Python机器学习教程—线性回归的实现(不调库和调用sklearn库)
第一个要讲的机器学习算法便是线性回归,从此模型入手便于我们很快的熟悉机器学习的流程,便于以后对其他算法甚至是深度学习模型的掌握。本文尝试使用两个版本的python代码,一个是不调用sklearn库版本,另一个是调用sklearn库版本的
目录
线性回归介绍
线性回归实现(不调用sklearn库)
线性回归实现(调用sklearn库)
sklearn提供的线性回归相关的API
调用库函数进行多元线性回归
线性回归介绍
什么是线性回归?前文曾提到过,是指利用机器学习的模型算法找出一组数据输入和输出之间的关系,输出是连续的数据便是回归问题,而所谓线性回归,即是使用线性数学模型解决生活中回归预测问题。
即找到一个最优秀的线性模型y=f(x)表达样本数据特征之间的规律,从而传入未知输出的输入x,求出预测的输出y。 试图用类似下面的公式表示的线性模型来表达输入与输出之间的关系
![]()
针对一组数据输入与输出我们可以找到很多线性模型,但最优秀的线性模型需要满足的是能最好的拟合图中的数据,误差是最小的。比如拿到模型去测试一组数据,已知输入和真实输出,那么我们的预测输出与真实输出之间的差便是误差,那么所有测试数据总的误差也体现着模型表达能力的误差。那么线性回归中最难的部分也就是模型训练的部分——怎么寻找到最适合的斜率和截距,也就是公式中的![]()
线性回归实现(不调用sklearn库)
首先设定数据,是员工的工龄(年限)对应薪水(千元)的数据,使用散点图观察一下大致是否符合线性回归的情况
# 线性回归的实现
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 样本数据 员工工龄x对应薪水y
x=np.array([0.5, 0.6, 0.8, 1.1, 1.4])
y=np.array([5.0, 5.5, 6.0, 6.8, 7.0])
# 根据样本数据画散点图观察一下
plt.grid(linestyle=':')
plt.scatter(x,y,s=60,color='dodgerblue',label='Samples')输出结果为
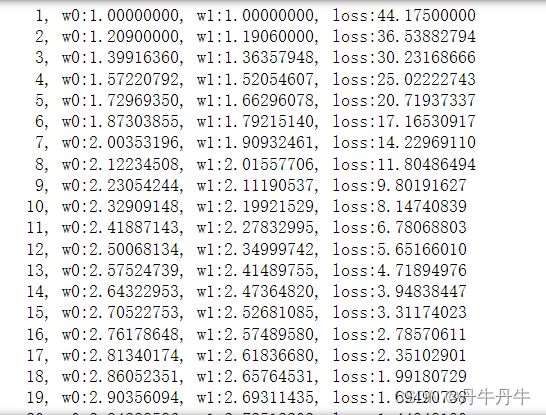
编写梯度下降代码,中间输出w0,w1和loss在循环过程中每一轮的数据,这样做的意义在于之后我们自己编写的时候可以通过写个for循环来监控一下随着迭代次数的增加,模型参数的变化以及损失函数的变化。可以观察到w0,w1和loss的变化方向和趋势,这也方便继续对参数进行调整。
# 基于梯度下降算法,不断更新w0和w1,从而找到最佳的模型参数
# 设定超参数
w0,w1,lrate=1,1,0.01 # lrate代表学习率
times=1000 # times表示迭代次数
# 循环求模型的参数
for i in range(times):
# 输出每一轮运算过程中,w0、w1、1oss的变化过程:
loss=((w0+w1*x-y)**2).sum()/2
print('{:4}, w0:{:.8f}, w1:{:.8f}, loss:{:.8f}'.format(i+1,w0,w1,loss))
# 计算w0和W1方向上的偏导数,代入模型参数的更新公式
d0=(w0+w1*x-y).sum()
d1=(x*(w0+w1*x-y)).sum()
# 更新w0和w1
w0=w0-lrate*d0
w1=w1-lrate*d1
输出结果如下图,可观察到损失函数loss在不断的下降
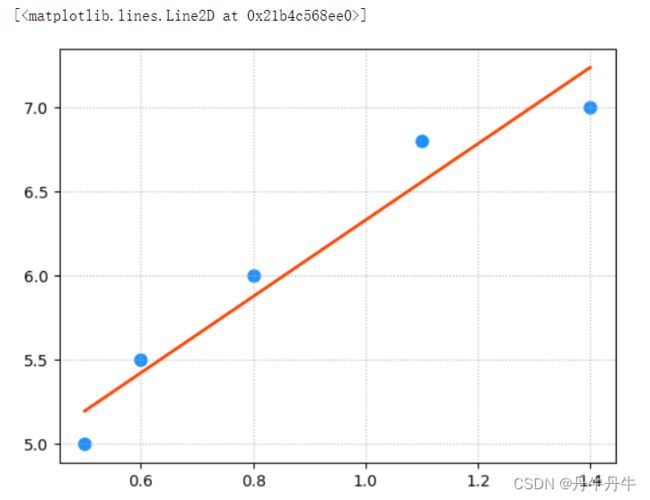
根据训练好的模型在图上绘制样本点和回归线
# 绘制样本点
plt.grid(linestyle=':')
plt.scatter(x,y,s=60,color='dodgerblue',label='Samples')
# 绘制回归线
pred_y=w0+w1*x
plt.plot(x,pred_y,color='orangered',linewidth=2,label='Regression Line')结果如下图
线性回归实现(调用sklearn库)
真正在应用上,可以直接使用python的sklearn库中的函数,只需几行代码就可完成线性回归。
sklearn提供的线性回归相关的API
整个线性回归的训练过程都已在model中定义好,只需将训练数据放在model.fit()中就可以自动去进行训练,而将要预测的数据放到predict()中即可。
import sklearn.linear_model as lm
#创建模型
model=lm.LinearRegression()
# 训练模型
# 输入为一个二维数组表示的样本矩阵
# 输出为每个样本最终的结果
mode1.fit(输入,输出) # 通过梯度下降法计算模型参数
# 预测输出
# 输入array是一个二维数组,每一行是一个样本,每一列是一个特征。
result=model.predict(array)注意模型传参格式要求:真正训练时,输入是一个二维数组表示样本矩阵,而输出是一维数组表示每个样本的最终结果。在预测时,要传入一个二维数组,也就是要预测的样本,系统会计算后输出。
示例:薪资预测
# 线性回归的实现
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import sklearn.linear_model as lm
# 样本数据 员工工龄x对应薪水y
x=np.array([0.5, 0.6, 0.8, 1.1, 1.4])
y=np.array([5.0, 5.5, 6.0, 6.8, 7.0])
# 给的x是一维的,库函数要求输入是二维的,所以要调整x
train_x,train_y=pd.DataFrame(x),y
# 基于sklearn提供ApI,训练线性回归模型
model=lm.LinearRegression()
model.fit(train_x,train_y)
# 针对所有训练样本,执行预测操作,绘制回归线
pred_train_y=model.predict(train_x)
# 可视化
plt.grid(linestyle=':')
plt.scatter(x,y,s=60,color='dodgerblue',label='Samples')
plt.plot(x,pred_train_y,color='orangered',label='Regression Line')
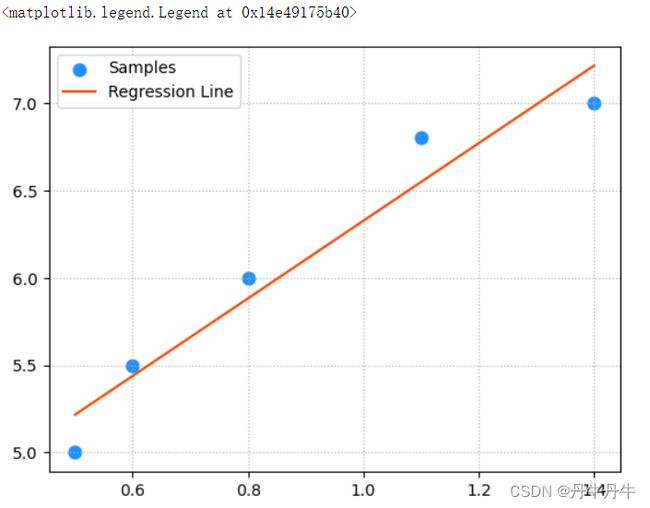
plt.legend()输出结果如下图,可以看出拟合的回归线与我们上面手动编写的线性回归模型效果相同
调用库函数进行多元线性回归
上面所举的例子是一元线性回归,那么与之类比的多元线性回归,也就是考虑x1,x2,x3...这样多个特征对输出y的影响和它们之间的关系。根据库函数的特性,要求输入必须是二维向量,那么我们只需把这多个特征的数据整理成一个二维的样本矩阵,“一行一样本,一列一特征”,用这样的数据直接调用上面列出的API即可
在实际应用中我们的数据一般都是存在文件中的,以csv文件为例,假设我们考虑影响薪资水平的有多列特征,包括工作年限、学历、性别等因素,那么只需把数据集整理成二维的,加载进python接下来调库即可。
#加载数据集
data=pd.read_csv('Salary_Data.csv')
x,y=data['YearsExperience','Education','Gender'],data['Salary']