论文地址:基于生成对抗网络的语音增强
博客地址(转载请指明出处):https://www.cnblogs.com/LXP-Never/p/9986744.html
SEGAN的例子
摘要
当前的语音增强技术是在频谱域或利用一些高级特征的基础上进行的。他们中的大多数人处理的噪音条件有限,并依赖于一阶统计特性。为了规避这些问题,深层网络正被越来越多地使用,因为它们能够从大量的训练数据集中学习到复杂的关系。在本文中,我们提出了生成对抗性网络在语音增强中的应用。与现有技术相比,我们在波形级上操作,对模型进行端到端的训练,并将28个说话人和40个不同的噪声条件合并到同一个模型中,以便在它们之间共享模型参数。我们使用一个独立的、看不见的测试集来评估所提出的模型,该测试集有两个说话人和20种不同的噪声条件。改进后的语音证实了该模型的可行性,客观评价和主观评价都证实了模型的有效性。在此基础上,我们对语音增强的生成体系结构进行了探索,这将逐步纳入更多以语音为中心的设计选择,以提高它们的性能。
关键字:语音增强、深度学习、生成对抗网络、卷积神经网络
一、引言
语音增强技术试图改善受加性噪声污染的语音的可懂度和质量[1]。它的主要应用是提高噪声环境下的移动通信质量。然而,我们也发现了与助听器和人工耳蜗有关的重要应用,其中放大前增强信号可以显著减少不适,增加可懂度[2]。在语音识别和说话人识别系统[3,4,5]中,语音增强也被成功地应用于预处理阶段。
经典的语音增强方法有谱减法(spectral subtraction)[6]、维纳滤波(Wiener filtering)[7]、基于统计模型的方法(statistical model-based methods)[8]和子空间算法(subspace algorithms)[9,10]。自80年代以来,神经网络也被应用于语音增强[11,12]。近年来,去噪自动编码器结构[13]已被广泛采用。然而,递归神经网络(Rnns)同样也被使用起来。例如,递归去噪自动编码器在利用嵌入式信号中的时间上下文信息方面表现出了显著的性能。大多数最新的方法都将长-短期记忆RNNs应用于去噪任务[4,14]。在[15]和[16]中,噪声特征被估计并包含在深度神经网络的输入特征中。使用dropout, post-filtering和感知激励的度量被证明是有效的。
目前的大多数系统都是基于短时傅立叶分析/综合框架[1]。它们只会改变频谱的大小,因为人们经常声称短时间相位对语音增强不重要[17]。然而,进一步的研究[18]表明,语音质量的显著改善是可能的,特别是当一个干净的相位谱是已知的时候。1988年,Tamura等人。[11]提出了一个直接工作于原始音频波形的深层网络,但他们使用的是逐帧(60个样本)在依赖于说话者和孤立的单词数据库上工作的前馈层。
最近在深度学习生成建模领域的一个突破是生成对抗性网络(GANS)[19],它在计算机视觉领域取得了很好的成功,能够生成真实的图像,并能很好地推广到像素级的复杂(高维)分布[20,21,22]。对于我们来说,GANS还没有应用于任何语音生成或增强任务,因此这是第一种使用对抗性框架来生成语音信号的方法。
论文结合GAN网络提出了SEGAN,并通过实验发现,SEGAN主要优势有以下三点:
- 1、提供一个快速语音增强过程,没有因果关系是必要的,因此没有像RNN那样的递归操作。
- 2、它基于原始音频做处理,没有提取特征,因此没有对原始数据做出明确的假设。
- 3、从不同的说话人和噪声类型中学习,并将他们合并到相同的共享参数中,这使得系统在这些维度上变得简单和一般化。
在下面,我们在(第二节)概述GANS,接下来我们(第三节)描述了所提出的模型及其实验装置(第四节),(第五节)我们最后报告了结果,(第六节)讨论一些结论。
二、Generative Adversarial Networks
GAN[19]是学习将样本z从一些先验分布$Z$映射到样本x的另一分布$X$的生成模型,该分布X是训练示例之一(例如,图像、音频等)。在GAN结构中执行映射的组件称为生成器(G),其主要任务是学习能够模拟真实数据分布的有效映射,以生成与训练集相关的新样本。重要的是,G不是通过记忆输入输出对,而是通过将数据分布特性映射到我们先前z中定义的流形上。
G学习映射的方式是通过对抗性训练,其中我们有另一个组件,称为判别器(D)。D通常是二进制分类器,它的输入要么是来自G正在模仿的数据集的真实样本,要么是由G组成的假样本。对抗性特征来源于D必须将来自x的样本分类为真实样本,而来自G,$\tilde{x}$的样本必须被归类为假样本。这导致G试图愚弄D,而这样做的方法是G调整其参数,以便D将G的输出分类为真。在反向传播期间,D更善于在其输入中找到现实的特征,并且反过来,G校正其参数以向由训练数据描述的真实数据流形移动(图1)。这种对抗性学习过程被描述为G和D之间的极大极小博弈,其目标函数是

我们还可以使用条件GANs,在G和D中有一些额外的信息来执行映射和分类(参见[20]及其中的引用)。在这种情况下,我们可以添加一些额外的输入$x_c$,因此我们将目标函数更改为
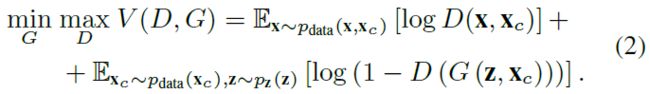
我们对GAN方法进行了改进,以稳定训练并提高G中生成的样本的质量,因为经典的方法由于计算成本所使用的Sigmoid交叉熵损失函数而受到渐变的影响。为了解决这一问题,我们采用了[21]的最小二乘GAN(LSGAN)方法,用二进制编码(1为实,0为假)代替代价函数。有了这个,方程中的公式第二2项改动

论文的第二部分,是介绍GAN的,如果有GAN的基础可以跳过这一节。GAN网络是一种对抗模型,可以将样本服从Z分布的样本映射到服从X分布的x。
关于GAN的更多解释:
有人说GAN强大之处在于可以自动的学习原始真实样本集的数据分布。为什么大家会这么说。
对于传统的机器学习方法,我们一般会先定义一个模型让数据去学习。(比如:假设我们知道原始数据是高斯分布的,只是不知道高斯分布的参数,这个时候我们定义一个高斯分布,然后利用数据去学习高斯分布的参数,最终得到我们的模型),但是大家有没有觉得奇怪,感觉你好像事先知道数据该怎么映射一样,只是在学习模型的参数罢了。GAN则不同,生成模型最后通过噪声生成一个完整的真实数据(比如人脸),说明生成模型已经掌握了从随机噪声到人脸数据的分布规律。有了这个规律,想生成人脸还不容易,然而这个规律我们事先是不知道的,我们也不知道,如果让你说从随机噪声到人脸应该服从什么分布,你不可能知道。这是一层层映射之后组合起来的非常复杂的分布映射规律。然而GAN的机制可以学习到,也就是说GAN学习到了真实样本集的数据分布。
三、Speech Enhancement GAN
我们有一个噪声的输入语音信$\tilde{x}$,我们想要去除噪声获得增强的语音信号$\hat{x}$,我们打算用SEGAN(语音增强生成对抗网络)来实现目的。G网络来执行增强操作,G网络的输入是噪声语音信号$\tilde{x}$和潜在表示z,其输出是增强的语音信号$x=G(\tilde{x})$,G网络被设计成完全卷积的,以至于根本没有全连接的网络层,这迫使网络在输入信号中和整个分层过程中关注时间上紧密的相关性,此外卷积网络还减少了训练的参数和训练时间。
G网络的结构类似于自动编码器(auto-encoder)。在编码阶段,输入信号被投影,通过被多个strided卷积层压缩,其次是PReLUs(参数整流线性单元),从滤波器的每个步骤获得卷积结果。我们选择strided卷积,因为对于GAN训练它相对于其他的池化方法更稳定。抽取直到我们得到一个被称作思维向量c的压缩表示,它与前夫向量z相连接。在解码阶段,编码过程通过分数步长转置卷积(有时称为反卷积),进行反转,之后就是PReLUs。
G网络还具有跳过连接的特性,将每个编码层连接到其相应的解码层,并绕过在模型中间执行的压缩(图2)

图二:生成器,encoder-decoder
这是因为模型的输入和输出共享相同的底层结构,即自然语音的结构。如果我们强制所有的信息都流过压缩瓶颈,那么为了正确地重构语音波形,可能会丢失许多低级一点的细节。跳过连接直接将波形的细粒度信息传递给解码阶段(例如:相位、对准)。此外,他们提供了更好的训练行为,因为梯度可以在整个结构中流动得更深,而不会遭受太多的损失[24]。
G网络的一个重要特征就是它的端到端的结构,因此它处理16kHz采样的原始语音,去掉所有的中间变换来提取声学特征(与许多常见的管道形成对比),在这类模型中,我们必须要小心处理典型的回归损失,如平均绝对误差或均方误差,如原始语音生成模型WaveNET中所提到的[25]。这些损失在我们强假设产生的分布如何形成和强加一些重要的模型限制时起作用,例如不允许多模态分布和将预测偏向所有可能预测的平均值。我们克服这些限制的解决方案是使用生成对抗设置。通过这种方式,D负责将信息传递给G哪个是真的,哪个是假的,这样G就可以朝向真实稍微修正它的输出波形,去除被D判别是假的噪声信号。D可以理解为学习一些损失,使得G的输出看起来真实。
在初步实验中,我们发现在G的损失上增加一个次要成分是很方便的,这样可以使G的世代与干净的例子之间的距离最小化。为了测量这样的距离,我们选择L1范数,因为它已经被证明在图像处理领域是有效的[20,26]。通过这种方式,我们让对抗性组件添加了更多的细粒度和现实的结果。L1范数的大小由一个新的超参数控制。从而使得的LSGAN (Eq. 4)中的G损失变成
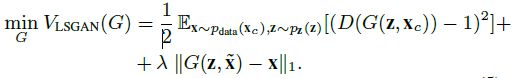
四、实验步骤
4.1 数据集
为了评估SEGAN的有效性,我们使用Valentini等人的数据集[27]。我们之所以选择它,是因为它是开放的、可用的,而且数据的数量和类型符合我们这项工作的目的:概括了不同说话人的多种噪音。数据集是从语音语音库[28]中选择的30个说话人:28个包含在训练集中,2个包含在测试集合中。
为了建立噪声训练集,总共有40种不同的条件被考虑为[27],10种类型的噪声(2种人为噪声,8种来自于需求数据库[29]),每种信噪有4个信噪比(SNR)(15dB、10dB、5dB和0dB)。每个说话人在每个条件下都有大约10个不同的句子。为了建立测试集,总共考虑20个不同的条件[27],5种类型的噪声(全部来自需求数据库),每个噪声有4种信噪比(17.5dB、12.5dB、7.5dB和2.5 dB)。每个测试说话人在每个条件下大约有20个不同的句子。重要的是:使用不同的说话人和条件,测试集是完全看不见的(和训练集不同)。
4.2 SEGAN步骤
模型使用RMSprop[30]对86个epoch进行训练,学习率为0.0002,有效batch size为400,我们将训练示例分成两组(图3)。

真实的一对(噪声信号和纯净的信号$(\tilde{x},x)$)和伪造的一对(噪声信号和增强的信号$(\tilde{x},\hat{x})$)。为了使数据集文件符合我们的波形生成目的,我们对原始语音进行下采样从48 kHz到16 kHz。在训练期间,我们通过每隔的500毫秒(50%的重叠)滑动窗口提取大约1秒钟的波形(16384个样本)。在测试期间,我们基本上在整个测试过程中滑动窗口,没有重叠,并在流的末尾连接结果。在训练和测试中,我们对所有输入样本都使用了系数为0.95的高频预强调滤波器(在测试过程中,输出相应地去加重)。
关于L1正则化的$\lambda $权,经过实验,我们将其设置为100,用于整个训练。我们最初将其设为1,但我们观察到,在对抗性的情况下,G损失是两个数量级,所以L1对学习没有实际影响。一旦我们把它设为100,我们就会看到L1中的最小化行为和对抗性的平衡行为。我们假设随着L1值的降低,输出样本的质量增加,有助于G在现实生成方面更有效。
在结构上,G由22个滤波器宽度31且阶梯N=2的一维阶梯卷积层组成。每层的滤波器数量增加,也就是随着宽度(信号在时间上的持续时间)变窄,深度变大。每一层是样本X特征的映射,每一层的维度是16384*1、8192*16、4096*32、2048*32、1024*64、512*64、256*128、128*128、64*256、32*256、16*512和8*1024。在这里,我们从先前的8*1024维正态分布N (0, I)中采样噪声样本z。如上所述,G的解码器阶段是具有相同滤波器宽度和每层相同滤波器数量的编码器的镜像。然而,忽略连接和添加潜在向量使得每一层的特征映射的数量加倍。
判别网络D的编码器采用和生成网络G相同的一维卷积结构。它适用于卷积分类网络和传统拓扑结构。不同之处在于
1)、得到了16384个双输入通道的样本
2)、在$\alpha=0.3$的LeakyReLU非线性之前,它使用了virtual batch-norm[31]
3)、在最后一层激励层中,有一个一维卷积层(1*1卷积),其中有一个宽度为1的滤波器,他不会对隐藏层的激励信号进行下采样
后来(3)减少了分类神经元和隐藏激励线性全连接所需的参数数量。
后来(3)减少了最终分类神经元所需参数的数量,该神经元完全连接到所有具有线性行为的隐藏激励。这意味着我们将全连接的组件中所需的参数量从8*1024=8192减少到8。并且1024个信道的合并方式可以通过卷积的参数来学习
所有的项目都是用Tensorflow开发的,代码可以在https://github.com/santi-pdp/segan找到。我们参考此资源以进一步实现我们的详细信息。在http://veu.talp.cat/segan/中提供了增强的语音样本。
五、结果
4.1 客观评价
为了评估增强语音的质量,我们计算以下客观度量(越高越好)。所有度量将增强后的语音信号与824个未处理的语音进行比较,它们是使用了包含在[1]中的实现来计算的,并可在出版商网站2获取。
PESQ:语音质量感知评价,使用ITU-T P.862.2[33]中建议的宽带版本(0.5 - 4.5)。
CSIG:仅关注语音信号[34](从1到5)的信号失真的平均意见评分(MOS)预测。
CBAK:背景噪声侵入性的MOS预测[34](从1到5)。
COVL:总体效应的MOS预测[34](从1到5)。
SSNR:分段SNR[35,P 41](从0到1)。

表一:目的比较噪声信号与维纳增强信号和分段增强信号的优劣。
表一显示了这些度量的结果,为了具有比较参考,如[1]中所提供的,他还显示了当但直接应用有噪声信和基于先验SNR估计[36]使用wiener滤波的信号时,这些度量的结果。可以观察到SEGAN如何使PESQ稍微变差。然而在所有其他与语音/噪声失真相关的度量中,SEGAN优于Wiener方法。它产生较少的语音失真(CSIG)和更有效地去除噪声(CBAK和SSNR)。因此,它在两个因素(COVL)之间取得了更好的平衡。
4.2 主观评价
为了比较SEGAN增强的噪声信号和维纳基线,还进行了感知测试。为此从测试集中选择了20个句子,由于数据库没有说明每个文件的噪声的数量和类型,所以通过侦听提供的一些噪声文件来进行选择,试图平衡不同的噪声类型,大多数文件具有低信噪比,但也有少数具有高信噪比的文件。
总共有16名听众随机抽取20个句子,对于每个句子,都按随机顺序给出了以下三种形式:噪声信号、维纳增强信号和SEGAN增强信号。对于每个信号,听众使用从1到5的刻度对总体质量进行评级。在描述这5个类别时,指示它们注意信号失真和噪声侵入性(例如,5=优秀:非常自然的语音,没有退化和不明显的噪声)。听众可以听任意次数的每个信号,并被要求注意三个信号的比较率。
在表2中,可以观察到SEGAN如何优于噪声信号和维纳基线。然而,由于噪声信号的信噪比有较大的变化,MOS范围很大,Wiener和SEGAN之间的差异不明显。然而,当侦听者同时比较所有系统时,可以通过减去所比较的两个系统的MOS来计算比较MOS(CMOS)。图4描绘了这种相对比较。我们可以看到SEGAN产生的信号是如何优选的。更具体地,在67%的情况中,SEGAN优于原始(有噪声)信号,而在8%的情况中,有噪声信号是优选的(25%的情况中没有优选)。就Wiener系统而言,53%的案例优选SEGAN,23%的案例优选Wiener(24%的案例不优选)。

表二:主观评价结果比较噪声信号和维纳增强信号和SEGAN增强信号。

图4:CMOS盒图(Seang-Wiener比较中线位于1)。正值意味着SEGAN是首选。
六、总结
本工作在生成对抗框架下实现了一种端到端的语音增强方法。该模型采用编码器-解码器的全卷积结构,能够快速地进行波形块的去噪处理。结果表明,该方法不仅可行,而且可以代表现有方法的有效替代方案。未来可能的工作包括探索更好的卷积结构并在对抗训练中加入感知权重,以便减少当前模型可能引入的高频伪影。需要做进一步的实验来比较SEGAN与其他竞争方式。
七、致谢
这项工作是由项目TEC2015-69266 P(MiNeCo/FEDER,UE)支持的。
八、参考文献
[1] P. C. Loizou, Speech Enhancement: Theory and Practice, 2nd ed.Boca Raton, FL, USA: CRC Press, Inc., 2013.
[2] L.-P. Yang and Q.-J. Fu, “Spectral subtraction-based speech enhancement for cochlear implant patients in background noise,” The Journal of the Acoustical Society of America, vol. 117, no. 3, pp. 1001–1004, 2005.
[3] D. Yu, L. Deng, J. Droppo, J. Wu, Y. Gong, and A. Acero, “A minimum-mean-square-error noise reduction algorithm on melfrequency cepstra for robust speech recognition,” in Proc. of the IEEE Int. Conf. on Acoustics, Speech and Signal Processing ICASSP). IEEE, 2008, pp. 4041–4044.
[4] A. L. Maas, Q. V. Le, T. M. O’Neil, O. Vinyals, P. Nguyen, and A. Y. Ng, “Recurrent neural networks for noise reduction in robust asr.” in Proc. of INTERSPEECH, 2012, pp. 22–25.
[5] J. Ortega-Garcia and J. Gonzalez-Rodriguez, “Overview of speech enhancement techniques for automatic speaker recognition,” in Spoken Language, 1996. ICSLP 96. Proceedings., Fourth International Conference on, vol. 2, Oct 1996, pp. 929–932 vol.2.
[6] M. Berouti, R. Schwartz, and J. Makhoul, “Enhancement of speech corrupted by acoustic noise,” in Proc. of the Int. Conf. on Acoustics, Speech, and Signal Processing (ICASS), vol. 4, Apr 1979, pp. 208–211.
[7] J. Lim and A. Oppenheim, “All-pole modeling of degraded speech,” IEEE Trans. on Acoustics, Speech, and Signal Processing, vol. 26, no. 3, pp. 197–210, Jun 1978.
[8] Y. Ephraim, “Statistical-model-based speech enhancement systems,” Proceedings of the IEEE, vol. 80, no. 10, pp. 1526–1555, Oct 1992.
[9] M. Dendrinos, S. Bakamidis, and G. Carayannis, “Speech enhancement from noise: A regenerative approach,” Speech Communication, vol. 10, no. 1, pp. 45–57, 1991.
[10] Y. Ephraim and H. L. Van Trees, “A signal subspace approach for speech enhancement,” IEEE Trans. on speech and audio processing, vol. 3, no. 4, pp. 251–266, 1995.
[11] S. Tamura and A. Waibel, “Noise reduction using connectionist models,” in Proc. of the IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP), 1988, pp. 553–556.
[12] S. Parveen and P. Green, “Speech enhancement with missing data techniques using recurrent neural networks,” in Proc. of the IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP), 2004, pp. 733–736.
[13] X. Lu, Y. Tsao, S. Matsuda, and C. Hori, “Speech enhancement based on deep denoising autoencoder.” in Proc. of INTERSPEECH, 2013, pp. 436–440.
[14] F. Weninger, H. Erdogan, S. Watanabe, E. Vincent, J. Le Roux, J. R. Hershey, and B. Schuller, “Speech enhancement with LSTM recurrent neural networks and its application to noise-robust ASR,” in Proc. of the Int. Conf. on Latent Variable Analysis and Signal Separation, 2015, pp. 91–99.
[15] Y. Xu, J. Du, L.-R. Dai, and C.-H. Lee, “A regression approach to speech enhancement based on deep neural networks,” IEEE/ACM Trans. on Audio, Speech and Language Processing, vol. 23, no. 1, pp. 7–19, 2015.
[16] A. Kumar and D. Florencio, “Speech enhancement in multiplenoise conditions using deep neural networks,” in Proc. of the Int. Speech Communication Association Conf. (INTERSPEECH), 2016, pp. 3738–3742.
[17] D. Wang and J. Lim, “The unimportance of phase in speech enhancement,” IEEE Trans. on Acoustics, Speech, and Signal Processing, vol. 30, no. 4, pp. 679–681, Aug 1982.
[18] K. Paliwal, K. W´ojcicki, and B. Shannon, “The importance of phase in speech enhancement,” Speech Communication, vol. 53, no. 4, pp. 465 – 494, 2011. [Online]. Available: http://www.sciencedirect.com/science/article/pii/S0167639310002086
[19] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,” in Advances in Neural Information Processing Systems (NIPS), 2014, pp. 2672–2680.
[20] P. Isola, J.-Y. Zhu, T. Zhou, and A. A. Efros, “Image-toimage translation with conditional adversarial networks,” ArXiv: 1611.07004, 2016.
[21] X. Mao, Q. Li, H. Xie, R. Y. K. Lau, and Z. Wang, “Least squares generative adversarial networks,” ArXiv: 1611.04076, 2016.
[22] A. Radford, L. Metz, and S. Chintala, “Unsupervised representation learning with deep convolutional generative adversarial networks,” arXiv preprint arXiv:1511.06434, 2015.
[23] K. He, X. Zhang, S. Ren, and J. Sun, “Delving deep into rectifiers: Surpassing human-level performance on imagenet classification,” in Proc. of the IEEE Int. Conf. on Computer Vision (ICCV), 2015, pp. 1026–1034.
[24] ——, “Deep residual learning for image recognition,” in Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 770–778.
[25] A. van den Oord, S. Dieleman, H. Zen, K. Simonyan, O. Vinyals, A. Graves, N. Kalchbrenner, A. Senior, and K. Kavukcuoglu, “Wavenet: A generative model for raw audio,” CoRR abs/1609.03499, 2016.
[26] D. Pathak, P. Krahenbuhl, J. Donahue, T. Darrell, and A. A. Efros, “Context encoders: Feature learning by inpainting,” in Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 2536–2544.
[27] C. Valentini-Botinhao, X. Wang, S. Takaki, and J. Yamagishi, “Investigating rnn-based speech enhancement methods for noiserobust text-to-speech,” in 9th ISCA Speech Synthesis Workshop, pp. 146–152.
[28] C. Veaux, J. Yamagishi, and S. King, “The voice bank corpus: Design, collection and data analysis of a large regional accent speech database,” in Int. Conf. Oriental COCOSDA, held jointly with 2013 Conference on Asian Spoken Language Research and Evaluation (O-COCOSDA/CASLRE). IEEE, 2013, pp. 1–4.
[29] J. Thiemann, N. Ito, and E. Vincent, “The diverse environments multi-channel acoustic noise database: A database of multichannel environmental noise recordings,” The Journal of the Acoustical Society of America, vol. 133, no. 5, pp. 3591–3591, 2013.
[30] T. Tieleman and G. Hinton, “Lecture 6.5-RMSprop: divide the gradient by a running average of its recent magnitude,” COURSERA: Neural Networks for Machine Learning 4, 2, 2012.
[31] T. Salimans, I. Goodfellow, W. Zaremba, V. Cheung, A. Radford, and X. Chen, “Improved techniques for training gans,” in Advances in Neural Information Processing Systems (NIPS), 2016, pp. 2226–2234.
[32] M. Abadi, A. Agarwal, P. Barham, E. Brevdo, Z. Chen, C. Citro, G. S. Corrado, A. Davis, J. Dean, M. Devin et al., “Tensorflow: Large-scale machine learning on heterogeneous distributed systems,” arXiv preprint arXiv:1603.04467, 2016.
[33] P.862.2: Wideband extension to Recommendation P.862 for the assessment of wideband telephone networks and speech codecs, ITU-T Std. P.862.2, 2007.
[34] Y. Hu and P. C. Loizou, “Evaluation of objective quality measures for speech enhancement,” IEEE Trans. on Audio, Speech, and Language Processing, vol. 16, no. 1, pp. 229–238, Jan 2008.
[35] S. R. Quackenbush, T. P. Barnwell, and M. A. Clements, Objective Measures of Speech Quality. Englewood Cliffs, NJ: Prentice-Hall, 1988.
[36] P. Scalart and J. V. Filho, “Speech enhancement based on a priori signal to noise estimation,” in Proc. of the IEEE Int. Conf. on Acoustics, Speech, and Signal Processing (ICASSP), vol. 2, May 1996, pp. 629–632 vol. 2.