OpenCV 神经网络 - 多层感知器(MLP)
一、简述
人工神经网络(ANN) 简称神经网络(NN),能模拟生物神经系统对物体所作出的交互反应,是由具有适应性的简单单元(称为神经元)组成的广泛并行互连网络。
二、M-P神经元
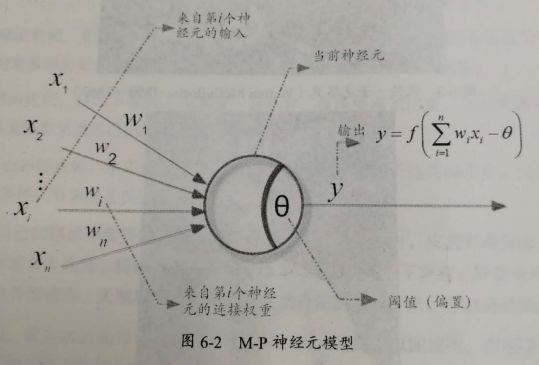
“M-P神经元模型”(McCulloch and Pitts,1943)是开创性的人工神经元模型,将复杂的生物神经元活动通过简单的数学模型表示出来,提出最早且影响最大。
如下图所示,来自其它神经元的信号,![]() ,传递过来作为输入信号,并通过带权重
,传递过来作为输入信号,并通过带权重![]() 的连接 (connection) 继续传递,然后神经元的总输入值
的连接 (connection) 继续传递,然后神经元的总输入值![]() 与阈值 θ 作比较,最后经过激活函数f产生神经元的输出:
与阈值 θ 作比较,最后经过激活函数f产生神经元的输出: 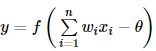
三、多层感知器(MLP)
1、介绍
多层感知器(Multi-Layer Perceptron,MLP)也叫人工神经网络(Artificial Neural Network,ANN),是常见的一种ANN算法。MLP算法一般包括三层,分别是一个输入层、一个或多个隐藏层、一个输出层的神经网络组成。每一层由一个或多个神经元互相连结,且一个“神经元”的输出便是另一个“神经元”的输入。最简单的MLP需要有一层隐层,即输入层、隐层和输出层才能称为一个简单的神经网络,习惯原因我之后会称为神经网络。
通俗而言,神经网络是仿生物神经网络而来的一种技术,通过连接多个特征值,经过线性和非线性的组合,最终达到一个目标,这个目标可以是识别这个图片是不是一只猫,是不是一条狗或者属于哪个分布。
2、感知机(perceptron)
感知机由两层神经元组成,输入层接收外界输入信号,而输出层则是一个 M-P 神经元。 实际上,感知机可视为一个最简单的“神经网络”,用它可很容易的实现逻辑与、或、非等简单运算。

3、层级结构
常见的神经网络,可分为三层:输入层、隐含层、输出层。输入层接收外界输入,隐层和输出层负责对信号进行加工,输出层输出最终的结果。
以下图为例:每层神经元与下一层神经元全互连,而同层神经元之间不连接,也不存在跨层连接,这样的结构称为“多层前馈神经网络”(multi-layer feedforward neural networks)

4、神经网络工作流程
以下图中单隐层的神经网络为例,说一下神经网络的具体流程。大致模型如图所示:

首先我们先对图中的参数做一个解释:
其中,第0层(输入层),我们将x1,x2和x3向量化为X;0层和1层(隐层)之间,存在权重w1(x1到各个隐层),w2...w4,向量化为W[1];注:其中[1]表示第1层的权重,偏置b同理;
(1)第1层
对于第1层,计算公式为:
Z[1] = W[1]X + b[1]
A[1] = sigmoid(Z[1])
其中Z为输入值的线性组合,A为Z通过激活函数sigmoid的值,对于第1层的输入值为X,输出值为A,也是下一层的输入值;
(2)第2层
1层和2层(输出层)之间,与0层和1层之间类似,其计算公式如下:
Z[2] = W[2]A[1] + b[2]
A[2] = sigmoid(Z[2])
yhat = A[2]
其中yhat即为本次神经网络的输出值。
5、激活函数
关于激活函数,首先要搞清楚的问题是,激活函数是什么,有什么用?不用激活函数可不可以?答案是不可以。激活函数的主要作用是提供网络的非线性建模能力。如果没有激活函数,那么该网络仅能够表达线性映射,此时即便有再多的隐藏层,其整个网络跟单层神经网络也是等价的。因此也可以认为,只有加入了激活函数之后,深度神经网络才具备了分层的非线性映射学习能力。 那么激活函数应该具有什么样的性质呢?
可微性: 当优化方法是基于梯度的时候,这个性质是必须的。
单调性: 当激活函数是单调的时候,单层网络能够保证是凸函数。
输出值的范围: 当激活函数输出值是 有限 的时候,基于梯度的优化方法会更加 稳定,因为特征的表示受有限权值的影响更显著;当激活函数的输出是 无限 的时候,模型的训练会更加高效,不过在这种情况小,一般需要更小的learning rate
从目前来看,常见的激活函数多是分段线性和具有指数形状的非线性函数
(1)sigmoid

sigmoid 是使用范围最广的一类激活函数,具有指数函数形状,它在物理意义上最为接近生物神经元。此外,(0, 1) 的输出还可以被表示作概率,或用于输入的归一化,代表性的如Sigmoid交叉熵损失函数。
然而,sigmoid也有其自身的缺陷,最明显的就是饱和性。从上图可以看到,其两侧导数逐渐趋近于0
![]()
具有这种性质的称为软饱和激活函数。具体的,饱和又可分为左饱和与右饱和。与软饱和对应的是硬饱和, 即
![]()
sigmoid 的软饱和性,使得深度神经网络在二三十年里一直难以有效的训练,是阻碍神经网络发展的重要原因。具体来说,由于在后向传递过程中,sigmoid向下传导的梯度包含了一个 f′(x)因子(sigmoid关于输入的导数),因此一旦输入落入饱和区,f′(x)就会变得接近于0,导致了向底层传递的梯度也变得非常小。此时,网络参数很难得到有效训练。这种现象被称为梯度消失。一般来说, sigmoid 网络在 5 层之内就会产生梯度消失现象。
此外,sigmoid函数的输出均大于0,使得输出不是0均值,这称为偏移现象,这会导致后一层的神经元将得到上一层输出的非0均值的信号作为输入。
(2)Tanh

tanh也是一种非常常见的激活函数。与sigmoid相比,它的输出均值是0,使得其收敛速度要比sigmoid快,减少迭代次数。然而,从途中可以看出,tanh一样具有软饱和性,从而造成梯度消失。
(3)ReLU,P-ReLU, Leaky-ReLU
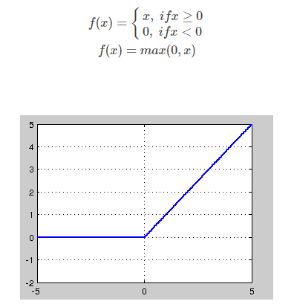
关于ReLU的介绍参考链接。ReLU的全称是Rectified Linear Units,是一种后来才出现的激活函数。 可以看到,当x<0时,ReLU硬饱和,而当x>0时,则不存在饱和问题。所以,ReLU 能够在x>0时保持梯度不衰减,从而缓解梯度消失问题。这让我们能够直接以监督的方式训练深度神经网络,而无需依赖无监督的逐层预训练。
然而,随着训练的推进,部分输入会落入硬饱和区,导致对应权重无法更新。这种现象被称为“神经元死亡”。与sigmoid类似,ReLU的输出均值也大于0,偏移现象和 神经元死亡会共同影响网络的收敛性。
针对在x<0的硬饱和问题,我们对ReLU做出相应的改进,使得
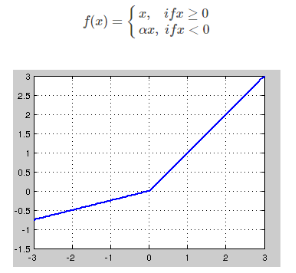
这就是Leaky-ReLU, 而P-ReLU认为,α也可以作为一个参数来学习,原文献建议初始化a为0.25,不采用正则。
(4)ELU
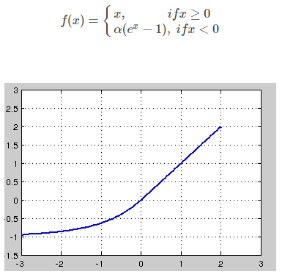
融合了sigmoid和ReLU,左侧具有软饱和性,右侧无饱和性。右侧线性部分使得ELU能够缓解梯度消失,而左侧软饱能够让ELU对输入变化或噪声更鲁棒。ELU的输出均值接近于零,所以收敛速度更快。在 ImageNet上,不加 Batch Normalization 30 层以上的 ReLU 网络会无法收敛,PReLU网络在MSRA的Fan-in (caffe )初始化下会发散,而 ELU 网络在Fan-in/Fan-out下都能收敛。
(5)Maxout
![]()
在我看来,这个激活函数有点大一统的感觉,因为maxout网络能够近似任意连续函数,且当w2,b2,…,wn,bn为0时,退化为ReLU。Maxout能够缓解梯度消失,同时又规避了ReLU神经元死亡的缺点,但增加了参数和计算量。
对于激活函数的选择,是神经网络中很重要的一步,对比sigmoid函数和tanh函数在不同层的使用效果:
- 隐藏层:tanh函数的表现要好于sigmoid函数,因为tanh的取值范围在[-1,1]之间,均值为0,实际上起到了归一化(使图像分布在0周围,得到的结果更方便使用梯度下降)的效果。
- 输出层:对于二分类而言,实际上是在计算yhat的概率,在[0,1]之间,所以sigmoid函数更优。
然而在sigmoid函数和ReLU函数中,当Z很大或很小时,Z的导数会变得很小,趋紧于0,这也称为梯度消失,会影响神经网络的训练效率。
ReLU函数弥补了二者的缺陷,当z>0时,梯度始终为1,从而提高神经网络的运算速度。然而当z<0时,梯度始终为0。但在实际应用中,该缺陷影响不是很大。
Leaky ReLU是对ReLU的补偿,在z<0时,保证梯度不为0。
怎么选择激活函数呢?
我觉得这种问题不可能有定论的吧,只能说是个人建议。
如果你使用 ReLU,那么一定要小心设置 learning rate,而且要注意不要让你的网络出现很多坏死的 神经元,如果这个问题不好解决,那么可以试试 Leaky ReLU、PReLU 或者 Maxout.
友情提醒:最好不要用 sigmoid,你可以试试 tanh,不过可以预期它的效果会比不上 ReLU 和 Maxout.
还有,通常来说,很少会把各种激活函数串起来在一个网络中使用的。
总结而言:在选择激活函数的时候,如果不知道该选什么的时候就选择ReLU,当然具体训练中,需要我们去探索哪种函数更适合。
6、损失函数
参考链接:链接1 链接2
7、Backprop
BP(Back Propagation)神经网络是1986年由Rumelhart和McCelland为首的科研小组提出,参见他们发表在Nature上的论文 Learning representations by back-propagating errors 。
BP神经网络是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一。BP网络能学习和存贮大量的 输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。它的学习规则是使用最速下降法,通过反向传播来不断 调整网络的权值和阈值,使网络的误差平方和最小。
BP算法的基本思想
上一次我们说到,多层感知器在如何获取隐层的权值的问题上遇到了瓶颈。既然我们无法直接得到隐层的权值,能否先通过输出层得到输出结果和期望输出的误差来间接调整隐层的权值呢?BP算法就是采用这样的思想设计出来的算法,它的基本思想是,学习过程由信号的正向传播与误差的反向传播两个过程组成。
- 正向传播时,输入样本从输入层传入,经各隐层逐层处理后,传向输出层。若输出层的实际输出与期望的输出(教师信号)不符,则转入误差的反向传播阶段。
- 反向传播时,将输出以某种形式通过隐层向输入层逐层反传,并将误差分摊给各层的所有单元,从而获得各层单元的误差信号,此误差信号即作为修正各单元权值的依据。
参考链接:https://blog.csdn.net/u013007900/article/details/50118945
关于神经网络的原理介绍,这里有份赵春江的《机器学习经典算法剖析基于OpenCV》相关内容截图:

四、MLP在OpenCV中的实现
1、数据准备
//每个像素RGB的宽度(即每个样本的长度;这里将一个像素作为一个像本)
const int pixelsLen = 3;
//物料只分1类(通过标签 1、-1 来区分透明和浅黄)
const int materielTypeSum = 1;
//每类物料共有像素个数
const int materielsSum = 3000;
//样本的总数量【每行为一个像本】
const int dataHeight = materielTypeSum * materielsSum;
//每一行一个像素
float trainingData[dataHeight][pixelsLen] = { {0} };
//训练样本标签
float labels[dataHeight][materielTypeSum] = { {0} };
//训练样本数据 及 对应标签
Mat trainingDataMat(dataHeight, pixelsLen, CV_32FC1, trainingData);
Mat labelsMat(dataHeight, materielTypeSum, CV_32FC1, labels);2、创建模型
Ptr model = ANN_MLP::create(); 3、神经网络层数设置
Mat layerSizes = (Mat_(1, 2) << pixelsLen, materielTypeSum); //只有2层:输入层和输出层(未加入隐藏层),且输入为pixelsLen,输出为materielTypeSum
model->setLayerSizes(layerSizes); //创建层数 4、训练方法
model->setTrainMethod(ANN_MLP::BACKPROP, 0.001, 0.1); //训练方法OpenCV里提供了两个方法一个是很经典的反向传播算法BACKPROP,另一个是弹性反馈算法RPROP,我使用的是BACKPROP。
关于每种训练方法的相关参数,针对于反向传播法,主要是两个参数,一个是权值更新率bp_dw_scale和权值更新冲量bp_moment_scale。这两个量一般情况设置为0.1就行了;太小了网络收敛速度会很慢,太大了可能会让网络越过最小值点。
5、激活函数
model->setActivationFunction(ANN_MLP::SIGMOID_SYM, 1.0, 1.0); //激活函数一般情况下我们用SIGMOID函数就可以了,当然你也可以选择正切函数或高斯函数作为激活函数。
OpenCV3里提供了三种激活函数,线性函数(CvANN_MLP::IDENTITY)、sigmoid函数(CvANN_MLP::SIGMOID_SYM)和高斯激活函数(CvANN_MLP::GAUSSIAN)。且训练方法只有BACKPROP 和 RPROP。

而OpenCV4中提供了5种激活方法 ,多了RELU 和 LEAKYRELU 。训练方法也多了一个ANNEAL。

6、设置迭代终止准则
model->setTermCriteria(TermCriteria(TermCriteria::MAX_ITER | TermCriteria::EPS, 10000, 0.0001)); //设置迭代终止准则
迭代次数设置成10000次7、训练
Ptr trainData = TrainData::create(trainingDataMat, ROW_SAMPLE, labelsMat); //创建训练数据,ROW_SAMPLE表示data中每行为一个样本
model->train(trainData); //训练 8、保存
//保存训练结果
model->save("E:/vs2017Project/Number_MLP/Number_MLP/MLPModel.xml");9、输出参数
//输出权重参数和偏置
Mat outWeightMat = model->getWeights(1);
cout << "type = " << outWeightMat.type() << endl; //CV_64F(double类型)
double *data1 = outWeightMat.ptr(0);
double *data2 = outWeightMat.ptr(1);
double *data3 = outWeightMat.ptr(2);
double *data4 = outWeightMat.ptr(3);
g_fWeightR = (float)*data1;
g_fWeightG = (float)*data2;
g_fWeightB = (float)*data3;
g_fOffset = (float)*data4; 可利用这些参数来计算并判断结果分类;
10、预测
Mat_ testMat(1, pixelsLen);
testMat.at(0, 0) = 172.0 / 255;
testMat.at(0, 1) = 186.0 / 255;
testMat.at(0, 2) = 212.0 / 255;
//使用训练好的MLP model预测测试图像
Mat result;
model->predict(testMat, result);
cout << "testMat: " << testMat << endl;
float *p = result.ptr(0);
std::cout << "测试结果:" << *p << std::endl;
参考链接:
https://blog.csdn.net/akadiao/article/details/79236458
https://blog.csdn.net/xiaowei_cqu/article/details/9027617
OpenCV接口说明文档
https://blog.csdn.net/qq_32768679/article/details/90027652
https://blog.csdn.net/weixin_38206214/article/details/81137911
https://www.cnblogs.com/xinxue/p/5789421.html