PyTorch入门记录
本文是我学习b站up主小土堆的Pytorch入门视频后进行记录,链接https://www.bilibili.com/video/BV1hE411t7RN?p=1
一、Pytorch加载数据
读取数据主要涉及到两个类:Dataset及DataLoader
1.Dataset
首先可以继承torch.utils.data中的Dataset类加载自己的数据集
从pytorch官方源码可以看出,主要包括三个方法__init__、__getitem__和__len__
__init__的目的是得到一个包含数据和标签的list,每个元素能找到图片位置和其对应标签。
__getitem__方法得到每个元素的图像像素矩阵和标签,返回img和label。
__len__方法是得到数据的长度。
class MyData(Dataset):
def __init__(self, root_dir, image_dir, label_dir, transform):
self.root_dir = root_dir
self.image_dir = image_dir
self.label_dir = label_dir
self.label_path = os.path.join(self.root_dir, self.label_dir)
self.image_path = os.path.join(self.root_dir, self.image_dir)
self.image_list = os.listdir(self.image_path)
self.label_list = os.listdir(self.label_path)
self.transform = transform
# 因为label 和 Image文件名相同,进行一样的排序,可以保证取出的数据和label是一一对应的
self.image_list.sort()
self.label_list.sort()
def __getitem__(self, idx):
img_name = self.image_list[idx]
label_name = self.label_list[idx]
img_item_path = os.path.join(self.root_dir, self.image_dir, img_name)
label_item_path = os.path.join(self.root_dir, self.label_dir, label_name)
img = Image.open(img_item_path)
with open(label_item_path, 'r') as f:
label = f.readline()
# img = np.array(img)
img = self.transform(img)
sample = {'img': img, 'label': label}
return sample
def __len__(self):
assert len(self.image_list) == len(self.label_list)
return len(self.image_list)其次,可以用torchvision.dataset加载已有数据集
torchvision.dataset中包含很多数据集,例如COCO、CIFAR、MNIST等
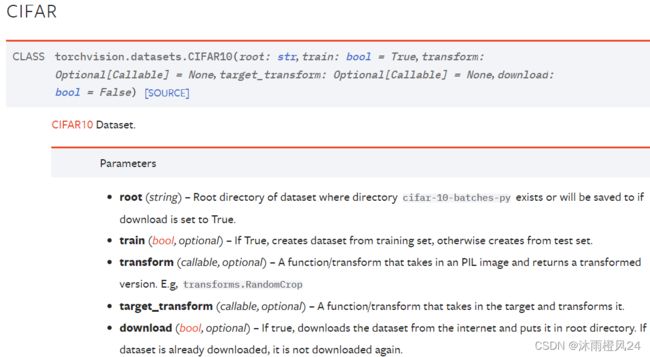
以CIFAR10为例,使用这个数据集需要5个参数
root:就是数据集存放位置。
train:是bool类型,True表示数据集为训练集,False表示为测试集。
transform:对图片进行变换操作,例如裁剪、旋转、改变尺寸或变为tensor数据类型(.ToTensor)等
download:bool类型,True表示需要下载数据集,一般选择True
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=dataset_transform, download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=dataset_transform, download=True)
torch.utils.tensorboard数据可视化
import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=dataset_transform, download=True)
writer = SummaryWriter("CIFAR_Test")
for i in range(10):
img, target = test_set[i]
writer.add_image("test_set", img, i)
writer.close()在tensorboard中就可以看到CIFAR10测试集中的前10张图片,如下图:

2.Dataloader
准备好数据集后,一般使用 torch.utils.data.DataLoader 进行数据的加载

由官方文档可以看到,Dataloader类的使用需要很多参数,其中最常用的是:
dataset:已经准备好的数据集
batch—size:单次训练抓取的样本数量
shuffle:在每个epoch是否打乱抓取图片的顺序,默认为False
num_workers:使用多进程加载,0表示使用主进程加载
drop_last:最后一次抓取数据不够一个batch_size是否舍弃
from torch.utils.data import DataLoader
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)
二、神经网络模型搭建nn.Module
1.卷积层

import torch
from torch import nn
from torch.nn import Conv2d
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
return xin_channels:输入通道数
out_channels:输出通道数
kernel_size:卷积核大小
stride:卷积核移动步长
padding:对输入矩阵增加边界 padding_mode:‘zeros’边界补0
bias:是否加偏置
2.池化层
以最大池化为例

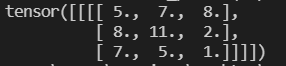
ceil_mode:True类似于向上取整,边界剩余元素也进行最大池化;False则会舍弃边界剩余元素,用代码举个例子:
import torch
input = torch.tensor([[1,2,3,4,5],
[4,5,6,7,8],
[7,8,9,11,2],
[2,4,6,3,2],
[7,3,5,2,1]],dtype=torch.float32)
input = torch.reshape(input,(1,1,5,5))
output = torch.nn.MaxPool2d(kernel_size=2,ceil_mode=True)
output = output(input)
print(output)当设置为True时输出为:
当设置为False时输出为:
![]()
ps:步长大小一般默认等于卷积核大小
3.非线性激活函数
常用的函数一般有Sigmoid函数、Relu函数等
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.relu1 = ReLU()
self.sigmoid1 = Sigmoid()
def forward(self, input):
output = self.sigmoid1(input)
#output = self.relu1(input)
return output4.线性层和其它层
其他层例如Normalization层、Dropout层等未进行详细介绍,具体使用方法依然可以通过官方文档进行查询。
线性层一般表示为![]() ,其每个神经元与上一个层所有神经元相连,实现对前一层的线性组合或线性变换。
,其每个神经元与上一个层所有神经元相连,实现对前一层的线性组合或线性变换。![]()

in_features:输入图像的尺寸
out_features:输出图像的尺寸
bias:是否需要加偏置
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = Linear(128, 10)
def forward(self, input):
output = self.linear1(input)
return output5.损失函数与反向传播
L1Loss:求输入与目标之间差的绝对值
MSELoss:求输入与目标之间差的平方
CrossEntropyLoss:交叉熵损失函数,一般用于分类模型
import torch
from torch import nn
inputs = torch.tensor([1, 4, 6], dtype=torch.float32)
targets = torch.tensor([1, 5, 9], dtype=torch.float32)
inputs = torch.reshape(inputs, (1, 1, 1, 3))
targets = torch.reshape(targets, (1, 1, 1, 3))
loss = nn.L1Loss(reduction='sum')
result = loss(inputs, targets)
loss_mse = nn.MSELoss()
result_mse = loss_mse(inputs, targets)
print(result)
print(result_mse)
x = torch.tensor([0.1, 0.2, 0.3])
y = torch.tensor([1])
x = torch.reshape(x, (1, 3))
loss_cross = nn.CrossEntropyLoss()
result_cross = loss_cross(x, y)
print(result_cross)特别地需要重点关注的是不同损失函数要求的输入输出。
而反向传播就是通过最小化损失函数不断对网络的参数更新。
loss.backward()6.优化器
以SGD为例

params:模型的参数
lr:学习率
optim = torch.optim.SGD(model.parameters(), lr=0.01)
optim.zero_grad() #梯度清零
loss_fn(model(input), target).backward()
optim.step()7.现有网络模型的使用及修改
以VGG16为例
import torchvision
from torch import nn
vgg16_false = torchvision.models.vgg16(pretrained=False)
vgg16_true = torchvision.models.vgg16(pretrained=True)
print(vgg16_true)
#print(vgg16_false)pretrained:True表示模型已经在ImageNet数据集进行预处理
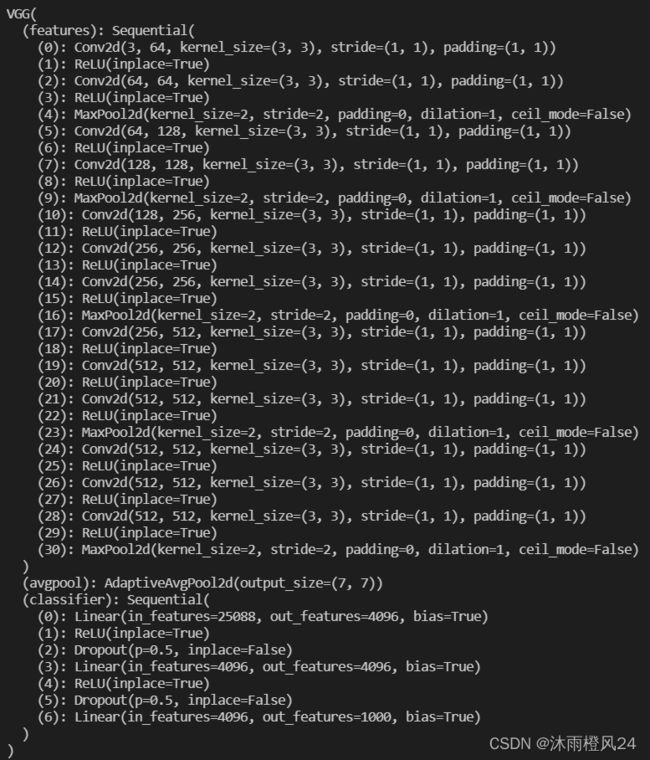
模型修改:如果想在VGG16网络最后加一个线性层
vgg16_true.classifier.add_module('add_linear', nn.Linear(1000, 10))
如果想修改网络结构
vgg16_false.classifier[6] = nn.Linear(4096, 10)
8.模型的保存和读取
模型保存
模型保存一般有两种方式
第一种:保存模型结构+模型参数
torch.save(vgg16, "vgg16_method1.pth")第二种:保存模型参数(官方推荐)
torch.save(vgg16.state_dict(), "vgg16_method2.pth")模型读取
对应模型保存的两种方式,模型读取也有两种方式
第一种:
model = torch.load("vgg16_method1.pth")注意:第一种方法在读取自己的模型时,需要提前从模型文件引入模型的类,否则会报错
from model_save import *第二种:
vgg16 = torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict(torch.load("vgg16_method2.pth"))需要先加载模型,然后将保存的模型参数更新网络
三、完整的模型训练和验证
model.py
# coding=gbk
import torch
from torch import nn
#构建LeNet-5网络
class Model(nn.Module):
def __init__(self):
super(Model,self).__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=6,kernel_size=(5,5),stride=1,padding=0,bias=True),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(6,16,5),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(16*5*5,120),
nn.ReLU(),
nn.Linear(120,84),
nn.ReLU(),
nn.Linear(84,10)
)
def forward(self,x):
x = self.model(x)
return x
#用于测试网络结构的正确性
if __name__ == '__main__':
model = Model()
input = torch.ones((64,3,32,32))
output = model(input)
print(output.shape)构建LeNet-5网络结构,使用CIFAR10数据集进行训练
train.py
# -*-coding:gbk-*-
import torch
from torch import nn, no_grad
import torchvision
from torch.utils.data import DataLoader
from model import *
from torch.utils.tensorboard import SummaryWriter
import time
#定义训练的设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#准备数据集
train_data = torchvision.datasets.CIFAR10('./data',train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10('./data',train=False,transform=torchvision.transforms.ToTensor(),download=True)
train_data_size = len(train_data)
test_data_size = len(test_data)
#使用DataLoader加载数据集
train_dataloader = DataLoader(train_data,batch_size=64,shuffle=True)
test_dataloader = DataLoader(test_data,batch_size=64)
#构建网络结构
LeNet = Model()
LeNet.to(device)
#损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn.to(device)
#优化器
lr = 1e-3
optim = torch.optim.SGD(LeNet.parameters(),lr,momentum=0.9)
#训练次数
train_step = 0
test_step = 0
#训练轮数
epoch = 50
#Tensorboard可视化
writer = SummaryWriter('./log_train')
#开始计时
start_time = time.time()
for i in range(epoch):
print(f'--------------第{i+1}轮训练开始--------------')
#开始训练
LeNet.train()
for data in train_dataloader:
imgs , targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = LeNet(imgs)
loss = loss_fn(outputs,targets)
optim.zero_grad()
loss.backward()
optim.step()
train_step += 1
if (train_step % 100 == 0):
end_time = time.time()
print(end_time - start_time)
print(f"训练次数{train_step},Loss:{loss.item()}")
writer.add_scalar("train_loss",loss.item(),train_step)
#利用测试集评估训练情况
LeNet.eval()
test_loss = 0
accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs , targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = LeNet(imgs)
loss = loss_fn(outputs,targets)
test_loss += loss.item()
accuracy += (outputs.argmax(1) == targets).sum()
print(f"测试集上的Loss:{test_loss}")
print(f"测试集正确率Accuracy:{accuracy / test_data_size}")
writer.add_scalar("test_loss",test_loss,test_step)
writer.add_scalar("test_accuracy",accuracy,test_step)
test_step += 1
#模型保存
torch.save(LeNet,"LeNet.pth")
print("模型已保存")
writer.close()

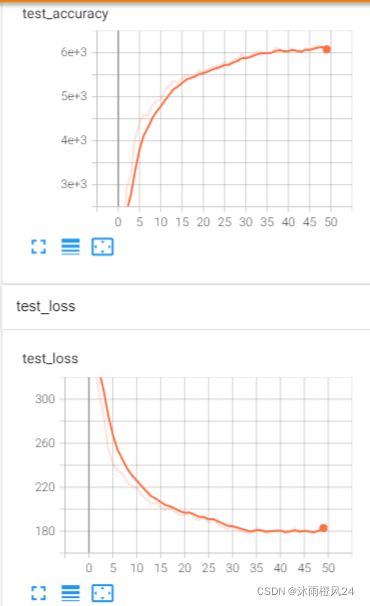
经过50轮的训练,网络在测试集达到60.88%的正确率
test.py
# -*- coding: gbk -*-
import imp
from PIL import Image
import torch
import torchvision
from model import *
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
#image_path = "dog.jpg"
image_path = "airplane.jpg"
img = Image.open(image_path)
#print(image)
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)),
torchvision.transforms.ToTensor()])
image = transform(img)
#print(image.shape)
LeNet = torch.load("LeNet.pth",map_location=torch.device("cpu"))
image = torch.reshape(image,(1,3,32,32))
LeNet.eval()
with torch.no_grad():
output = LeNet(image)
#print(output.argmax(1).item())
label = output.argmax(1).item()
print(classes[label])
img.show()分别使用狗和飞机的图片进行测试,最终网络都正确预测出类别。


![]()
![]()