[论文阅读笔记62]KnowPrompt - Knowledge-aware Prompt-tuning with Synergistic Optimization for RE
1. 题目
KnowPrompt: Knowledge-aware Prompt-tuning with Synergistic Optimization for Relation Extraction
the paper has been accepted by WWW2022.
Alibaba Group && Zhejiang University
2. 模型
2.1 摘要
把关系标签之间的知识整合到关系提取的prompt-tuning中,并提出了一种使用协同优化的Knowledge-aware Prompt-tuning方法(KnowPrompt)。
首先把关系的潜在知识注入到带有可学习的虚拟类型词与回答词的prompt的构造中,然后,用结构化约束协同优化prompt的表示;最后,在5个数据集之上对于标准与low-resource的情况进行了实验,并开源了代码【2】。
2.2 问题及最近提出
fine-tuning的缺点: 需要进一步进行训练,还需要花费人工与大量时间去标注数据,给模型一般化操作带有麻烦。
最近的prompt-tuning方法:[11, 18, 27, 43, 44] —采用预训练的模型直接作为预测器,通过完形填空的任务为pre-training与fine-tuning之间搭上桥梁。prompt-tuning将原始输入与提示模板融合来预测[MASK],然后将预测的标签词映射到相应的类集,对PLMs在few-shot任务上这种方法已经有很好的效果了。
例如(a),Prompt for Text Classification,文本分类典型,由一个模板(“<1> It is [MASK] ”)与一个标签词集(“great”, “terrible”etc.)。
总的来说,prompt-tuning包括了模板工程与语言表达工程,目标是去搜索最佳的模板与答案空间。[35] – 刘鹏飞的综述中提到的
在文本分类上有些成就,对于RE的问题:
第一方面:确定模型要领域专家或者自动生成要额外的资源;
第二方面:当关系标签变化时标签词的搜索计算高复杂度,经常是类别的指数;
例如(b)©, 如果一对实体包含“person”和“country”的语义,则关系“org:city_of_headquarters”对[MASK]的预测概率应该是低的;
加入关系知识(实体的类型)对于关系抽取是有帮助的 [4, 13, 33],注入知识是论文的研究重点—KnowPrompt。
通过可学习的虚拟回答词和虚拟类型词来构建具有知识注入的提示词;可学习的虚拟类型词来根据上下文进行动态调整,而不是利用标注的实体类型.
![[论文阅读笔记62]KnowPrompt - Knowledge-aware Prompt-tuning with Synergistic Optimization for RE_第1张图片](http://img.e-com-net.com/image/info8/65eee0b5843a46118b4faf23d8892719.jpg)
2.3 方法
![[论文阅读笔记62]KnowPrompt - Knowledge-aware Prompt-tuning with Synergistic Optimization for RE_第2张图片](http://img.e-com-net.com/image/info8/f41f6d796a334569ab8e97fa549b8cbe.jpg)
Entity Knowledge Injection
![[论文阅读笔记62]KnowPrompt - Knowledge-aware Prompt-tuning with Synergistic Optimization for RE_第3张图片](http://img.e-com-net.com/image/info8/1517ec12f4f94804921d136e36e2a7c0.jpg)
表示围绕在sub与obj的虚拟类型词的嵌入表示。I(.)函数是去重操作,是先验分布, 在这里是通过词频来统计的。例如根据表可以计算** = {“” : 3/6*,*“” : 3/6}。e表示预训练所给的向量嵌入。
这个意思就是说,先把各个sub的词向量找出来,然后就是把每个sub的权重计算出来,最后就是加权求和形成新的组合向量。即是对于某个sub或obj把多向量加权合并成一个向量
Relation Knowledge Injection
![]()
e表示预训练所给的向量嵌入。 _r表示在候选词C_r上的分布(关系的词是打散的),即是C_r是关系打散的词。带帽的e表示词v_`的加权求和的向量。
未太明白??
![[论文阅读笔记62]KnowPrompt - Knowledge-aware Prompt-tuning with Synergistic Optimization for RE_第4张图片](http://img.e-com-net.com/image/info8/772f4649311947a896d5efbc35e3f422.jpg)
基于知识约束的协同优化—两个损失函数
Context-aware Prompt Calibration
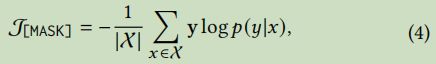
Implicit Structured Constraints
![[论文阅读笔记62]KnowPrompt - Knowledge-aware Prompt-tuning with Synergistic Optimization for RE_第5张图片](http://img.e-com-net.com/image/info8/a62e09d0f46c4cefabac3519618ed785.jpg)
$(_^′,, _^′) $表示负样本。
两阶段优化:
step1:使用比较大的学习率1:
![]()
step2:使用小的学习率lr1去学习[MAsk]:
![]()
3. 实验
3.1 数据集
![[论文阅读笔记62]KnowPrompt - Knowledge-aware Prompt-tuning with Synergistic Optimization for RE_第6张图片](http://img.e-com-net.com/image/info8/4f4501ca2c40490abf9459552f99febd.jpg)
3.2 实验设置
预测训练模型:RoBERT_large(除了DialogRE采用RoBERTa_base)
测试指标: micro 1 scores
Standard Setting:
采用合部样本数据进行fine-tune.
Baseline – SpanBERT [30], KnowBERT [38], LUKE [52], and MTB [3]
Low-Resource Setting:
主要参考:LM-BFF [15, 22]
3.3 标准结果
![[论文阅读笔记62]KnowPrompt - Knowledge-aware Prompt-tuning with Synergistic Optimization for RE_第7张图片](http://img.e-com-net.com/image/info8/4a211411efa840d7a76b29fe013d69ae.jpg)
3.4 低资源结果
![[论文阅读笔记62]KnowPrompt - Knowledge-aware Prompt-tuning with Synergistic Optimization for RE_第8张图片](http://img.e-com-net.com/image/info8/5698c273ebc14ceeaba309180056055c.jpg)
3.5 消融研究
![[论文阅读笔记62]KnowPrompt - Knowledge-aware Prompt-tuning with Synergistic Optimization for RE_第9张图片](http://img.e-com-net.com/image/info8/78de71b848d14ade9f6668e00772292d.jpg)
4. 代码研究
代码采用pyTorch Lightning来实现的, 另外还有可视化日志用到了wandb[https://wandb.ai/],这个需要注册一个账号. 跑了Re-Tacred数据,因为基于RoBERT_large显存不够用。只用了RoBERTa_base,每批size只设置为5条,如果如下:
![[论文阅读笔记62]KnowPrompt - Knowledge-aware Prompt-tuning with Synergistic Optimization for RE_第10张图片](http://img.e-com-net.com/image/info8/ea52f3cfb8634b97b1472e83bee7bec4.jpg)
5. 相关技术
5.1 RE
5.2 Prompt-tuning
Prompt-tuning开始于GPT-3;
Hu et al. [28]:建议把外部知识加入了;
Ding et al. [12] :通过构建面向实体的表达器和模板,将快速学习应用于实体类型;
自动建建模板:
Gao et al. [15], Schick et al. [42]:首先提出自动生成回答与模板;
Shin et al. [46]:进一步提出梯度引导搜索自动生成词标注;
提出continuous prompts:[21, 25, 34, 36]:利用可学习的连续嵌入作为prompt templates而不是标注词,可是这些方法不适应RE。????
对于RE,Han et al. [22] 提出PTR,使用逻辑规则使用子prompt去构建prompts.
5.3 相关定义
RE
Fine-tuning PLMs for RE
Prompt-Tuning of PLMs.
6. 参考
【1】论文: https://arxiv.org/pdf/2104.07650.pdf
【2】github: https://github.com/zjunlp/KnowPrompt
cumbersome adj. 笨重的;累赘的,难以携带的;缓慢复杂的,冗长的;麻烦的
fuse 英[fjuːz] 美[fjuːz]
vi. 熔化;融合
vt. 使融合;使融化;给…装信管
n. 保险丝;导火线;雷管;引信
[verbalizer](javascript: 在言语