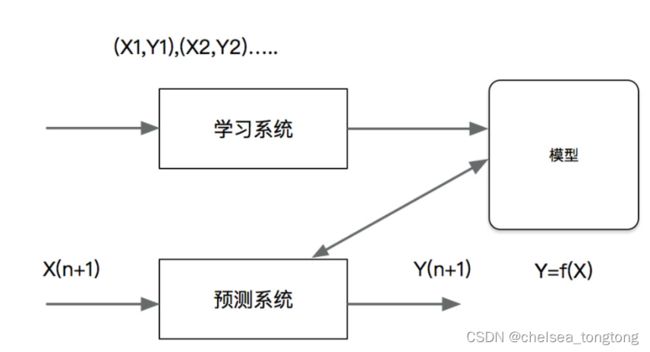
机器学习基础——线性回归、过拟合和欠拟合、岭回归和Lasso回归
目录
1 回归算法
1.1 线性回归
1.2 线性关系
1.3 线性关系模型
1.4 损失函数
2 优化算法
2.1 正规方程
2.2 梯度下降法(迭代)
3 sklearn线性回归正规方程、梯度下降API
4、scikit-learn和tensorflow比较
5、线性回归实例
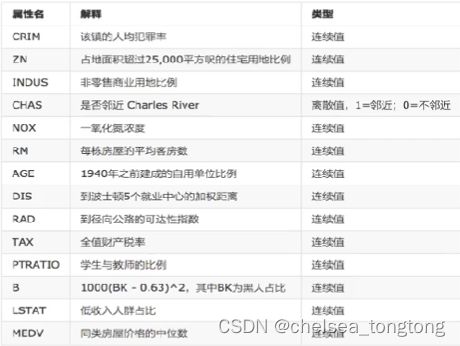
5.1 波士顿房价数据解释
5.2 数据案例分析流程
5.3 代码实现
5.3.1 调入包
5.3.2 处理数据集
5.3.3 估计器
5.3.4 自我检验
5.3.4 均方误差检验
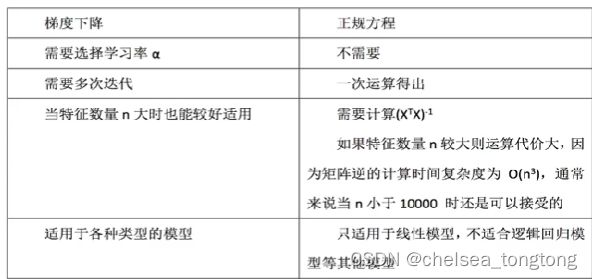
5.4 线性回归两种模型对比
6 过拟合和欠拟合
6.1 定义
6.2 原因及解决办法
6.2.1 欠拟合原因及解决办法
6.2.2 过拟合原因及解决办法
7、岭回归与Lasso回归
1 回归算法
1.1 线性回归
定义:线性回归通过一个或者多个自变量和因变量之间进行建模的回归分析。其中可以为一个或多个自变量之间的线性组合(线性回归的一种)
一元线性回归:涉及到的变量只有一个...
多元线性回归:涉及到的变量两个或两个以上...

矩阵:大多数算法计算基础
目的:寻找一种能预测的趋势,预测的时候真实值和预测值有差距
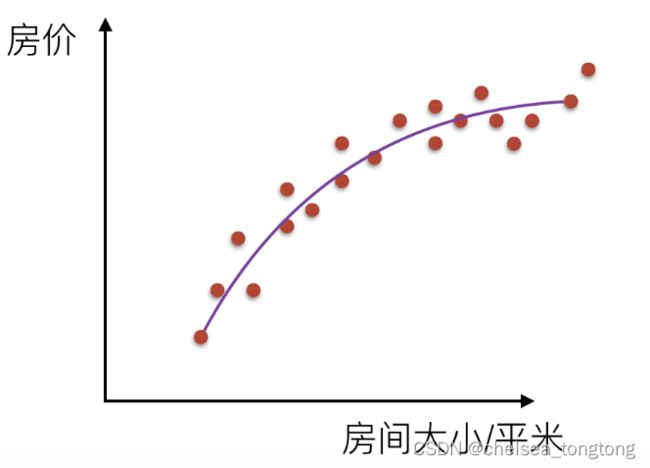
1.2 线性关系
二维:直线关系、三维:特征,目标值,平面当中
线性关系定义:y=wx+b
- b :偏置
- 加b:为了是对于单个特征的情况更加通用
1.3 线性关系模型
一个通过属性的线性组合来进行预测的函数:

w为权重,b称为偏置项,可以理解为:Wo
1.4 损失函数
- 寻找最优化的w值
- 策略(使得损失函数最小):最小二乘法算误差平方和

2 优化算法
2.1 正规方程
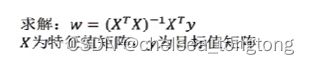
正规方程计算w:特征值数量过多时,计算速度过慢。
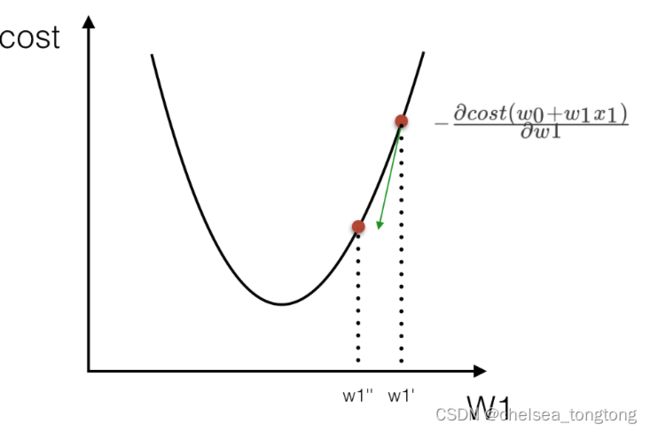
2.2 梯度下降法(迭代)

- 只需要理解过程,它不是一次完成的,需要不断地迭代,朝着损失减少的方向
- 从下图看,沿着山谷下降,最后找到山谷的最低点
- 算法的自我学习过程
- 一般都用梯度下降法进行优化
3 sklearn线性回归正规方程、梯度下降API
- sklearn.linear_model.LinearRegression
- 正规方程 普通最小二乘线性回归
- sklearn.linear_model.SGDRegressor
- 梯度下降 通过使用SGD最小化线性模型
- coef_: 回归系数
4、scikit-learn和tensorflow比较
scikit-learn优点:封装好,建立模型简单,预测简单
缺点:算法的过程,有些参数都在API内部优化
tensorflow优点:可以自己实现线性回归、学习率
5、线性回归实例
5.1 波士顿房价数据解释
5.2 数据案例分析流程
- 波士顿房价数据获取
- 波士顿房价数据分割
- 训练与测试数据标准化处理
- 使用最简单的线性回归模型LinearRegression和梯度下降估计SGDRegressor对房价进行预测
5.3 代码实现
5.3.1 调入包
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression,SGDRegressor
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np5.3.2 处理数据集
- 转化器:0.18和0.19版本的转化器里面数据维数要求不一样,我这个是0.19版本的,只能输入二维数组,但是0.18版本的输入一维和二维的都行
- y_test和y_train都是一维数组。关于它是否是一维还是二维数组,不是看行数和列数,得自己打印看,几层[]就是几维数组
#获取数据
lb=load_boston()
print(lb)
#分割数据集到训练集和测试集
x_train,x_test,y_train,y_test=train_test_split(lb.data,lb.target,test_size=0.25)
print(y_train,y_test)##发现是一维的数组
#进行标准化处理
#特征值和目标值都需要标准化,实例化两个标准化API
std_x=StandardScaler()
x_train=std_x.fit_transform(x_train)
x_test=std_x.transform(x_test)
#目标值
std_y=StandardScaler()
y_train=std_y.fit_transform(y_train.reshape(-1,1))
y_test=std_y.transform(y_test.reshape(-1,1))#把一维数组变成任意行,1列数组5.3.3 估计器
方法一:正规方程法
#正规方程求解方程式预测结果
lr=LinearRegression()
lr.fit(x_train,y_train)
print("这里是回归系数:",lr.coef_)
#预测测试集房子价格
y_predict=lr.predict(x_test)
print("预测每个房子的预测价格:",y_predict)
这里是回归系数: [[-0.12937742 0.12473739 0.03670592 0.07093524 -0.24900562 0.2621683
0.02365185 -0.36029046 0.33596857 -0.22118924 -0.23617709 0.09209973
-0.45201366]]
预测每个房子的预测价格: [[ 1.00456267] [ 1.79398169] [ 0.29116299] [-2.35988121]
[-0.50438495] [-1.00876333] [ 1.49039779] [ 0.28936604] [-0.46245197] [-0.94650153] [ 0.72012574] [-3.00684167] [ 0.51132297] [ 1.6257219 ] [-0.87927421] [-0.55729338]
[ 0.16963811] [ 0.52739851] [-1.26938951] [ 0.09202953] [ 0.82401351] [ 2.05005397]
方法二:梯度下降法
#梯度下降进行房价预测
sgd=SGDRegressor()
sgd.fit(x_train, y_train)
print("这里是回归系数:", lr.coef_)
# 预测测试集房子价格
y_predict = lr.predict(x_test)
print("预测每个房子的预测价格:", y_predict) 这里是回归系数: [[-0.0812083 0.1148654 0.03449191 0.05296688 -0.2130283 0.29399682
-0.01604545 -0.30265023 0.2806514 -0.23347402 -0.22783836 0.08908084
-0.40093789]]
预测每个房子的预测价格: [[ 0.22934965] [-0.27897226] [ 1.27281175] [-0.81305208]
[ 1.36460606] [ 0.06994104][-0.99441554] [ 0.23368286] [-0.20515641] [-0.51992321]
[-0.98392547] [ 0.65669976] [ 0.5241549 ] [ 0.31557027] [-0.6027864 ][ 0.31506297]
5.3.4 自我检验
a=lr.coef_
print("这里是x_test的几行几列数:", x_test.shape)
print("这里是x_train的几行几列数:", x_train.shape)
print("这里是y_test的几行几列数:",y_test.shape)
print("这里是y_train的几行几列数:", y_train.shape)
print("回归系数是几行几列:",a.shape) 这里是x_test的几行几列数: (127, 13)
这里是x_train的几行几列数: (379, 13)
这里是y_test的几行几列数: (127, 1)
这里是y_train的几行几列数: (379, 1)
回归系数是几行几列: (1, 13)
总结:回归系数是通过x_train和y_train拟合出来的,所以验算的时候看x_train和y_train是几行几列,而且矩阵相乘的时候乘的是转置,这么看就检验成功啦 !
5.3.4 均方误差检验
from sklearn.metrics import mean_squared_error- mean_squared_error()检验回归效果函数
print("正规方程测试集里面每个房子的预测价格:",y_lr_predict)
print("正规方程的均方误差:",mean_squared_error(std_y.inverse_transform(y_test),y_lr_predict))
print("梯度下降测试集里面每个房子的预测价格:", y_sgd_predict)
print("梯度下降法的均方误差:", mean_squared_error(std_y.inverse_transform(y_test), y_sgd_predict))正规方程的均方误差: 577.5937652713694
梯度下降法的均方误差: 578.0285461690776
5.4 线性回归两种模型对比
6 过拟合和欠拟合
6.1 定义
模型复杂的原因:数据的特征和目标值值的关系不仅仅是线性关系,可能是非线性关系。生活中大部分都是非线性回归。
过拟合:一个假设在训练数据集上能够获得比其他假设更好的拟合,但是在训练数据外的数据集上却不能很好得拟合数据,此时认为这个假设出现了过拟合的现象。(模型过于复杂)
欠拟合:一个假设在训练数据集上不能获得更好的拟合,但是在训练数据集意外的数据集上也不能很好地拟合数据,此时认为这个假设出现了欠拟合的现象。(模型过于简单)

6.2 原因及解决办法
6.2.1 欠拟合原因及解决办法
原因:学习到的数据特征过少
解决办法:增加数据的特征
6.2.2 过拟合原因及解决办法
判断依据:根据交叉验证训练集和测试集的结果
欠拟合表现:训练集和测试集->表现都不行
过拟合表现:训练集准确率结果99,误差平方和2.0;测试集准确率结果89%,10.0
原因:原始特征过多,存在一些嘈杂特征,模型过于复杂是因为模型尝试去兼顾各个测试数据点
解决办法:
- 进行特征选择,消除关联性大的特征(很难做)
- 交叉验证(让所有数据都有过训练)
- 正则化(了解)
7、岭回归与Lasso回归
代码实现看:机器学习总结(一):线性回归、岭回归、Lasso回归_她说巷尾l的樱花开了的博客-CSDN博客_岭回归
岭回归与Lasso回归的出现是为了解决线性回归出现的过拟合以及在通过正规方程方法求解θ的过程中出现的x转置乘以x不可逆这两类问题的,这两种回归均通过在损失函数中引入正则化项来达到目的,具体三者的损失函数对比见下图:
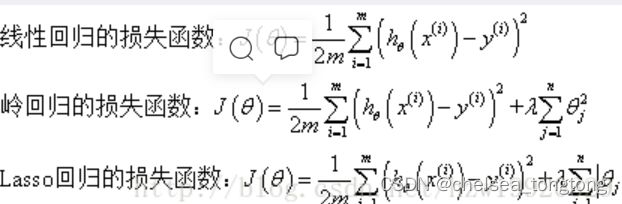
其中λ称为正则化参数,如果λ选取过大,会把所有参数θ均最小化,造成欠拟合,如果λ选取过小,会导致对过拟合问题解决不当,因此λ的选取是一个技术活。
岭回归与Lasso回归最大的区别在于岭回归引入的是L2范数惩罚项,Lasso回归引入的是L1范数惩罚项,Lasso回归能够使得损失函数中的许多θ均变成0,这点要优于岭回归,因为岭回归是要所有的θ均存在的,这样计算量Lasso回归将远远小于岭回归。