_features = torch.tensor(combined[:num_of_train].values, dtype=torch.float)
# 训练数据集目标
train_labels = torch.tensor(target.values, dtype=torch.float).view(-1, 1)
# 测试数据集特征
test_features = torch.tensor(combined[num_of_train:].values, dtype=torch.float)构建 BP 神经网络,如下图所示。
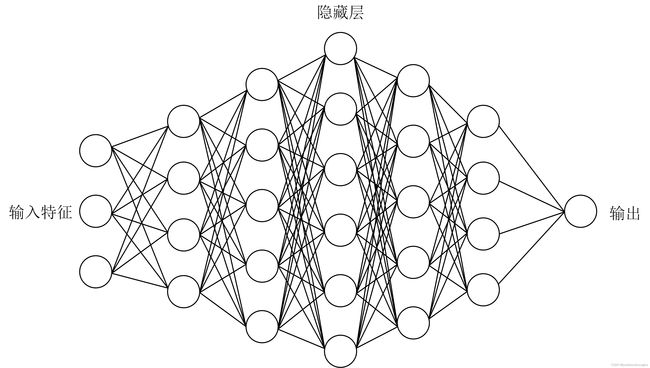
神经网络包含一个输入层、输出层、若干隐藏层。实现代码如下。
class Net(nn.Module):
def __init__(self, features):
super(Net, self).__init__()
self.linear1 = nn.Linear(features, 128)
self.linear2 = nn.Linear(128, 256)
self.linear3 = nn.Linear(256, 512)
self.linear4 = nn.Linear(512, 256)
self.linear5 = nn.Linear(256, 128)
self.linear6 = nn.Linear(128, 1)
def forward(self, x):
y = self.linear1(x)
y = nn.functional.relu(y)
y = self.linear2(y)
y = nn.functional.relu(y)
y = self.linear3(y)
y = nn.functional.relu(y)
y = self.linear4(y)
y = nn.functional.relu(y)
y = self.linear5(y)
y = nn.functional.relu(y)
y = self.linear6(y)
return y
model = Net(features=train_features.shape[1])该模型使用均方差作为损失函数,使用 SGD 优化器训练模型。
# 损失函数
loss = nn.MSELoss(reduction='mean')
# 优化器
optimizer = torch.optim.SGD(model.parameters(), lr=1e-4)使用训练好的模型对 test 数据进行测试,将“年份”与预测人口放到新表格中。
predict = model(test_features).detach().numpy()
result = pd.DataFrame({'年份':pd.read_excel('./dataset_3/test.xlsx')['年份'],'总人口': predictions[:, 0]})
result.to_excel('{}.xlsx'.format('./dataset_3/result'), index=False)预测准确性受多种因素的影响。在特征方面,模型考虑的影响人口的因素越多,预测结果越贴近现实情况。在模型设置方面,受数据量、模型结构、训练轮数(epoch数)、损失函数、学习率、优化器等多种因素影响。训练一个好的模型需要从多方面考虑。
(三) 预测结果

从图中可以看到, 2021 年至 2030 年的全国人口数量的预测情况。预测到 2030 年全国总人口数大概为 144716.5 万人。其中还可以观察到预测未来 10 年人口数量的增长率逐渐降低,人口缓慢增长。
工程代码:CNGMH/population prediction - 码云 - 开源中国 (gitee.com)