YOLOX训练代码分析2-trainer.py
1. yolox网络构建
(1) 网络加载
通过tools/train.py中main函数get_exp(yolox/exp/build.py)构建网络,其中get_exp可以通过名称与文件获取网络模型与参数。
if exp_file is not None:
return get_exp_by_file(exp_file) # 通过文件获取模型参数
else:
return get_exp_by_name(exp_name) # 通过名称获取模型参数get_exp_by_name最终是调用get_exp_by_file,该函数通过加载.py的文件获取模型与相关参数,接下来分析get_exp_by_file:
def get_exp_by_file(exp_file):
try:
sys.path.append(os.path.dirname(exp_file)) # 模型文件添加到系统文件中,供调用
# 动态导入模块,获得对象文件
current_exp = importlib.import_module(os.path.basename(exp_file).split(".")[0]) # os.path.basename(exp_file).split(".")[0]获取模型名称
# 调用py文件(yolox_l,_m,_s,_x,_tiny等)中的Exp类,获取模型参数(键值对形式)
exp = current_exp.Exp()
except Exception:
raise ImportError("{} doesn't contains class named 'Exp'".format(exp_file))
return exp(2) 继承关系
其中yolox_s.py,yolox_m.py,yolox_l.py,yolox_x.py,yolox_tiny.py文件中的Exp类继承自yolox/exp/yolox_base.py中的Exp类,yolox_base文件的Exp类主要实现yolox/exp/base_exp.py文件中的BaseExp的抽象类的抽象方法。yolox_base文件中的Exp类存储了网络的各个超参数。

网络构建过程中的一些继承关系
2. yolox的训练
yolox通过main函数中的Trainer(exp, args)传递相关参数,然后由trainer.train()进行网络的训练。train函数如下
def train(self):
self.before_train() # 训练之前的准备
try:
self.train_in_epoch() # 一个周期的训练
except Exception:
raise
finally:
self.after_train() # 训练后的处理2.1 before_train
before_train是训练之前的准备工作,主要是数据加载、数据增强、梯度优化器获取等功能。
(1) 梯度优化器获取
self.optimizer = self.exp.get_optimizer(self.args.batch_size)
# yolox/exp/yolox_base.py
# 优化器获取
def get_optimizer(self, batch_size):
if "optimizer" not in self.__dict__:
if self.warmup_epochs > 0:
lr = self.warmup_lr
else:
lr = self.basic_lr_per_img * batch_size
pg0, pg1, pg2 = [], [], [] # optimizer parameter groups
for k, v in self.model.named_modules():
if hasattr(v, "bias") and isinstance(v.bias, nn.Parameter): # pg2存储bias
pg2.append(v.bias) # biases
if isinstance(v, nn.BatchNorm2d) or "bn" in k: # pg0是batchNorm的gamma
pg0.append(v.weight) # no decay
elif hasattr(v, "weight") and isinstance(v.weight, nn.Parameter): # pg1是conv的weight(卷积核)
pg1.append(v.weight) # apply decay
optimizer = torch.optim.SGD(pg0, lr=lr, momentum=self.momentum, nesterov=True)
optimizer.add_param_group({"params": pg1, "weight_decay": self.weight_decay}) # add pg1 with weight_decay
optimizer.add_param_group({"params": pg2})
self.optimizer = optimizer
return self.optimizer是否采用混合精度加速,amp的精髓在于,内存中用 FP16 做储存和乘法从而加速计算,用 FP32 做累加避免舍入误差
if self.amp_training:
model, optimizer = amp.initialize(model, self.optimizer, opt_level="O1")(2) 数据加载与数据增强
# data related init 最后迭代周期取消数据增强操作
self.no_aug = self.start_epoch >= self.max_epoch - self.exp.no_aug_epochs
# 训练数据的加载,no_aug控制数据增强
self.train_loader = self.exp.get_data_loader(batch_size=self.args.batch_size,
is_distributed=self.is_distributed, no_aug=self.no_aug)
# 默认情况是yolox/exp/yolox_base.py中的get_data_loader
# 如果训练时指定文件:
# -f ../exps/example/yolox_coco/yolox_coco_s.py
# -f ../exps/example/yolox_voc/yolox_voc_s.py
# 则调用yolox_coco_s.py文件中的get_data_loader, 其中yolox_coco_s.py
# 文件中的类Exp继承自yolox/exp/yolox_base.py中的Exp.exps/example/yolox_coco/yolox_coco_s.py
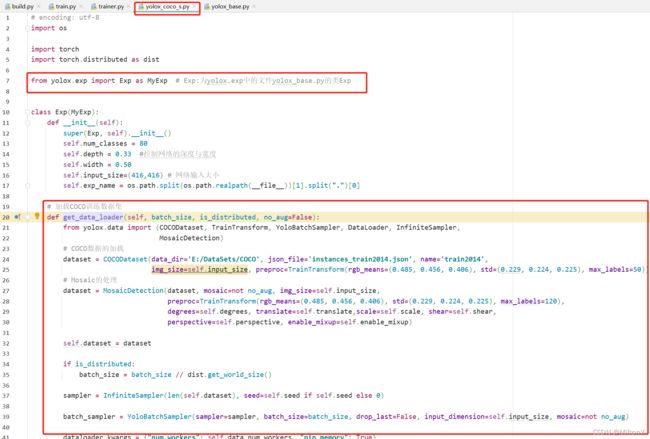
yolox/exp/yolox_base.py

(3) 获取学习率策略
self.lr_scheduler = self.exp.get_lr_scheduler(
self.exp.basic_lr_per_img * self.args.batch_size,
self.max_iter)(4) 获取模型评估器
self.evaluator = self.exp.get_evaluator(
batch_size=self.args.batch_size,
is_distributed=self.is_distributed)2.2 train_in_epoch(周期迭代)
一个周期的训练表示以batch_num迭代图像数据集一篇,yolox中该函数内容如下
# 所有周期的训练
def train_in_epoch(self):
for self.epoch in range(self.start_epoch, self.max_epoch):
self.before_epoch() # 周期迭代前的处理,判断是否结束数据增强操作
self.train_in_iter() # 一个周期的训练
self.after_epoch() # 周期迭代后的处理,训练模型评估并保存某个周期训练的模型参数train_in_iter表示一个周期的迭代训练,代码内容如下:
# 一个周期的迭代
def train_in_iter(self):
for self.iter in range(self.max_iter):
self.before_iter() # 一次batch迭代前的处理,未添加代码(pass)
self.train_one_iter() # 一个batch的迭代
self.after_iter() # 一次batch迭代后的处理,每多少个周期输出日志(如损失,学习率等)以上代码梳理的结构图如下

最关键的函数是train_one_iter,一个batch的图像训练。其中先获取一个batch的图像与图像标注信息,再由model检测头计算模型的损失,最后进行反向传播,更新相关参数。
def train_one_iter(self):
iter_start_time = time.time()
inps, targets = self.prefetcher.next() # 获取一个batch的图像数据与标注信息
inps = inps.to(self.data_type)
targets = targets.to(self.data_type)
targets.requires_grad = False
data_end_time = time.time()
# 此处计算模型的损失等
outputs = self.model(inps, targets)
loss = outputs["total_loss"] # 总损失获取
self.optimizer.zero_grad() # 模型梯度置0
if self.amp_training: # 是否采用混合精度加速
with amp.scale_loss(loss, self.optimizer) as scaled_loss:
scaled_loss.backward()
else:
loss.backward()
self.optimizer.step() # 梯度下降执行一步参数更新
if self.use_model_ema:
self.ema_model.update(self.model)
# 更新学习率
lr = self.lr_scheduler.update_lr(self.progress_in_iter + 1)
for param_group in self.optimizer.param_groups:
param_group["lr"] = lr
iter_end_time = time.time()
self.meter.update(iter_time=iter_end_time - iter_start_time,
data_time=data_end_time - iter_start_time, lr=lr, **outputs)模型中的损失输出通过yolox/models/yolox.py获取。