黄硕:百度飞桨文心大模型在语音文本审核中的应用
实时互动作为下一代基础技术能力,正在支撑并推进着人、物及空间之间创新的沟通和交互方式。
语音处理是实时互动领域中非常重要的一个场景,在「RTC Dev Meetup 丨语音处理在实时互动领域的技术实践和应用」活动中,来自百度、寰宇科技和依图的技术专家,围绕该话题进行了相关分享。

百度飞桨文心大模型在语音文本审核中的应用
黄硕 百度自然语言处理部架构师
深度学习预训练大模型最近几年发展迅速,颠覆了很多以往使用传统机器学习技术解决的领域。得益于大模型技术在百度的发展,语音文本审核这项互联网传统业务在技术上也有了较大的发展。
本文将在大模型相对传统模型的整体效果、通用性、个性化需求适配以及服务性能上进行介绍和展开,希望让大家了解大模型的优势,以及审核技术最新的一些发展趋势和业务应用效果。
01 百度飞桨文心大模型的发展
1、业界大规模与训练模型的历史
2018 年,Google 推出 BERT 预训练大模型之后,自然语言处理领域的很多传统做法被彻底改变。在此之前,如果想让机器理解人类的语言,往往要解决一系列语言学问题,比如,中文领域最基础的切词、词性标注、实体识别、核心词的抽取,甚至复杂句子中词语的依存关系,才能让计算机准确理解一句话中的逻辑关系,从而进行搜索、相关度计算或者推荐等完成任务。
而 BERT 这一类针对文本的大规模预训练模型被提出之后,GPT、T5,以及百度的 ERNIE 等大模型底座相继推出,使得我们在理解语言文本的相关任务时,可以快速地基于大规模的预训练模型底座,利用其对语言的理解,直接在上层搭建要解决的任务即可。
如图 1 所示,在 2014 年左右,业界就已经有了类似 word2vec 的词向量的实践,百度的网页搜索、语义计算排序的大升级也是在 2014 年左右进行进行了全流量上线,这些技术在当时优雅地解决了搜索排序时关键词不完全匹配的问题,通过这些技术,计算机也可以理解词语背后的语义,不过在效果和泛化性上不及后来结合 Attention 以及 Transformer 等网络结构的预训练模型。
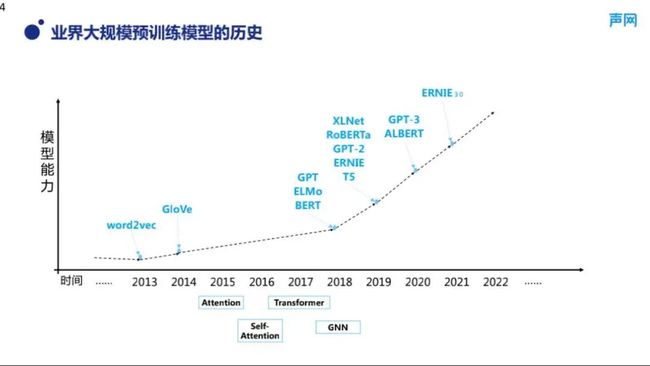
■图 1
2、深度学习技术框架在百度的发展
刚才提到,关于语义向量的计算,百度在 2013 年左右就已经开始了相关实践。图 2 的时间轴展现了百度深度学习技术的发展历程。在 2012 年左右,百度就已经开始在语音识别和 OCR 领域研发深度学习相关的技术,而深度学习在搜索上的应用也在 2013 年左右完成上线。同时,百度还自主研发了 PaddlePaddle,也就是飞桨深度学习框架。深度学习技术在图像、文本、语音、搜索推荐以及自动驾驶等各个百度的主要业务上都实现了大规模的应用。
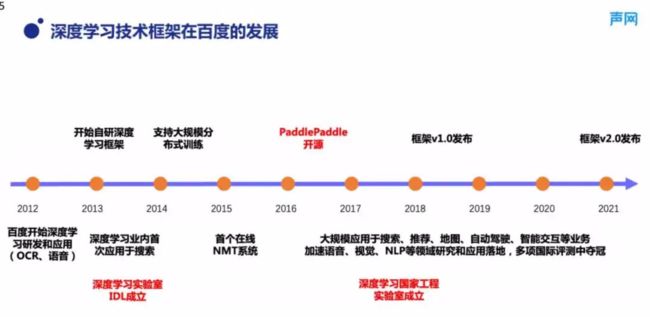
■图 2
3、百度飞桨文心与训练模型近几年的发展情况
百度在 2019 年推出了飞桨文心大规模预训练模型,今天会围绕我们使用文心大模型在审核技术方面所尝试的各种应用方式来进行技术分享。在最近两三年间我们陆续发布了 2.0、3.0 以及各种不同领域、不同语言、不同规模的文心大模型版本。
图 3 展示了文心大模型的家族。文心大模型的家族从下向上分为几层,其实不仅是飞桨文心大模型,业界类似的大模型大多数也是如此。文心大模型有不同粒度的版本,也有针对不同任务类型进行优化的版本。比如,针对语言生成的模型和用于信息抽取的模型,模型底座对应不同任务会有效果差异。再上层,中间是一层领域模型,基于不同的领域,大模型技术会利用不同的预训练语料打造不同的效果,所以在不同的领域中,效果也会有所不同。再上一层是比如跨模态、跨语言这种,也就是说,除了文本以外,还可以融合语音、图像、文档等不同的信息模态,实现一个更多层次的预训练模型。最顶层代表不同倾向的预训练大模型的应用,其在搜索、推荐、语音、文档、客服等各个业务上都得到了应用验证。
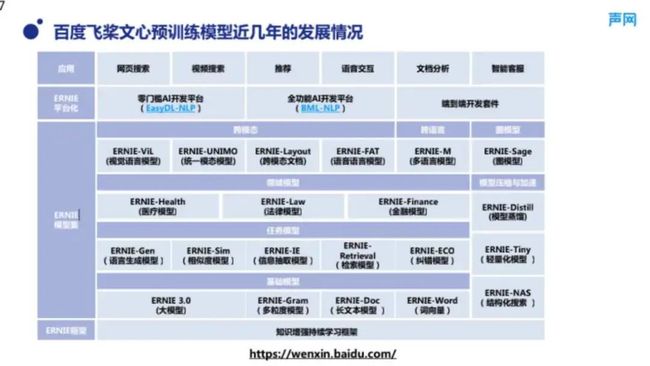
■图 3
文心大规模的预训练模型语音文本审核业务上能起到什么作用呢?关于这一点我将会从多个不同的方面来进行分享,包括大模型作为模型底座的效果是怎么样的?针对大模型的性能问题,利用蒸馏技术能起到什么样的作用?大模型对于数据样本增强会起到什么样的作用?在不同用户的个性化需求方面,大模型的作用是什么?大模型可以如何优化传统审核业务中的匹配规则策略?
02 文心大模型在语音文本审核中的应用
1、审核业务特点
(1) 文本审核与语音审核背景介绍
文档审核是语音审核的一个基础,内容审核在业界大致划分为涉黄、涉政、广告暴恐、辱骂等类,各类在数据层面的细分中具有不同的审核目标。而这些不同的数据来源对于审核技术来说,难度是不一样的。比如,在新闻网站上发布的文章,其内容、用词会相对规整;而用户评论或论坛发帖等文本,在用词和句式方面就会相对随意。对应到审核的需求,每一类下的细分内容也会有不同的需求,对应的技术方面,词库结合模型的语义判断是最常见的做法。
除了经典的通过 ASR 转译为文本后可以利用文本的审核能力以外,语音数据具备其他特点。比如声纹,我们仅凭文本字面无法识别一句话是在愤怒的情绪下还是平静的情绪下讲述的,但通过声音其实可以得到这些信息。此外,语音的断句、转译、纠错,以及利用机器人合成的语音广告、对话等,都是在语音审核方面区别于纯文本的特点。
(2) 语音审核与文本审核技术常见难点
图 4 展示了审核技术方面通常包含的技术难点。第一个是数据的多样性,比如新闻稿、用户弹幕和机器人语音,数据的内容差异非常大。第二个是审核需求的多样性,涉政、涉黄、广告等各个类目,其审核重点、在数据中的检出率,以及对于语义理解的需求程度,难度各不相同。第三个是审核业务对服务的性能要求通常较高,如在语音直播、语音聊天、弹幕等应用中,对时延的要求是非常高的。此外,很多业务需要实时拦截,而不能接受离线大批量审核过滤方式。
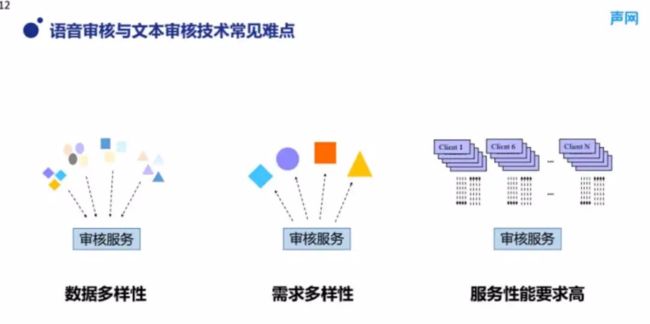
■图 4
(3) 审核业务客户个性化需求
除了上述几点通用的技术难点以外,还有一些常见的来自客户的个性化需求。比如,审核的尺度存在差异,比如针对不同客户的批评,在比较严肃的论坛中,客户的要求基本是零容忍;而在聊天场景下,客户或许可以接受一些不太过分的口头禅等。这样,即使是同样的审核需求,但是对于尺度的要求可能也是不一样的。
另外,在审核类目方面,比如,同样是涉黄审核,语音和纯文字的审核侧重点可能是不一样的,比如一些涉及未成年人保护的审核要求等,在内容的审核要求方面侧重点就是不一样的,这是不同用户的特点。那么,我们是怎么结合大模型尝试解决上述这些技术难点的呢?我将从下面几个方面展开介绍。
2、文心大模型底座
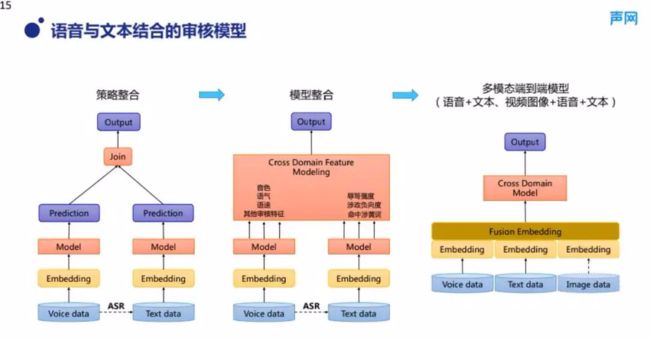
(1) 语音与文本结合的审核模型
首先我们从模型本身来讲,图 5 是语音跟文本相结合的审核模型,图 5 从左到右是三个不同层次的模型的语音和文本结合方式。首先,我们一般把审核模型建模为一个分类问题。当然,在一些场景下,为了识别出不同的审核程度,我们也会结合回归建模技术,但通常来说都是分类问题。图 5 的左边展示的是一种最朴素的语音审核模型和文本审核模型的结合方式,过程是在两个模型分别预测出结果之后,通过规则策略将其相结合,这是一种最简单的方式。但这种方式的效果是不太理想的。中间的模型进行了整合,把文本和语音模型在特征层面展开,使两边的模型分别产出特征,然后在这一层进行跨模态的的特征层建模。这样做的好处是,比如我们要判断一段话是不是涉黄,不是单纯地把语音模型识别出来的结果跟文本模型识别出来的结果进行加权打分,而是可以结合语音模型中识别出来的性别特征和语调,以及在语音方面比较特殊的审核特征,通过从文本模型中识别出的整体涉黄度、涉黄特征词等详细特征,让模型进行最终判断。这是目前我们发现的一种效果比较好的建模方式。最右侧是一种多模态的端到端建模的方式,它是在语义理解的 embedding 层把语音和文本展开,并在该层交叉之后直接进行建模。从长远来说,这种端到端的方式更通用、更优雅,而且可以更好地扩展到视频领域。比如我们可以把图像特征也引入到 embedding 层上,目前我们在文档理解和视频图文理解方面的大模型中就是采取这种方式。
■图 5
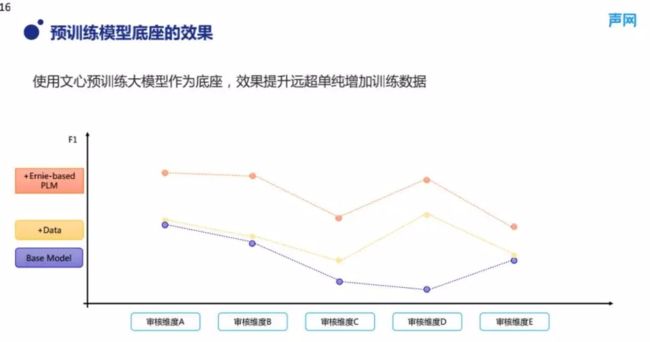
(2) 预训练模型底座的效果
图 6 展示了使用文心模预训大模型之后的效果,可见利用这种语言理解的大模型作为底座,效果远远超过单纯地增加训练数据。图 6 中紫色的线代表基线模型,这大概是我们一两年前使用的基准模型,这里横轴是在不同审核维度上的模型效果,纵轴中与基线模型对比的有两种方法,黄色代表持续增加训练数据,在持续增加训练数据的情况下,模型效果是明显有所提升的。而橙色展示的是把模型底座完成预训练大模型之后的趋势,发现其效果得到了整体的提升,可以说远远超出花费大量时间不断积累训练数据所带来的效果。
■图 6
使用预训练大模型,除了直接替换语义理解层能带来显著的效果以外,我们还利用预训练模型可以进行领域适配的这种领域预训练方法,打造了多种不同场景下的场景化审核模型。如图 7 所示,左边是一个比较简单的流程示意图,展示的是领域训练的过程,对于已有的文心预训练模型,我们会加入大规模的无标签的领域语料进行领域预训练。这样,该模型的底座能更好地理解特定领域的语义,在用于上层的审核模型训练的时候,其训练出来的模型对场景效果适配得更好。最右侧是效果的对比图,这是我们在游戏场景下进行的效果评估。前四种颜色是我们的通用模型跟几家友商内部评估的模型效果的对比。可以看到,在不同的审核维度下,效果是各有所长的。但是当使用经过领域预训练的游戏场景模型之后,可以很明显地看出,在各个维度上,不管是对比友商还是对比之前的通用模型,效果都是显著领先的。

■图 7
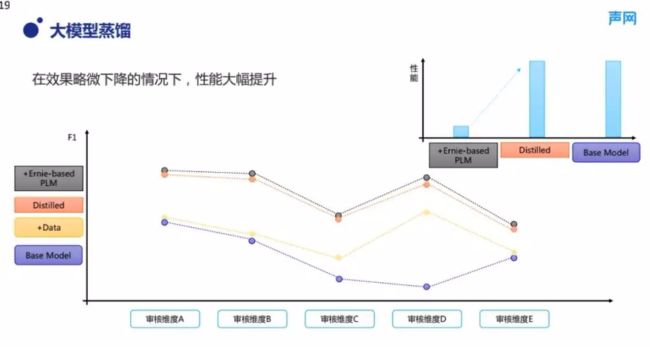
3、大规模蒸馏
众所周知,大模型无论是训练还是预测都需要巨大的计算量,那么在审核服务这种性能要求较高的场景下,怎么使用大模型呢?接下来针对性能的问题介绍大模型蒸馏的效果。对于大模型蒸技术大家可能都有所了解,通过数据蒸馏或模型蒸馏方式,效果会受到一定程度的损失,但性能会得到显著的提升。具体到我们的业务中,可以看图 8 所示,左侧图中橙色的线展示了大模型经过蒸馏,被压缩到一个较小的模型结构之后,用于预测服务的模型效果,相比完整训练好的大模型它的效果确实会略有下降,但是相比于小模型或者加入大量训练数据之后的小模型,它的效果还是得到了显著提升。
■图 8
右上角是我们在服务预测性能方面进行的评估,这里我没有列具体性能提升的数字,因为蒸馏之后小模型结构跟基线模型是一致的,所以它的预测性能跟使用大模型之前是齐平的。可以看到,跟完整的大模型的性能差距大概是数十倍的量级。
4、样本增强
除了直接用于模型层以外,利用大模型技术,我们可以在数据样本层进行一些比较有意思的操作。这里列举两个样本增强的例子,前面提到过,在审核业务过程中,由于客户需求的多样性,我们无法基于每一个客户的需求标注大量的训练数据来优化模型,所以如何低成本地获取大量的有效训练样本是一个很关键的问题。通过图 9 分别展示了我们如何利用文心大模型基于有标签的训练数据和无标签的数据达到样本增强的目的。图 9 左侧展示的是基于有标签的训练数据,利用文心大模型针对生成任务的预训练大模型,这里我们用到 ERNIR-Gen。利用该模型可以生成大量与训练数据相似的样本,然后结合相似度或者匹配等简单的过滤规则,可以低成本地得到大量基于生成的训练数据。
■图 9
图 9 右侧展示的过程是,首先收集大量线上业务中无标签的数据,然后通过预训练大模型的语义聚类计算加入少量有标签的数据,对无标签数据进行聚类,同时在每一个聚类处的结果中结合有标签数据的分布,可以看到哪些位置的标签大概率是相同的,从而得到大批量基于聚类的来自线上的训练数据。
此外,利用大模型进行样本增强,除了通过生成或者聚类方式以外,还可以进行一些更有针对性的任务。比如在处理审核业务的时候,往往要求审核模型具有泛化性。所谓泛化性是指可以覆盖某些“变体”,这是业界常见的绕过审核技术的文本表达方式。对于这个问题,我们利用大模型的泛化性,借鉴文本纠错技术中的建模方法,除了对单字的特征进行语义的建模以外,还将拼音和笔画这两种信息都进行了建模,使大模型能够理解发音相同,或者笔画相似的字,使得大模型具有一定的变体识别能力。当然,如果直接建模大模型用于审核业务,其效果并不如人意。所以基于变体识别的大模型,我们可以通过数据增强方式有针对性地从外部定向挖掘可疑的变体和样本,然后在离线利用变体检测模型进行识别,经过校验后将样本添加到模型的训练数据集中,就可以持续提升审核模型对变体的识别效果。
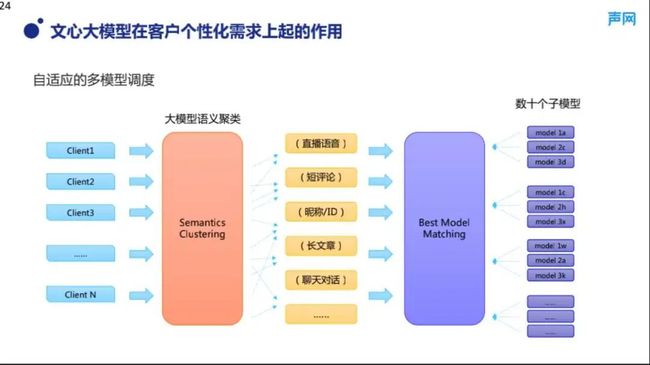
5、个性化需求扩展
在技术难点的介绍中提到过,不同客户的数据来源是不一样的。这导致长期下来除了几个通用的审核模型以外,我们还积累了大量的不同场景下效果不同的子模型,如何使系统智能地给不同的用户选择最优的模型组合,这对系统整体来说是一个难题,为此,我们尝试了一种自适应的多模型调度框架。
首先是利用大模型对于客户数据进行语义聚类,使类型相似的数据聚集在一起。如图 10 所示,中间黄色这一层就是一个示意。当然我们无法准确地知道不同类的数据是怎样的,但是它们的长短、文本特征分布等方面会有一定的特征,使得类似需求的数据聚集在一起。将这些数据聚集在一起之后,再进行最优模型的选择。这样,既可以解决客户的个性化需求,同时也可以避免整套系统无限的膨胀,因为我们不可能持续不断地为每一个客户增加效果优化过的子模型。通过这个语义聚类,运营人员也可以在模型的选择层介入,这样可以更有针对性地进行效果的分析和客户需求的效果优化。
■图 10
另外,为了满足不同的客户在审核尺度上的需求,审核服务的输出是支持阈值可调的。但是我们在训模型时经常会遇到一个问题,就是模型预测结果的概率分布经常聚集在很小的区间中。比如图 11 所示,模型预测出来的结果可能 90% 都集中在 0.4~0.6 这一概率区间之内,这会导致客户无论是设置 0.8 的阈值还是 0.9 的阈值,都无法得到令自己满意的准确召回率。因此,我们尝试了不同的模型建模方法,比如在辱骂轻重度的需求方面,我们引入了 Pairwise 的建模方式,并在数据标注的时候尝试了更细粒度的分档标注,而不是简单的 0/1 标注。这使得模型对审核的程度更加敏感,从而一定程度上达到了把预测结果分布拉伸到更广的范围上的目的。
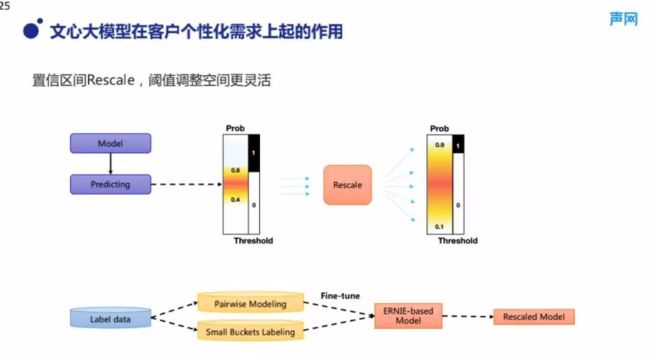
■图 11
6、大模型优化匹配规则
图 12 的最左边是一个简单的词匹配规则流程。词匹配技术是传统审核系统中必备的环节。可以说大概从十多年前互联网审核需求出现开始,就产生了词匹配技术。词匹配技术具有简单、见效快、精准等特点,但是它没有泛化性,同时由于长期维护很容易导致规则的冲突,历史规则或者词更新标准不一致等都是长期维护中存在的难题。
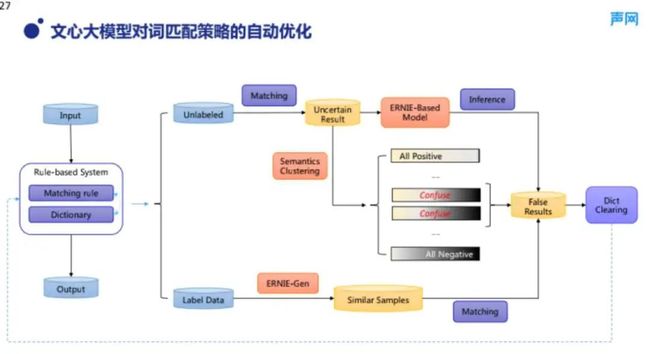
■图 12
在图 12 中我想举例三个例子,这是三种利用大模型优化词匹配系统的方法。其中,流程图上边这部分利用了无标签数据,下面这部分利用了有标签数据。首先基于无标签数据有两种方法可以优化词匹配规则。第一种是将无标签的数据结合现有的词匹配规则,可以得到大量不确定的匹配结果,对于这些匹配规则得到的结果我们不确定其正确性。然后可以利用大模型进行二次的审核校验,这样可以得到一些高置信度的错误匹配的结果。利用这些错误的样本就可以反向清洗词库或者匹配规则,这是一种直接高效的做法。另一种方法是对无标签数据进行匹配之后,得到一些不确定的样本,然后将这些样本进行语义聚类。注意,此时既要添加匹配的样本,也要把一些不匹配的样本,也就是没有命中审核规则的样本也添加进来。在进行语义聚类之后,可以分析每一个聚类簇的标签分布。我们可以发现,有一些簇的标签是非常一致的,比如 100% 认为是正样本或者 100% 认为是负样本,也会有一些簇的标签是相互矛盾的。同一个簇的语义是非常相近的,于是对于一半命中、一半没有命中的情况,可以找出这些标签矛盾的样本,这些样本同样能用于词典和匹配规则的清洗。第三种方法是利用已有的少量的有标签数据,通过大模型技术生成一批标签相同、文本相似的样本,然后用于校验词匹配规则,这可以起到类似的效果。不过我们常用的是前两种,因为这样可以经常利用最新的线上业务数据来校验历史词表和规则策略的准确性。
03 百度语音文本审核产业化发展
图 13 展示了审核业务所依赖的技术全景图,从数据层到基础的算法,包括词法分析、句法分析、语义计算等技术,蓝色部分展示了审核业务支持的各种功能细节,最上层是审核技术支持的产品。可以看出,审核技术目前除了对外支持以外,同时也支持了百度重要的产品业务,比如说输入法、百家号等。在对外业务方面,百度的内容审核在各种常见的内容生产/分发场景都得到了广泛的应用,比如视频直播、社区社交、在线教育等。在服务接入方面,百度的内容审核支持在线的公有云接入方式,也支持私有化部署。
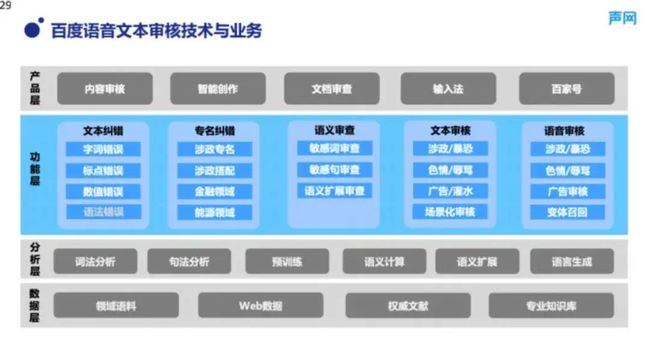
■图 13