新鲜出炉!ECCV2022 107个开源数据集合辑,全球 AI 研究热点一网打尽
两年一度的ECCV2022终于在万众瞩目下召开啦,相信有不少小伙伴们对今年ECCV发布的新方向、新算法和新数据集十分感兴趣。今天小编从数据集的角度入手,给大家精选了ECCV2022发布的8个数据集,囊括了庞大的标注数据和新奇又有趣的任务,欢迎大家速速来围观!
本文还有一个超大福利:ECCV 2022数据集合辑。小编们呕心沥血地对ECCV2022的1600多篇接收文章进行了筛选,最终获取了107个数据集,并按照任务类型进行了整理,小伙伴们快来看看有没有你们中意的数据集吧!
OpenDataLab也将陆续整理上架这些开源数据集资源,敬请关注~
本文由两部分组成:
1. ECCV2022精选数据集介绍
包含了8个数据集的详细介绍。从任务类型和引用率的角度考虑,挑选了8个数据集进行简单的介绍(包括标注类型、应用场景、论文中的关键结果图等)。
2. ECCV2022数据集合辑
包含107个数据集名单。对107个数据集进行了粗粒度和细粒度的任务类型划分,并提供了相应的文章链接,并辅以简单说明。
(完整信息请访问OpenDataLab的Github数据集主页,或联系小助手获取)
一、精选数据集介绍
该部分包括多个任务领域的8个数据集的详细介绍:
● HuMMan (4D人体感知和建模)
● OpenLane/Waymo (自动驾驶)
● PartImageNet (零部件分割)
● Sherlock (溯因推理)
● MovieCuts (视频剪辑类型识别)
● DexMV (机器人模仿学习)
● ViCo (视频生成-倾听者反馈)
No.1 HuMMan
4D人体感知和建模是视觉和图形领域的基本任务,具有多种应用。随着新传感器和算法的进步,对更通用数据集的需求越来越大。HuMMan[1]是一个大型多模态4D人体数据集,包含1000个人体对象、400k序列和60M帧。
HuMMan的特点在于:
1) 多模态数据和注释,包括彩色图像、点云、关键点、SMPL参数和纹理网格;
2) 传感器套件中包括主流的移动设备;
3) 囊括了500个动作,涵盖了人体活动的基本动作;
4) 支持和评估多种任务,如动作识别、姿势估计、参数化人体恢复和纹理网格重建。

图1. HuMMan具有多种数据格式和注释形式:a)彩色图像,b)点云,c)关键点,d)SMPL参数,e)网格,f)纹理。每个序列还带有来自500个动作的动作标签注释。每个受试者都有两个额外的高分辨率扫描,对自然和衣着最少的身体进行扫描[1]
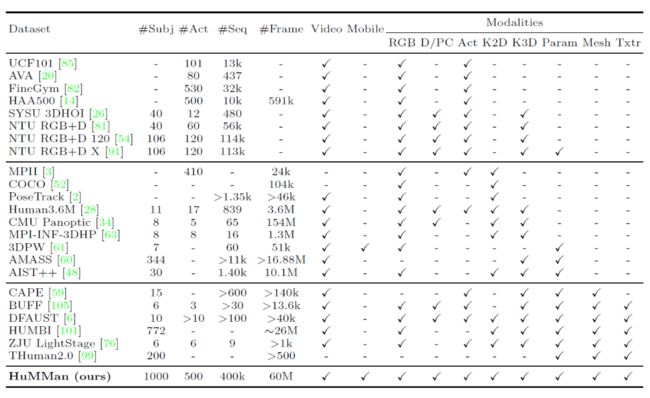
表1. HuMMan与已发布数据集的比较[1]
HuMMan在受试者数量(#Subj)、动作(#Act)、序列(#Seq)和帧(#Frame)方面具有竞争力。数据来源分为:视频,即连续数据,不限于RGB序列;移动,即传感器套件中的移动设备。
此外,HuMMan具有多种模式标注用于支持多种任务,包括:RGB,即三波段图像;D/PC,即深度图像或点云,仅考虑从深度传感器采集的真实点云;Act,即动作标签;K2D,即二维关键点;K3D,即3D关键点;Param,即统计模型(如SMPL)参数;Mesh,即网格,Txtr,即纹理。
HuMMan的大量实验表明,在多个诸如细粒度动作识别、动态人体网格重建、基于点云的参数化人体恢复和跨设备域间隙等等研究领域,仍存在较多挑战,具有很大的研究空间。
HuMMan数据集链接:https://caizhongang.github.io/projects/HuMMan/
为方便AI研究员们,OpenDataLab 已收录该数据集资源,打开链接(https://opendatalab.org.cn/OpenXD-HuMMan),即可免费、高速下载。
No.2&3 OpenLane/Waymo
OpenLane[2]是迄今为止第一个真实世界3D车道数据集,也是目前为止最大规模的,拥有200K帧和880K条经过仔细注释的车道。
该数据集从公众感知数据集Waymo Open dataset[3]收集有价值的内容,并为1000个segment提供车道和最近路径对象(closest-in-path object, CIPO)注释。
车道注释包括:
● 车道形状。每个2D/3D车道都显示为一组2D/3D点。
● 车道类别。每条车道都有一个类别,例如双黄线或路缘。
● Lane属性。有些车道具有右车道、左车道等特性。
● 车道跟踪ID。除路缘外,每条车道都有唯一的ID。
● 停车线和路缘石。
CIPO/场景注释包括:
● 二维边界框。其类别表示对象的重要性级别。
● 场景标记。它描述了在哪个场景中收集此帧。
● 天气标签。它描述了这个框架是在什么天气下收集的。
● 小时标签。它会注释收集此帧的时间。
(具体可见:https://github.com/OpenPerceptionX/OpenLane/blob/main/anno_criterion/CIPO/README.md)

图2. OpenLane的标注示例[2]
Waymo Open dataset[3]也是ECCV 2022接收文章中公开的数据集,提供了激光雷达和相机这两种传感器上的独立标注,标注类型包括:车辆和行人的3D Lidar检测和分割、2D相机检测和分割(包括图片和视频)、2D-to-3D correspondence,以及人体关键点标注等。

图3. Waymo的标注示例(https://waymo.com/open/data/perception/)
OpenLane数据集链接:https://github.com/OpenPerceptionX/OpenLane
Waymo数据集链接:https://waymo.com/open/
为方便AI研究员们,OpenDataLab 已收录该数据集资源,打开链接(https://opendatalab.org.cn/OpenLane),即可免费、高速下载。
No.4 PartImageNet
PartImageNet[4]是一个具有零部件分段注释的大型高质量数据集。
它由ImageNet[5]中的158个类组成,大约有24000个图像。这些类别被分为11个super-categories,零件分割是根据super-categories设计的,如下所示(类别名称后面括号中的数字表示该super-categories下包含的子类别总数):
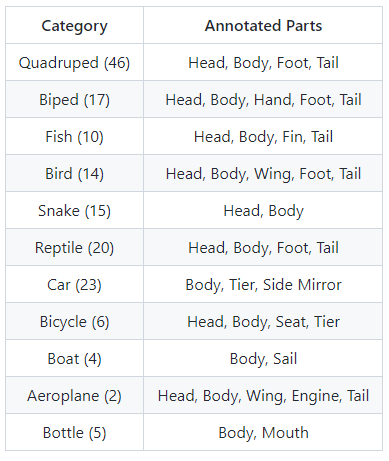
表2. PartImageNet的标注类别[4]
PartImageNet在众多研究领域具有广泛的潜力,包括零件发现、少样本学习和语义分割中的应用等。以下是该数据集中一些测试图像在不同模型下获得的效果:
图4. PartImageNet标注示例和模型测试结果示例(来源为数据集官网)
PartImageNet数据集链接:https://github.com/TACJu/PartImageNet
No.5 Sherlock
Sherlock[6]是一个结合图片实例级框标注和文字标注的的数据集,任务的目标是给定图像中的某部分内容,以及一段指引性的线索,让机器去推断这部分内容包含的一些信息或者正在发生的事件,即溯因推理。
语料库中包括103K幅图像中的363K个推理。每个图像包含多个边界框,每个边界框中包含文字线索和推理文本标注,总共收集了363K(线索、推理)对,形成了第一个此类外展性视觉推理数据集。
下面给出了其中一个性能最好的模型的预测示例,以及人类注释:

图5. Sherlock数据集标注示例和模型预测示例(来源为数据集官网)
Sherlock数据集链接:http://visualabduction.com/
No.6 MovieCuts
MovieCuts[7]是一个视频及剪辑标注的大型数据集,包含173967个视频剪辑,这些视频剪辑被标记为10种不同的剪辑类型。数据集中的每个样本都由两个视频片段(将一段视频从中剪辑拆分开)及其附带的音频组成。
该数据集主要针对一种新的任务:视频剪辑类型识别。视频剪辑指的是将两段视频拼接在一起,并且拼接之后的视频看起来具有连续性,不会太突兀。视频剪辑类型识别则是要识别出两段视频是通过何种方式拼接在一起的。
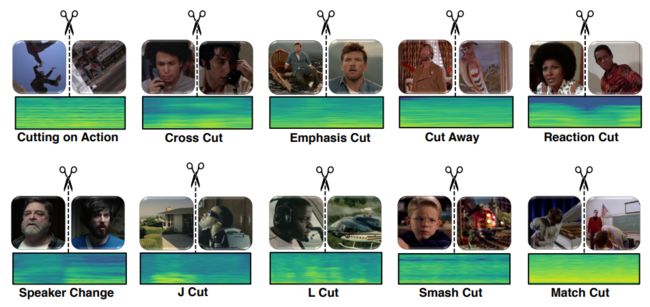
图6. MovieCuts数据集中的剪辑类型[7]:剪辑类型分为两个大类:视觉驱动(第一行)和视听驱动(第二行)
该文章对一系列视听方法进行了基准测试,包括一些处理问题的多模式和多标签性质的方法。最佳模型仅达到45.7%mAP,这表明实现高精度的剪辑类型识别是一个开放且有挑战性的问题。
MovieCuts数据集链接:https://www.alejandropardo.net/publication/moviecuts/
No.7 DexMV
虽然在计算机视觉中理解手-物体相互作用方面取得了重大进展,但机器人执行复杂的灵巧操作仍然是一项非常具有挑战性的任务。DexMV[8]就是为了人体视频中灵巧操作的模仿学习任务而创建的数据集,用于改善机器人执行复杂的灵巧操作。
DexMV包含了一个平台和pipline,包括:(a)一个多指机器人手复杂灵巧操作任务的仿真系统,(b)一个计算机视觉系统,用于记录执行相同任务的人手的大规模演示。并从视频中进行3D手和物体的姿态估计,最后将人体运动转换为机器人演示。文章应用并比较了多种模拟学习算法和演示。结果表明,演示确实可以大幅度改进机器人学习,并解决强化学习单独无法解决的复杂任务。

图7.DexMV平台和pipline[8]: 平台由计算机视觉系统(黄色)、仿真模拟系统(蓝色)和演示翻译模块(绿色)组成。计算机视觉系统收集人类操纵视频。在仿真模拟系统中为机器人手设计了相同的任务。应用视频中的3D手对象姿势估计,然后通过演示翻译模块生成机器人演示,用于模拟学习
该文章对一系列视听方法进行了基准测试,包括一些处理问题的多模式和多标签性质的方法。最佳模型仅达到45.7%mAP,这表明实现高精度的剪辑类型识别是一个开放且有挑战性的问题。
DexMV数据集链接:https://yzqin.github.io/dexmv/
No.8 ViCo
ViCo[9]数据集主要是用于上下文理解的视觉面部表情生成,应用场景为在面对面交谈中生成听众的反应反馈(例如点头、微笑)。
ViCo共涉及92种身份(67位发言者和76位听众)和483个视频音频片段,采用配对“说-听”模式,听众(listener)根据说话者(speaker)的语音以及视频实时生成态度不同的反应反馈(积极、中立、消极)。与传统的语音到手势或说话头部生成不同,倾听者头部生成利用来自说话者的音频和视频信号作为输入,并实时提供非语言的反馈(例如头部运动、面部表情)。
该数据集支持广泛的应用,例如人与人的交互、视频与视频的转换、跨模式理解和生成。

图8.真实标注和模型生成的听众反馈(来源为数据集官网)
数据集由三部分组成:
● videos/*.mp4: 所有的视频(不包含音频)
● audios/*.wav: 所有的音频
● *.csv: 返回的元数据(具体字段见表3)

表3.元数据包含的字段(来源为数据集官网)
ViCo数据集链接:https://project.mhzhou.com/vico
二、ECCV2022数据集合辑
根据本次ECCV2022的107个数据集涉及到的任务类型,从几个大方向对数据集进行了粗分类:,(详情名单点击标题查看)
● 分类、检测、跟踪、分割、关键点和识别(40个)
● 图像处理和生成(21个)
● 多模态(20个)
● 其他(26个)
数据集来源论文、数据下载链接等完整信息,可访问OpenDataLab Github 数据集主页,或添加小助手获取哦。)
参考文献
[1] Cai Z, Ren D, Zeng A, et al. HuMMan: Multi-Modal 4D Human Dataset for Versatile Sensing and Modeling[J]. arXiv preprint arXiv:2204.13686, 2022. [2] Chen L, Sima C, Li Y, et al. PersFormer: 3D Lane Detection via Perspective Transformer and the OpenLane Benchmark[J]. arXiv preprint arXiv:2203.11089, 2022. [3] Mei J, Zhu A Z, Yan X, et al. Waymo open dataset: Panoramic video panoptic segmentation[J]. arXiv preprint arXiv:2206.07704, 2022. [4] He J, Yang S, Yang S, et al. Partimagenet: A large, high-quality dataset of parts[J]. arXiv preprint arXiv:2112.00933, 2021. [5] Deng J, Dong W, Socher R, et al. Imagenet: A large-scale hierarchical image database[C]//2009 IEEE conference on computer vision and pattern recognition. Ieee, 2009: 248-255. [6] Hessel J, Hwang J D, Park J S, et al. The abduction of sherlock holmes: A dataset for visual abductive reasoning[J]. arXiv preprint arXiv:2202.04800, 2022. [7] Pardo A, Heilbron F C, Alcázar J L, et al. Moviecuts: A new dataset and benchmark for cut type recognition[J]. arXiv preprint arXiv:2109.05569, 2021. [8] Qin Y, Wu Y H, Liu S, et al. Dexmv: Imitation learning for dexterous manipulation from human videos[J]. arXiv preprint arXiv:2108.05877, 2021. [9] Zhou M, Bai Y, Zhang W, et al. Responsive Listening Head Generation: A Benchmark Dataset and Baseline[J]. arXiv preprint arXiv:2112.13548, 2021.
- End -
以上就是本次分享,获取海量数据集资源,请访问OpenDataLab官网;获取更多开源工具及项目,请访问OpenDataLab Github空间。另外还有哪些想看的内容,快来告诉小助手吧。更多数据集上架动态、更全面的数据集内容解读、最牛大佬在线答疑、最活跃的同行圈子……欢迎添加微信opendatalab_yunying加入OpenDataLab官方交流群。