2022秋中国海洋大学《软件工程》第14小组第三次作业
2022秋中国海洋大学《软件工程》第14小组第三次作业
本博客为OUC2022秋季软件工程第三次作业
文章目录
-
-
- 2022秋中国海洋大学《软件工程》第14小组第三次作业
-
- 一、学习心得
-
- 兰宇瑞
- 文顺
- 李昊
- 吴鑫磊
- 陈子琪
- 秦奥翔
- 二、代码练习
-
- 文顺
- 吴鑫磊
- 兰宇瑞
- 秦奥翔
- 陈子琪
- 李昊
- 3.思考问题
-
- 1、dataloader 里面 shuffle 取不同值有什么区别?
- 2、transform 里,取了不同值,这个有什么区别?
- 3、epoch 和 batch 的区别?
- 4、1x1的卷积和 FC 有什么区别?主要起什么作用?
- 5、residual leanring 为什么能够提升准确率?
- 6、代码练习二里,网络和1989年 Lecun 提出的 LeNet 有什么区别?
- 7、代码练习二里,卷积以后feature map 尺寸会变小,如何应用 Residual Learning?
- 8、有什么方法可以进一步提升准确率?
-
一、学习心得
兰宇瑞
卷积神经网络是深度学习的代表算法之一,具有表征学习能力,可以按照其阶层结构对输入信息进行平移不变分类。卷积神经网络在计算机视觉领域发挥了巨大的作用,在自动驾驶、人脸识别方面都有很多的应用。卷积神经网络的结构分为输入层、隐含层、输出层。其中最复杂的为隐含层,包括卷积层、池化层和全连接层3类常见构筑,到目前一些先进的算法中还包括Inception模块、残差块等复杂构筑。
文顺
在《深度学习数学基础》中,我对机器学习三要素(模型、策略、算法)、频率学派&贝叶斯学派、因果推断和群体智能有了初步了解。
机器学习中的主要数学基础有三:线性代数、概率统计和微积分。线性代数在深度学习中作为数据表示和空间变换的有力工具,概率统计是模型假设和策略设计的关键方法,而微积分则是求解目标函数具体算法的数学基础。梯度下降十分重要,是神经网络的共同基础。概率和函数两种形式看似两相对立,实则有机统一,经验风险最小化策略与极大似然策略优化得到的模型参数是一致的。此外,频率学派主要关注可独立重复的随机试验中单个事件发生的概率,其模型参数唯一,需要从有限的观测数据中采用极大似然估计法来估计参数值;而贝叶斯学派则主要关注随机事件的可信程度,其模型参数是随机变量,需要采用最大后验估计法估计参数的整个概率分布。
在《卷积神经网络》中,我对卷积神经网络的应用、其与传统神经网络的差异、以及卷积神经网络的基本组成结构(卷积、池化、全连接)和卷积神经网络的典型结构(AlexNet、ZFnet、VGG、GoogleNet、ResNet)有了初步了解。
卷积神经网络(CNN)在计算机视觉中有重要应用(图像检测、分割、分类、检索、人脸识别、图像生成、风格转化、自动驾驶等)。一个典型的卷积神经网络由卷积层、池化层和全连接层构成。全连接层通常在卷积神经网络的尾部。通过学习五大经典CNN结构,我对卷积神经网络有了一个更为深入的认识。
李昊
在本次视频学习中,主要学习了CNN的基本结构,包括卷积、池化和全连接。以及典型的网络结构如:AlexNet、VGG、GooleNet和ResNet。同时我也基本了解了卷积神经网络的概念,同时通过课后的实验,也对新学习的内容进行了巩固。
吴鑫磊
传统神经网络可以应用到计算机视觉上,但全连接网络处理图像的问题存在参数过多问题从而导致过拟合,而卷积神经网络可以通过局部关联和参数共享来解决。卷积网络的基本组成结构是卷积、池化和全连接传统神经网络:参数太多,会出现过拟合现象,同时它的泛化性能差卷积神经网络:局部关联并且参数共享相同之处:传统神经网络与卷积神经网络都是层级结构一维卷积主要应用于信号处理,计算信号延迟累计。二维卷积主要是数字图像处理,当大小不匹配时,需要零填充操作。
陈子琪
视频的前部分介绍了传统神经网络与卷积神经网络,并进行对比。讲到了深度学习三部曲,即step1:搭建神经网络结构,step2:找到一个合适的损失函数,step3:找到一个合适的优化函数,更新参数。其中损失函数用来衡量吻合度。接下来讲到传统神经网络可以应用到计算机视觉上,但全连接网络处理图像的问题存在参数过多问题从而导致过拟合,而卷积神经网络可以通过局部关联和参数共享来解决。卷积网络的基本组成结构是卷积、池化和全连接。卷积是对两个实变函数的一种数学操作,在图像处理中需要二维卷积,因为图像以二维矩阵的形式输入到神经网络。池化一般处于卷积层与卷积层之间,全连接层与全连接层之间,它保留了主要特征的同时减少参数和计算量,防止过拟合,提高了模型泛化能力。全连接是两层之间所有神经元都有权重链接,且全连接层通常在卷积神经网络尾部,并且参数量很大。之后讲解了一系列卷积神经网络典型结构。这次学习之后感觉有了一个大致的了解,但对具体的内容还不是很清楚,仍需要在后期的学习与实践中深入理解。
秦奥翔
第一部分 卷积神经网络的概念
传统神经网络与卷积神经网络的异同:
传统神经网络:参数太多,会出现过拟合现象,同时它的泛化性能差
卷积神经网络:局部关联并且参数共享
相同之处:传统神经网络与卷积神经网络都是层级结构
卷积神经网络基本组成结构:卷积;池化;全连接
一维卷积主要应用于信号处理,计算信号延迟累计。
二维卷积主要是数字图像处理,当大小不匹配时,需要零填充操作。
输出特征图的大小的计算
行列数=(N+padding*2-F)/stride+1
N为输入大小
F为卷积核大小
Stride为步长
Padding为填充大小
深度为depth/channel=filter个数
输出=特征图大小*深度
参数量=(单个filter大小+1)×filter个数
池化位于卷积层与卷积层间、全连接层与全连接层之间
作用:保留主要特征,减少参数量和计算量,防止出现过拟合现象,提高模型泛化能力
常用方法:最大值池化(分类)、平均值池化
全连接:参数量大,一般放在卷积神经网络的尾部
第二部分:卷积神经网络典型结构
AlexNet:采用大数据训练,具有非线性激活函数ReLU,同时可以防止过拟合现象,用双GPU实现。
优点是在正区间内解决了梯度消失的问题,计算速度快,收敛速度远快于sigmoid
VGG16:增加深度,通过将参数固定来实现训练
GoogleNet:优点是增加了非线性激活函数(裂变),同时降低了参数量。
ResNet:残差的思想,去掉相同的主体部分,从而突出微小的变化,可以被用来训练非常深的网络。
疑问:为什么最大值池化更适用于分类问题?
二、代码练习
文顺



吴鑫磊
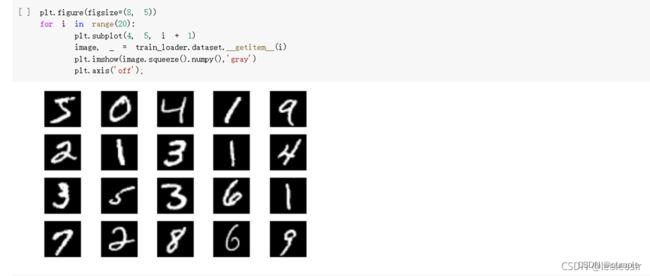

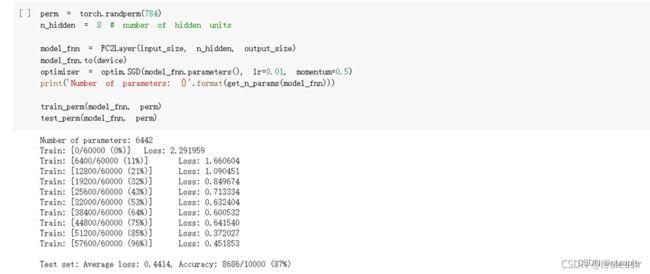
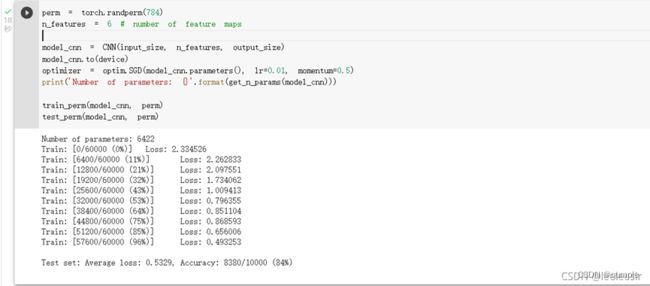

兰宇瑞
卷积神经网络代码练习

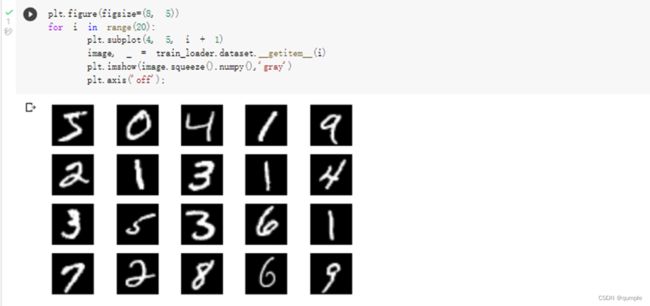
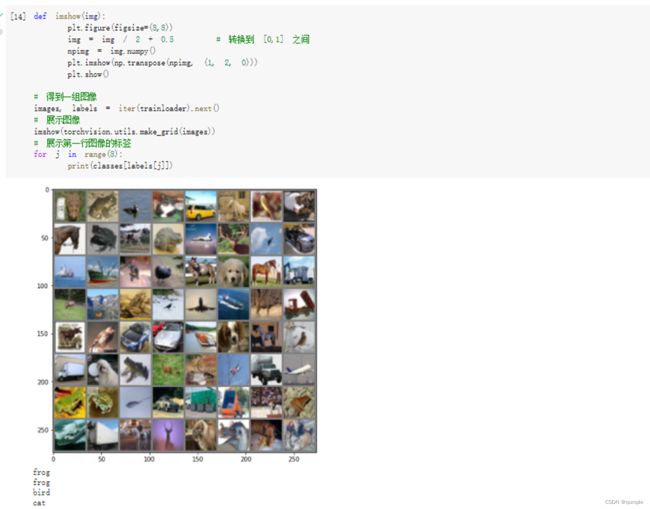
显示数据集中的部分图像
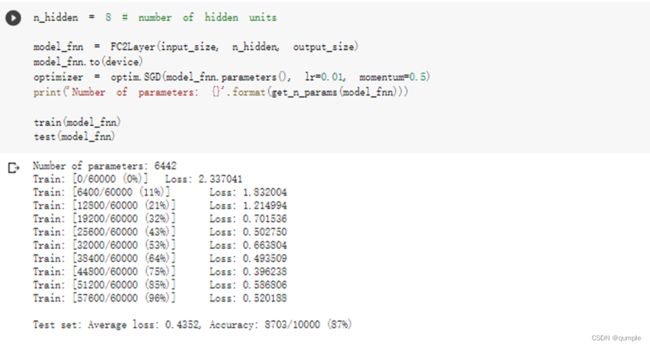
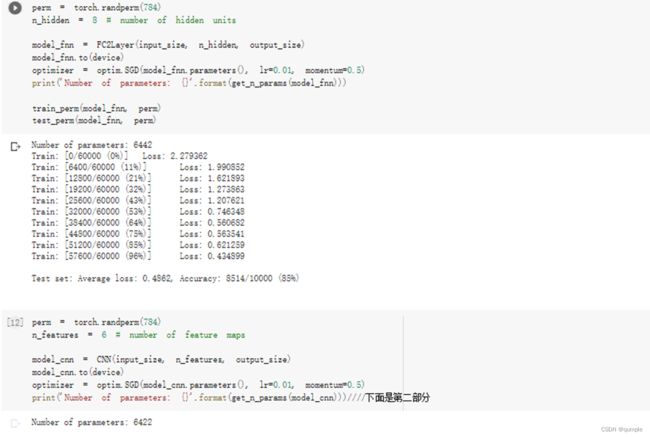
在小型全连接网络上训练
在卷积神经网络上训练

可以看到CNN能更好的处理图像中的信息,主要是卷积和池化的优化。
打乱顺序再次实验
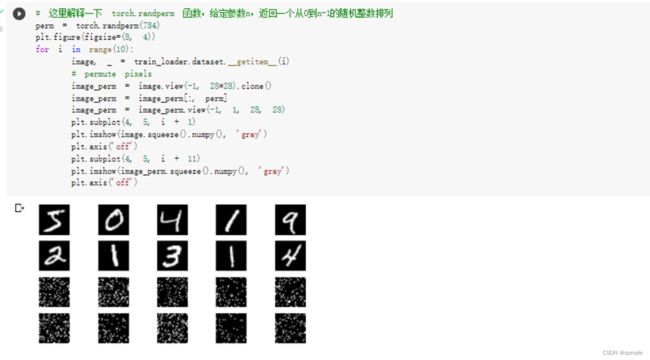
可以看到卷积神经网络的性能明显下降
下面使用CIFAR10数据集
展示图片
训练网络
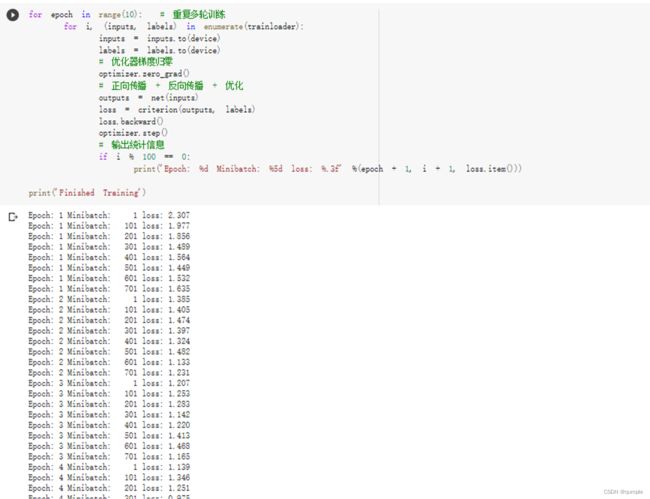
查看识别结果
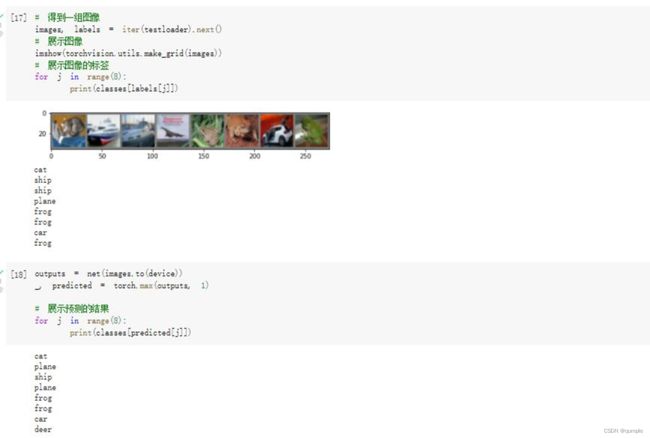
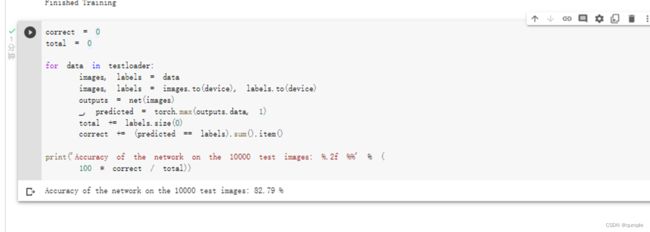
看一下网络在整个数据集的表现
秦奥翔
Part 01
1.加载数据 (MNIST)
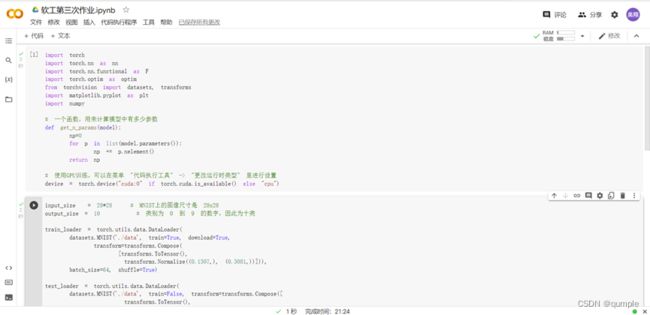
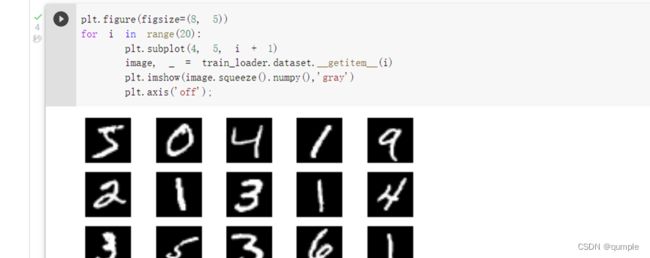
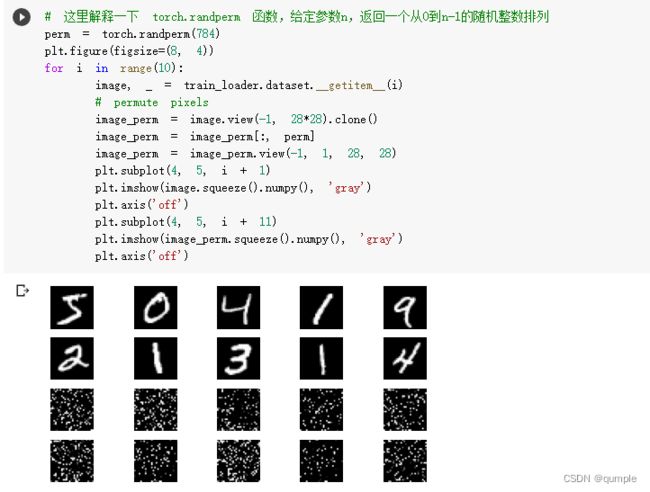
显示数据集中的部分图像
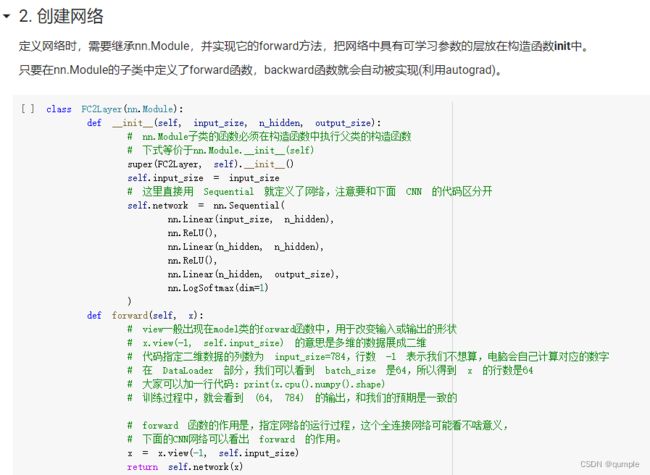
2. 创建网络

定义训练和测试函数

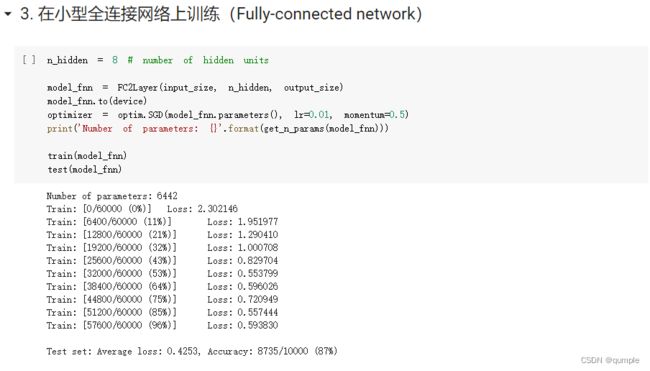
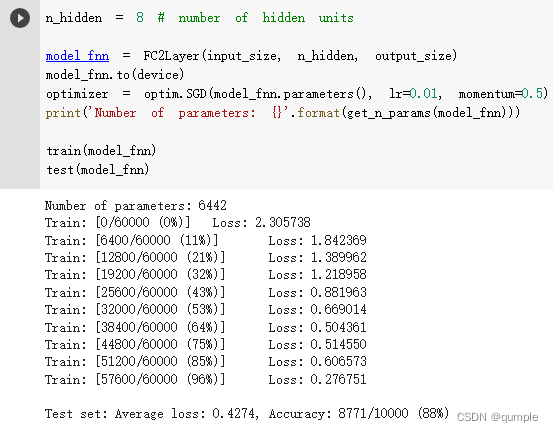
3. 在小型全连接网络上训练(Fully-connected network)
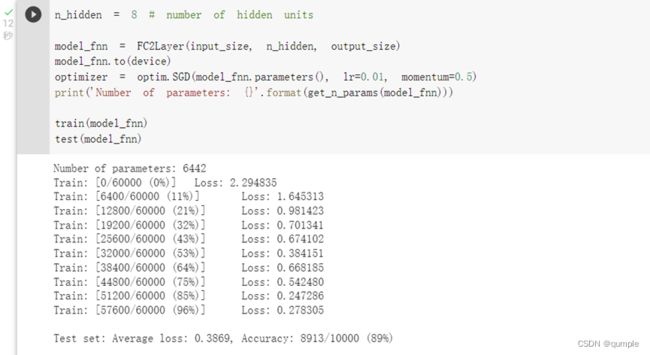
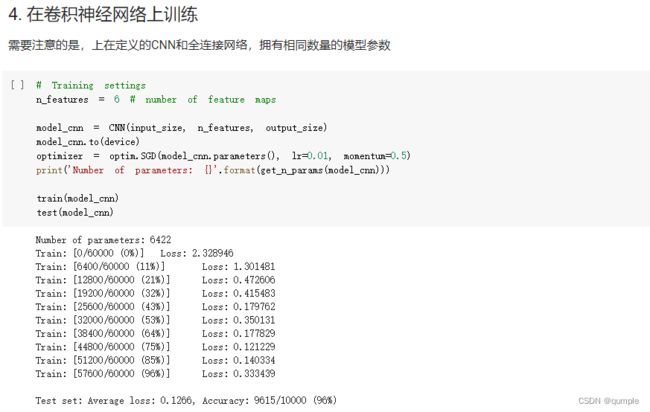
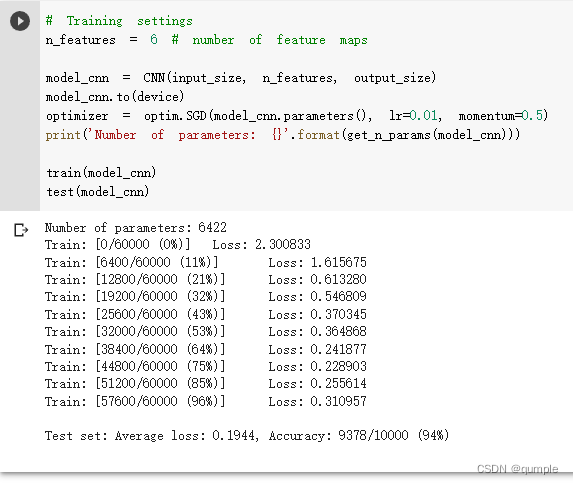
- 在卷积神经网络上训练

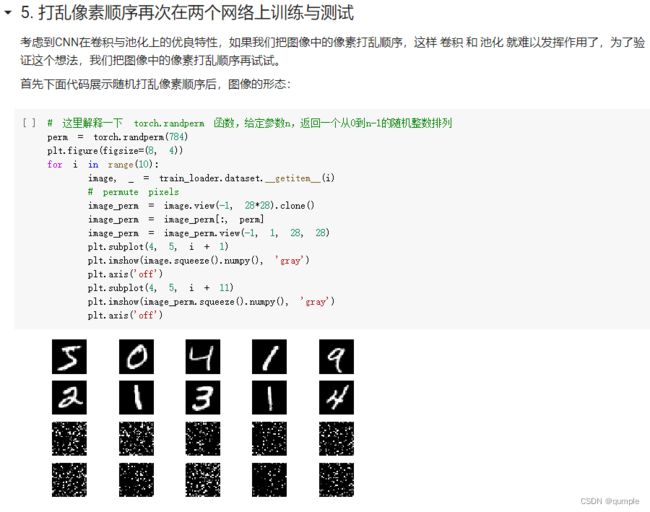
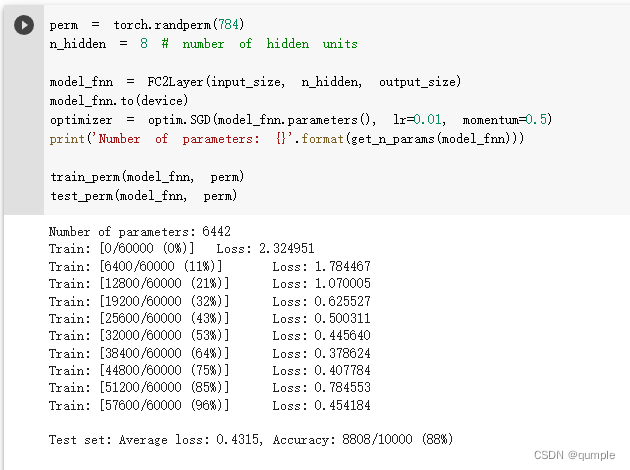
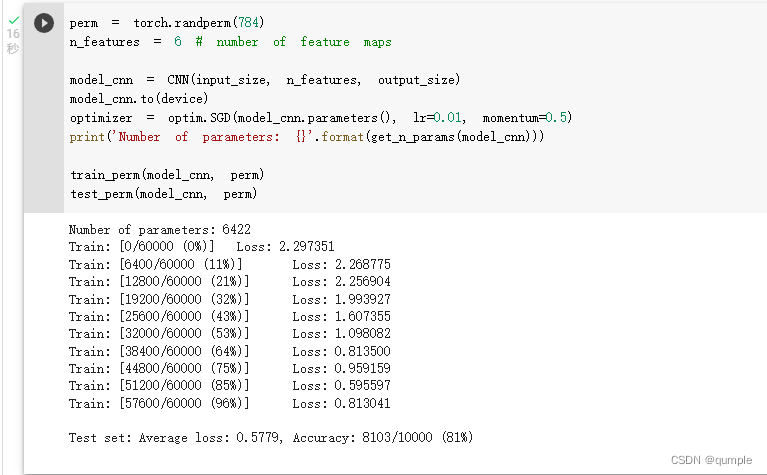
\5. 打乱像素顺序再次在两个网络上训练与测试
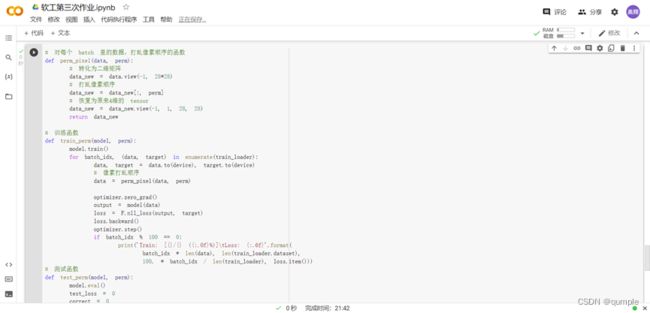
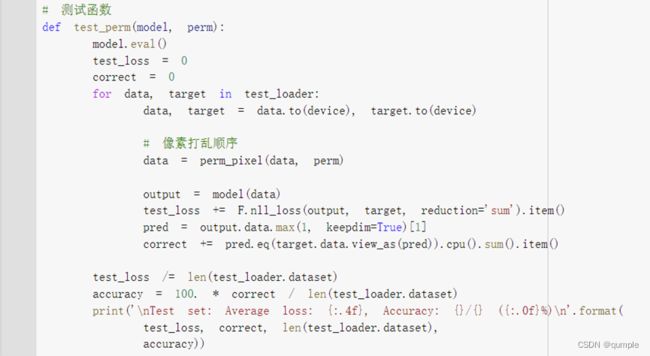
重新定义训练与测试函数,写了两个函数 train_perm 和 test_perm,分别对应着加入像素打乱顺序的训练函数与测试函数。
与之前的训练与测试函数基本上完全相同,只是对 data 加入了打乱顺序操作。
在全连接网络上训练与测试:
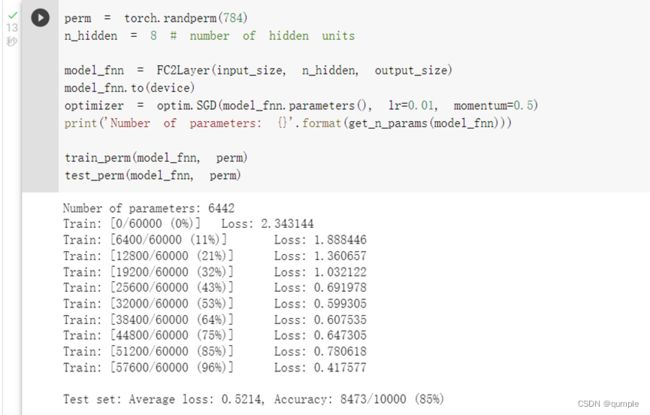
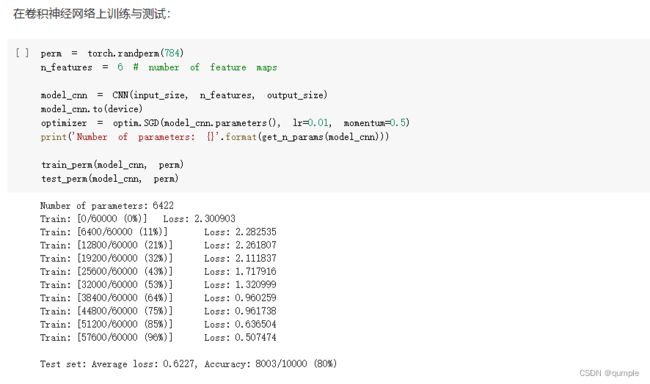
在卷积神经网络上训练与测试:

从打乱像素顺序的实验结果来看,全连接网络的性能基本上没有发生变化,但是卷积神经网络的性能明显下降。这是因为对于卷积神经网络,会利用像素的局部关系,但是打乱顺序以后,这些像素间的关系将无法得到利用。
Part 02
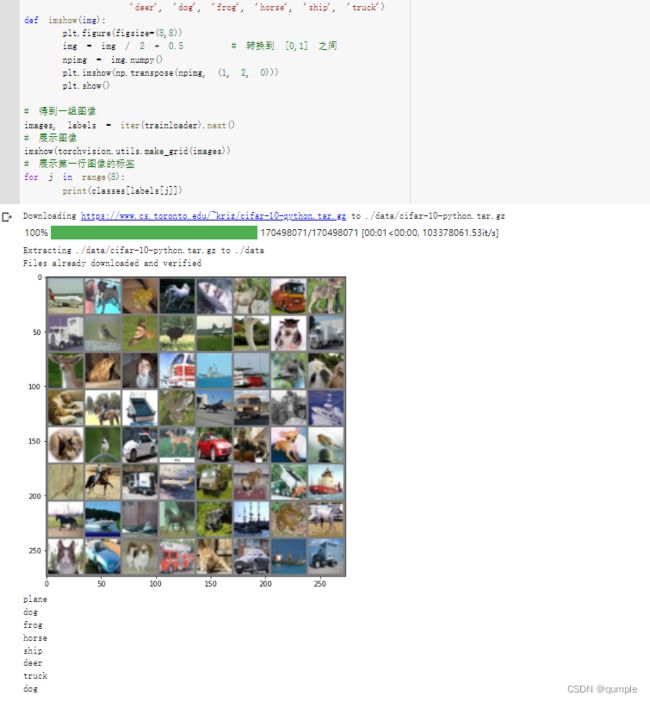
下面展示 CIFAR10 里面的一些图片:

接下来定义网络,损失函数和优化器:
训练网络:
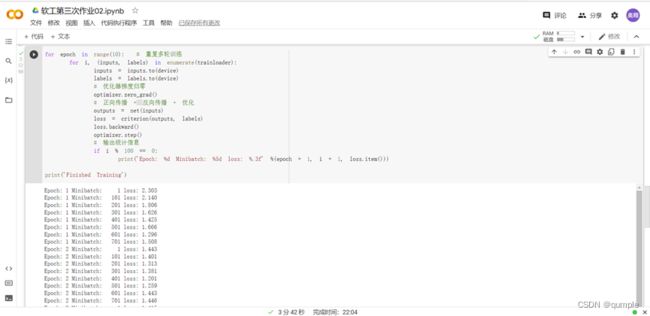

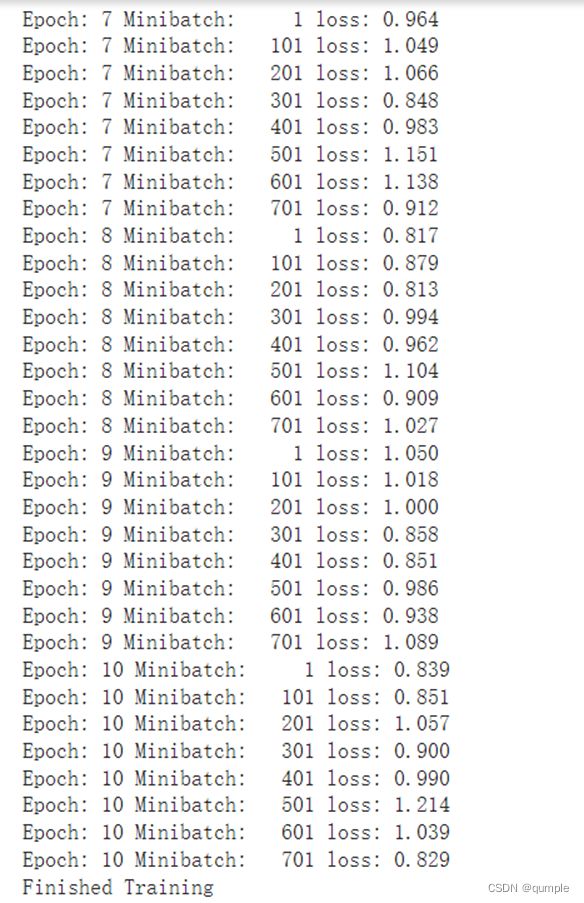
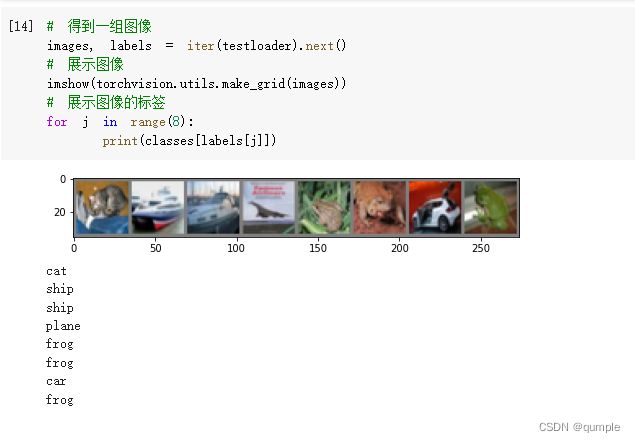
现在我们从测试集中取出8张图片:
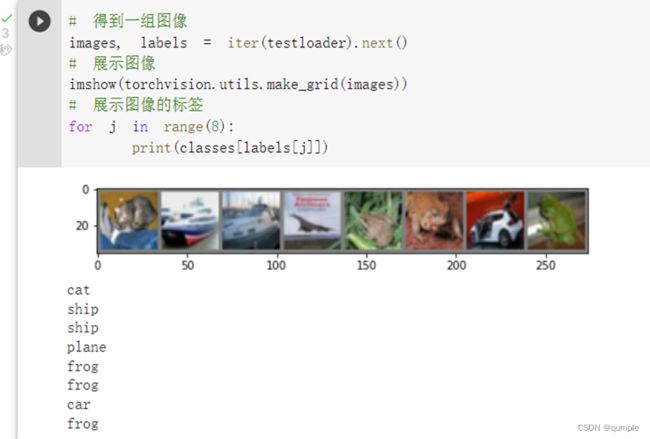
把图片输入模型:
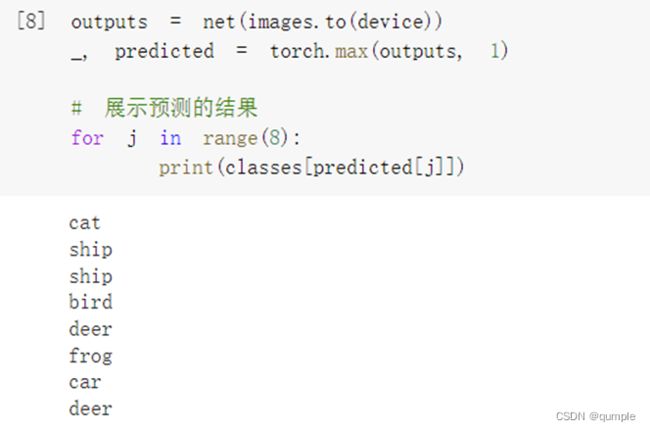
可以发现,有几张图片识别出错了
看网络在整个数据集上的表现:
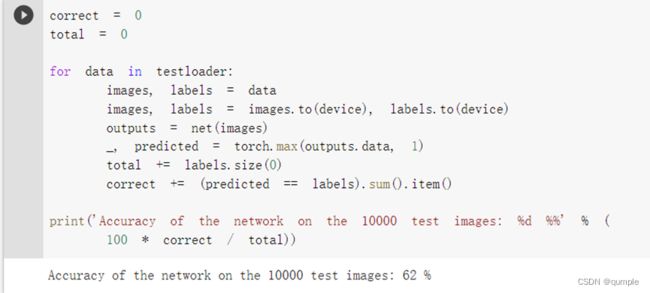
准确率还可以,通过改进网络结构,性能还可以进一步提升。在 Kaggle 的LeaderBoard上,准确率高的达到95%以上。
Part 03
1.定义 dataloader
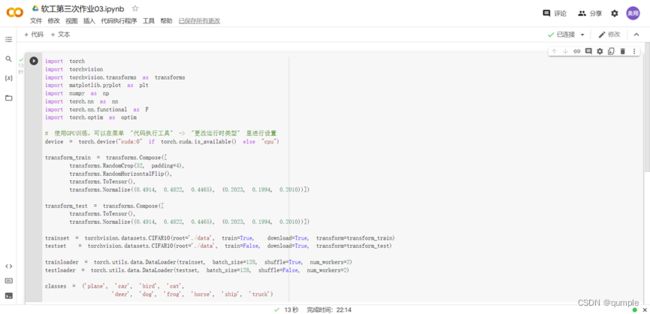
\2. VGG 网络定义
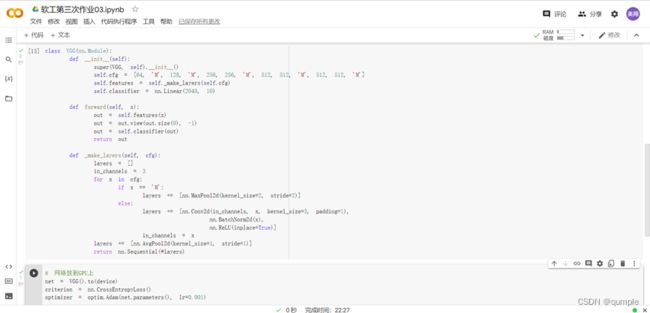
3.网络训练
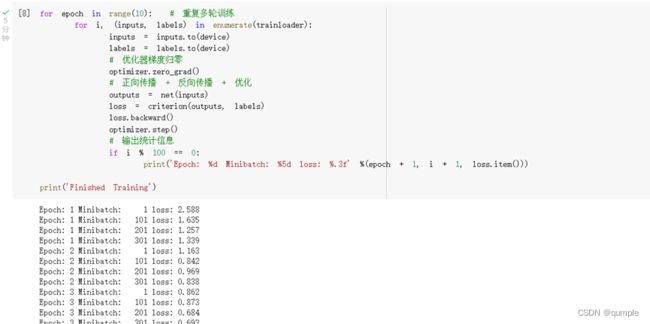
4.测试正确率
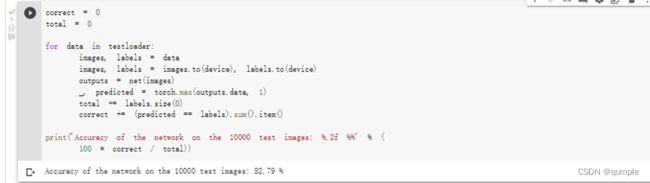
可以看到,当使用VCC网络时,可以将准确率从62%提高到82.79%。
陈子琪
MNIST数据集分类
使用PyTorch进行CNN的训练与测试
加载数据 (MNIST)
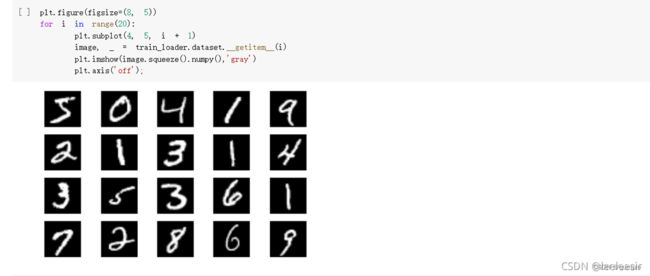
创建网络

定义训练和测试函数
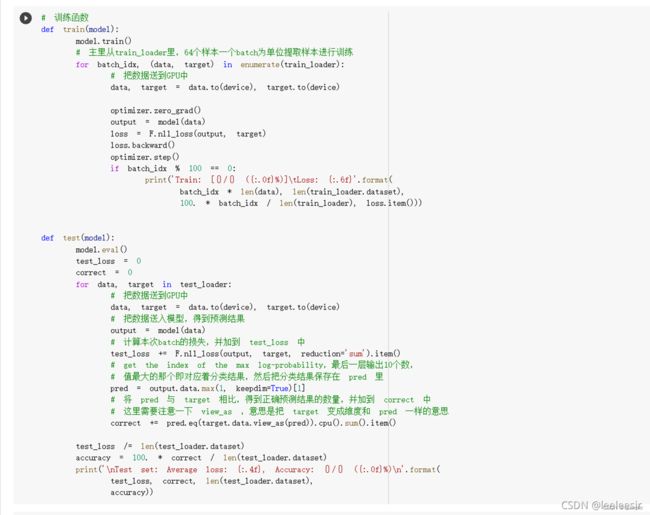
在小型全连接网络上训练(Fully-connected network)
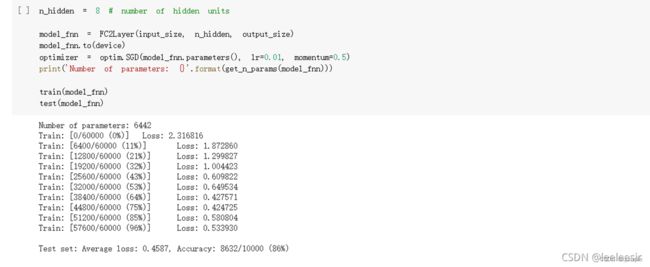
在卷积神经网络上训练
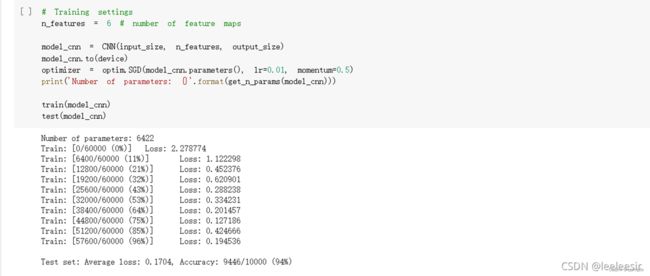
由上面的测试结果可以发现,含有相同参数的 CNN 效果明显优于简单的全连接网络,因为CNN 可以通过卷积和池化更好地挖掘图像中的信息。
打乱像素顺序再次在两个网络上训练与测试
把图像中的像素打乱顺序,卷积和池化就难以发挥作用了。
在全连接网络上训练与测试:
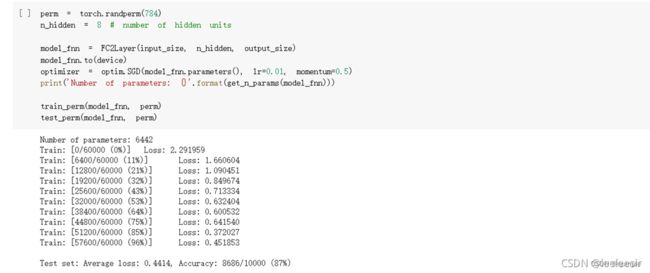
在卷积神经网络上训练与测试:
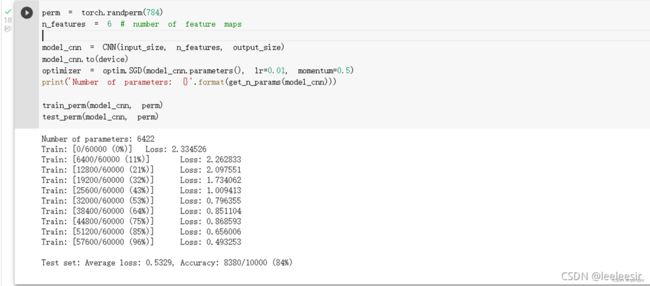
从打乱像素顺序的实验结果可以看出,全连接网络的性能基本上没有发生变化,但是卷积神经网络的性能明显下降。
这是因为对于卷积神经网络,会利用像素的局部关系,但是打乱顺序以后,这些像素间的关系将无法得到利用。
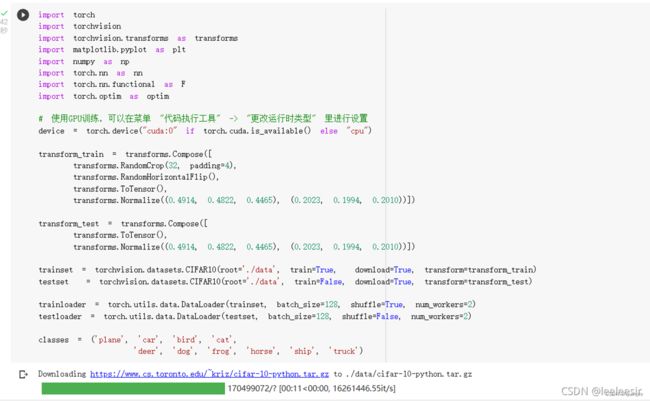
CIFAR 数据集分类
下面将使用CIFAR10数据集,它包含十个类别:‘airplane’, ‘automobile’,‘bird’, ‘cat’, ‘deer’, ‘dog’, ‘frog’, ‘horse’, ‘ship’, ‘truck’。CIFAR-10 中的图像尺寸为3x32x32,也就是RGB的3层颜色通道,每层通道内的尺寸为32*32。
定义网络,损失函数和优化器:

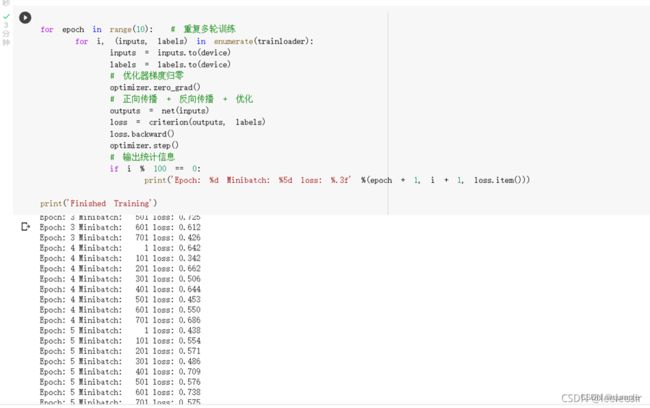
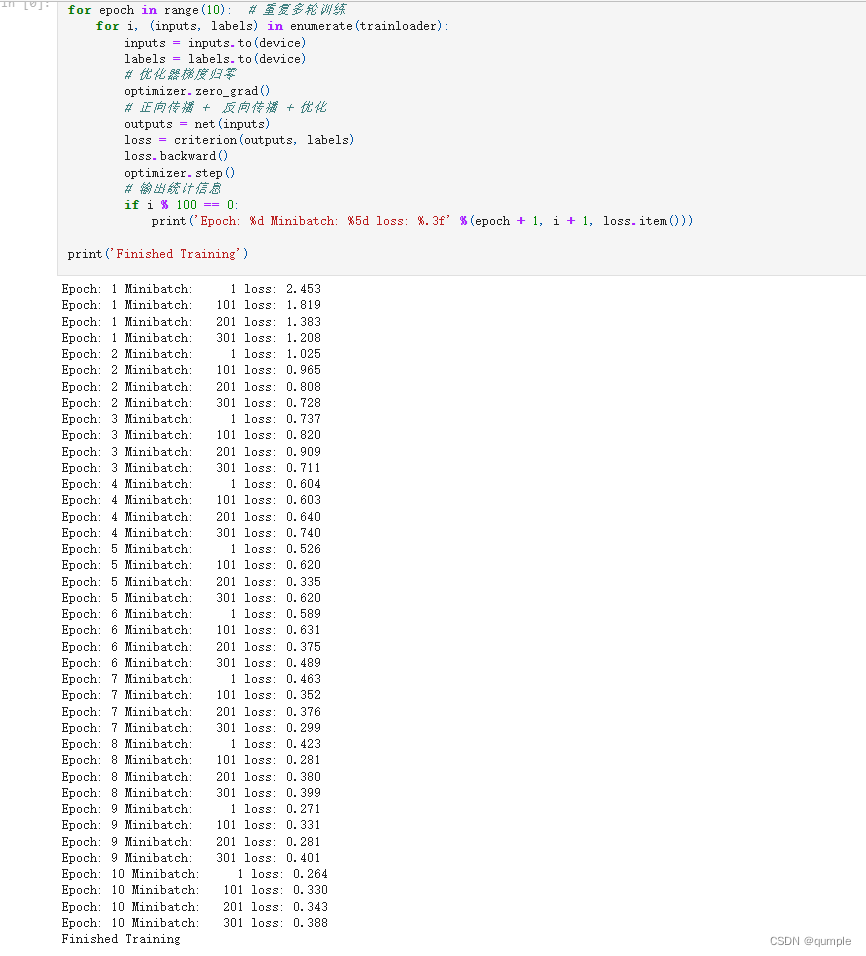
训练网络:
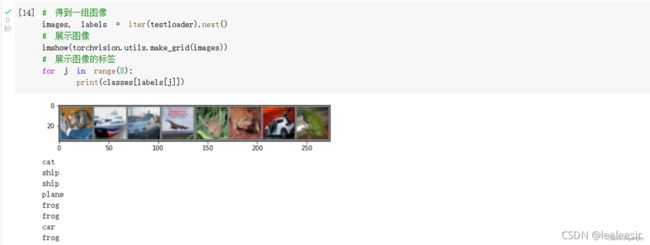
从测试集中取出8张图片:
把图片输入模型,查看识别结果:

其中有好几个均识别出错。
网络在整个数据集上的表现:
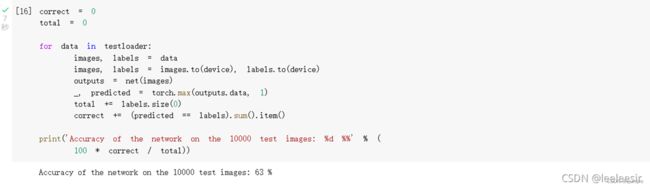
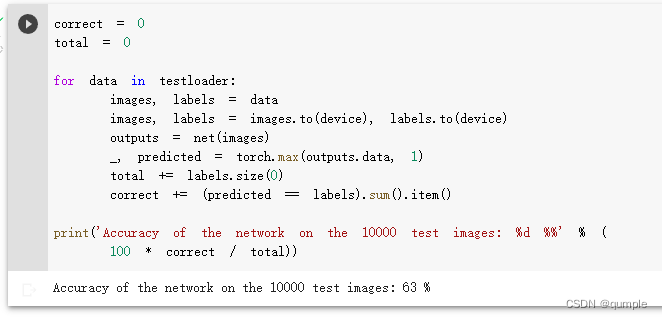
准确率为63%。通过改进网络结构,性能还可以进一步提升。
使用VGG16对CIFAR10分类
定义 dataloader
VGG 网络定义
模型的实现代码:
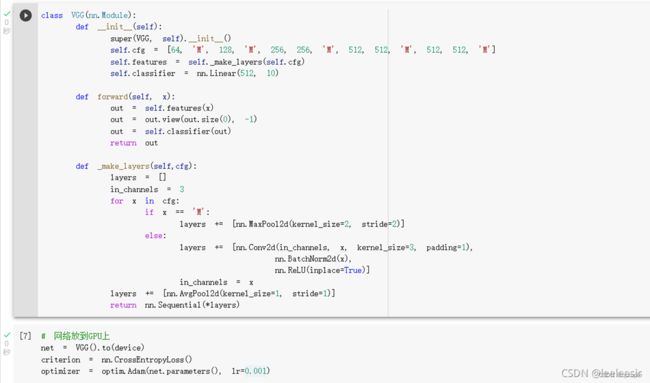
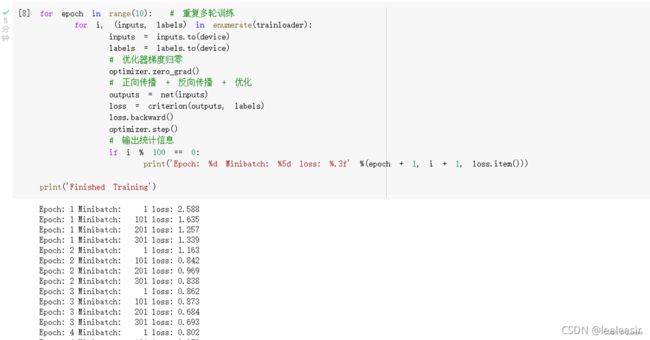
网络训练
训练的代码与之前一样:
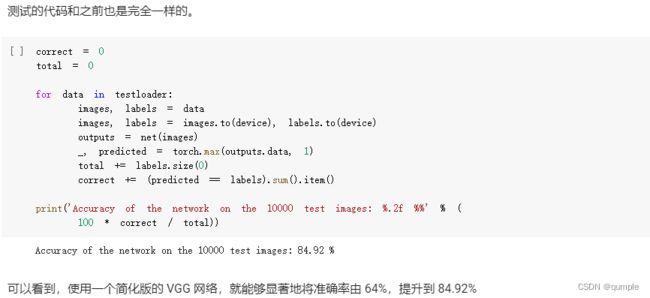
测试验证正确率
测试的代码和之前也是一样的:
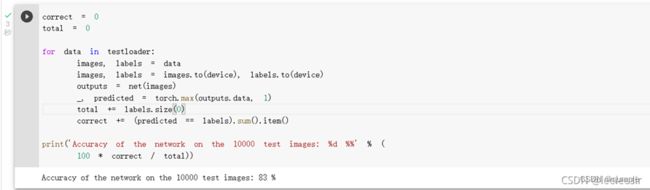
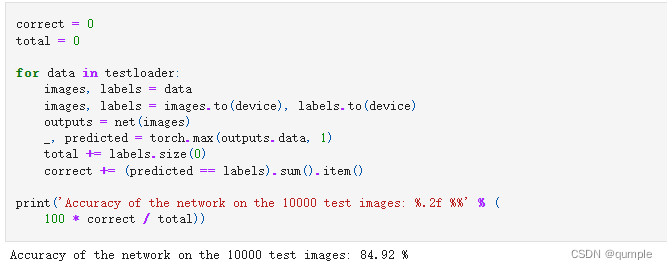
可以看到,使用一个简化版的VGG网络,就能够显著地将准确率由 64%,提升到 83%。
李昊








3.思考问题
1、dataloader 里面 shuffle 取不同值有什么区别?
dataloader中设置shuffle值为True,表示每次加载的数据都是随机的,将输入数据的顺序打乱。shuffle值为False,表示输入数据顺序固定。
是否进行随机打乱顺序的操作
2、transform 里,取了不同值,这个有什么区别?
transform 对数据进行某种统一处理,进行标准化、降维、归一化、正则化等变换操作。例如,transforms.CenterCrop为中心裁剪操作;transforms.RandomCrop为随机裁剪操作;
transforms.Resize为调整尺寸操作;transforms.Normalize为标准化操作;transforms.RandomRotation 为随机旋转操作
transform是常用的图像预处理方法,包括归一化、随机裁剪等,提高泛化能力。代码练习中用到的有: transforms.ToTensor() 作用是转换为tensor格式,这个格式可以直接输入进神经网络; transforms.Normalize()是对像素值进行归一化处理,使得数据服从均值为0,标准差为1的分布
3、epoch 和 batch 的区别?
batch大小是在更新模型以前处理的多个样本。epoch数是经过训练数据集的完整传递次数。
4、1x1的卷积和 FC 有什么区别?主要起什么作用?
1x1的卷积层采用参数共享方式,需要的参数量会比FC层所使用的参数量少,计算速度更快;1*1的卷积可以用于降维(减少通道数),升维(增加通道数),代替fc成为一个分类器; FC层对于训练样本要求统一尺寸,但是1x1的卷积没有。
功能上卷积代替全连接应该是基于输入尺寸的考虑,全连接的输入是特征图所有元素乘以权重再求和,但是这个权重向量是在设计网络的时候就需要固定的,所以全连接没办法适应输入尺寸的变化只能固定
5、residual leanring 为什么能够提升准确率?
残差学习通过残差网络结构,使用恒等映射直接将前一层输出传到后面,可以把网络层弄的很深,并且最终的分类效果也非常好,解决了梯度消失的问题,使得整个学习模型的错误率下降。
6、代码练习二里,网络和1989年 Lecun 提出的 LeNet 有什么区别?
模型构造不同。AlexNet网络包含8层,其中包括5层卷积和2层全连接隐藏层,以及1个全连接输出层。
激活函数不同。传统的LeNet网络使用的是sigmoid激活函数,而AlexNet使用的是ReLU函数。
7、代码练习二里,卷积以后feature map 尺寸会变小,如何应用 Residual Learning?
采用1x1的卷积,设置步长为2。
8、有什么方法可以进一步提升准确率?
使用分类更合理、特征更明显的数据集;选择性能更优的神经网络结构;选择合适的优化器、激活函数等。