复现 Oriented R-CNN RTX3080ti
在3080ti主机上复现Oriented R-CNN,参考了:复现Oriented R-CNN RTX 2080Ti_吃肉不能购的博客-CSDN博客
这篇博文给我提供了很大帮助
前言
GitHub链接:GitHub - jbwang1997/OBBDetection: OBBDetection is an oriented object detection library, which is based on MMdetection.
显卡:RTX3080ti
系统:Ubuntu20.04
一、创建环境
conda create -n pytorch171 python=3.7 -y
conda activate pytorch171
conda install pytorch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2 cudatoolkit=11.0 -c pytorch这里我一开始用了我的比较高版本的pytorch去跑,发现会报THC/THC.h的错误,简单说就是torch版本太高,和代码里用的函数不匹配。之后参考另一篇博文想用pytorch=1.6.0,但是30系显卡只支持cuda11,所以尝试了最低的支持cuda11的版本torch=1.7.0,然后代码setup成功了,但还是莫名其妙有错误,查了说好像需要1.7.1。第二天索性删掉环境重来,直接下载torch1.7.1。
二、配置OBBdetection
下载代码文件
git clone https://github.com/jbwang1997/OBBDetection.git --recursive
cd OBBDetection安装BboxToolkit
cd BboxToolkit
pip install -v -e .
cd ..如果下载git下载的时候出错误了BboxToolkit没下载下来,或者文件夹没有setup.py文件,就去https://github.com/jbwang1997/BboxToolkit.git下载然后覆盖过来。
然后安装mmcv
https://download.openmmlab.com/mmcv/dist/cu110/torch1.7.0/index.html
这是openmmlab官方的的下载地址,只要把链接里面cu(CUDA)和torch改成你想要的版本就可以看到对应版本的mmcv-full,如果没有就是不支持这个版本,我一开始找的是torch1.7.1,然后发现没有,但是1.7.0支持,应该能兼容,然后安装。这里我安装的1.4.0,obb官方要求大于1.3,最新的版本已经到1.6了,但是版本太高说不定也会报错,没试过,所以装1.4.0。
pip install mmcv-full==1.4.0 -f https://download.openmmlab.com/mmcv/dist/cu110/torch1.7.0/index.html --no-cache-dir安装Obbdetection
pip install -r requirements/build.txt
pip install mmpycocotools
pip install -v -e . 这里要等个几分钟,只要不报错就行,安装成功显示:
Successfully installed Pillow-6.2.2 mmdet-2.2.0+4c779ba
三、运行代码
1、运行demo
先去网上下载他训练好的权重,然后在Obbdetection文件夹下新建个ckpt文件夹用来放权重文件,如果报错说这“is not a checkpoint file”,那有可能是pth文件名或者目录写错了,系统没找到这个文件。
OBBDetection/configs/obb/oriented_rcnn at master · jbwang1997/OBBDetection · GitHub
python demo/huge_image_demo.py demo/dota_demo.jpg configs/obb/oriented_rcnn/faster_rcnn_orpn_r101_fpn_1x_ms_rr_dota10.py ckpt/faster_rcnn_orpn_r101_fpn_1x_dota10_epoch12.pth BboxToolkit/tools/split_configs/dota1_0/ss_test.json
因为我用的是个人主机,所以是可以直接plot出来的,如果不能显示图形界面,plot画不出图来,可以参考另一篇文章里的方法(链接),加入保存图片的代码。找到mmdet/apis/inference.py,最后一行加入cv2.imwrite("xxxx320.jpg", img),但别忘了在开头再加上import cv2,不然还得报错,运行后会在当前目录下生成一张图片。这是我plot出来的结果:
2、训练
如果上面的demo没有问题,那就成功一半了,接下来是训练,先准备好HRSC2016数据集。因为configs中的配置文件里默认数据集路径为‘‘data_root = 'data/HRSC2016/’’,我懒得改配置文件了,所以我把数据集放到了OBB的一个data文件夹下。然后运行代码:
python tools/train.py configs/obb/oriented_rcnn/faster_rcnn_orpn_r101_fpn_3x_hrsc.py --work-dir work_dirs 然后需要注意的是:默认的配置文件中,每隔一个epoch保存一次参数,并且没有验证过程,所以如果怕空间不够或者想训练过程中看验证效果,可以改一下配置文件,但是原版的配置文件是这样的:
_base_ = './faster_rcnn_orpn_r50_fpn_3x_hrsc.py'
# model
model = dict(pretrained='torchvision://resnet101', backbone=dict(depth=101))并不能直接改,一个方法是,先运行上面的训练代码,等它开始显示loss以后,Ctrl+c停止,然后去生成的work_dirs文件夹下把faster_rcnn_orpn_r101_fpn_3x_hrsc.py文件复制到configs/obb/oriented_rcnn/文件夹下,这里建议重命名一下,不然系统的默认配置文件就被覆盖了,比如我把复制过来的py文件重命名为new_faster_rcnn_orpn_r101_fpn_3x_hrsc.py,然后打开它就可以看到全部的配置信息了,
evaluation = None
total_epochs = 36
checkpoint_config = dict(interval=1)
load_from = None
resume_from = None这里evaluation就是验证,checkpoint_config里的interval就表示每隔几个epoch保存一次权重, load_from是加载预训练权重,resume_from是接着之前的训练权重训练,如果用过mmdet的肯定都熟悉,方法是一样的。如果要改evaluation,可以参考我的这个,然后还要记得加入验证集的配置,因为原文件中只有train和test,我是直接复制了test的配置然后改名成val。
evaluation = dict(interval=1, metric=['mAP'])然后用我们改好的配置文件进行训练:
python tools/train.py configs/obb/oriented_rcnn/new_faster_rcnn_orpn_r101_fpn_3x_hrsc.py --work-dir work_dirs 3、部分效果展示
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 453/453, 17.7 task/s, elapsed: 26s, ETA: 0s2022-07-15 17:29:02,321 - mmdet - INFO -
+-------+------+------+--------+--------+
| class | gts | dets | recall | ap |
+-------+------+------+--------+--------+
| ship | 1188 | 3926 | 0.0455 | 0.0909 |
+-------+------+------+--------+--------+
| mAP | | | | 0.0909 |
+-------+------+------+--------+--------+
2022-07-15 17:29:02,322 - mmdet - INFO - Epoch(val) [1][453] mAP: 0.0909
2022-07-15 17:29:15,793 - mmdet - INFO - Epoch [2][50/309] lr: 3.581e-03, eta: 0:42:04, time: 0.269, data_time: 0.045, memory: 5348, loss_rpn_cls: 0.0354, loss_rpn_bbox: 0.0803, loss_cls: 0.0396, acc: 99.1094, loss_bbox: 0.0144, loss: 0.1696, grad_norm: 2.1386这是刚刚训练完一个epoch的验证结果 ,我没有改batch_size,默认为2,就已经占用了9g的显存,一共36个epoch,用时40多分钟,可以看到loss在降,就说明在收敛了。
最后测试一下最终结果:
先在voc07metric下测试一下:
python tools/test.py configs/obb/oriented_rcnn/faster_rcnn_orpn_r101_fpn_3x_hrsc.py work_dirs/epoch_36.pth --eval mAP[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 453/453, 17.4 task/s, elapsed: 26s, ETA: 0s
+-------+------+------+--------+--------+
| class | gts | dets | recall | ap |
+-------+------+------+--------+--------+
| ship | 1188 | 5058 | 0.9806 | 0.9048 |
+-------+------+------+--------+--------+
| mAP | | | | 0.9048 |
+-------+------+------+--------+--------+然后在voc12metric下测试一下:
python tools/test.py configs/obb/oriented_rcnn/faster_rcnn_orpn_r101_fpn_3x_hrsc.py work_dirs/epoch_36.pth --eval mAP --options use_07_metric=False[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 453/453, 17.3 task/s, elapsed: 26s, ETA: 0s
+-------+------+------+--------+--------+
| class | gts | dets | recall | ap |
+-------+------+------+--------+--------+
| ship | 1188 | 5058 | 0.9806 | 0.9732 |
+-------+------+------+--------+--------+
| mAP | | | | 0.9732 |
+-------+------+------+--------+--------+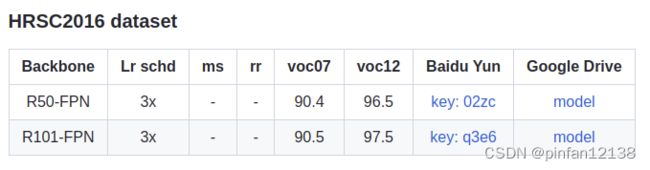
参考官方在HRSC2016上的结果,可以看到基本达到官方精度了,复现成功。
总结
成功复现了Oriented R-CNN,我曾尝试在Windows下复现,但bug太多了,还是老老实实投入Linux的怀抱,不然放着显卡不用太浪费了。不断去试哪个pytorch版本能成功也是心累,接下来就可以继续尝试别的obb的版本了。