【跨模态实践】VCED环境搭建全教程与Jina初步
环境搭建目标
- 搭建ubuntu系统
- miniconda源码运行
- 搭建miniconda与python3.9环境
- 安装 rust, ffmpeg
- 安装 clip
- 启动server
- 启动web
- jina基操
注意:本文从虚拟机的Ubuntu环境开始搭建,jina不适合于windows系统
1.从Ubuntu开始搭建环境
由于本人之前已经用vmware搭建好Ubuntu环境了,这个过程有点漫长,大概一个多小时用于搭建(下载时间较长),所以这里不再展示如何配置Ubuntu系统了,使用vmware搭建Ubuntu系统的教程网上很多,这里不赘述了,去b站上搜一下很多的
2.miniconda源码运行
进入Ubuntu桌面后,右键桌面,点击在终端中打开,打开命令行

终端效果如下
2.1 搭建miniconda与python3.9环境
miniconda是anaconda的阉割版,少了很多不必要的包的安装,适合python版本管理
1.设置root环境
sudo passwd root
然后设置一个新的密码
su -
进入root环境
2.下载miniconda
# 下载安装软件
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
# 给安装文件添加执行指令
sudo chmod +x Miniconda3-latest-Linux-x86_64.sh
# 安装
sudo ./Miniconda3-latest-Linux-x86_64.sh
中间有跳出来这些文字,最后一行是输入下载路径,如果一直按ENTER,会默认下载在当前目录文件夹,也可以输入路径指定安装
Miniconda3 will now be installed into this location:
/root/miniconda3
- Press ENTER to confirm the location
- Press CTRL-C to abort the installation
- Or specify a different location below
[/root/miniconda3] >>> 这里可以输入路径,例如:/opt/miniconda
完成后看看conda能不能用
进入环境变量更改
vim ~/.bashrc
添加
export PATH="/root/miniconda3/bin:$PATH"
其中/root/miniconda是你刚才的指定路径,如果没有指定路径应该就是/root/minicconda
顺便配置python3.9环境变量

添加
alias python='/usr/bin/python3.9'
摁下esc,输入:wq!进行保存,后续涉及进入文件退出文件的保存操作相同
source ~/.bashrc
python
显示python3.9说明配置成功
创建虚拟环境,配置python3.9,环境名叫做vced
conda create -n vced python==3.9
激活环境(后面重启时,要先进入root再激活),下面两句都执行一下
conda activate vced
source activate vced
进入成功则显示(vced)
以后再进的话直接输入`source activate vced
2.2 安装rust和ffmpeg
直接使用pip安装
考虑到下载很慢,请在Ubuntu系统中配置pip源
mkdir ~/.pip
vim ~/.pip/pip.conf
复制下面之一的内容到文件里面
清华源
[global]
trusted-host = pypi.tuna.tsinghua.edu.cn
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
或者选择豆瓣源
[global]
trusted-host = pypi.douban.com
index-url = http://pypi.douban.com/simple
之后保存即可
首先要更新一下pip,否则下载会出现cp38的情况(笔者这里是这样)
/usr/local/bin/python3.9 -m pip install --upgrade pip
安装下列包(注意是否是cp39)
pip install rust
pip install ffmpeg
2.3 安装clip
cd ~/vced/
pip install git+https://github.com/openai/CLIP.git
可能会提示连接失败(拒绝连接),不要灰心,多试几次
多试几次还不行,考虑使用码云
https://gitee.com/473091010/CLIP.git
2.4 启动server
需要先clone项目源码,也就是本次VCED项目
git clone https://github.com/datawhalechina/vced.git
# 进入 server 文件夹
cd code/service
# 安装相关依赖
pip install -r requirements.txt
# 启动服务端
python3.9 app.py
注意这里使用python3.9进行运行,否则报错(目前还没找到为什么只能用python3.9而不是python的原因,因为明明前面已经设置过环境变量了,可能是因为miniconda的缘故吧,大家看着来就行,以能运行为主)
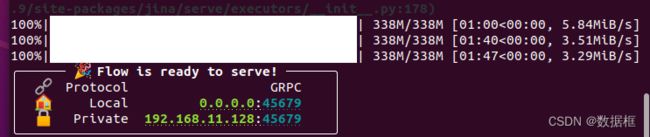
启动后端server后,不要动该终端了,另外开一个新的终端运行web,也就是右键桌面再打开一个终端,然后重新进入root,然后进入vced虚拟环境
2.5 启动web
# 进入 web 文件夹
cd code/web
# 安装相关依赖
pip install -r requirements.txt
# 启动服务端
streamlit run app.py

直接在网站输入localhost:8501,即可打开如下

只需要上传一段MP4视频,即可开始视频搜索!!
进一步解释为什么有些同学(我)报如下错

大概是只开了一个终端跑server和web,是不是python3.9 app.py 运行成功了,然后ctrl+z或者ctr+c了,然后另起一行运行web?
nonono,完全错了,另起一个吧,分开运行
3. JINA基操
上面第二大步我们完成了项目的快速运行,这一步开始我们进入JINA的学习(点击连接快速进入md)
本次学习内容如下:
- 成功启动grpc服务
- 在Jina的Docarray中导入任意模态的数据
- 代码练习:code/jina_demo
3.1 成功启动grpc服务
1.使用pip安装jina
pip install jina
2.找到toy.yml和test.py和client.py
cd vced/code/jina_demo
该文件下有已经创建好的三个文件
3.启动grpc服务
jina flow --uses toy.yml
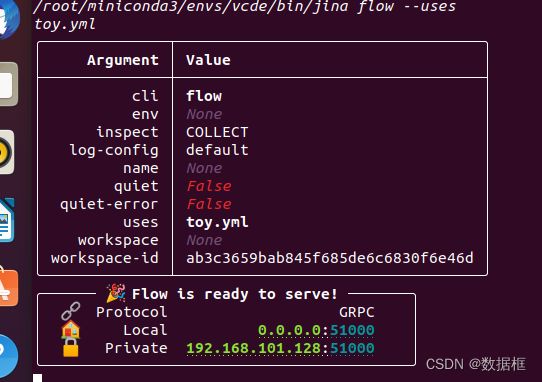
启动后得到如上grpc为51000
然后新开一个终端(反正不是现在这个启动grpc的终端就行)
4.运行client.py文件
python3.9 client.py
最终会打印出一个 "['', 'foo was here', 'bar was here']" 字符串
![]()
成功!
3.2 在Jina的DocArray中导入任意模态的数据
问题来了,jina是什么?DocArray是什么?
前面光顾着配环境+无脑跑程序了,现在可以来好好学一波正经知识了!
1.jina是什么?
一句话:jina将非结构化数据转为向量
非结构化数据:图像、文档视频等
为啥要转为向量:这就涉及到不同模态数据的同化问题了,本项目的重心是跨模态,也就是说,我们要把视频里面的图像,文字,统一转换成相同的向量形式,这样数据不就可以混在一块儿用了嘛
2.DocArray是什么?
如果你有数据分析的基础,对pandas和numpy等包不陌生,你一定会很快理解什么叫做DocArray。
DocArray是用于存储非结构化数据的数据结构工具包,其基本数据结构为Document,可以类比一下DataFrame?DocArray对数据采用分层存储,以某一个画面为轴,可以在第一层存入该画面的视频,第二层存入该视频的不同镜头,第三层可以是视频的某一帧,也可以存储台台词等等,这使得你可以通过台词去搜索到视频,也可以通过视频定位某几帧画面,这样搜索的颗粒度,结构的多样性和结果的丰富度,都比传统文本检索好很多。
DocArray除了基本数据结构Document以外,还包括两个概念:
- DocumentArray:用于高效访问、处理和理解多个文档的容器,可以保存多个 Document 的列表
- Dataclass:用于直观表示多模式数据的高级API
DocArray融合了Json、Pandas、Numpy、Protobuf 的优点,如果你有这些包的使用经验,那么DocArray也不会那么难上手
其他的介绍可以参考jina.md,上述描述是个人的学习理解而已,具体还需要学习者自行领会
3.2.1 导入任意模态数据
就像pandas里面的DataFrame一样,我们把任意数据放到dataframe里面
dt = pd.DataFrame(data)
DocArray也是如此方便
dt = Document(data)
比如我们放一段文本进去
dt = Document(text='hello,word.')
OK,任务完成!
- 在Jina的DocArray中导入任意模态的数据 ✅ 2022-11-17
3.3 代码练习:code/jina_demo
这意思是在项目目录下code/jina_demo里面有代码等着我们去练习,不再赘述,读者自行完成即可
- 文本处理
- 创建文本:
d = Document(text='hello, world.') - 获得文本数据:
print(d.text) - 获取URI文本:
d = Document(uri='https://www.w3.org/History/19921103-hypertext/hypertext/README.html')d.load_uri_to_text()
- 切割:
d.chunks.extend([Document(text=c) for c in d.text.split('!')]) # 按'!'分割 - text、ndarray互相转换
from jina import DocumentArray, Documentda = DocumentArray([Document(text='hello world'), Document(text='goodbye world'),Document(text='hello goodbye')])- 输出text:
da.get_vocabulary() - 将文本转为tensor:
d.convert_text_to_tensor(vocab, max_length=10)- d表示一个Document
- 打印d.tensor即可将文本转换为向量形式
- tensor转文本:
d.convert_tensor_to_text(vocab)- d表示一个ndarray
- 打印d.text即可得到文本形式
- 文本匹配
- 创建文本:
- 图像处理
- 读取与转tensor
d = Document(uri='apple.png')d.load_uri_to_image_tensor()
- 图像处理
- 设置shape:
.set_image_tensor_shape(shape=(224, 224)) - 标准化:
.set_image_tensor_normalization() - 更改通道:
.set_image_tensor_channel_axis(-1, 0) - tensor转图像:
.save_image_tensor_to_file('apple-proc.png', channel_axis=0)
- 设置shape:
- 读取图像集
- 从文件夹读取所有jpg图片:
DocumentArray.from_files('./*.jpg') - 绘制图片集图片:
.plot_image_sprites('sprite-img.png')
- 从文件夹读取所有jpg图片:
- 切割图像
- 使用 64*64 的滑窗切割原图像,切分出 12*15=180 个图像张量:
.convert_image_tensor_to_sliding_windows(window_shape=(64, 64), strides=(10, 10), as_chunks=True)- strides:采用滑动窗口扫描整个图像,此处可以进行过采样
- as_chunks:设置为True,可以使得上述 180 张图片张量添加到 Document 块中
- 使用 64*64 的滑窗切割原图像,切分出 12*15=180 个图像张量:
- 读取与转tensor
- 视频处理
- 导入与切分
d = Document(uri='toy.mp4')d.load_uri_to_video_tensor()for b in d.tensor:d.chunks.append(Document(tensor=b))d.chunks.plot_image_sprites('mov.png')
- 关键帧提取
- 我们从视频中提取的图像,很多都是冗余的,可以使用
only_keyframes这个参数来提取关键帧 d.load_uri_to_video_tensor(only_keyframes=True)
- 我们从视频中提取的图像,很多都是冗余的,可以使用
- 张量转视频
- 可以使用
save_video_tensor_to_file进行视频的保存 Document(uri='toy.mp4').load_uri_to_video_tensor() .save_video_tensor_to_file('60fps.mp4', 60)
- 可以使用
- 导入与切分
- Executer
- Executor 可以看作一个 python 类,用于在 DocumentArray 上执行一系列任务
- Flow
- 可以理解为一系列任务的协调器,通过 add 方法可以将多个 Executor 串成一套执行逻辑