NLP之依存句法分析(小白专栏学习之路)
由于研究生的规划方向是NLP(自然语言处理),所以将自己每次汇报学习过程记录在本专栏。大家可以和我一起进行学习,后续有论文采用也会将链接贴下。
自然语言处理的语法分析有两个比较火,一个是短语结构分析(也叫上下文无关文法),一个是依存句法分析。
什么是短语结构分析/短语结构树?
简单来说,我们分析一个句子的时候,不用考虑句子词语间的联系关系。只需要让不同的词语组成有关短语结构,生成短语结构树。
短语结构语法描述了如何自顶而下的生成一个句子,反过来,句子也可以用短语结构语法来递归的分解。层级结构其实是一种树形结构,例如这句话“上海 浦东 开发 与 法制 建设 同步”,分解成如下图的短语结构树:
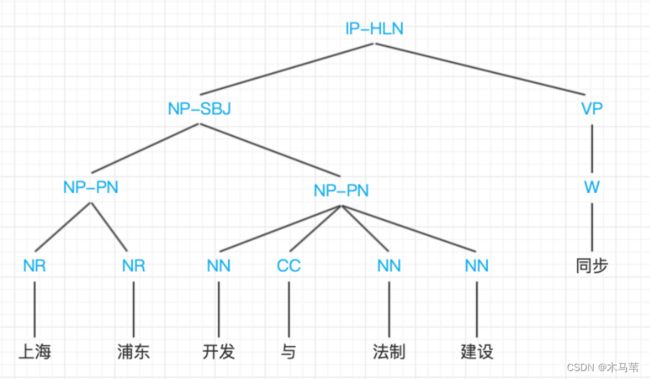
这样的树形结构称为短语结构树,相应的语法称为*短语结构语法**或上下文无关文法。至于树中的字母下面开始介绍。
不过这个不是我们实验室研究方向,所以短语结构树分析就到这里。
什么是依存句法分析?
依存句法分析就比短语结构树关注词语间的语法联系。
首先,我们需要知道词与词之间有主从关系:①他们是二元不等的关系(也就是不可交换);②两个词有联系或者说有依存关系。处于主宰地位的是支配词(head),另一个修饰/依附于支配词的叫从属词(dependent)。
现代依存语法中,语言学家 Robinson 对依存句法树提了 4 个约束性的公理。
①根节点唯一性:有且只有一个词语(ROOT,虚拟根节点,简称虚根)不依存于其他词语。
②连通:除此之外所有单词必须依存于其他单词。
③无环:每个单词不能依存于多个单词,若A依存于B,那么B不可能依存于A。
④投射性( projective ):如果单词 A 依存于 B,那么位置处于 A 和 B 之间的单词 C 只能依存于 A、B 或 AB 之间的单词。
这四个公理为后面的设计方法奠定了基础。
详解依存句法分析
依存句法分析( dependency parsing )指的是分析句子的依存语法的一种中高级 NLP任务,其输人通常是词语和词性,输出则是一棵依存句法树。 本节介绍实现依存句法分析的两种宏观方法,以及依存句法分析的评价指标。
- 基于转移的依存句法分析(非实验室方向,仅了解)
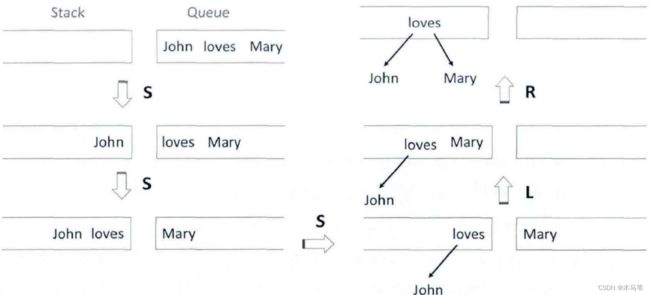
转移系统:初始状态—(状态转移动作)—>n个中间状态----(状态转移动作)---->接受状态,将一个状态表示为<栈,缓存,已分析好的依存弧>
初始状态:栈中只有伪词 w0 , 整个词语都在缓存中,没有依存弧。
接受状态:栈中只有伪词,缓存清空,所有的依存弧。
状态转移动作:移进,左规约,右规约。
移进表示将缓存中的第一个词移入栈中。
栈中词从左往右排序【…,X3,X2,X1】,栈顶词为X1,后进先出。
左规约表示栈顶的第一个词与第二个词产生了左指向依存弧,即第一个词依存于第二个词,将栈顶第二个词(核心词)下栈。
右规约表示栈顶第一个词与第二个词产生了右指向依存弧,即第二个次依存于第一个词,将栈顶第一个词下栈。
2.基于图的依存句法分析
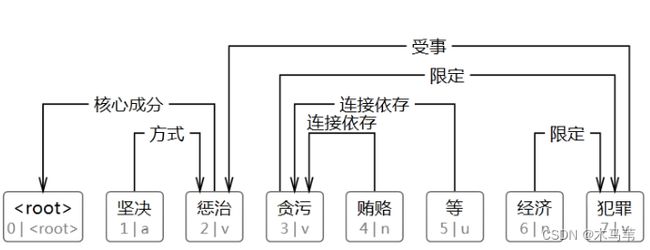
正如树是图的特例一样,依存句法树其实是完全图的一个子图。如果为完全图中的每条边是否属于句法树的可能性打分,然后就可以利用Prim之类的算法找出最大生成树作为依存句法树了。这样将整棵树的分数分解为每条边上的分数之和,然后在图上搜索最优解的方法统称为基于图的方法。
基于图的依存句法分析就是为每个要分析的句子生成一个有向图,其中:节点是句子中的单词,边是单词之间的依存关系,因为依存句法中规定每个句子都有其核心成分,所以加入了须根节点。依存句法中还规定了句子中除了须根节点,每个词必须依存于其他词,因此,句子依存图中边的个数和单词的个数相等。
步骤:
1.句子分词
2.手动设置一个虚根
3.从虚根w0开始,从左往右连接算arc的分数,分数最高确定arc连接指向。
4.依次从w1往后,重复3的步骤。(基于图,要求没有单独节点/词)。如w1->w2,计算分值,w1->w3...w1->w7,比较w1指向所有其他词的分值,得分最高进行连线。接着又w2->w3...
5.再来判断两个词之间的label关系,步骤同3.4一样。
5.所有词都走完,然后确定根据prim算法或者其他的,求最大生成树。
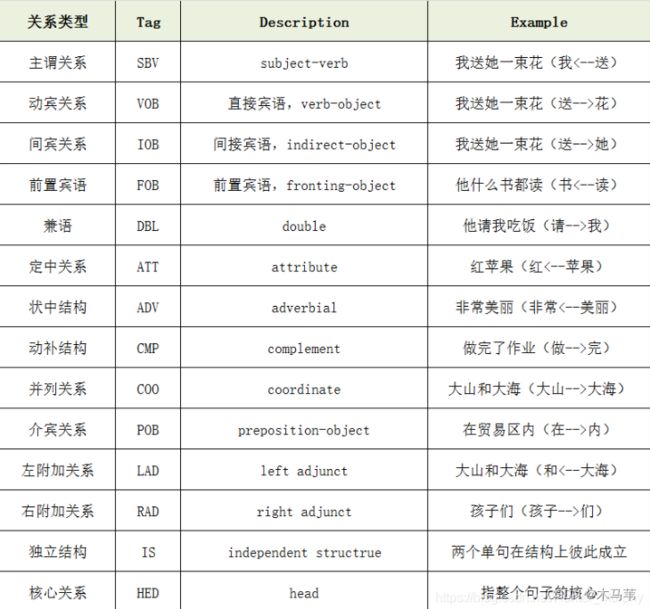
最后来个词间关系类型的表总结:
下章讲解具体例子,如何将一句话生成一棵树,按照机器输出格式。
参考:
1.https://blog.csdn.net/qq_43428310/article/details/107290398