DataWhale组队学习-Task01:Paddle开发深度学习模型快速入门
Trick
1. Series数据处理-map
不论是利用字典还是函数进行映射,Series.map()方法都是把对应的数据逐个当作参数传入到字典或函数中,得到映射后的值。
#①使用字典进行映射
data["gender"] = data["gender"].map({"男":1, "女":0})
#②使用函数
def gender_map(x):
gender = 1 if x == "男" else 0
return gender
#注意这里传入的是函数名,不带括号
data["gender"] = data["gender"].map(gender_map)2. pd.DataFrame.reset_index(drop=False)
重置索引,获得新的index。原来的index变成数据列,保留下来;不想保留原来的index,使用参数 drop=True。
一、定义DataSet
1. 数据原始形式
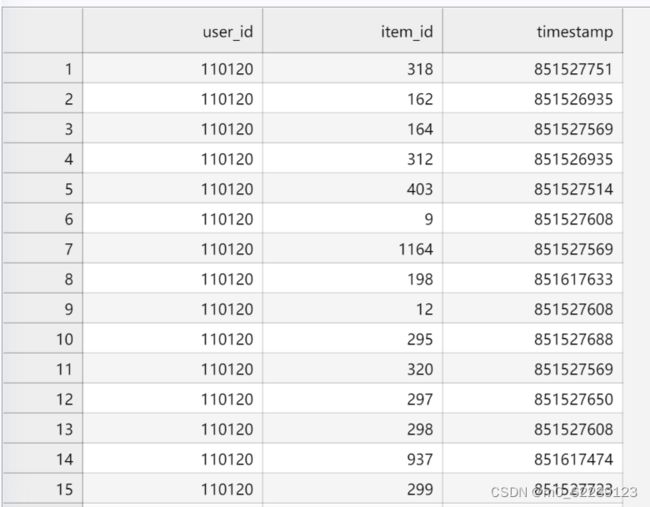
2. 数据编码方式
#Dataset构造
class BaseDataset(Dataset):
def __init__(self,df):
self.df = df
self.feature_name = ['user_id','item_id']
#数据编码
self.enc_data()
def enc_data(self):
#使用enc_dict对数据进行编码
self.enc_data = defaultdict(dict)
for col in self.feature_name:
self.enc_data[col] = paddle.to_tensor(np.array(self.df[col])).squeeze(-1)
def __getitem__(self, index):
data = dict()
for col in self.feature_name:
data[col] = self.enc_data[col][index]
if 'label' in self.df.columns:
data['label'] = paddle.to_tensor([self.df['label'].iloc[index]],dtype="float32").squeeze(-1)
return data
def __len__(self):
return len(self.df)
train_dataset = BaseDataset(train_df)
test_dataset = BaseDataset(test_df)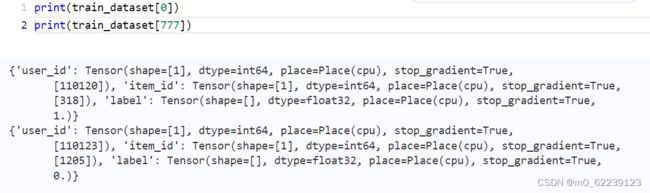
3. 如何进行数据I/O
二、 定义模型
- 定义各个子模块
- 将子模块合并成最终的模型
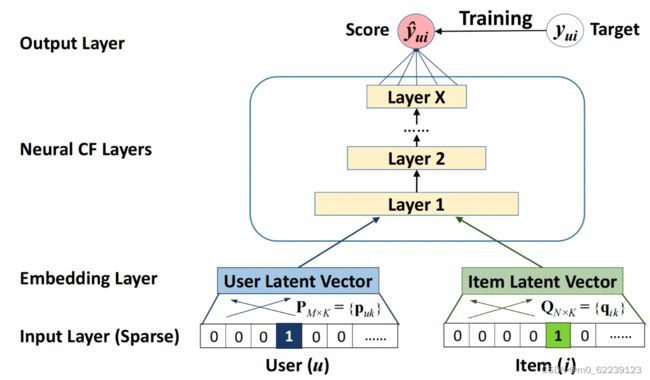
class NCF(paddle.nn.Layer):
def __init__(self,
embedding_dim = 16,
vocab_map = None,
loss_fun = 'nn.BCELoss()'):
super(NCF, self).__init__()
self.embedding_dim = embedding_dim
self.vocab_map = vocab_map
self.loss_fun = eval(loss_fun) # self.loss_fun = paddle.nn.BCELoss()
self.user_emb_layer = nn.Embedding(self.vocab_map['user_id'],
self.embedding_dim)
self.item_emb_layer = nn.Embedding(self.vocab_map['item_id'],
self.embedding_dim)
self.mlp = nn.Sequential(
nn.Linear(2*self.embedding_dim,self.embedding_dim),
nn.ReLU(),
nn.BatchNorm1D(self.embedding_dim),
nn.Linear(self.embedding_dim,1),
nn.Sigmoid()
)
def forward(self,data):
user_emb = self.user_emb_layer(data['user_id']) # [batch,emb]
item_emb = self.item_emb_layer(data['item_id']) # [batch,emb]
mlp_input = paddle.concat([user_emb, item_emb],axis=-1).squeeze(1)
y_pred = self.mlp(mlp_input)
if 'label' in data.keys():
loss = self.loss_fun(y_pred.squeeze(),data['label'])
output_dict = {'pred':y_pred,'loss':loss}
else:
output_dict = {'pred':y_pred}
return output_dict三、完成Pipeline
- 训练模型,验证模型,测试模型
def train_model(model, train_loader, optimizer, metric_list=['roc_auc_score','log_loss']):
model.train()
pred_list = []
label_list = []
pbar = tqdm(train_loader)
for data in pbar:
output = model(data)
pred = output['pred']
loss = output['loss']
loss.backward()
optimizer.step()
optimizer.clear_grad()
pred_list.extend(pred.squeeze(-1).cpu().detach().numpy())
label_list.extend(data['label'].squeeze(-1).cpu().detach().numpy())
pbar.set_description("Loss {}".format(loss.numpy()[0]))
res_dict = dict()
for metric in metric_list:
if metric =='log_loss':
res_dict[metric] = log_loss(label_list,pred_list, eps=1e-7)
else:
res_dict[metric] = eval(metric)(label_list,pred_list)
return res_dict
def valid_model(model, valid_loader, metric_list=['roc_auc_score','log_loss']):
model.eval()
pred_list = []
label_list = []
for data in (valid_loader):
output = model(data)
pred = output['pred']
pred_list.extend(pred.squeeze(-1).cpu().detach().numpy())
label_list.extend(data['label'].squeeze(-1).cpu().detach().numpy())
res_dict = dict()
for metric in metric_list:
if metric =='log_loss':
res_dict[metric] = log_loss(label_list,pred_list, eps=1e-7)
else:
res_dict[metric] = eval(metric)(label_list,pred_list)
return res_dict
def test_model(model, test_loader):
model.eval()
pred_list = []
for data in tqdm(test_loader):
output = model(data)
pred = output['pred']
pred_list.extend(pred.squeeze().cpu().detach().numpy())
return np.array(pred_list)2. 加载数据集
train_loader = DataLoader(train_dataset,batch_size=config['batch'],shuffle=True,num_workers=0)
test_loader = DataLoader(test_dataset,batch_size=config['batch'],shuffle=False,num_workers=0)3. 实例化模型,优化器
model = NCF(embedding_dim=64,vocab_map=vocab_map)
optimizer = paddle.optimizer.Adam(parameters=model.parameters(), learning_rate=config['lr'])
train_metric_list = []4. 开始训练
for i in range(config['epoch']):
#模型训练
train_metirc = train_model(model,train_loader,optimizer=optimizer)
train_metric_list.append(train_metirc)
print("Train Metric:")
print(train_metirc)5. 新数据预测
y_pre = test_model(model,test_loader)
test_df['y_pre'] = y_pre
test_df['ranking'] = test_df.groupby(['user_id'])['y_pre'].rank(method='first', ascending=False)
test_df = test_df.sort_values(by=['user_id','ranking'],ascending=True)
test_df6. 计算指标
HITRATE 与 NDCG
def hitrate(test_df,k=20):
user_num = test_df['user_id'].nunique()
test_gd_df = test_df[test_df['ranking']<=k].reset_index(drop=True)
return test_gd_df['label'].sum() / user_num
def ndcg(test_df,k=20):
'''
idcg@k 一定为1
dcg@k 1/log_2(ranking+1) -> log(2)/log(ranking+1)
'''
user_num = test_df['user_id'].nunique()
test_gd_df = test_df[test_df['ranking']<=k].reset_index(drop=True)
test_gd_df = test_gd_df[test_gd_df['label']==1].reset_index(drop=True)
test_gd_df['ndcg'] = math.log(2) / np.log(test_gd_df['ranking']+1)
return test_gd_df['ndcg'].sum() / user_num
hitrate(test_df,k=5)
ndcg(test_df,k=5)