When AWGN-based Denoiser Meets Real Noises
个人论文阅读笔记,可能存在许多瑕疵和错误,欢迎评论指正,谢谢~~
1.总括:
实际噪声大多是空间/通道相关和空间/通道可变的。如果仅使用AWGN训练模型,则该域间隙在具有真实噪声的图像上会产生不满意的性能。本文提出一种新的方法来提高真实图像去噪器的性能,该去噪器仅使用AWGN主导的合成像素无关噪声数据集进行训练。首先,训练了一个深度模型,该模型由一个噪声估计器和一个具有混合AWGN的随机值脉冲噪声(RVIN)的去噪器组成。然后,研究了像素重组下采样(PD)策略,以使用训练模型适应真实噪声。

所提出的自适应方法的基本思想:Pixel-shuffle Down-sampling (PD)。空间相关的真实噪声(左)被分解为空间可变像素无关的噪声(中)以近似空间可变的高斯噪声(右)。然后可以相应地将基于 AWGN 的去噪器应用于此类真实噪声。
本文寻求将一种基于学习的去噪器采用与像素无关的合成噪声进行训练,以适应未知的真实噪声。如图一所示,假设真实噪声与像素无关的合成噪声主要在空间/通道可变和相关性方面不同。这种差异源于像去马赛克这样的相机内管道。基于这一假设,首先提出使用混合AWGN和RVIN训练基去噪网络。该柔性基网络由显示噪声估计器和条件去噪器组成。并证明了这样的完全卷积网络在处理与像素无关的空间/通道可变噪声方面实际上是有效的。其次,提出了一种简单而有效的自适应策略,像素重组下采样PD,该策略采用分治思想,通过分解空间相关性来处理真实噪声。
本文贡献:
提出了一种新的灵活的深度去噪模型(用AWGN和RVIN训练),用于盲和非盲图像去噪。还证明了在空间不变噪声上训练的这种完全卷积模型可以处理空间可变噪声。
通过应用一种称为像素重组下采样的新策略,使用AWGN-RVIN训练的深度去噪器适应真实噪声。将空间相关噪声分解为像素级独立噪声。检查并克服了提出的域间隙,以提高实际去噪性能。
模型不使用任何图像或来自真实噪声数据集的先验数据。还表明所提出的PD策略,可以提高其他一些现有去噪器模型性能。
2.Methodology
2.1.Basis Noise Model
基本噪声模型为AWGN-RVIN混合模型。由于伽玛变换、去马赛克和其他插值等原因,sRGB图像中的噪声不再像原始传感器数据中那样近似为高斯泊松噪声。
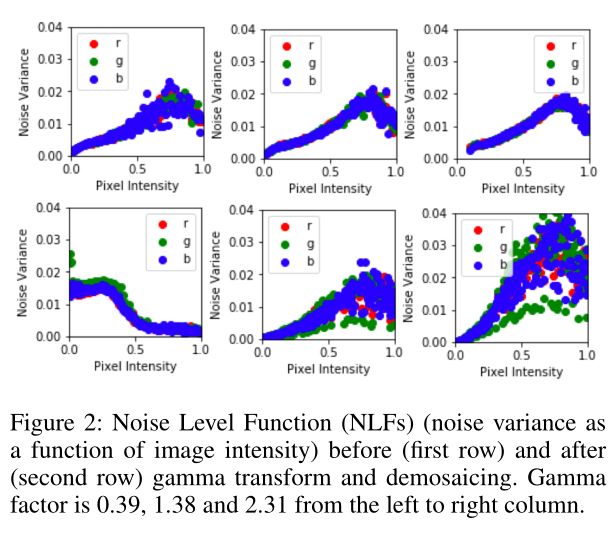
遵循流程合成噪声图像,并绘制伽玛校正变换(第一行)和去马赛克(第二行)的噪声级函数(NLF)(噪声方差作为图像强度的函数)。从左到右,伽玛因子增强。结果表明,在RGB图像中,剪切效应和其他非线性变换将极大的影响原始传感器数据中原本线性的噪声方差-强度关系,甚至改变噪声均值。对于比建模不同非线性变换的高斯泊松噪声更一般的情况,RGB中的真实噪声仍然可以局部近似AWGN。因此,在本文中假设RGB噪声近似空间可变和空间相关的AWGN。在训练中添加RVIN旨在明确解决大多数夜间拍摄图像中经常出现的由相机硬件的死像素或长曝光引起的缺陷像素。
2.2.Basis Model Structure
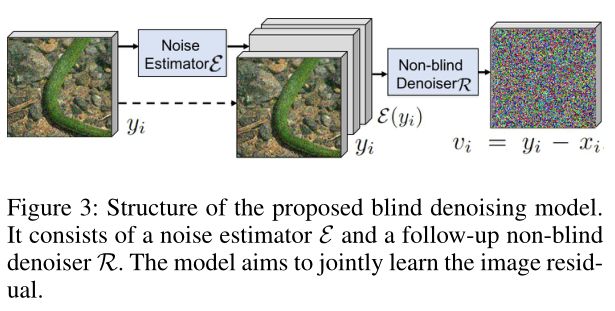
基础模型的架构如图3所示。提出的盲去噪模型 由噪声估计器
由噪声估计器 和后续非盲去噪器
和后续非盲去噪器 组成。给定一个噪声观测值
组成。给定一个噪声观测值![]() ,其中F是噪声合成过程,
,其中F是噪声合成过程, 是无噪声图像,该模型旨在联合学习残差
是无噪声图像,该模型旨在联合学习残差![]() ,并在成对的合成数据(
,并在成对的合成数据(![]() )上进行训练。具体来说,噪声估计器输出
)上进行训练。具体来说,噪声估计器输出![]() ,
,![]() 由六个像素级噪声水平图组成,对应于两个噪声类型,即AWGN和RVIN,跨越三个通道(R、G、B)。然后将
由六个像素级噪声水平图组成,对应于两个噪声类型,即AWGN和RVIN,跨越三个通道(R、G、B)。然后将 与估计的噪声水平图
与估计的噪声水平图![]() 连接并馈入非盲降噪器。然后去噪器输出噪声残差
连接并馈入非盲降噪器。然后去噪器输出噪声残差![]() 。提出了三个目标来监督网络训练,包括噪声估计
。提出了三个目标来监督网络训练,包括噪声估计![]() 、盲
、盲![]() 和非盲
和非盲![]() 图像去噪目标,定义为:
图像去噪目标,定义为:
 和
和
其中![]() 和
和![]() 是和的可训练参数。
是和的可训练参数。 是的真实噪声水平图,由
是的真实噪声水平图,由![]() 和
和![]() 组成。对于AWGN,
组成。对于AWGN,![]() 表示为在R、G、B通道上填充相同标准偏差值的偶数地图,范围从0到75。对于RVIN,
表示为在R、G、B通道上填充相同标准偏差值的偶数地图,范围从0到75。对于RVIN,![]() 表示为具有损坏像素比率的地图,其上限设置为0.3。我们进一步将标准化为范围(0,1)。那么完整的目标可以表示为上诉三个损失的加权和。
表示为具有损坏像素比率的地图,其上限设置为0.3。我们进一步将标准化为范围(0,1)。那么完整的目标可以表示为上诉三个损失的加权和。
![]()
其中 是平衡损失的超参数,将它们设置为相等。
是平衡损失的超参数,将它们设置为相等。
该模型结构可以同时进行盲去噪和非盲去噪,模型在交互去噪和结果调整方面更加灵活。显式噪声估计也有利于噪声建模和分离。
3.Pixel-shuffle Down-sampling(PD) Adaptation
Pixel-shuffle Downsampling:像素重组下采样定义为通过步幅S采样图像来创建马赛克。与其他下采样方法(如线性插值、双三次插值和像素面积关系)相比,噪声图像上的像素重组和最近领下采样不影响真实噪声分布。此外,与其他方法相比,像素重组通过保留图像中的原始像素也有利于图像恢复。这两个优势产生了PD策略的两个阶段:自适应和细化。
3.1.Adaptation
基于AWGN训练的学习型去噪器由于域的差异,对真实噪声的鲁棒性不足。为了使噪声模型适应真实噪声,在此简要分析并证明关于真实噪声和高斯噪声之间差异的假设:空间/通道可变和相关。
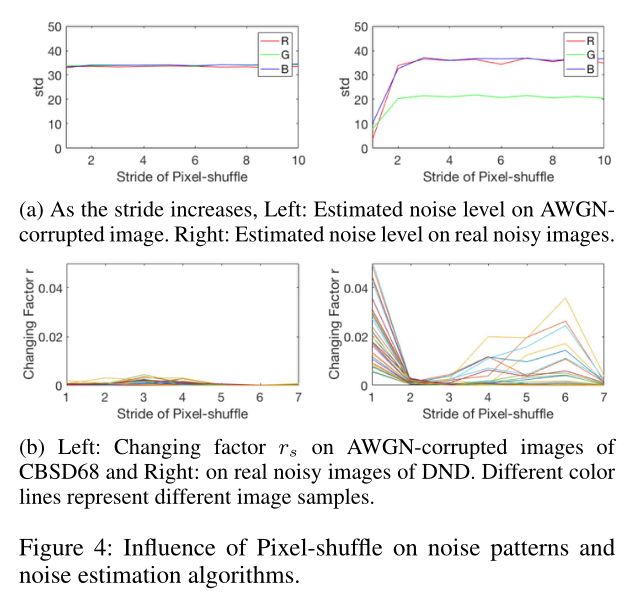
假设噪声估计器是鲁棒的,这意味着它可以准确估计准确的噪声级,对于单个AWGN损坏的图像,当样本步长足够小以保留纹理结构时,PD既不会影响AWGN方差,也不会影响估计值。当将其扩展为真实噪声情况时,有一个有趣的假设:当增加像素重组的的样本步长时,特定噪声估计器的估计值首先波动,然后在几步增量内保持稳定。这种假设是可行的,因为像素重组将空间相关的噪声模式分解为与像素无关的噪声模式,可以近似为空间变量AWGN,并适用于这些估计器。
如图一所示,从SIDD中随机噪声图像y中随机裁剪了一个大小为200×200的补丁。将std=35的AWGN添加到其无噪声地面真值x。在对y和AWGN损坏的x进行PD后,从步长s=2开始,y的噪声模式显示出预期的像素独立性。使用x的估计结果在图4(a)(左)中保持不变,但图4(a)(右)中y的估计结果在跨步s=2后首先增加并开始保持稳定。这种视觉模式和假设是一致的。
对于空间变量信号相关的真实噪声,我们的像素估计有其优越性。为了统计空间变量噪声估计值,提取了噪声图![]() 的三个AWGN通道,其中W和H是输入图像的宽度和高度,并且在步幅为s时计算每个通道上的归一化的10-bin直方图
的三个AWGN通道,其中W和H是输入图像的宽度和高度,并且在步幅为s时计算每个通道上的归一化的10-bin直方图![]() 。引入变化因子
。引入变化因子![]() 来检测噪声图分布随步长s的增加而变化,
来检测噪声图分布随步长s的增加而变化,
![]()
其中c是通道索引。然后,研究了高斯白噪声和真实噪声之间的![]() 序列差异。具体来说,从CBSD68中随机选取50幅图像,并在其中添加随机水平AWGN。为了进行比较,从DND基准中随机选取了50个512×512的图像块。在图4(b)中,对于所有AWGN循环图像,
序列差异。具体来说,从CBSD68中随机选取50幅图像,并在其中添加随机水平AWGN。为了进行比较,从DND基准中随机选取了50个512×512的图像块。在图4(b)中,对于所有AWGN循环图像,![]() 序列保持接近零(左图),而对于真实噪声
序列保持接近零(左图),而对于真实噪声![]() ,当s=2时,会突然下降。这表明空间相关性已从s=2中断。
,当s=2时,会突然下降。这表明空间相关性已从s=2中断。
上述分析启发了所提出的基于像素重组的自适应策略。直观地说,我们的目标是找到最小步长,使下采样的空间相关噪声与像素无关的AWGN匹配。因此,我们不断增加步幅s,直到下降到阈值t以下。在CBSD68上进行了100次迭代,以选择合适的广义阈值t。在平均每个迭代的最大r后,根据经验设置t=0.008。
3.2.PD Refinement

图5显示了拟议的PD细化策略:(1)计算最小步长s(在本例中为2)和更多数码相机图像情况,以在自适应过程后匹配AWGN,并将图像像素重组为马赛克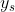 ;(2)使用G对进行去噪;(3)分别用噪声块重新填充每个子图像,并对他们进行像素重组上采样;(4)使用G再次对每个重新填充的图像进行去噪,并对其进行平均,以获得“纹理细节”T;(5)结合过度平滑的“平坦区域”F以细化最终结果。
;(2)使用G对进行去噪;(3)分别用噪声块重新填充每个子图像,并对他们进行像素重组上采样;(4)使用G再次对每个重新填充的图像进行去噪,并对其进行平均,以获得“纹理细节”T;(5)结合过度平滑的“平坦区域”F以细化最终结果。
噪声去除的目标包括保留纹理细节和边界、平滑平坦区域和避免产生伪影。因此,在上述步骤(5)中,我们建议结合“纹理细节”T和“平坦区域”F进一步细化去噪图像通过提升噪声估计水平,可以从过度平滑去噪结果中获得平坦区域。在这项工作中,给定噪声观测y,细化噪声图定义为,
![]()
因此,“平坦区域”被定义为![]() ,其中PD和PU是像素重组下采样和上采样。最终结果由得出
,其中PD和PU是像素重组下采样和上采样。最终结果由得出![]() 。
。
完结~~