【知识图谱】
知识图谱
知识抽取中三元组
三元组数据来源
本次数据来源医学临床检验书籍,同时该类书籍的内容排版具备结构化,或者半结构化,如下图1所示
如下图中红色框起来内容,这就是具备排版结构书籍,因此,可以根据此类数据特点,将该书籍内容转化成三元组形式。

抽取三元组工具
OCR图文转换
推荐使用百度orc在线转换工具
百度ORC在线
https://console.bce.baidu.com/ai-engine/ocr/converter/index?_=1666145936235
生成网页数据
1.下载安装Typora工具,自行百度
2.ORC工具生成得文档数据,直接导入到Typora中,然后导入数据设定不同类型标题,设定标题根据抽取数据结构而定,具体下图2所示

3.将Typora中数据导出html格式,此时数据将是网页数据,便于后续数据利用正则表达式进行处理。
抽取三元组所需要python模块
from bs4 import BeautifulSoup,NavigableString,Tag
import re
import os
from itertools import islice
import pandas as pd
抽取三元组流程
第一步
1.现将html数据转成DataFrame格式。
def get_dic(file):
h1dic = defaultdict(dict)
with open(file,'r',encoding = 'utf8') as f:
block = islice(f,6,1500)
state1,state2,state3 = 0,0,0
h2set,h3set = set(),set()
for line in block:
if '<' not in line:
line = ''
+ line + ''
soup = BeautifulSoup(line,'html.parser')
if soup.h1:
state1 = 1
state2 = 0
state3 = 0
h2dic = defaultdict(dict)
h1key = soup.get_text().replace(' ','').replace('\n','')
h1dic[h1key] = h2dic
continue
if soup.h2:
state1 = 0
state2 = 1
state3 = 0
h3dic = defaultdict(dict)
h2key = soup.get_text().replace(' ','').replace('\n','')
h2set.add(h2key)
h2dic[h2key] = h3dic
continue
if soup.h3:
state1 = 0
state2 = 0
state3 = 1
h3key = soup.get_text().replace(' ','').replace('\n','')
h3set.add(h3key)
h3dic[h3key] = []
continue
if soup.p and state1 == 1:
if 'h1value' not in h1dic.keys():
h1dic['h1value'] = []
h1dic['h1value'].append(soup.get_text().replace(' ','').replace('\n',''))
else:
h1dic['h1value'].append(soup.get_text().replace(' ','').replace('\n',''))
if soup.p and state2 == 1:
if 'h2value' not in h2dic.keys():
h2dic[h2key]['h2value'] = []
h2dic[h2key]['h2value'].append(soup.get_text().replace(' ','').replace('\n',''))
else:
h2dic[h2key]['h2value'].append(soup.get_text().replace(' ','').replace('\n',''))
if state3 == 1:
h3dic[h3key].append(soup.get_text().replace(' ','').replace('\n ',''))
return [h1dic,h2set,h3set]
2.将生成字典转化成DataFrame格式
def get_dataframe(dic,h3set):
df = pd.DataFrame(dic)
df['h1'] = df.columns[0]
df['h2'] = df.index
df.rename(columns = {df.columns[0]:'value'},inplace = True)
df.index = range(df.shape[0])
def get_dic_value(dic,key):
return dic[key] if key in dic.keys() else None
def split_cols(df,h3set):
h3set.add('h2value')
for key in h3set:
df[key] = df['value'].apply(lambda x:get_dict_value(x,key))
return df
return split_cols(df,h3set)
3.生成DataFrame数据如下图3所示

第二步
1.利用正则表达式对DataFrame格式每一列数据进行处理,抽取我们希望抽取的实体
def get_yiyi_rela(strlist,label):
head1 = []
if label == 1:
for i in range(len(strlist)):
if '镰状细胞特征' in strlist[i][:7]:
vallist = re.split('1.|\\(1\\)|(2)|\\(3\\)',strlist[i])
for val in vallist:
if val != '镰状细胞特征' and val != '':
head1.append('镰状细胞特征' + '|' + val)
if '获得性缺陷' in strlist[i][:7]:
h = '获得性缺陷'
for val in strlist[i].split('。'):
if '(1)' in val:
begin = val.find('(1)')
end = val.find(':')
h1 = val[begin:end]
for word in re.split(';',val[end:]):
if word:
head1.append(h + re.sub(u"[(\d+)]","",h1) + '|' + word)
else:
if val != '':
hindex = val.find('见于')
h1 = val[:hindex]
for word in re.split(';',val[val.find('①'):]):
if word:
head1.append(h + re.sub(u"[(\d+)]","",h1) + '|' + word)
elif '(1)' in strlist[i]:
hindex = strlist[i].replace(' ','').find('(1)')
h = strlist[i][:hindex]
vallist = re.split(';|。',strlist[i][hindex:])
for val in vallist:
if val != '' and len(val) > 1:
head1.append(h + '|' + val)
else:
head1.append(strlist[i])
elif label == 2:
strlist = ''.join(strlist)
hindex = strlist.find('1')
h = strlist[:hindex]
vallist = re.split(';|。',strlist[hindex:])
for val in vallist:
if val != '':
head1.append(h + '|' + val)
else:
pass
return head1
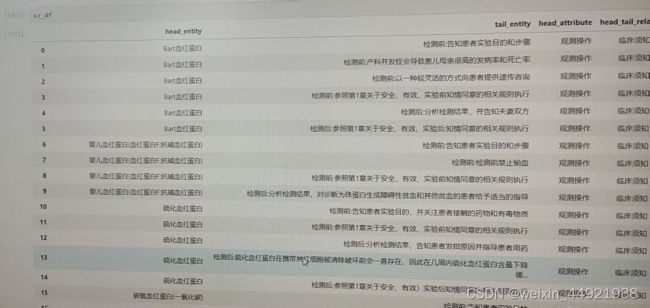
3.经过第二步处理数据如下图4所示
第三步
1.根据正则表达式处理后,可以获得数据格式 “头实体|尾实体”,下面主需要做一下简单拆分,就可以分别获得头尾实体
df_yiyi['head_entity'] = df_yiyi['split_yiyi'].apply(lambda x:x.split('|')[0] if '|' in x else '')
df_yiyi['end_entity'] = df_yiyi['split_yiyi'].apply(lambda x:x.split('|')[1] if '|' in x else '')
2.根据头尾实体添加关系,因为书籍内容存在比较明显关系,主要关系:参考值;临床意义;实验步骤;临床警示;干扰因素等,直接添加头尾实体两者关系。
3.抽取三元组如图5所示