开放集域适应文献阅读四
Attract or Distract: Exploit the Margin of Open Set
- 1 问题与挑战
- 2 本文贡献
- 3 方法
-
- 3.1 总体架构
- 3.2 对抗域适应(ADA)
- 3.3 语义类别对齐(SCA)
- 3.4 语义对比映射(SCM)
- 3.5 目标
- 4 小结
- 参考文献
1 问题与挑战
开集域适应,旨在在没有目标域标签的情况下同时处理域移动和未知对象的识别。目标域存在未知类,未知样本的存在阻碍了跨域的对齐,同时,跨域的类间不对齐也使得区分未知样本变得更加困难。
2 本文贡献
- 提出使用 semantic categorical alignment (SCA 语义类别对齐)来实现目标已知类的良好可分性。
- 并使用 semantic contrastive mapping (SCM 语义对比映射)来将未知类推离决策边界。
本文方法致力于通过增强表示的区分性,将目标域中的相似样本与源域对齐,同时将未知样本推离所有已知类来解决开放集域自适应问题。
图示如下
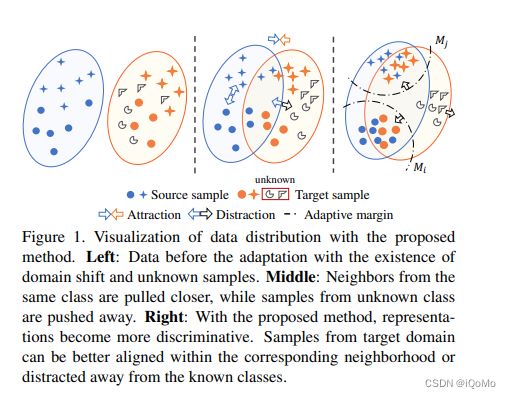
3 方法
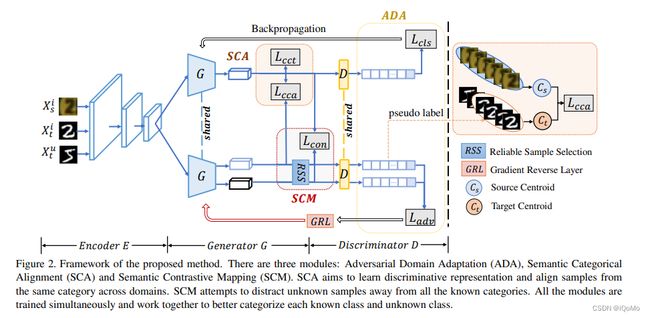
3.1 总体架构
设计以下模块:
1)对抗性领域适应(ADA)。基于交叉熵损失,ADA 旨在最初将目标中的样本与源已知样本对齐,或将其分类为未知样本。
2)语义类别对齐(SCA)。本模块由两部分组成。首先,基于对比中心损失,旨在压缩来自同一类的样本的表示。第二,基于跨域的中心损失,尝试调整源和目标之间同一类的分布。
3)语义对比映射(SCM)。在对比损失的情况下,SCM 旨在鼓励目标中的已知样本向源中相应的质心移动。同时,它还试图使未知样本远离所有已知类。
总体框架如图2所示
3.2 对抗域适应(ADA)
这部分和 OSBP 一样。
符号表示:Source domain { X s , Y s } \left\{X_s,Y_s\right\} {Xs,Ys},Target domain { X t } \left\{X_t\right\} {Xt}.
我们利用对抗性训练方法,将目标中的样本与源域已知样本进行初始对齐,或将其作为未知样本拒绝。具体地,鉴别器 D 被训练以分离源域和目标域。然而,特征生成器 G 试图最小化源和目标之间的差异。当专家 D 无法确定样本来自哪个域时,G学习域不变表示。
将交叉熵损失与softmax函数一起用于已知源样本分类:
L c l s ( x s , y s ) = − log ( p ( y = y s ∣ x s ) ) = − log ( D ∘ G ( x s ) ) y s ) \begin{aligned} \mathcal{L}_{c l s}\left(x_s, y_s\right) &=-\log \left(p\left(y=y_s \mid \boldsymbol{x}_s\right)\right) \\ &\left.=-\log \left(D \circ G\left(\boldsymbol{x}_s\right)\right)_{y_s}\right) \end{aligned} Lcls(xs,ys)=−log(p(y=ys∣xs))=−log(D∘G(xs))ys)
为了尝试为未知样本创建边界,我们利用了二进制交叉熵损失:
L a d v ( x t ) = − 1 2 log ( p ( y = N + 1 ∣ x t ) ) − 1 2 log ( 1 − p ( y = N + 1 ∣ x t ) ) \begin{aligned} \mathcal{L}_{a d v}\left(\boldsymbol{x}_t\right)=&-\frac{1}{2} \log \left(p\left(y=N+1 \mid \boldsymbol{x}_t\right)\right) \\ &-\frac{1}{2} \log \left(1-p\left(y=N+1 \mid \boldsymbol{x}_t\right)\right) \end{aligned} Ladv(xt)=−21log(p(y=N+1∣xt))−21log(1−p(y=N+1∣xt))
ADA模块的目标可以表述为:
L A D A = min G ( L c l s ( x s , y s ) − L a d v ( x t ) ) + min D ( L c l s ( x s , y s ) + L a d v ( x t ) ) \begin{aligned} \mathcal{L}_{A D A}=& \min _G\left(\mathcal{L}_{c l s}\left(\boldsymbol{x}_s, y_s\right)-\mathcal{L}_{a d v}\left(\boldsymbol{x}_t\right)\right)+\\ & \min _D\left(\mathcal{L}_{c l s}\left(\boldsymbol{x}_s, y_s\right)+\mathcal{L}_{a d v}\left(\boldsymbol{x}_t\right)\right) \end{aligned} LADA=Gmin(Lcls(xs,ys)−Ladv(xt))+Dmin(Lcls(xs,ys)+Ladv(xt))
ADA 模块最初只将目标域中的样本与源已知样本对齐,并学习已知和未知之间的粗略边界。
3.3 语义类别对齐(SCA)
引入语义类别对齐(SCA),旨在压缩已知类的表示,并将每个已知类与其他类区分开来。SCA有两个步骤。首先,采用对比中心损失来增强源样本的一般特征的辨别性。其次,来自目标的已知类的每个质心将与源域中相应的类质心对齐。通过这种方式,源样本的表示将最终变得更具辨别力,同时,已知的目标质心将更精确地对齐。
1)为了压缩特征空间中属于同一类的源样本,将以下对比中心损失应用于源样本:
L c c t = 1 2 ∑ i = 1 m ∥ x s i − c s y s i ∥ 2 2 ( ∑ j = 1 , j ≠ y s i N ∥ x s i − c s j ∥ 2 2 ) + δ \mathcal{L}_{c c t}=\frac{1}{2} \sum_{i=1}^m \frac{\left\|x_s^i-c_s^{y_s^i}\right\|_2^2}{\left(\sum_{j=1, j \neq y_s^i}^N\left\|x_s^i-c_s^j\right\|_2^2\right)+\delta} Lcct=21i=1∑m(∑j=1,j=ysiN∥∥∥xsi−csj∥∥∥22)+δ∥∥∥xsi−csysi∥∥∥22
其中, m m m 表示训练过程中小批量中的样本数量, x s i x_s^i xsi 表示来自源域的第 i i i 个训练样本。 c s y s i c_s^{y_s^i} csysi 表示源域中 y s i y_s^i ysi 类的质心。 δ \delta δ 是用于预放空零分母的常数。
2)来自目标的已知类的每个中心将与源域中相应的类的中心对齐。
由于每个小 batch 有随机性、偏移性,所以使用全局中心来代替局部中心,而全局中心又是从每次局部中心的迭代中更新生成的。
全局中心的初始化:
c ( 0 ) k = 1 n k ∑ j = 0 n k G ( x i k ) c_{(0)}^k=\frac{1}{n^k} \sum_{j=0}^{n^k} G\left(x_i^k\right) c(0)k=nk1j=0∑nkG(xik)
在源域数据上使用预训练的模型进行训练,对于目标样本,使用预测结果作为伪标签。在每次迭代计算一次局部中心(所有样本的平均值),并对源域以及目标域的中心进行加权更新:
ρ s = ρ ( a s ( I ) k , c s ( I − 1 ) k ) c s ( I ) k ← ρ s a s ( I ) k + ( 1 − ρ s ) c s ( I − 1 ) k ρ t = ρ ( a t ( I ) k , c s ( I − 1 ) k ) c t ( I ) k ← ρ t a t ( I ) k + ( 1 − ρ t ) c t ( I − 1 ) k \begin{aligned} \rho_s &=\rho\left(a_{s(I)}^k, c_{s(I-1)}^k\right) \\ c_{s(I)}^k & \leftarrow \rho_s a_{s(I)}^k+\left(1-\rho_s\right) c_{s(I-1)}^k \\ \rho_t &=\rho\left(a_{t(I)}^k, c_{s(I-1)}^k\right) \\ c_{t(I)}^k & \leftarrow \rho_t a_{t(I)}^k+\left(1-\rho_t\right) c_{t(I-1)}^k \end{aligned} ρscs(I)kρtct(I)k=ρ(as(I)k,cs(I−1)k)←ρsas(I)k+(1−ρs)cs(I−1)k=ρ(at(I)k,cs(I−1)k)←ρtat(I)k+(1−ρt)ct(I−1)k
其中, ρ ( x i , x j ) = ( x i ⋅ x j ∥ x i ∥ × ∥ x j ∥ + 1 ) / 2 \rho\left(x_i, x_j\right)=\left(\frac{x_i \cdot x_j}{\left\|x_i\right\| \times\left\|x_j\right\|}+1\right) / 2 ρ(xi,xj)=(∥xi∥×∥xj∥xi⋅xj+1)/2。
最后,分类中心对齐损失公式如下:
L c c a = ∑ k = 1 N dist ( c s ( I ) k , c t ( I ) k ) \mathcal{L}_{c c a}=\sum_{k=1}^N \operatorname{dist}\left(c_{s(I)}^k, c_{t(I)}^k\right) Lcca=k=1∑Ndist(cs(I)k,ct(I)k)
3.4 语义对比映射(SCM)
对于目标域中的非质心样本,使用对比损失函数来鼓励已知样本靠近其质心,并强制未知样本远离已知类的所有质心。通过这种方式,可以在目标域中对齐非质心样本。此过程称为语义对比映射(SCM)。
由于目标样本的伪标签不正确,选择分类概率超过阈值的可靠样本。在本文方法中,将阈值设置为 1 / ( N + 1 ) 1/(N+1) 1/(N+1)。SCM 旨在减小可靠已知样本与其质心之间的距离,同时扩大可靠未知样本与所有质心之间的间距。
L con ( x t ; G ) = ( 1 − z ) D k ( x t k , c s k ) − z N ∑ k = 1 N D u ( x t k , c s k ) \mathcal{L}_{\text {con }}\left(x_t ; G\right)=(1-z) \mathcal{D}_k\left(x_t^k, c_s^k\right)-\frac{z}{N} \sum_{k=1}^N \mathcal{D}_u\left(x_t^k, c_s^k\right) Lcon (xt;G)=(1−z)Dk(xtk,csk)−Nzk=1∑NDu(xtk,csk)
其中, z z z 是已知类的时候值为0,而为未知类的时候值为1, D k D_k Dk 表示目标域已知类与对应源域类别的距离, D u D_u Du 表示目标域未知类与对应源域所有类别的距离。
D k ( x t k , c s k ) = ( 1 − ρ ) ω dist ( x t k , c s k ) 2 D u ( x t N + 1 , c s k ) = − ρ ω ( max { 0 , M k − dist ( x t N + 1 , c s k ) } ) 2 \begin{gathered} \mathcal{D}_k\left(x_t^k, c_s^k\right)=(1-\rho)^\omega \operatorname{dist}\left(x_t^k, c_s^k\right)^2 \\ \mathcal{D}_u\left(x_t^{N+1}, c_s^k\right)=-\rho^\omega\left(\max \left\{0, M^k-\operatorname{dist}\left(x_t^{N+1}, c_s^k\right)\right\}\right)^2 \end{gathered} Dk(xtk,csk)=(1−ρ)ωdist(xtk,csk)2Du(xtN+1,csk)=−ρω(max{0,Mk−dist(xtN+1,csk)})2
其中 ρ ρ ρ 表示余弦相似性。为了确保有效和准确地测量距离,我们还使用超参数 ω ω ω 来重新计算损失中计算的距离。 M k M^k Mk 是用于测量类 k k k 的邻域半径的分类自适应余量
M k = 1 N ∑ j = 1 , j ≠ k N dist ( c t j , c s k ) M^k=\frac{1}{N} \sum_{j=1, j \neq k}^N \operatorname{dist}\left(c_t^j, c_s^k\right) Mk=N1j=1,j=k∑Ndist(ctj,csk)
3.5 目标
final objective:
L total = L A D A + L S C A + L S C M = L c l s + L a d v + λ s L c c t + λ c L c c a + λ t L c o n . \begin{aligned} \mathcal{L}_{\text {total }} &=\mathcal{L}_{A D A}+\mathcal{L}_{S C A}+\mathcal{L}_{S C M} \\ &=\mathcal{L}_{c l s}+\mathcal{L}_{a d v}+\lambda_s \mathcal{L}_{c c t}+\lambda_c \mathcal{L}_{c c a}+\lambda_t \mathcal{L}_{c o n} . \end{aligned} Ltotal =LADA+LSCA+LSCM=Lcls+Ladv+λsLcct+λcLcca+λtLcon.
在每次迭代中,网络同时更新类质心和网络参数。

4 小结
预训练对抗网络中的生成器与鉴别器,先通过 ADA 初步进行源域各个类别的区分、目标域与源域相应类别的中心对齐、并初步形成目标域中已知样本与未知样本的边界。
通过 SCA 使每个已知类更加集中,源和目标之间的对齐更加准确,拉近已知类内部的表示,而加大各个已知类之间的区分。
使用 SCM 对于目标域中的非中心样本,鼓励已知样本向其中心靠近,并强制未知样本远离所有已知类的中心。
参考文献
[1] Q. Feng, G. Kang, H. Fan and Y. Yang, “Attract or Distract: Exploit the Margin of Open Set,” 2019 IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 7989-7998, doi: 10.1109/ICCV.2019.00808.
[2] https://zhuanlan.zhihu.com/p/363456100