目标追踪与定位学习笔记7-遮挡感知R-CNN:在人群中检测行人论文阅读
Occlusion-aware R-CNN:Detecting Pedestrians in a Crowd
遮挡感知R-CNN:在人群中检测行人
论文地址:arxiv
1. Overview
文章提出了新的遮挡感知算法来提高人群中的检测精度,具体而言设计一个新的aggregation loss去靠近并紧凑的定位到相对应对象。同时,使用一个新的汇集单元来代替RoI汇集层,以便将具有可见性预测的人体先验结构信息集成到网络中来处理遮挡。
此文章使用的数据集(CityPersons, ETH, INRIA)

AggLoss不仅强制建议靠近相对应的对象,而且最小化与相同对象相关联的建议内部区域距离。同时为了有效的处理部分遮挡,提出一种新的部分遮挡感兴趣的区域PORoI池单元来代替探测器第二阶段Fast R-CNN模块中的原始RoI池层,该单元将人体的先验结构信息与可见性预测集成到网络中。
算法思路:首先将行人区域划分为5个部分,通过自适应的边界框将每个部分的投影下的特征以及整个建议在特征图上的投影合并成固定长度的特征向量。然后利用学习后的子网络预测各部分的能见度得分,结合提取的特征进行行人检测。
行人检测研究历史:对所有位置和比例的子图像进行穷尽性操作的行人检测器 -> 用于人体检测的方向梯度(HOG)描述符和支持向量机(SVM)分类器的直方图 -> 有证明使用来自多个通道的特征可以显著提高性能 -> 通过适当的滤波器组,滤波后的信道特征可以达到最高的检测质量 -> 设计了一种建立在低层视觉特征和空间汇集基础上的新特征,并直接优化ROC曲线下的部分区域以获得更好的性能
2. 算法原理
遮挡感知R-CNN探测器是基于行人探测的自适应Fast R-CNN框架。具有aggregation loss和PORoI池化单元。
Fast R-CNN由两个模块组成,一个RPN(Region Proposal Network),一个Fast R-CNN模块。其中RPN模块用来生成高质量的region proposals,Fast R-CNN模块用于根据生成的建议对象的准确位置和大小进行分类和回归。
为了在第一个区域规划网络模块中有效的生成区域准确建议,本文设计聚焦损失项,以强制建议紧密且紧凑的位于ground-truth,定义为:
L r p n ( { p i } , { t i } , { p i ∗ } , { t i ∗ } ) = L c l s ( { p i } , { p i ∗ } ) + α ⋅ L a g g ( { p i ∗ } , { t i } , { t i ∗ } ) , \mathbb L_{rpn}(\{p_i\},\{t_i\},\{p^*_i\},\{t^*_i\})=\mathcal L_{cls}(\{p_i\},\{p^*_i\})+\alpha \cdot \mathcal L_{agg}(\{p^*_i\},\{t_i\},\{t^*_i\}), Lrpn({pi},{ti},{pi∗},{ti∗})=Lcls({pi},{pi∗})+α⋅Lagg({pi∗},{ti},{ti∗}),
i是mini-batch中的锚的索引, p i 和 t i p_i和t_i pi和ti是第i个锚的预测置信度, p i ∗ 和 t i ∗ p^*_i和t^*_i pi∗和ti∗是第i个锚的ground-truth类标签和坐标。 α \alpha α是平衡两个损失的超参数。 L c l s ( { p i } , { p i ∗ } ) \mathcal L_{cls}(\{p_i\},\{p^*_i\}) Lcls({pi},{pi∗})是分类损失, L a g g ( { p i ∗ } , { t i } , { t i ∗ } ) \mathcal L_{agg}(\{p^*_i\},\{t_i\},\{t^*_i\}) Lagg({pi∗},{ti},{ti∗})是聚集损失。使用对数损失来计算两个类之间的分类损失。行人的 p i ∗ = 1 p^*_i=1 pi∗=1背景的 p i ∗ = 0 p^*_i=0 pi∗=0。
L c l s ( { p i } , { p i ∗ } ) = 1 N c l s ∑ i − ( p i ∗ log p i + ( 1 − p i ∗ ) log ( 1 − p i ) ) \mathcal L_{cls} (\{p_i\},\{p^*_i\}) = \frac 1 {N_{cls}} \sum_i-(p^*_i \log p_i +(1-p^*_i) \log (1-p_i)) Lcls({pi},{pi∗})=Ncls1i∑−(pi∗logpi+(1−pi∗)log(1−pi))
N c l s N_{cls} Ncls是分类问题中锚的总数量。
2.1 Aggregation Loss
为了减少相邻重叠行人的错误检测,我们强制建议靠近并紧凑地定位到相应的ground-truth。我们为区域建议网络(RPN)和快速R-CNN算法中的快速R-CNN模块设计了一种新的聚集损失(AggLoss),这是一种多任务损失推动建议接近相应的真实值对象,同时最小化与相同对象相关联的建议的内部区域距离,即,
L a g g ( { p i ∗ } , { t i } , { t i ∗ } ) = L r e g ( { p i ∗ } , { t i } , { t i ∗ } ) + β ⋅ L c o m ( { p i ∗ } , { t i } , { t i ∗ } ) , ( 3 ) \mathcal L_{agg} (\{p^*_i\},\{t_i\},\{t^*_i\})=\mathcal L_{reg} (\{p^*_i\},\{t_i\},\{t^*_i\}) + \beta \cdot \mathcal L_{com} (\{p^*_i\},\{t_i\},\{t^*_i\}), ~~~~~(3) Lagg({pi∗},{ti},{ti∗})=Lreg({pi∗},{ti},{ti∗})+β⋅Lcom({pi∗},{ti},{ti∗}), (3)
L r e g ( { p i ∗ } , { t i } , { t i ∗ } ) \mathcal L_{reg} (\{p^*_i\},\{t_i\},\{t^*_i\}) Lreg({pi∗},{ti},{ti∗})是回归损失,要求每个建议接近指定的ground-truth, ⋅ L c o m ( { p i ∗ } , { t i } , { t i ∗ } ) \cdot \mathcal L_{com} (\{p^*_i\},\{t_i\},\{t^*_i\}) ⋅Lcom({pi∗},{ti},{ti∗})是紧急性损失(compactness),强制建议紧挨着制订的基本事实对象。
类似于Fast R-CNN,使用平滑L1损失作为回归损失 L r e g ( { p i ∗ } , { t i } , { t i ∗ } ) \mathcal L_{reg} (\{p^*_i\},\{t_i\},\{t^*_i\}) Lreg({pi∗},{ti},{ti∗})来度量边界框的精度。
L r e g ( { p i ∗ } , { t i } , { t i ∗ } ) = 1 N r e g ∑ i p i ∗ Δ ( t i − t i ∗ ) \mathcal L_{reg}(\{p^*_i\},\{t_i\},\{t^*_i\})=\frac 1 {N_{reg}}\sum_i p^*_i \Delta(t_i - t^*_i) Lreg({pi∗},{ti},{ti∗})=Nreg1i∑pi∗Δ(ti−ti∗)
N r e g N_{reg} Nreg是回归阶段锚的总数, Δ ( t i − t i ∗ ) \Delta (t_i - t^*_i) Δ(ti−ti∗)是预测边界框 t i t_i ti的平滑L1损失。
3中的后半部分是考虑相同基本事实对象相关的建议的吸引力。通过这种方式可以提出在ground-truth周围的紧密定位的建议,以减少相邻重叠对象的错误检测。具体而言,将 { t ~ 1 ∗ , ⋅ ⋅ ⋅ , t ~ ρ ∗ } \{\tilde t^*_1,\cdot\cdot\cdot,\tilde t^*_{\rho}\} {t~1∗,⋅⋅⋅,t~ρ∗}设置为与一个以上锚相关联的ground-truth集合。并将 { φ ~ 1 ∗ , ⋅ ⋅ ⋅ , φ ~ ρ ∗ } \{\tilde \varphi^*_1,\cdot\cdot\cdot,\tilde \varphi^*_{\rho}\} {φ~1∗,⋅⋅⋅,φ~ρ∗}设置为与ground-truth相对应的相关锚的索引集,真实值 t ~ k ∗ \tilde t^*_k t~k∗和锚的索引值 ϕ k \phi_k ϕk结合起来,其中 ρ \rho ρ是与一个以上锚相关联的真实对象的总数。因此,对于 t ~ k ∗ ∈ { t ~ i ∗ } \tilde t^*_k \in \{\tilde t^*_i\} t~k∗∈{t~i∗}和 Φ i ∩ Φ j = ∅ \Phi_i \cap \Phi_j = \empty Φi∩Φj=∅,我们用L1损失来度量由 { Φ 1 , ⋅ ⋅ ⋅ , Φ ρ } \{\Phi_1,\cdot\cdot\cdot,\Phi_{\rho}\} {Φ1,⋅⋅⋅,Φρ}中的每个集合索引的锚的平均预测和对应真实值之间的不同,描述了预测的边界框相对于真实值对象的紧凑性:
L c o m ( { p i ∗ } , { t i } , { t i ∗ } ) = 1 N c o m ∑ i = 1 ρ Δ ( t ~ i ∗ − 1 ∣ Φ i ∣ ∑ j ∈ Φ 1 t j ) \mathcal L_{com} (\{p^*_i\},\{t_i\},\{t^*_i\})= \frac 1 {N_{com}} \sum^{\rho}_{i=1} \Delta(\tilde t^*_i- \frac 1 {|\Phi_i|}\sum_{j \in \Phi_1}t_j) Lcom({pi∗},{ti},{ti∗})=Ncom1i=1∑ρΔ(t~i∗−∣Φi∣1j∈Φ1∑tj)
N c o m N_{com} Ncom是多于一个锚结合的真实值的总数, ∣ Φ i ∣ {|\Phi_i|} ∣Φi∣是第i个真实值所连接的锚的数目。
2.2 零件遮挡感知RoI汇集单元
基于零件的模型在处理遮挡行人时时有效的。本文设计了一个新的零件遮挡感知RoI池化单元,将人体的先验结构信息与可见性预测集成到检测器的Fast R-CNN模块中,该模块组装了一个微神经网络来估计部件的遮挡状态。
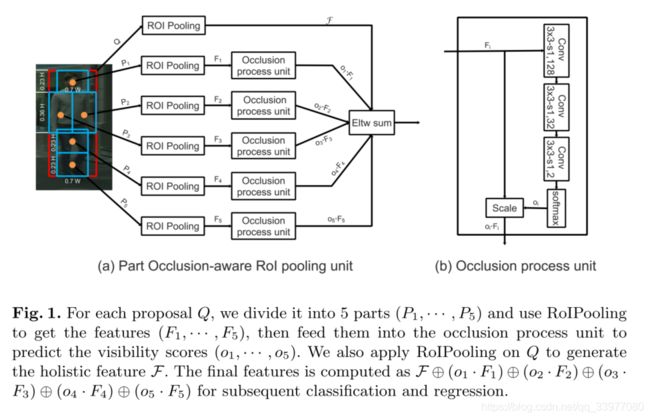
我们将每个单元分成5个部分,使用RoI池化来获得相对应的特征 ( F 1 , ⋅ ⋅ ⋅ , F 5 ) (F_1,\cdot\cdot\cdot,F_5) (F1,⋅⋅⋅,F5),然后将其喂入遮挡处理单元来预测可见性分数 ( o 1 , ⋅ ⋅ ⋅ , o 5 ) (o_1,\cdot\cdot\cdot,o_5) (o1,⋅⋅⋅,o5),我们还对Q应用RoI池化来生成整体特征 F \mathcal F F,最后特征被计算为 F ⊕ ( o 1 ⋅ F 1 ) ⊕ ( o 2 ⋅ F 2 ) ⊕ ( o 3 ⋅ F 3 ) ⊕ ( o 4 ⋅ F 4 ) ⊕ ( o 5 ⋅ F 5 ) \mathcal F \oplus (o_1\cdot \mathcal F_1) \oplus (o_2 \cdot \mathcal F_2) \oplus (o_3 \cdot \mathcal F_3) \oplus (o_4 \cdot \mathcal F_4) \oplus (o_5 \cdot \mathcal F_5) F⊕(o1⋅F1)⊕(o2⋅F2)⊕(o3⋅F3)⊕(o4⋅F4)⊕(o5⋅F5),随后用于回归和分类。
遮挡处理单元:根据合并特征来预测相应部分的可见性得分。具体而言遮挡处理单元由三个卷积层和一个在训练中具有对数损失的softmax layer构成。 c i , j c_{i,j} ci,j代表第i个方案的第j个部分, o i , j ∗ o^*_{i,j} oi,j∗代表可见的真实值得分,如果半部分 c i , j c_{i,j} ci,j可见,则 o i , j ∗ = 1 o^*_{i,j}=1 oi,j∗=1,否则, o i , j ∗ = 0 o^*_{i,j}=0 oi,j∗=0。定义 c i , j c_{i,j} ci,j和真实目标的可见区域除以 c i , j c_{i,j} ci,j的面积超过阈值,则 o i , j ∗ = 1 o^*_{i,j}=1 oi,j∗=1,
o i , j ∗ = { 1 Ω ( U ( c i , j ) ∩ V ( t i ∗ ) ) Ω ( U ( c i , j ) ) > ρ , 0 Ω ( U ( c i , j ) ∩ V ( t i ∗ ) ) Ω ( U ( c i , j ) ) ≤ ρ , o^*_{i,j}= \begin{cases} 1 ~~~ \frac {\Omega(U(c_{i,j})\cap V(t^*_i))} {\Omega (U(c_{i,j}))} \gt \rho, \\ 0 ~~~ \frac {\Omega(U(c_{i,j})\cap V(t^*_i))} {\Omega (U(c_{i,j}))} \leq \rho, \end{cases} oi,j∗={1 Ω(U(ci,j))Ω(U(ci,j)∩V(ti∗))>ρ,0 Ω(U(ci,j))Ω(U(ci,j)∩V(ti∗))≤ρ,
其中 Ω ( ⋅ ) \Omega(\cdot) Ω(⋅)是计算面积的函数, U ( c i , j ) U(c_{i,j}) U(ci,j)是 c i , j c_{i,j} ci,j的区域, V ( t ~ i ∗ ) V(\tilde t^*_i) V(t~i∗)是真实值对象的可见区域, ∩ \cap ∩是两个区域的交集运算,遮挡处理单元的损失函数可以这样计算:
L o c c ( { t i } , { t i ∗ } ) = ∑ j = 1 5 − ( o i , j ∗ log o i , j + ( 1 − o i , j ∗ ) log ( 1 − o i , j ) ) \mathcal L_{occ}(\{t_i\},\{t^*_i\}) = \sum ^5_{j=1} - (o^*_{i,j}\log o_{i,j}+(1-o^*_{i,j})\log(1-o_{i,j})) Locc({ti},{ti∗})=j=1∑5−(oi,j∗logoi,j+(1−oi,j∗)log(1−oi,j))
在此之后,应用逐元素乘法符将每个部分的合并特征与相应的预测可见性分数相乘,生成512*7*7的最终特征,逐元素求和操作被进一步用于组合五个部分的提取特征和用于R-CNN模块的分类和回归整个proposal。
为了进一步提高回归准确率,我们用在Fast R-CNN模块中使用AggLoss:
L f r c ( { p i } , { t i } , { p i ∗ } , { t i ∗ } ) = L c l s ( { p i } , { p i ∗ } ) + α ⋅ L a g g ( { p i ∗ } , { t i } , { t i ∗ } ) + λ ⋅ L o c c ( { t i } , { t i ∗ } ) , \mathbb L_{frc}(\{p_i\},\{t_i\},\{p^*_i\},\{t^*_i\})=\mathcal L_{cls}(\{p_i\},\{p^*_i\})+\alpha \cdot \mathcal L_{agg}(\{p^*_i\},\{t_i\},\{t^*_i\})\\ +\lambda \cdot \mathcal L_{occ}(\{t_i\},\{t^*_i\}), Lfrc({pi},{ti},{pi∗},{ti∗})=Lcls({pi},{pi∗})+α⋅Lagg({pi∗},{ti},{ti∗})+λ⋅Locc({ti},{ti∗}),
其中, α \alpha α和 λ \lambda λ用于平衡三个损失项, L c l s ( { p i } , { p i ∗ } ) \mathcal L_{cls}(\{p_i\},\{p^*_i\}) Lcls({pi},{pi∗})和 L a g g ( { p i ∗ } , { t i } , { t i ∗ } ) \mathcal L_{agg}(\{p^*_i\},\{t_i\},\{t^*_i\}) Lagg({pi∗},{ti},{ti∗})是分类和聚集损失,定义与RPN相同, L o c c ( { t i } , { t i ∗ } ) \mathcal L_{occ}(\{t_i\},\{t^*_i\}) Locc({ti},{ti∗})是遮挡模块的损失。
3. 实验
3.1 实验设置
本文提出的OR-CNN是基于Fast R-CNN框架使用VGG-16作为主干网络,在ILSVRC CLSLOC数据集上预训练,对高度小于100像素的锚盒进行二次密集来提高小规模行人的检测精度,使用相应的匹配策略将锚和真实值相关联。
在新加的卷积层的所有参数都是使用xavier方法随机初始化的。使用动量为0.9,衰减率为0.0005的随机梯度下降算法优化OR-CNN,硬件设施 2 TitanX GPU。
CityPerson数据集:前40k个迭代学习率 1 0 − 3 10^{-3} 10−3,后20k个迭代的学习率为 1 0 − 4 10^{-4} 10−4。
Caltech-USA数据集:前120k个迭代学习率为 1 0 − 3 10^{-3} 10−3,在前80k个迭代后将学习率减少10倍。超参数 α , β , λ \alpha,\beta,\lambda α,β,λ均设置为1。
3.2 CityPerson数据集
数据集有5000张图片(2975,500,1525),带有35000个手动注释的人加上13000个忽略区域注释。边界框和行人的可见部分都被提供,并且每张图片上平均大约有7个行人。Heavy代表大于35%的遮挡,partial代表在10%-35%的遮挡,bare代表小于10%的遮挡。
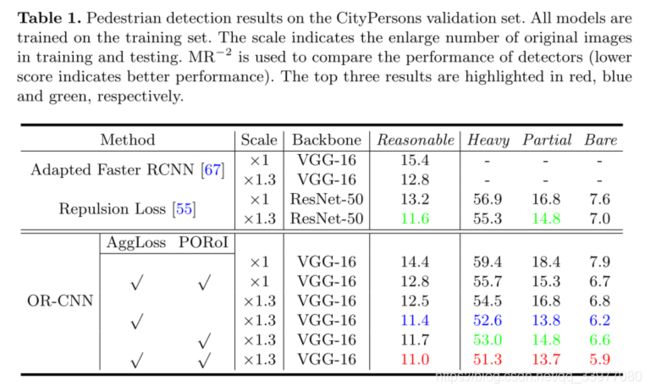
比例尺代表训练和测试中原始图像的放大数量, M R − 2 MR^{-2} MR−2用于比较检测器的性能(分数越低性能越好)。
在每幅图像的假正例范围内的平均对数损失率用来衡量检测性能(分数越低表示性能越好)。在实验中,验证集中的 M R − 2 MR^{-2} MR−2设置为12.5,比例尺设置为1.3可以获得最佳的结果。
OR-CNN-A用来证明聚集损失的有效性,使用聚集损失代替基础基线检测器中的原始回归损失,并进行评估。此方法可以将 M R − 2 MR^{-2} MR−2降低1.1%(12.5-11.4)。聚集损失比Repulsion更能有效地检测到人群中的行人。
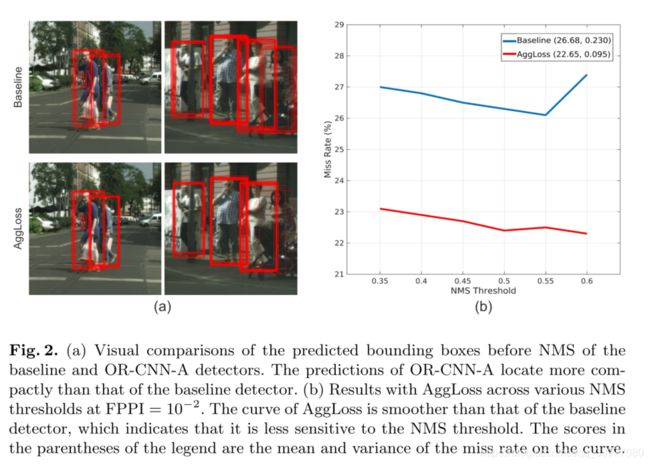
如左图所示,OR-CNN-A探测器的预测比基础探测器框更简洁,位于两个相邻真实值之间的预测比基线探测器少。这一现象表明,聚集损失可以将预测紧凑地放在真实值物体上,使检测器对NMS阈值不太敏感,在人群场景中具有更好的性能。右图表示FPPI=0.01时NMS阈值下的增益损耗结果,高阈值容易产生更多的假正例,低NMS容易产生更多的假反例。OR-CNN-A比基线更加平滑,方差也较小。
因为NMS操作在OR-CNN-A预测中过滤了比基线更多的假正例,所以这种方法总能产生较低的漏检率,这意味着OR-CNN-A的预测边界框比基线方法更紧凑地定位。
PORoI的消融研究:构建OR-CNN-P来验证PORoI的有效性,使用PoRoI汇集单元而不是基线中的RoI汇集层,并在数据集上进行评估。参数和上述一样,在相应的数据集上进行训练和测试。
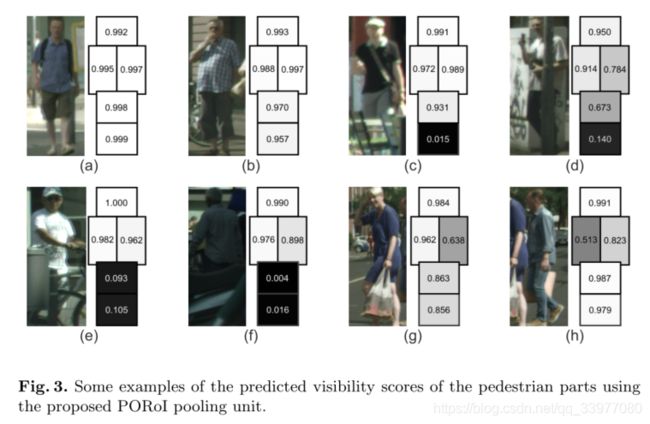
若行人没有遮挡,则行人各部分的可见度得分接近1,若行人的某些部位被背景障碍物或其他行人遮挡,则相应部位的分值会降低,比如图3©-(f)中被遮挡的大腿和小腿。如果两个行人相互遮挡,PORoI也可以成功检测到遮挡的人体部分,这有助于降低遮挡部分在行人检测中的贡献。如果我们将每个部分的可见性分数固定为1,而不是使用遮挡处理单元的预测,OR-CNN检测器的检测精度无法提高。因此遮挡处理单元是检测精度的关键组件,使我们的PORoI池单元能够检测行人的遮挡部分,这有助于提取有效的检测特征。
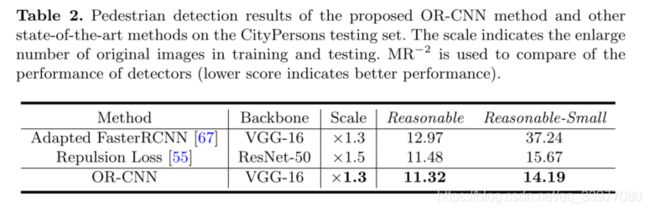
第二好的探测器Repulsion排斥损失使用更大的输入图像×1.5scale并且使用更强大的网络
3.3 Caltech-USA Dataset
数据集的训练集和测试集分别有42782帧和4024帧,在 1 0 − 2 到 1 0 0 10^{-2}到10^0 10−2到100范围内选9个点,取其对数平均失效率来评估探测器的性能。合理子集遮挡率小于35%仅包括至少50像素高的行人,这被广泛应用于评估行人探测器。

3.4 ETH Dataset

OR-CNN和RFN+BF方法:在ETH数据集上的实验结果不仅验证了该方法在行人检测中的优越性,也验证了其对其他场景的泛化能力。
3.5 INRIA Dataset
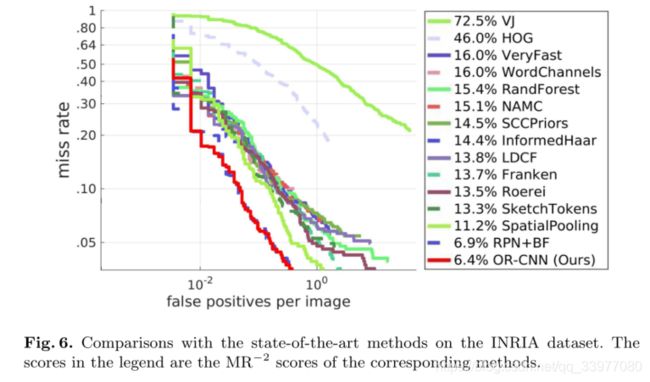
数据集包括主要从假日照片中收集的高分辨率行人图像,有2120张(1832+288)图片组成。训练集中有614张正样例和1218张负样例。
4. 结论
本文贡献:
- 设计新的聚焦损失来减少相邻重叠行人的错误检测,同时强烈建议靠近相关对象,并能紧凑地定位。
- 提出RoI池化单元代替检测器的Fast R-CNN模块中的RoI层,有效处理部分遮挡。将人体的先验结构信息与可见性预测集成到网络中来处理遮挡。
论文可改进的地方:
- 重新设计PORoI池化单元,联合估计网络中对象部分的位置大小和遮挡状态。不使用经验比率。
- 可以用于检测其他物体,提高模型的泛化性。