ROC曲线绘制(详细)以及模型选择
在我们在讲解ROC曲线之前 首先要明确混淆矩阵的概念
如下图:

- 真正率 TPR:预测为正例且实际为正例的样本占所有正例样本(真实结果为正样本)的比例。
- 假正率 FPR:预测为正例但实际为负例的样本占所有负例样本(真实结果为负样本)的比例。
公式:
文章目录
-
- 一 :ROC曲线简介
- 二:ROC曲线的绘制
- 三. 利用ROC曲线选择最佳模型
-
- 不同模型之间选择最优模型
-
- ROC曲线之间没有交点
- ROC曲线之间存在交点
- 同一模型中选择最优点对应的最优模型
- 四.ROC曲线python代码实现
下面进入正题:
一 :ROC曲线简介
来自百度百科解释(讲了半天我也没看懂)
接受者操作特性曲线(receiver operating characteristic curve,简称ROC曲线),又称为感受性曲线(sensitivity curve)。得此名的原因在于曲线上各点反映着相同的感受性,它们都是对同一信号刺激的反应,只不过是在几种不同的判定标准下所得的结果而已。接受者操作特性曲线就是以虚惊概率为横轴,击中概率为纵轴所组成的坐标图,和被试在特定刺激条件下由于采用不同的判断标准得出的不同结果画出的曲线 [1] 。
个人备注:ROC曲线是非常重要和常见的统计分析方法。
首先介绍一下在模型评估上的一些基本概念:

以上这些概念是需要我们熟记于心的。
二:ROC曲线的绘制
举个例子:
如果大家对二值分类模型熟悉的话,都会知道其输出一般都是预测样本为正例的概率,而事实上,ROC曲线正是通过不断移动分类器的“阈值”来生成曲线上的一组关键点的。可能这样讲有点抽象,还是举刚才雷达兵的例子。每一个雷达兵用的都是同一台雷达返回的结果,但是每一个雷达兵内心对其属于敌军轰炸机的判断是不一样的,可能1号兵解析后认为结果大于0.9,就是轰炸机,2号兵解析后认为结果大于0.85,就是轰炸机,依次类推,每一个雷达兵内心都有自己的一个判断标准(也即对应分类器的不同“阈值”),这样针对每一个雷达兵,都能计算出一个ROC曲线上的关键点(一组FPR,TPR值),把大家的点连起来,也就是最早的ROC曲线了。
相信大家还是不太容易理解 那么咱们来举一个现实例子:
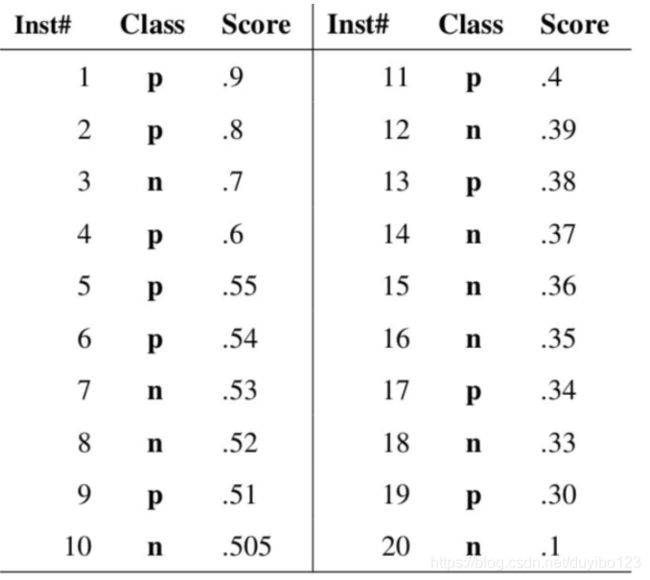
注:概率都是0.9,所有概率都是零点几
现在我们指定一个阈值为0.9,那么只有第一个样本(0.9)会被归类为正例,而其他所有样本都会被归为负例,因此,对于0.9这个阈值,我们可以计算出FPR为0,TPR为0.1(因为总共10个正样本,预测正确的个数为1),那么我们就知道曲线上必有一个点为(0, 0.1)。依次选择不同的阈值(或称为“截断点”),画出全部的关键点以后,再连接关键点即可最终得到ROC曲线如下图所示。

语言文字形容:
ROC曲线的绘制步骤如下:
- 假设已经得出一系列样本被划分为正类的概率Score值,按照大小排序。
- 从高到低,依次将“Score”值作为阈值threshold,当测试样本属于正样本的概率大于或等于这个threshold时,我们认为它为正样本,否则为负样本。举例来说,对于某个样本,其“Score”值为0.6,那么“Score”值大于等于0.6的样本都被认为是正样本,而其他样本则都认为是负样本。
- 每次选取一个不同的threshold,得到一组FPR和TPR,以FPR值为横坐标和TPR值为纵坐标,即ROC曲线上的一点。
- 根据3中的每个坐标点,画图。
三. 利用ROC曲线选择最佳模型
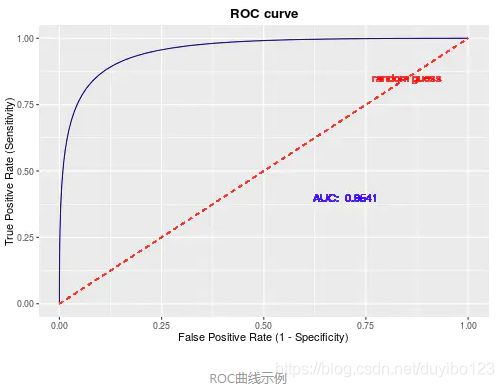
首先了解一下ROC曲线图上很重要的四个点:
- 第一个点( 0 , 1 ) (0,1)(0,1),即FPR=0, TPR=1,这意味着FN(False Negative)=0,并且FP(False Positive)=0。意味着这是一个完美的分类器,它将所有的样本都正确分类。
- 第二个点( 1 , 0 ) (1,0)(1,0),即FPR=1,TPR=0,意味着这是一个糟糕的分类器,因为它成功避开了所有的正确答案。
- 第三个点( 0 , 0 ) (0,0)(0,0),即FPR=TPR=0,即FP(False Positive)=TP(True Positive)=0,可以发现该分类器预测所有的样本都为负样本(Negative)。
- 第四个点( 1 , 1 ) (1,1)(1,1),即FPR=TPR=1,分类器实际上预测所有的样本都为正样本。
从上面给出的四个点可以发现,ROC曲线图中,越靠近(0,1)的点对应的模型分类性能越好,所以,可以确定的是ROC曲线图中的点对应的模型,它们的不同之处仅仅是在分类时选用的阈值(Threshold)不同,每个点所选用的阈值都对应某个样本被预测为正类的概率值
不同模型之间选择最优模型
AUC值:AUC(Area Under Curve)被定义为ROC曲线下与坐标轴围成的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。AUC越接近1.0,检测方法真实性越高;等于0.5时,则真实性最低,无应用价值。
ROC曲线之间没有交点
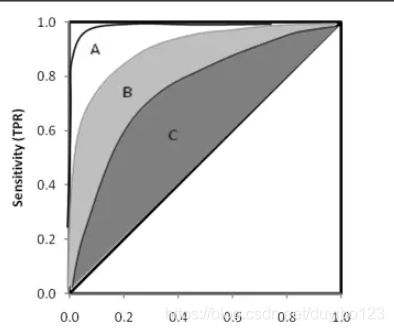
A,B,C三个模型对应的ROC曲线之间交点,且AUC值是不相等的,此时明显更靠近( 0 , 1 ) (0,1)(0,1)点的A模型的分类性能会更好。
ROC曲线之间存在交点
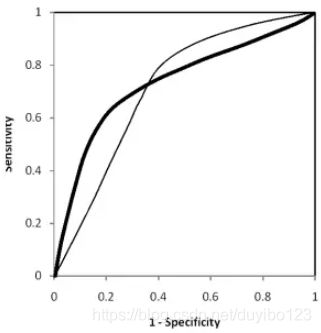
模型A、B对应的ROC曲线相交却AUC值相等,此时就需要具体问题具体分析:当需要高Sensitivity值时,A模型好过B;当需要高Specificity值时,B模型好过A。
同一模型中选择最优点对应的最优模型
我们可以知道,在同一条ROC曲线上,越靠近( 0 , 1 ) (0,1)(0,1)的坐标点对应的模型性能越好,因为此时模型具有较高的真正率和较低的假正率。那么我们如何定量的从一条ROC曲线上找到这个最优的点呢?通常需要借助ISO精度线来找到这个最优的点。
具体的ISO精度线咱们后续再继续深入研究。
四.ROC曲线python代码实现
roc_curve和auc的官方说明教程示例:
from sklearn.metrics import roc_curve, auc
# 数据准备
>>> import numpy as np
>>> from sklearn import metrics
>>> y = np.array([1, 1, 2, 2])
>>> scores = np.array([0.1, 0.4, 0.35, 0.8])
# roc_curve的输入为
# y: 样本标签
# scores: 模型对样本属于正例的概率输出
# pos_label: 标记为正例的标签,本例中标记为2的即为正例
>>> fpr, tpr, thresholds = metrics.roc_curve(y, scores, pos_label=2)
# 假阳性率
>>> fpr
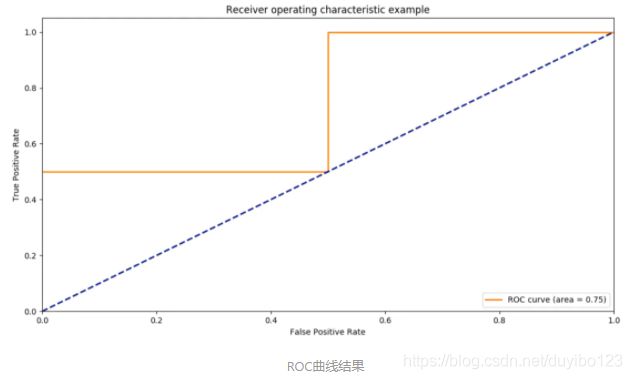
array([ 0. , 0.5, 0.5, 1. ])
# 真阳性率
>>> tpr
array([ 0.5, 0.5, 1. , 1. ])
# 阈值
>>> thresholds
array([ 0.8 , 0.4 , 0.35, 0.1 ])
# auc的输入为很简单,就是fpr, tpr值
>>> auc = metrics.auc(fpr, tpr)
>>> auc
0.75
因此调用完roc_curve以后,我们就齐全了绘制ROC曲线的数据。接下来的事情就很简单了,调用plt即可,还是用官方的代码示例一步到底。
import matplotlib.pyplot as plt
plt.figure()
lw = 2
plt.plot(fpr, tpr, color='darkorange',
lw=lw, label='ROC curve (area = %0.2f)' % auc)
plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic example')
plt.legend(loc="lower right")
plt.show()
最终生成的ROC曲线结果如下图。