《Marrying Up Regular Expressions with Neural Networks》神经网络结合正则表达式
阅读感想:这篇文章区别于前两篇更新的文章,前面两篇文章都是对神经网络的输出部分进行规则(正则表达式)融合,而这篇则是从输入、神经模型层和输出三个角度融合。
问题背景:神经网络训练需要大量数据,相比之下,手工定义的规则更加简洁、解释性强并且不依赖数据。但是规则也有泛化性能差,必须要定义所有的同义词和变体等缺点。规则的缺点恰巧神经网络可以解决,于是作者便通过三个不同的角度在少样本数据和全样本数据上面设计他的实验,实验是在意图检测和槽填充两个任务进行。
本文提出在三个不同的角度来进行规则融合,对应每个图中的1,2,3:
Input Level: 将规则的输出作为神经网络输入特征的一部分。
Network Module Level: 将规则里面编码的知识来引导神经网络的attention机制。
Output Level: 将规则的评估结果和神经网络的输出使用一种可学习的方式来结合。
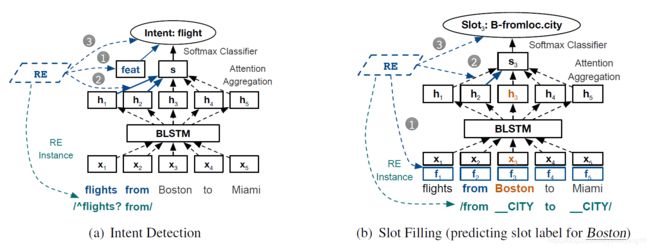
Base Models:
我们使用BLSTM作为基本的神经网络模型,attention使用如下:

Using REs at the Input Level:
我们将规则的输出作为神经网络输入特征的一部分添加上去。
(1)Intent Detection:一个用于意图检测的句子可能满足多个标签,从而产生REtags相互冲突,为了解决上述矛盾冲突,对随机初始化的可训练标签进行平均形成聚合embedding作为输入,这里有两种方式来使用聚合embedding。(1)将聚合标签加到每个word embedding的后面。(2)将聚合标签加到softmax classifier的后面。根据我们设计的测试实验,发现第二种更好。
(2)Slot Filling: 因为Slot RE的评测结果是字级别的,所以我们可以把REtags嵌入并且平均到每个字的向量,并将其加到对应的word embedding后面。
Using REs at the Network Module Level:
在神经网络模块层面,我们主要是探讨怎么使用RE中的线索词语来引导神经网络中的attention模块。
(1)Intent Detection:结合原有的attention方法,我们做了两个修改:
a. 首先,原先对于所有意图标签我们都使用同一个sentence embedding,这样导致attention被削弱,因此我们在这里首先对于每个Intent label K都使用不同的注意力ai,ai被用来产生对于该intent的句子embedding sk:
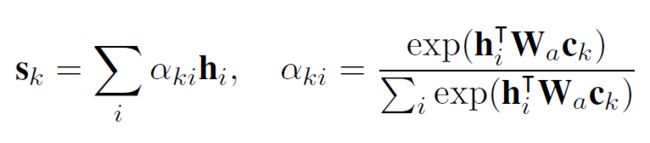
相应的,我们可以得到对于该输入句子某个Intent label对应的概率Pk:

b. 其次,对于某个intent label来说一个规则除了可以表示肯定,也有表示否定的能力,于是我们可以给出一组新的attention——正向和负向的attention,我们需要对上述a中的公式进行如下修改:
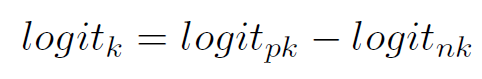
并且,在最终的损失函数中,我们加上:

最终的attention loss可以写作:
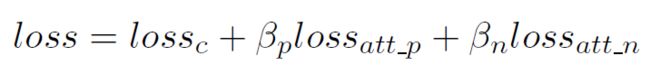
(2)相对于意图检测,槽填充需要计算每个单词的attention,太浪费资源了,于是使用了一个简化版本的attention机制,所有的槽标签分享同一组positive和negative attention,特别的,为了预测单词i对应的slot label,我们给出如下关于单词i对应于positive attention的sentence embedding:

最终,我们给出关于word i的预测标签Pi:
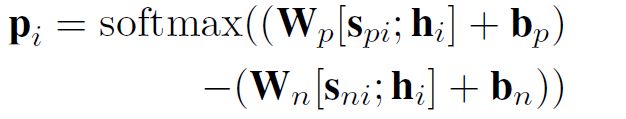
Using REs at the Output Level:
在输出的时候,规则的作用是用来修改神经网络的输出,这个层次,我们对于intent detecting和Slot Filling使用同样的方法。

其中logit'是原先神经网络的输出,Wk是对于产生目标标签k的规则的置信度的可训练权重,zk是一个0-1指示符,表示是否至少有一条规则满足目标标签k。 末尾,作者说了一下为什么使用logit而不是概率,因为logit是一个无限制的值,对于wkzk的匹配能力要强于概率,我理解是logit就是没有归一化的概率。
结论:
本文是规则与神经网络结合的另一篇文章,从输入、网络层和输出三个方面来给出结合方式。相比于前面两篇文章,作者在输出方面也有满足度这一体现——可训练权重wk,但是文章没有详细说明怎么得到wk。