Poly-YOLO及YOLOv3的不足:标签重写、无效的anchor分配
前言
在学习PolyYolo开源!Yolo也能做实例分割,检测mAP提升40%!,记录一下所学的内容。
YOLOv3存在的问题
标签重写

YOLO系列都是基于图像的cell作为单元进行检测,即把一张图片分成mn个网格,就如上图的左图,黄色的点是四辆车的中心点,分别落在不同的格子,每个格子就负责预测这个物体。
以416416输入图像为例,图像的大小随着一系列的卷积下降到1313的feature map(YOLO从输入到输出的时候是经过32倍的下采样)。此时特征图的一个像素点的感受野是3232大小的图像patch,在YOLOv3训练的时候,如果出现过相同两个目标的中心位于同一个cell,且分配个相同一个anchor,那么前面的一个目标就会被后面的目标重写。也就是说,两个目标由于中心距离太近以至于特征图上采样成为同一个像素点时,这时候其中一个目标就会被重写而无法进行到训练中。结果导致,忘了训练时会忽略一些目标,导致正样本数量非常少,特被是存在于分辨率比较低的特征图中。
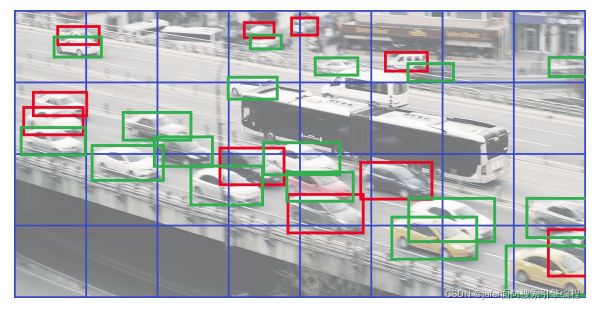
如上图所示,说明标签重写问题。如果两个框(具有相同的锚框),中心属于同一个cell,则标签会被其他物体重写。上图中蓝色表示网格,红色表示重写标签,绿色表示保留标签。上图一共27个标签,10个被重写,并且检测器未经过训练以检测它们。
无效的anchor分配
YOLO系列的anchor机制
YOLOv3中采用kmeans算法聚类得到特定的9个anchor,并且以每三个为一组,大尺度的特征图负责预测小物体,中等尺度和小尺度的特征图负责预测大物体。一个特定的GT框与哪个scale的anchor匹配度最高,就会被指定给哪个scale,正常情况下应该是不同大小的物体会被anchor分配到不同预测层进行预测。但是这种分配机制只适用于标准分布M~U(0,r),然而,在实际问题中,目标框大小不会分布的这么理想,就会造成某些尺度的特整层未被充分利用。
为了说明这个问题,假设两个box:M1和M2;前者与放置在高速公路上的摄像头的车牌检测任务相连接,后者与放置在车门前的摄像头的人检测任务相连接。对于这样的任务,我们可以获得大M1∼(0.3r,0.2r),因为这些牌将会覆盖小的区域(正常情况下,车牌相对于图片占比是比较小的),而m2∼(0.7r,0.2r)因为人类将会覆盖大的区域。
对于这两个集合,分别计算anchor。第一种情况导致的问题是,中、大型的输出规模也将包括小的anchor,因为数据集不包括大的目标。这里,标签重写的问题将逐步升级,因为需要在粗网格中检测小目标。反之亦然。大目标将被检测在小和中等输出层。在这里,检测将不会是精确的,因为中小输出层有有限的感受野。三种常用量表的感受野为{85×85,181×181,365×365}。这两种情况的实际影响是相同的:性能退化。
在介绍YOLOv3的文章中,作者说:“YOLOv3具有较高的小目标AP性能。但是,在中、大型目标上的性能相对较差。” 我们认为YOLOv3出现这些问题的原因就是在此。
Poly-YOLO根据YOLOv3的改进
改进标签重写问题
1、增加输入图片分辨率大小;
2、增加输出特征图大小
Poly-YOLO作者的做法是增加输出特征图大小。
下图是不同输入尺寸下,Poly-YOLO和YOLOv3标签重写率的比较
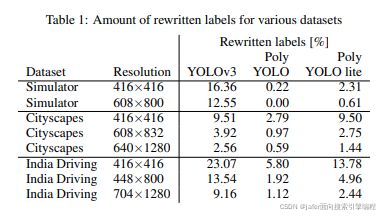
上图所示,输入的尺寸越大,不管是YOLOv3还是Poly-YOLO,标签重写率都是降低的,但是Poly-YOLO笔YOLOv3的效果要好一点。
改进anchor分配问题
anchor分布问题,有两种解决办法:
第一种方法:
kmeans聚类流程不变,但是要避免出现小物体被分配到小的特征图上训练和大目标被分配到大输出特征图上面训练问题,具体就是首先基于网络输出层感受野,定义三个大概范围尺度,然后设置两个阈值,强行将三个尺度离散化分开;然后对bbox进行单独三次聚类,每次聚类都是在前面指定的范围内选择特定的bbox进行,而不是作用于整个数据集。主要是保证kmeans仅仅作用于特定bbox大小范围内即可。但是缺点也非常明显,如果物体大小都差不多,那么几乎仅仅只有一个输出层有物体分配预测,其余两个尺度在“摸鱼”。
第二种方法:
创建具有单个输出的体系结构,所有物体都是在这个层预测。可以避免kmeans聚类问题,但是为了防止标签重写,所以把输出分辨率调高。作者采用的事1/4尺度输出,属于高分辨率输出,重写概率很低。(创建一个具有单个输出的体系结构,该输出将聚合来自各种scale的信息。然后一次性处理所有的anchor。)
模型融合
下图是作者实现的结构:
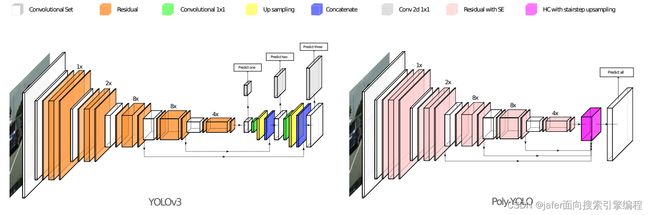
emsp;作者是怎么进行模型融合的呢?可以看到上图,比较明显,将前面的特征融合都一个feature map里面。
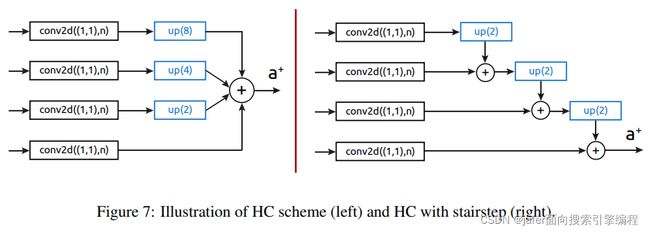
emsp;下面可以详细了解一下(下面的公式有点难,有兴趣的可以自行去研究一下论文)。作者使用了具有高缩放比例的单个输出层与所有锚点链接,s1 = 1/4(即输出尺度是输入尺度的1/4),对于由多个局部尺度组成的单个输出尺度,采用了hypercolumn technique,这里使用hypercolmn实现对多个尺度部分的单尺度输出合成(hypercolmn主要是把单尺度的图融合在一起)。设O是一个特征图,u(·, ω)函数表示以因子ω对输入图像进行上采样,m(·)函数表示一个转换,把a × b × c × ·转为a × b × c × δ维度的映射,δ是一个常数。此外,认为g(O1, …, On)是一个n元的composition/aggregation函数。为此, 使用hypercolmn的输出特征图如下所示
![]()
选择加法作为聚合函数
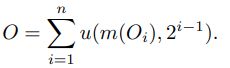
emsp;从公式明显可以看出,存在很高的不平衡性-O1的单个值投影到O只是单个值,而On的单个值直接投影到 2n−1 × 2n−1的值中。为了打破这种不平衡,作者使用计算图形学中已知的阶梯方法。
staircase插值增加(或降低)图像分辨率最大10%,直到达到期望的分辨率。与直接上采样相比,输出更平滑。这里使用最低可用的upscale因子2。形式上定义staircase输出特征映射O为:
![]()
如果考虑最邻近上采样O=O’保持不变。由于双线性差值(和其他),O 不等于O’用于非齐次输入。关键是,无论是直接上采样还是staircase方法,计算复杂度都是相同的。虽然staircase方法实现了更多的添加,但是它们是通过分辨率较低的特征图计算,因此添加的元素数量是相同的。
看下图,左边是普通的hypercolmn,右边是梯度形式的hypercolmn。从右图中可以看到,小尺度的输出特征图进行一个二倍的上采样,然后和上一级(比它大一级的尺度图)进行融合。融合之后,再进行上采样,再和更大的尺度他进行融合,以此类推。左边,最小的特征图直接进行8倍的上采样,中间的分别进行4倍、二倍的上采样。把他们上采样到统一尺度之后,再进行融合。
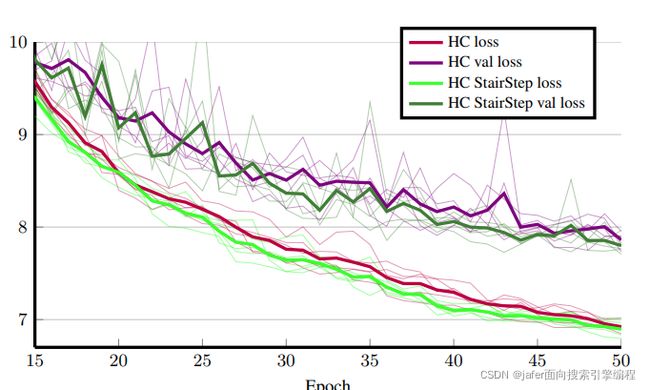
以上的做法有什么好处呢?作者直接上图,如下图所示。该图显示了在损失方面,使用hypercolmn和带有梯度的hypercolmn之间的差异。可以看到带有梯度的hypercolmn在损失下降方面还是有比较明显的优势。
其他改进
通过(SE)块
和提高输出分辨率,降低了计算速度。由于速度是YOLO的主要优势。作者在特征提取阶段减少了卷积滤波器的数量,即设置为原始数量的75%.
小结
Poly-YOLO在特征提取部分每层使用较少的卷积滤波器,并通过squeeze-and-excitation模块扩展它。较重的neck block使用staircase进行上采样带有hypercomn的轻量block所取代。
head使用一个输出而不是三个输出,具有更高的分辨率。
综上所述,Poly-YOLO的参数比YOLOv3少40%,但是可以产生更精确的预测。
Poly-YOLO实例分割
多边形框原则
在一般的实例分割中,属于像素级的,即每一个像数代表一个什么东西,把轮廓内的每个像素点都分为一个类别。
在Poly-YOLO中,作者引入一个多边形表示,它能够检测不同数量的顶点的目标,以边界框的中心点作为原点,αi,j代表一个顶点到中心的距离(除以box的对角线进而归一化到[0, 1]), βi,j 为顶点到中心的角度。当检测到多边形边界框,可以通过对角线长乘以αi,j来获得多边形的box。
该原则允许网络学习与大小无关的一般形状,而不是具有大小的特定实例,βi,j∈[0, 360], 可以通过限行变换将其更改为βi,j∈[0, 1]。当某个极单元cell具有高置信度时,顶点必定位于单元内部。通过与极坐标单元的原点和位置之间的距离,就可以知道其近似位置,并且可以通过极单元内部的角度来精确调整位置。
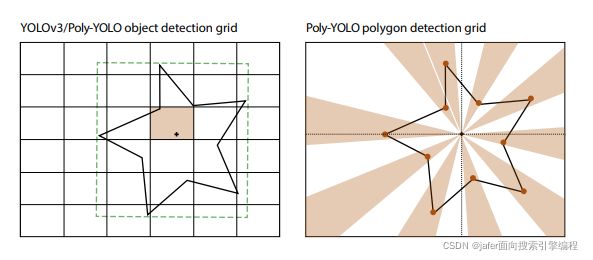
下图展示Poly-YOLO中使用的网格。左图:矩形网格,取自YOLOv3。一个对象的边界框位于其中心的单元格,讲预测其边界框的坐标。右图:Poly-YOLO中基于圆形扇区的网格,用于检测多边形的顶点。网格的中心与对象边界框的中心重合。然后,每个扇形区负责检测特定顶点的极坐标。没有顶点的扇区应该产生等于0的置信度。
与Poly-YOLO集成(实例分割和目标检测集成)
检测多边形的思想是通用的,可以很容易地集成到任意的神经网络中。通常,必须修改三个部分:数据准备的方式、体系结构和损失函数。在Poly-YOLO中,输出层中卷积滤波器的数量必须更新。当我们只检查box时,最后一层输出维度为n=na(nc +5),na=9(anchor的个数),nc为类别数。对基于多边形的目标检测进行集成,得到n=na(nc+5+3nv),nv为每个多边形检测到的顶点数的最大值。
损失函数如下图所示:
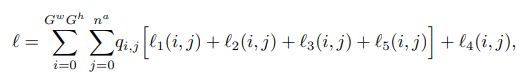
l1(i,j)是对边界框中心预测的损失;
l2(i,j)是对框的尺寸的损失;
l3(i,j)是置信度的损失;
l4(i,j)是类别预测的损失;
l5(i,j)是由距离、角度和顶点置信度预测组成的边界多边形的损失。最后,qi,j∈{0, 1}是一个常数,指示第
个单元格和第j个锚点是否包含标签。
l1到l4都是和YOLOv3一样,l5是Poly-YOLO基于多边形预测扩展出来的。
参考:https://blog.csdn.net/baobei0112/article/details/106440642/