论文阅读-ID-Reveal: Identity-aware DeepFake Video Detection
ID-Reveal
一、论文信息:
- 题目:ID-Reveal: Identity-aware DeepFake Video Detection
- 作者团队:

- 会议:ICCV2021
二、目的
这篇文章从一个新的角度出发,不同于以往的直接对单个视频进行检测,而是更贴合实际。例如:当一个名人需要来证实一段视频是deepfake自己的脸,只需要她提供自己真实的一段视频来与需要鉴定的视频进行比较即可判定出来。比较符合当前的现实需求。
三、Motivation
当前的deepfake检测技术很多在面部重建操作上的检测效果不太好,所以作者为了克服这种问题,做出了以下的推断:人面部信息包含了视觉身份和生物特征两部分,并且两者特征之间有关联。但是篡改过的视频会改变两者之间的关联性,与此同时,deepfake中的面部重建方法是会保留身份信息,破坏生物特征的运动。
人脸再现:改变面部表情,保持身份;人脸交换:修改了一个人的身份,保留了面部表情。
四、网络结构
论文提出了一种新的方法,通过度量学习和对抗性策略来学习时间层面上的面部特征。
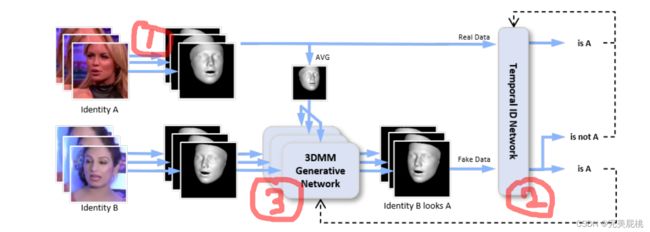
该网络主要由三个结构组成:(1)特征提取;(2)时序ID网络;(3)3DMM生成网络。
1)特征提取:输入的是视频,对视频中的每一帧提取出面部特征。然后通过一个3D形态模型来将每个脸映射成一个低维表示(也就是图中显示的人脸形态图)。该表示中包含了关于脸部形状,表情,外貌等信息。下一步是从该低维表示中取回人脸的这些信息参数,将这些信息再次映射成一个62个参数的向量。
![]()
在帧t处提取的个体c的视频i的3DMM特征。
时序ID网络:该网络的作用是比较输入的特征之间的相似度,同时也作为一个判别器来与接下来介绍的3DMM生成网络进行对抗学习。流程是:将传入该部分的两个特征向量进行特征映射然后来比较两者之间的相似度,将该相似度与标签对比,如果判定错误则更新3DMM生成网络的参数来使得其生成更能分辨真假之间关键信息的特征。
![]()
时序ID网络Nt通过沿时间方向工作的卷积层来将传入该部分的特征向量进行特征映射

为评估嵌入向量的距离,使用欧几里得距离计算相似性(真假数据的相似性)

类似于基于距离的逻辑损失,在适当的定义的概率上采用对数损失,即对每个嵌入的向量Yc,i(t)通过softmax建立概率。(与同一个人至少有一个相似之处比其他个体的相似之处大得多)
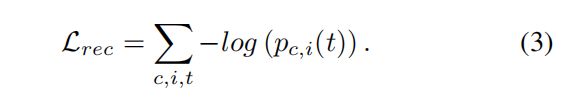
度量学习损失函数为负对数(交叉熵)损失函数
3DMM生成网络:该网络的作用是生成类似于经过deepfake篡改过的视频,如图上所示:将身份A的面部五官等放到身份B的面部背景上面,也就是与个人视觉身份一致但生物特征不一致的信息。对于每个身份c,计算平均3DMM特征向量Xc,基于这个平均的输入特征和个体i 的视频帧的特征,使用生成器Ng去生成合成的3DMM特征。一般被使用两次,将个体i变为身份c并将变为3DMM特征,之后将生成的3DMM特征再重新变换为i.
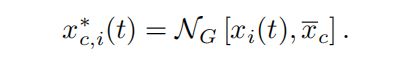

3DMM生成网络的损失函数,由对抗学习的损失和循环的损失组成。

对抗学习损失基于时序ID网络,它试图通过生成与特定身份一致的特征来欺骗时序ID网络,但生成器一帧一帧工作,它可以通过只改变个体的外观而不改变时间模式来欺骗时序ID网络。

生成的特征与真实之间的相似性

生成器旨在增加相似性,而时序ID网络训练阻碍发生器

对抗训练的最终目标是提高时序ID网络区分真实身份与虚假身份的能力。
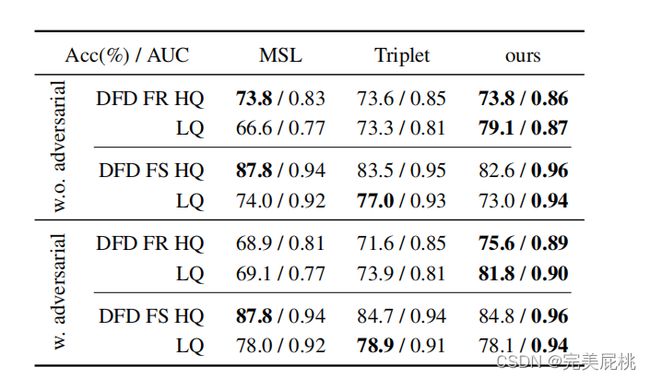
五、实验结果
数据集
该论文选择的数据集跟平常的检测deepfake的数据集不一样,选择的是VoxCeleb2数据集,将其中的5120个视频作为训练集,512个作为验证集。每个batch包括64个96帧的视频,其中的64个视频又分别是8个人的8段视频。



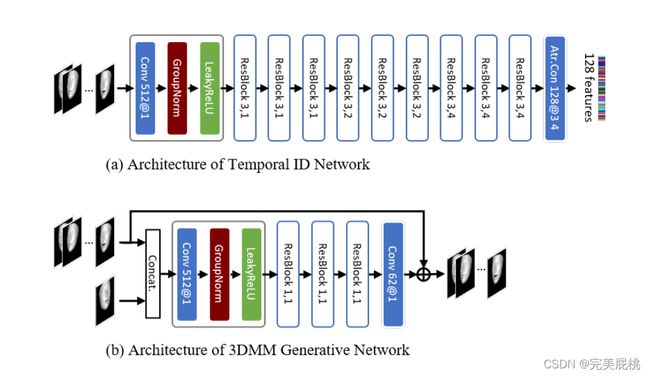
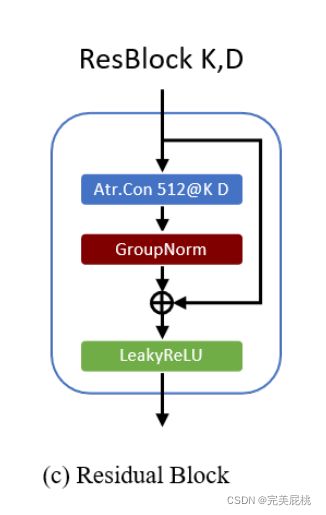
时序ID网络:利用卷积神经网络架构,该架构沿时间方向工作,由11层组成,除了最后一层,我们用GroupNorm和LeakyReLU非线性,为了不增加可训练参数的情况下增加了接收场,我们使用a-trous卷积(扩张卷积)来代替经典卷积,第一层将通道数从62扩张到512,后边几层受ResNet架构启发,包含了图上的残差块。残差块的参数K和D分别是滤波器的维数和a-trous卷积的膨胀因子,最后一层再将通道从512减少到128,整个网络感受野等于51帧,大约2秒。
3DMM生成网络:由两个3DMM特征向量提供,这两个特征向量被连接起来,导致了124个通道的单输入向量,这个网络由5层组成,一层将信道从124增加到512,三个残差块,最后一层将信道从512减少到62。将输出与输入的3DMM特征向量相加,以获得生成的3DMM特征向量,为了逐帧工作,所有卷积滤波器维数都等于1.
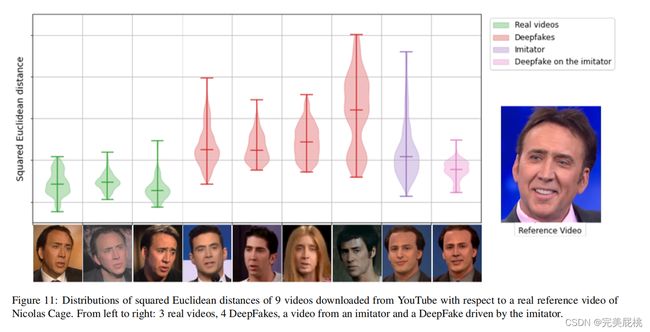 9个视频相对于真实视频的平方欧几里得距离的分布,左3为真,中间4个为deepfakes,倒数第二个是模仿者视频,最后一个是模仿者视频的deepfakes.
9个视频相对于真实视频的平方欧几里得距离的分布,左3为真,中间4个为deepfakes,倒数第二个是模仿者视频,最后一个是模仿者视频的deepfakes.