如何在ubuntu系统上安装多个cudn环境(及对应cudnn、pytorch 、torchvision安装方法 )
如何在ubuntu系统上安装多个cudn环境
- 第二版本的cuda的安装
- cuda的切换设置
- 对应cudnn的安装
- 安装pytorch及torchvision
- 后话
- 转载请注明出处
在跑模型的时候报错说缺乏函数,查了下相关任务发现是版本问题,需要安装更低版本的相应环境。由于cuda与pytorch之前存在对应关系,所以尝试安装不同版本的cuda,使不同虚拟环境可以使用不同的cuda,参考了一些文章还算顺利的完成了配置。
第二版本的cuda的安装
cuda的安装网上很多教程,这里不赘述了,主要讲在已有cuda的情况下如何安装第二个cuda。服务器已有的cuda-11.1,打算再安装一个cuda-10.0,用来匹配代码需要的pytorch版本 。具体的cuda及pytorch版本之间的对应关系可以查看https://pytorch.org/get-started/previous-versions/#via-pip,可以根据之前下载的版本了解版本对应关系。
首先到https://developer.nvidia.com/cuda-toolkit-archive下载想要的cuda版本 ,参照其他一些教程进行安装,比如 https://blog.csdn.net/ashome123/article/details/105822040/
注意不需要安装显卡驱动 以及不添加链接 cuda的samples就因人而异吧
Install NVIDIA Accelerated Graphics Driver for Linux-x86_64 384.81?
(y)es/(n)o/(q)uit: n
Do you want to install a symbolic link at /usr/local/cuda?
(y)es/(n)o/(q)uit: n
Installing the CUDA Toolkit in /usr/local/cuda-10.0 ...
主要不同点就是 install a symbolic link需要选择no,同时不要通过.bashrc文件设置cuda的链接。
cuda的切换设置
之后就是设置进入某个环境时,将我们的cuda路径自动链接到我们的cuda-10.2中,过程如下:
首先新建虚拟环境(your_env_name为你想设置的虚拟环境名字 同时指定python版本)
conda create -n your_env_name python=x.x
之后进入到新建的环境,通过下面代码查看虚拟环境的绝对路径
echo ${CONDA_PREFIX}
之后根据自己的虚拟环境替换地址执行以下命令,该部分操作使得进入该环境时系统的cuda路径自动替换到想要的cuda版本。比如我的环境是:/home/lab208/anaconda3/envs/torch_1.1.0,我的命令是:
mkdir -p /home/lab208/anaconda3/envs/torch_1.1.0/etc/conda/activate.d
gedit /home/lab208/anaconda3/envs/torch_1.1.0/etc/conda/activate.d/activate.sh
在上面第二行代码运行后会打开一个文本,在里面输入下面代码并保存(注意第四行的cuda填写自己想要的版本,比如我需要该虚拟环境使用cuda-10.0):
ORIGINAL_CUDA_HOME=$CUDA_HOME
ORIGINAL_LD_LIBRARY_PATH=$LD_LIBRARY_PATH
ORIGINAL_PATH=$PATH
export CUDA_HOME=/usr/local/cuda-10.0
export LD_LIBRARY_PATH=$CUDA_HOME/lib64:$LD_LIBRARY_PATH
export PATH=$CUDA_HOME/bin:$PATH
保存之后执行下面代码,给系统权限
(关于这行代码可以参照https://blog.csdn.net/u012106306/article/details/80436911进行理解)
chmod +x /home/lab208/anaconda3/envs/torch_1.1.0/etc/conda/activate.d/activate.sh
之后为了退出之后将cuda的路径修改回原本的系统路径,还需要执行以下命令:
mkdir -p /home/lab208/anaconda3/envs/torch_1.1.0/etc/conda/deactivate.d
gedit /home/lab208/anaconda3/envs/torch_1.1.0/etc/conda/deactivate.d/deactivate.sh
在输入上面第二行代码的时候会打开一个文本,在里面输入下面代码并保存:
export CUDA_HOME=$ORIGINAL_CUDA_HOME
export LD_LIBRARY_PATH=$ORIGINAL_LD_LIBRARY_PATH
export PATH=$ORIGINAL_PATH
unset ORIGINAL_CUDA_HOME
unset ORIGINAL_LD_LIBRARY_PATH
unset ORIGINAL_PATH
保存之后执行下面代码,给系统权限
chmod +x /home/lab208/anaconda3/envs/torch_1.1.0/etc/conda/deactivate.d/deactivate.sh
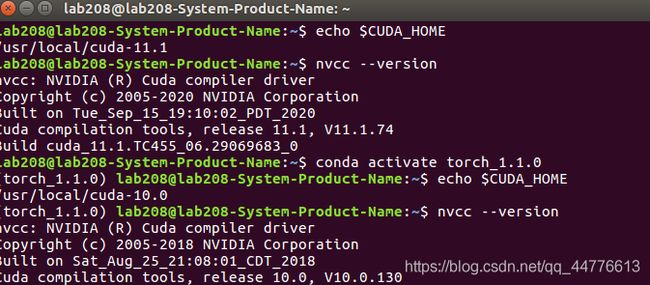
到这就完成了cuda切换的配置,可以通过下面方法查看是否配置成功:
echo $CUDA_HOME ## 查看cuda路径
nvcc --version ## 利用nvcc查看cuda版本
成功结果展示如下图 在base环境中为cuda-11.1 在torch_1.1.0中环境为cuda-10.0
对应cudnn的安装
在安装好第二个cuda之后,我们就可以安装相应的cudnn,但注意需要安装到对应的cudn版本中,比如我需要安装到cuda-10.0中。到https://developer.nvidia.com/rdp/cudnn-archive下载需要的cudnn版本,解压之后有一个cuda文件,执行下面命令:
sudo cp cuda/include/cudnn*.h /usr/local/cuda-10.0/include
sudo cp -P cuda/lib64/libcudnn* /usr/local/cuda-10.0/lib64
sudo chmod a+r /usr/local/cuda-10.0/include/cudnn*.h /usr/local/cuda-10.0/lib64/libcudnn*
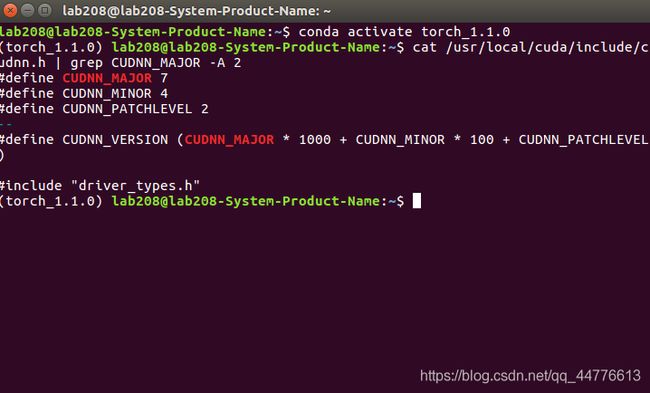
可以用以下代码检测是否安装成功(其实是查看版本号):
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
结果如下:
注意路径需要时对应自己的cuda版本(比如我需要安装到cuda-10.0文件夹中)
同时注意第一行命令中是cudnn*.h而不是cudnn.h,不然之后用命令行查看不了版本;不过似乎也没有很大影响,我最开始也是这一安装的,将命令修改为下面命令也可以查看版本:
cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
安装pytorch及torchvision
可以选择conda安装也可以使用pip install安装 ,这里我选择直接conda安装:
安装代码请到https://pytorch.org/get-started/previous-versions/#via-pip查看
(本来是打算安装pytroch==1.1.0的,但是后来看代码介绍1.1.0代码也不支持,因此安装1.0.1版本,不过这个虚拟环境的名字就尴尬了…)
conda install pytorch==1.0.1 torchvision==0.2.2 cudatoolkit=10.0 -c pytorch
后话
如上安装之后运行代码还是出错,错误显示如下:
from torch.jit.annotations import Optional ImportError: cannot import name ‘Optional’
查看之后发现pytorch== 1.0.1和 torchvision== 0.2.2 之间是不匹配的,需要将torchvision降级为0.2.1,降级之后代码成功运行。根据官方的命令pytorch== 1.0.1和 torchvision== 0.2.2应该是配对的·,不知道为什么pytorch会出这种错误,不过代码最后能运行就非常开心了,不再想了。
转载请注明出处
主要参考博客:
如何在Ubuntu 20.04的Anaconda不同环境中安装不同的CUDA版本(2020年8月)
查看cudnn版本
给虚拟环境指定cuda
pytorch版本,cuda版本,系统cuda版本查询和对应关系