TransUNet:Transformers Make Strong Encoders for Medical Image Segmentation用于医疗图像分割的transformers编码器详解
原文地址:https://arxiv.org/pdf/2102.04306.pdf
收录:CVPR 2021
代码: https://github.com/Beckschen/TransUNet
首篇将transformers用于医疗分割的文章
设计的Idea:UNet +transformers的结合体,使用的具体模块:ViT+ResNet50+skip connection
对关键的公式,和结构图进行了个人的一些注释,供大家参考。
目录
摘要
1 Introduction
2.1 CNN-based self-attention methods
2.2 Transformers
3 method
3.1 Transformer as Encoder
3.2 TransUNet
4 Experiments and Discussion
4.1 Dataset and Evaluation
4.2 Implementation Details
4.3 Comparison with State-of-the-arts
4.4 Analytical Study
4.5 Visualizations
4.6 Generalization to Other Dataset
摘要
在医学图像中, U-Net, 已经成为了 de-facto standard 并取得很大的成功。但是它有着缺陷:explicitly modeling long-range dependency 显式建模的长期依赖. Transformers 天生具有全局的self attention机制,但是因为不充足的low-level特征,导致有限的局部定位能力。
本文提出TransUNet,以结合Unet和transformers的优点。一方面,为了提取全局contexts,transformers encodes 来自CNN feature map的标记化图像patches( tokenized image patches)。另一方面,decoder对encoded的特征进行上采样,然后与高分辨率的CNN feature maps结合,以增加局部精度。
TransUNet 取得了巨大的成功在多器官和心脏分割数据集上 multi-organ segmentation and cardiac segmentation。
1 Introduction
我们发现一个有趣的事,如果直接将transformer编码后的输出,直接上采样到原分辨率,这样不能达到满意的分割效果。这是因为transformer专注于在各个阶段对全局context进行建模,因此生成的是缺失细节的局部信息的low -resolution features。然后这种特征不能直接通过上采样,被有效地恢复到 原分辨率,会导致粗糙的分割结果。 另一方面, CNN提供了提取低级的可视化线索,可以补救这些细微的空间细节。
实验证明,Transformer-based architecture 能更好地利用 self-attention (SA) 相比之前的 CNN-based SA methods。此外,我们观察到,更多密集地和low-level特征结合,可以达到更高的分割正确率。
2 related work
2.1 CNN-based self-attention methods
许多的文章基于特征maps,通过对所有像素点的全局交互建模,以试图将SA机制整合到CNN中。 Wang et al. 设计了一个非局部的operator,可以插入多个中间卷积层。Schlemper et al. 基于编码器-解码器 U 形架构,提出 additive attention gate modules ,其被整合到 skip-connections中。与这些方法不同,我们直接采用Transformer来整合全局的SA到我们的方法中。
2.2 Transformers
在许多NLP任务中,首先通过[14]提出了Transformer,此后在许多NLP任务中建立了最先进的方法。 为了使Transformer也适用于计算机视觉任务,许多modifications的工作已被发表。Parmar et al. [11] 仅在局部邻域的每个query像素上应用SA,而不是全局应用。最近,Vision Transformer (ViT) [4]达到state-of-the-art在ImageNet 分类任务上,通过直接应用 Transformers with global self-attention到 full-sized images. 所以我们所提出的TransUnet是第一个基于Transformer的医学图像分割框架,其在取得巨大成功的ViT上构建。
3 method
给定图像![]() ,其空间分辨率为H×W,通道数为C。 我们的目标是预测相应像素级label map,尺寸为H×W。最常见的方法是直接训练CNN(例如UNet),首先将图像encode为 high-level feature representations,然后将其decode回 full spatial resolution。
,其空间分辨率为H×W,通道数为C。 我们的目标是预测相应像素级label map,尺寸为H×W。最常见的方法是直接训练CNN(例如UNet),首先将图像encode为 high-level feature representations,然后将其decode回 full spatial resolution。
与现有方法不同,我们的方法通过使用Transformer将SA引入编码器设计。 我们将首先在第3.1节中介绍如何直接应用Transformer对来自分解后的图像patches的特征表示进行编码。 然后,将在3.2节中详细说明TransUNet的总体框架。
3.1 Transformer as Encoder
- Image Sequentialization.图像序列化。 根据[4](ViT),我们首先通过将输入x重塑为 flattened 2D patches
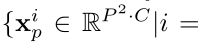
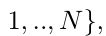 ,来执行标记化( tokenization)。每个patch大小为P^2,patches的数量为
,来执行标记化( tokenization)。每个patch大小为P^2,patches的数量为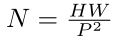 。 相当于把H×W的原图转化为N个P×P大小的2D图片,C还是不变。
。 相当于把H×W的原图转化为N个P×P大小的2D图片,C还是不变。 - Patch Embedding 我们使用可训练的线性投影将矢量化的patches
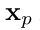 映射到一个潜在的D维embedding空间。 为了对patches 空间信息进行编码,我们学习了特定的位置embedding,并加入到patch embedding以保留位置信息。公式如下:
映射到一个潜在的D维embedding空间。 为了对patches 空间信息进行编码,我们学习了特定的位置embedding,并加入到patch embedding以保留位置信息。公式如下:
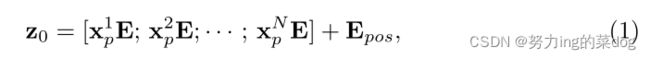
where ![]() 是patch线性投影,
是patch线性投影,![]() 代表位置embedding。
代表位置embedding。
理解:一共有N个![]() ,其大小为
,其大小为![]() , 分别都×上E,以转化为维度D的向量。如此以来,得到N×D的向量,再与
, 分别都×上E,以转化为维度D的向量。如此以来,得到N×D的向量,再与![]() 相加。
相加。
Transformer编码器由L层的 Multihead Self-Attention(MSA)和多层感知器(MLP) blocks 组成。因此,L层的输出如下:
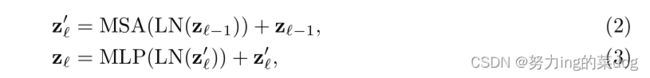
Where ![]() 表示 layer normalization operator,
表示 layer normalization operator, ![]() 是在第L层的编码的图像表示。
是在第L层的编码的图像表示。
理解:首先将上一层的输出,喂入LN,然后再进入MSA,再加上上一层的输出(残差结构),得到![]() 。然后做同样的事,不过是进入MLP,得到当前层的输出
。然后做同样的事,不过是进入MLP,得到当前层的输出![]()
Transformer层的结构如图1(a)所示。可见经过linear projection之后,就进入了12个transformer层,每层如左边所示。
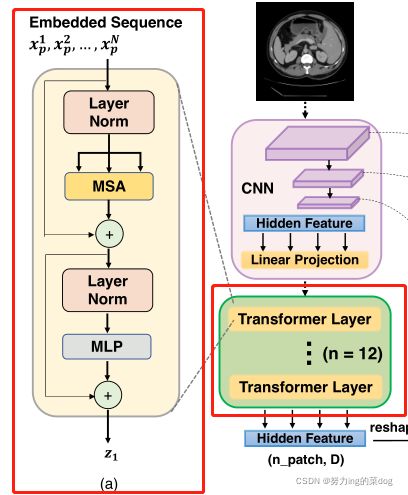
图1(a)
3.2 TransUNet
为了分割的目的,一个直观的解决方案是简单地将编码的特征表示![]() 即N×D,上采样到全分辨率,以预测密集输出。 在这里,为了恢复空间顺序,编码的特征应该首先重塑大小,从
即N×D,上采样到全分辨率,以预测密集输出。 在这里,为了恢复空间顺序,编码的特征应该首先重塑大小,从![]()
我们使用1×1的卷积将通道数减小到num of class。然后将特征图直接双线性插值(bilinearly upsampled)到全分辨率H×W。在4.3中我们我们在解码器设计中将此 naive的上采样基线表示为"None"
虽然采用双线性插值已经取得了不错的效果,因为![]() 通常比原始图像分辨率H × W 小得多,因此不可避免地导致low level细节的丢失(例如器官的形状和边界)。 因此,为了补偿这种信息损失,TransUnet采用了一种Hybrid CNN-Transformer结构作为编码器以及一个级联的 cascaded upsampler,以实现精确局部化。 proposed TransUNet的概述如图1所示。
通常比原始图像分辨率H × W 小得多,因此不可避免地导致low level细节的丢失(例如器官的形状和边界)。 因此,为了补偿这种信息损失,TransUnet采用了一种Hybrid CNN-Transformer结构作为编码器以及一个级联的 cascaded upsampler,以实现精确局部化。 proposed TransUNet的概述如图1所示。
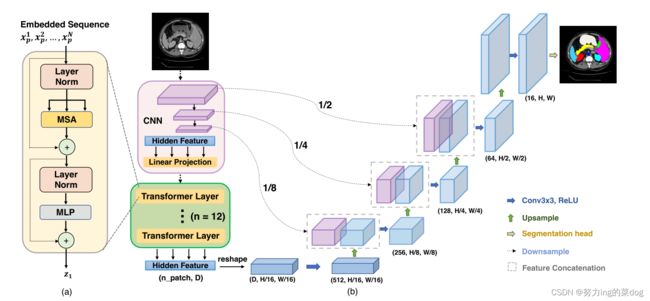
图1
- CNN-Transformer Hybrid as Encoder. CNN首先用作特征提取器,生成feature map作为input。Patch embedding 被应用在1×1的Patches上。这些Patches from CNN的feature map,而不是直接从原图得到。
这样设计的原因:1) 在解码path中,可以利用intermediate的高分辨率CNN feature map。2) 这比简单地用pure Transformer 作为decoder好(这不是废话嘛?)
- Cascaded Upsampler (CUP). 包含了许多下采样步骤去解码hidden特征,以输出最后的分割mask. 在reshape hidden特征
 到
到 后,(即3.2开头所述的部分),我们示例CUP通过级联多个上采样blocks去达到全分辨率从
后,(即3.2开头所述的部分),我们示例CUP通过级联多个上采样blocks去达到全分辨率从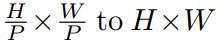 。每个block包含两个上采样操作,一个3×3卷积层,一个relu。
。每个block包含两个上采样操作,一个3×3卷积层,一个relu。
我们看到CUP 和hybrid encoder组成了一个U型结构,通过skip-connection, 使得不同分辨率水平的特征聚合。
结构梳理:
TransUnet的结构与Unet类似,是由一个encoder和一个decoder组成的U型结构。
Encoder部分一共做了4次下采样,缩小到16倍,并加入了Transformer机制,最终得到了N个一维向量。 注意transformer之前做了embbeding,将三维作为二维。![]() , 文章设置的P=16,则N=14*14=196
, 文章设置的P=16,则N=14*14=196

transformer中MLP:经过线性层从768放大到3976,然后relu+dropout,再通过一个线性层缩小回768,再drop out
Decoder部分做了4次上采样,最终将此一维向量恢复成了原来的图像。Encoder和Decoder部分还做了三次跳跃连接。
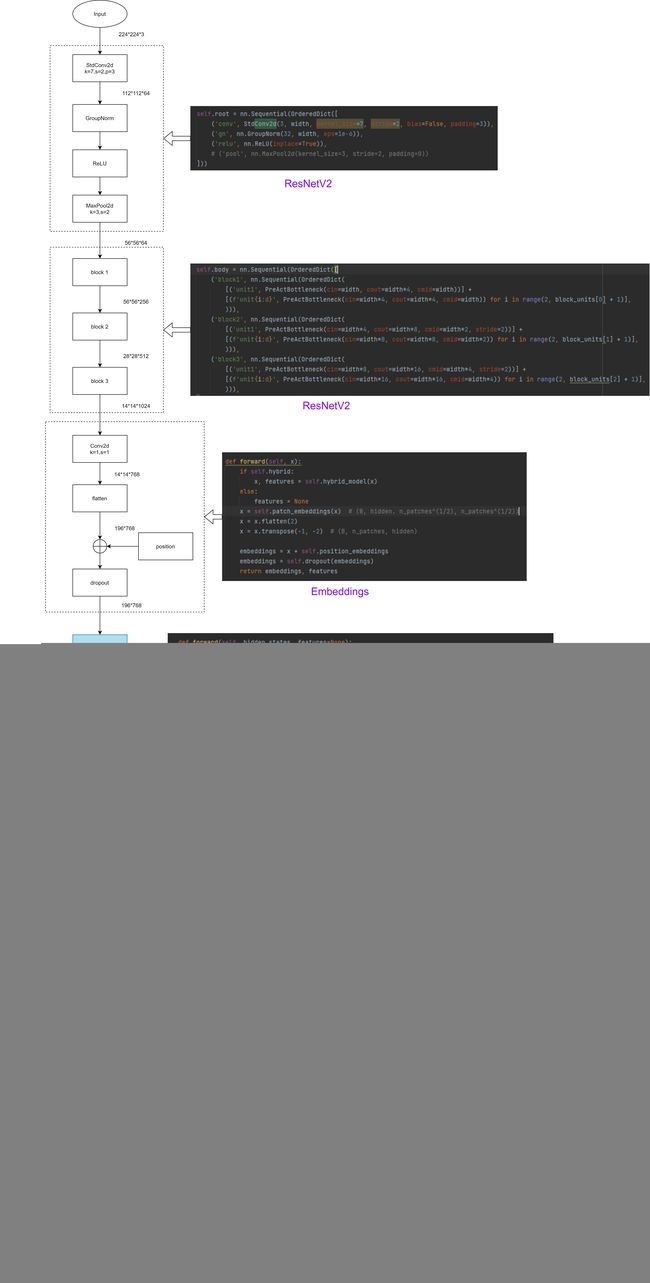
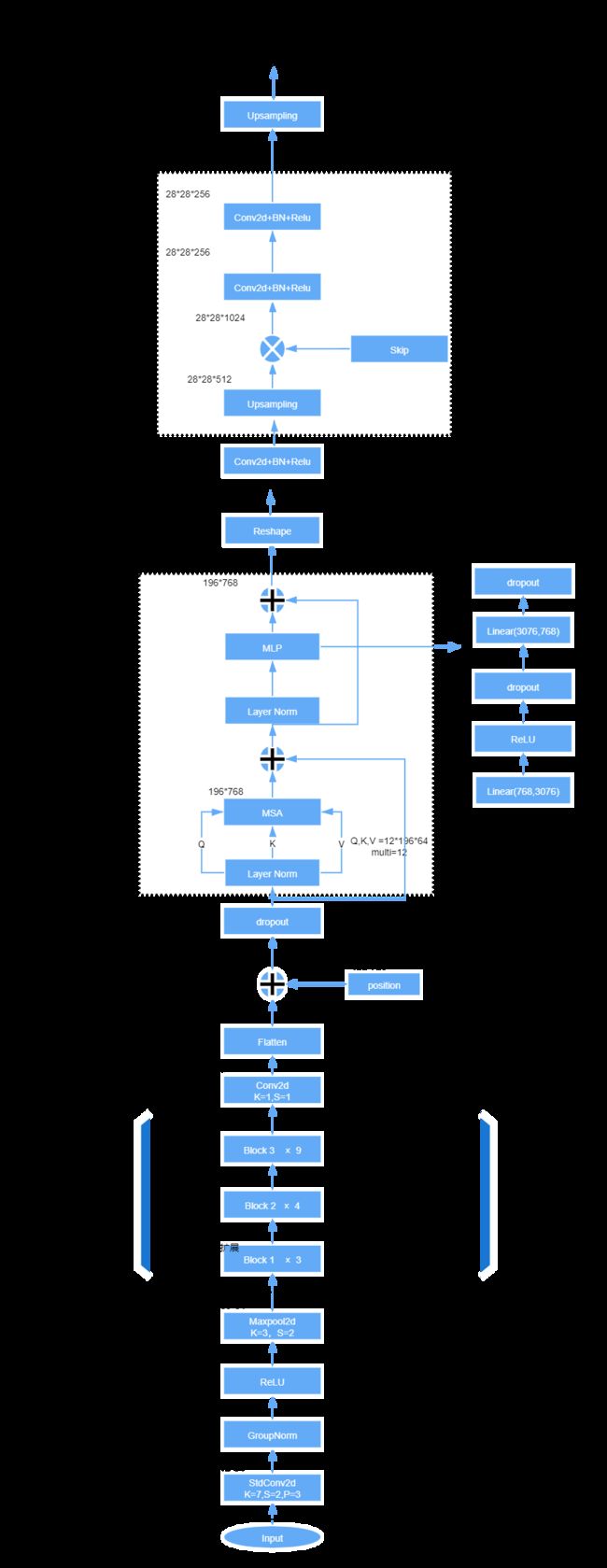
这两个图参考两位大佬:
TransUnet: 结构解析_ripple970227的博客-CSDN博客_transunet详解TransUNet_不秃头不成功的博客-CSDN博客_transunetTransUnet: 结构解析_ripple970227的博客-CSDN博客_transunet详解
4 Experiments and Discussion
4.1 Dataset and Evaluation
Synapse multi-organ segmentation dataset1 in the MICCAI 2015 Multi-Atlas Abdomen Labeling Challenge 指标:average DSC (Dice similarity coefficient) 和 average Hausdorff Distance (HD)
Automated cardiac diagnosis challenge 指标:average DSC
4.2 Implementation Details
for TransUNet, 有两种encoder设计,一种是简单地采用 ViT,一种是结合ResNet-50 和 ViT的,也就是文章一直讲的。所有的transformer的backbone都在Imagenet pretrain了。
4.3 Comparison with State-of-the-arts
对比了四个 previous state-of-the-arts: 1) V-Net [9]; 2) DARR [5]; 3) U-Net [12] and 4) AttnUNet

R50-ViT-CUP加了级联上采样机制CUP后,效果增加不少。
最后的TransUnet是在R50-ViT-CUP基础上,再增加了skip-connections
4.4 Analytical Study
在分析超参数
- The Number of Skip-connections.

- On the Influence of Input Resolution.

如果不降低数据的分辨率,其实效果更好,但是为了实验效率,所以采用224
- On the Influence of Patch Size/Sequence Length

较高的分割性能通常通过较小的patch大小获得。因为这样得到的N sequence比较长,信息没有被过度压缩
- Model Scaling. 模型规模

base: the hidden size D, number of layers, MLP size, and number of heads are set to be 12, 768, 3072, and 12
larger: 24, 1024, 4096, and 16
可以看出差别不大
4.5 Visualizations
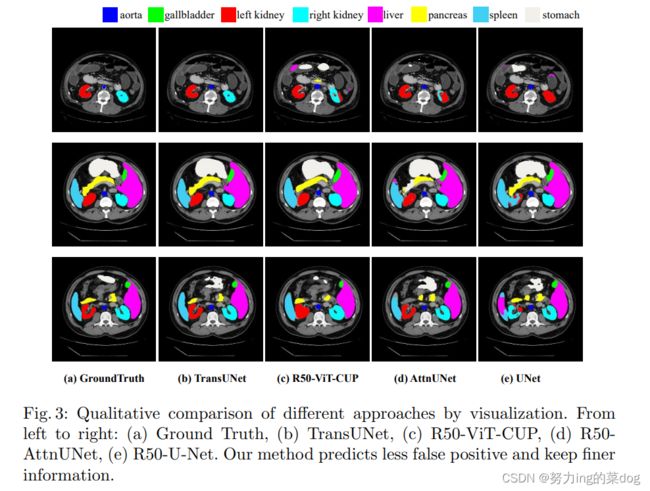
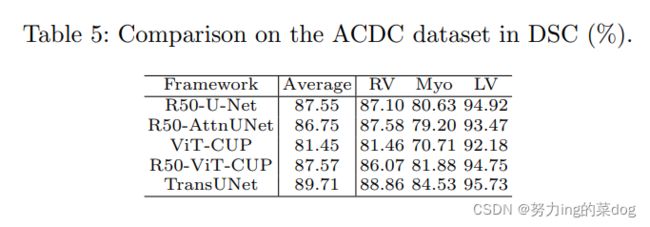
4.6 Generalization to Other Datasets
在心脏数据集ACDC上做了实验,已证明方法的通用性,可见得到的结果和多器官分割差不多。